【C++】通过stack、queue、deque理解适配器模式
破镜不能重圆,枯木可以逢春。

文章目录
- 一、stack
-
- 1.stack的介绍
- 2.stack相关OJ题(巧妙利用stack数据结构的特征)
- 3.stack的模拟实现
- 二、queue
-
- 1.queue的介绍
- 2.queue的相关OJ题(巧妙利用queue数据结构的特征)
- 3.queue的模拟实现
- 三、deque(双端队列容器,叫队列,但和队列没关系)
-
- 1.vector和list的优缺点→stack和queue的适配容器
- 2.deque的底层结构
- 3.deque的优缺点
- 4.为什么选择deque作为stack和queue的适配容器?(vector排序快,list中间插入删除牛,deque吸取两个容器的部分优点)
一、stack
1.stack的介绍

1.
stack和queue的设计实际是一种模式,这种模式叫做适配器模式,设计理念就是用已有的东西封装转换出你想要的东西。我们前面还学习过的一种模式叫做迭代器模式,这种模式的设计理念就是封装底层实现的细节,对所有底层数据结构不同的容器,都能提供统一的访问方式。
2.
stack的实现就是一种适配器的设计理念,适配器也可以叫做配接器,stack是一种只允许在某一端进行数据的插入和删除元素的容器,其他位置均不可以直接访问,所以对于stack来说不需要实现迭代器。
3.
在利用某种容器实现stack时,容器应该支持back()取到容器尾部元素,push_back()尾插,pop_back()尾删,empty()判空等操作,分别对应stack的top(),push(),pop(),empty()等操作。
对于stack来说,底层的适配容器为deque,但从其接口来看,stack实际就是一种特殊的vector,所以在模拟实现时,我们倾向于用vector来作stack的适配容器。
2.stack相关OJ题(巧妙利用stack数据结构的特征)
最小栈
1.
最小栈的解决思路就是利用两个栈,普通栈用来一直入栈所有的数据,minstack负责只入栈比上一次入栈元素小于或等于的元素,在出栈时,普通栈元素一定出栈,但minstack只有在普通栈的top元素和自身栈的top元素相等的时候才会去出栈,minstack的top元素就是当前普通栈的所有元素中最小的元素。
2.
解释一下为什么只有在普通栈top元素和minstack的top元素相等的时候,minstack才会出栈。
因为有可能在某一次入栈的元素是最小元素之后,入栈的剩余元素都是大于这个最小元素的,那么在pop的时候,你的minstack不能pop,因为minstack的top元素是现在栈所有元素最小的元素,只有说普通栈的top元素达到和minstack的top元素一样时,也就是现在pop的元素是栈中所有元素中最小的元素时,minstack才会跟着普通栈一样将最小的元素给pop掉。
class MinStack {
public:
MinStack() {
}
void push(int val) {
if(st.empty() || val <= minst.top())
minst.push(val);
st.push(val);//st是一直要入栈的。
}
void pop() {
if(st.top() == minst.top())
minst.pop();
st.pop();
}
int top() {
return st.top();
}
int getMin() {
return minst.top();
}
private:
stack<int> minst;
stack<int> st;
};
栈的压入弹出序列
1.
我们依次遍历入栈序列,拿入栈后的元素和出栈序列的第一个元素进行比较,如果相等,说明这个元素在入栈之后就立马出栈了,那我们就将入栈之后的元素给pop掉。如果不相等,说明这个元素还没有被pop掉,那我们就继续将入栈序列的后面的元素再次进行入栈,入栈之后再次和出栈序列的剩余元素进行比较。
2.
所以如果入栈序列和出栈序列是相匹配的话,遍历完入栈元素序列之后的结果应该是,st栈为空,并且下标i走到出栈序列的最后一个元素了。但如果两个序列是不匹配的话,st栈中一定还有剩余元素,无法被pop掉,并且i也无法走到出栈序列的最后一个元素的下标位置。
class Solution {
public:
stack<int> st;
bool IsPopOrder(vector<int> pushV,vector<int> popV) {
int i = 0;//代表出栈序列元素的下标。
for(auto e:pushV)
{
st.push(e);
while(!st.empty() && st.top() == popV[i])
{
st.pop();
++i;//出栈之后,该和出栈序列的下一个元素进行比较了。
}
}
return st.empty();
}
};
逆波兰表达式求值
1.
这道题里面有很多的知识点,帮助我复习运用了很多学过的知识,首先字符串有自己的比较运算符的重载函数,所以在比较字符串的时候,string类的字符串比较函数可以帮助我们节省很多代码,让我们无需再调用strcmp这样的函数来进行字符串的比较,下面都是一些非成员函数,在调用时可以直接调用,无需通过string类对象进行调用。

2.
string类还有字符串转换到其他类型的函数,在下面这道题中就用到了stoi将字符串转换为整数int类型的函数,stoi会返回字符串转换为整型之后的值。

3.
字符串也重载了[]+下标这样的访问方式,和vector一样,但到了list那里的时候我们就只能使用迭代器来进行访问了,利用[]+下标的访问方式和switch case分支语句的组合可以帮助我们挑选出vector里面字符串为运算符的部分。(有一说一,我做这个题的时候连switch case的格式都忘记了,太吓人了)
4.
这道题也巧妙利用了栈结构的特征,只要字符串是非运算符的那就将其全部转换为int,然后push到栈当中,只要遇到了运算符的字符串,那我们就依次取出栈顶的两个元素,按照取出次序来看,先取出的是右操作数,后取出的是左操作数,然后根据运算符类型将运算结果重新push到栈里面,等到下次遇到运算符字符串时,继续取出栈的两个元素进行计算,最后vector元素遍历完之后,栈中剩余的最后一个元素就是逆波兰表达式计算之后的结果。
class Solution {
public:
stack<int> st;
int evalRPN(vector<string>& tokens) {
for(auto s : tokens)
{
//if(s[0] == '+' || s[0] == '-' || s[0] == '*' || s[0] == '/')负数这里就不对了
if(s == "+" || s == "-" || s == "*" || s == "/")//利用string的运算符重载函数进行比较
{
int right = st.top();
st.pop();
int left = st.top();
st.pop();
switch(s[0])//拿到字符串的第一个字符
{
case '+':
st.push(left + right);
break;
case '-':
st.push(left - right);
break;
case '*':
st.push(left * right);
break;
case '/':
st.push(left / right);
break;
}
}
else
st.push(stoi(s));
}
return st.top();
}
};
用栈实现队列
1.
这道题比较经典了,也是很巧妙的利用栈结构的特征,栈是先进后出,队列是先进先出,如果想要用栈来模拟实现队列,一个栈肯定是不够用的,所以我们用两个栈之间的操作接口的配合,来模拟实现队列。
2.
入队列我们就将元素先都入栈到pushst里面,等到pop时,将pushst里面的元素依次取出来入栈到popst里面,这样popst里面依次取出来的元素序列正好符合出队列的元素序列,所以在出队列元素时,就相当于pop掉popst栈里面的元素,这样就符合了队列元素出队列的操作,peek就相当于queue的front接口的功能,拿到队头元素,实际就是拿popst栈顶的元素。
一旦popst栈为空时,我们就将pushst栈里面的元素倒腾过来,然后popst栈的操作行为就符合队列了。
class MyQueue {
public:
stack<int> pushst;
stack<int> popst;
MyQueue() {
//对于自定义类型,初始化列表会调用他的默认构造
}
void push(int x) {
pushst.push(x);
}
int pop() {
if(popst.empty())
{
while(!pushst.empty())
{
popst.push(pushst.top());
pushst.pop();
}
}
int ret = popst.top();
popst.pop();
return ret;
}
int peek() {
if(popst.empty())
{
while(!pushst.empty())
{
popst.push(pushst.top());
pushst.pop();
}
}
return popst.top();
}
bool empty() {
return pushst.empty() && popst.empty();
}
};
3.stack的模拟实现
1.
无论是函数模板还是类模板,在声明时都可以给缺省参数,只是在使用上有些不同,当你在使用函数模板时,无论是显式实例化还是隐式实例化,你所传参数是变量或对象,函数模板的实例化推演依靠的便是变量或对象的类型。而在使用类模板的时候,我们所传参数是类型,类模板依靠参数类型来推演实例化出具体的类。
2.
stack的实现颇为简单,利用vector容器就可以模拟实现出stack适配器,因为vector支持所有stack的操作,例如back,尾插尾删,size(),判空等操作。
namespace wyn
{
//前一个参数代表数据类型,后一个参数代表适配的容器
//template>
template<class T,class Container = deque<T>>
class stack
{
public:
void push_back(const T& x)
{
_con.push_back(x);
}
void pop()
{
_con.pop_back();
}
T& top()
{
return _con.back();
}
const T& top()const
{
return _con.back();
}
//const对象只能调用const成员函数,不能调用非const成员函数,因为权限不能放大。
//非const对象既能调用const成员函数,又能调用非const成员函数,因为权限可以平移或缩小。
bool empty()
{
return _con.empty();
}
size_t size()
{
return _con.size();
}
private:
Container _con;
};
}
二、queue
1.queue的介绍

1.
队列也是一种容器适配器,队列数据结构的接口功能要求有出队列,入队列所以,取队头元素,取队尾元素等重要接口,所以队列的底层容器需要支持头删,尾插,front,back等接口,list,deque,vector其实都可以作为queue的底层容器,但vector在出队列时,需要调用erase头删,而erase头删需要挪动数据,代价较大,所以queue的常见底层容器为list或deque。
2.
队列和栈一样,都不需要实现迭代器,因为队列只支持在容器的头尾两个位置进行元素的访问,所以无需实现迭代器。
2.queue的相关OJ题(巧妙利用queue数据结构的特征)
用队列实现栈
1.
这道题在queue本身有限的功能接口下实现栈的结构,是一道加深对于队列数据结构理解并且熟练运用其操作接口的题目。需要明确的原则就是,队列只能在队头出数据,在队尾入数据,在队头取数据,在队尾取数据。
2.
如果要实现栈的操作,我们可以用两个队列来实现,q负责将入栈的所有数据入到队列里面,等pop的时候,我们将q队尾的数据也就是back数据挪动到q的队头上面去,挪动的过程其实就是出队列数据,然后将数据再入队列,直到队尾数据挪动到队头后,我们将队头数据保存后,将q的队头数据pop掉,然后将刚刚保存的数据入队列到stackQ队列里面。
将上面的逻辑搞成一个循环,直到q队列为空,此时stackQ出队列的操作就是出栈操作了,栈的top元素就是stackQ的队头元素,如果stackQ为空,则栈顶元素就是q的队尾元素。
3.
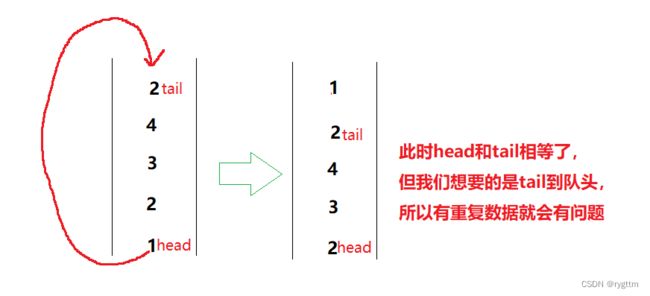
在具体实现时,我遇到了一点点问题,就是在写队尾数据挪到队头位置的while循环条件的时候,我当时用两个变量标识队头和队尾数据,然后让这两个变量不相等作为判断条件,在力扣上面通过了16个测试用例,最后一个没有通过。
在拿最后一个测试用例进行画图分析之后,我发现这个逻辑如果对于有重复数据的测试用例来看,在挪数据时会有问题,所以我们舍弃这样的用法,用队列大小来作为while循环条件。
class MyStack {
public:
queue<int> q;
queue<int> stackQ;
MyStack() {
}
void push(int x) {
q.push(x);
}
int pop() {
if(stackQ.empty())
{
int tail = q.back();
int head = q.front();
int size = q.size();
while(!q.empty())
{
//一旦push里面出现重复元素,head!=tail这样的判断条件,会让逻辑出现问题
//所以不要用这样的判断逻辑来换队尾到队头位置,用次数来作为判断条件吧!
// while(head != tail)
// {
// q.pop();
// q.push(head);
// head = q.front();
// }
while(--size)//循环次数为size-1次
{
q.pop();
q.push(head);
head = q.front();
}
//出来之后head==tail,将tail入stackQ队列,并且更新head和tail
stackQ.push(tail);
q.pop();
//q出队列之后,重新更新head和tail的值,用size作为判断条件后,size也要更新
tail = q.back();
head = q.front();
size = q.size();
}
}
int ret = stackQ.front();
stackQ.pop();//让stackQ直接出队列
return ret;
}
int top() {
if(stackQ.empty())
return q.back();
return stackQ.front();
}
bool empty() {
return q.empty() && stackQ.empty();
}
};
3.queue的模拟实现
1.
模拟实现queue也是非常简单的,只要底层容器有头删,尾插,back,front等接口功能就可以,list就可以作为queue的适配容器。所以模拟实现queue时,只要复用list的接口即可。模拟实现代码过于简单,大家一看就懂。
namespace wyn
{
//template>
template<class T, class Container = deque<T>>
class queue
{
public:
void push(const T& x)
{
_con.push_back(x);
}
void pop()
{
_con.pop_front();
}
const T& front()
{
return _con.front();
}
const T& back()
{
return _con.back();
}
//const对象只能调用const成员函数,不能调用非const成员函数,因为权限不能放大。
//非const对象既能调用const成员函数,又能调用非const成员函数,因为权限可以平移或缩小。
bool empty()
{
return _con.empty();
}
size_t size()
{
return _con.size();
}
private:
Container _con;
};
}
三、deque(双端队列容器,叫队列,但和队列没关系)
1.vector和list的优缺点→stack和queue的适配容器
1.
vector作为一种由动态数组实现的容器,他的缺点就是头删和头插会进行数据的挪动,并且如果发生扩容,还要对应产生扩容带来的消耗,比如开空间和拷贝数据。但他也有优点,支持随机访问,这一点保证了在vector进行数据访问时,无需进行遍历容器的操作,直接利用下标访问即可,而且尾插尾删的效率高,这其实也是由于其支持下标访问所带来的优点,所以这个优点可以合并到支持下标随机访问里。另一个优点是由于其空间结构连续,CPU高速缓存命中率高。
2.
list作为一种结构体结点链接而成的数据结构,他的缺点就是空间结构不连续,CPU高速缓存命中率低,并且由于他的结构是不连续的,无法支持下标的随机访问,因为结点之间的地址并没有确切的相关联系,而vector能够支持是因为地址与地址之间相差存储元素类型个字节,通过地址的±整数就可以支持数组中任意位置数据的访问。但其最大的优点就是任意位置插入删除数据的时间复杂度都是O(1),并且不会由于空间扩容带来性能的消耗,这也是他的优势。
3.
通过上面所阐述的优点和缺点就可以看出为什么我们在模拟实现stack和queue的时候,分别采用vector和list来作为其适配容器,因为stack会频繁进行尾插、尾删、取vector尾元素,所以正好符合了vector的优点。而queue会频繁进行头删、所以正好符合list的优点。
4.
但是呢,vector作为stack的适配容器来讲,stack扩容的时候,会带来空间扩容的消耗,而list无法支持下标随机访问,那么能不能有一个容器将vector和list的优点都兼顾到呢?答案是有的,他就是双端队列deque。
2.deque的底层结构
1.
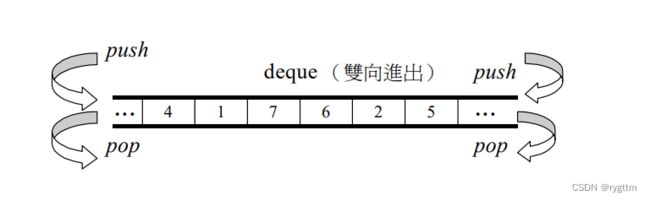
双端队列不仅支持了头尾的插入删除,还支持了下标的随机访问相比list,并且头插头删相比vector效率极高。
但deque并不是真正连续的空间,他是由一段段连续的空间组成的,你可以将它看作动态的二维数组。
2.
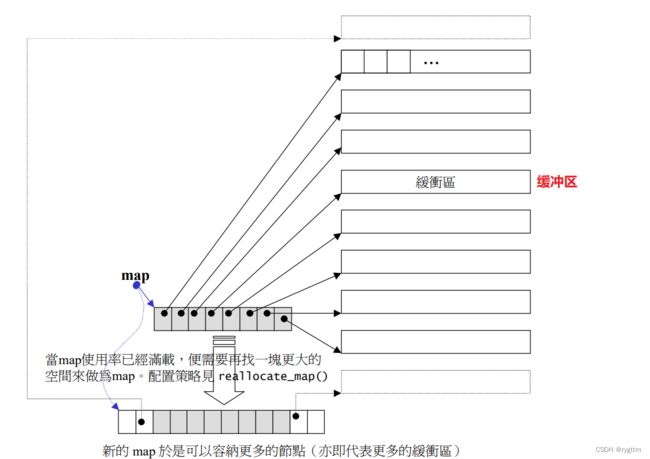
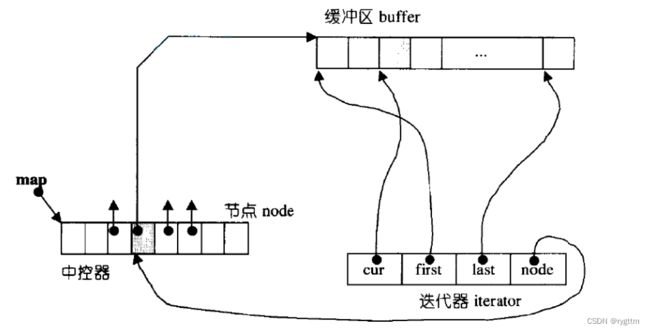
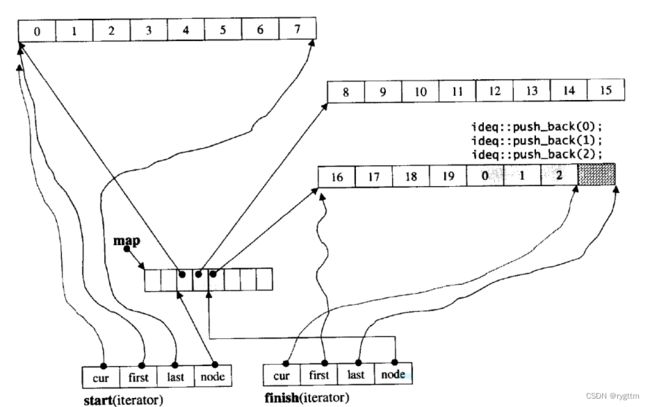
双端队列底层是一段假象的连续空间,实际是分段连续的,为了维护其“整体连续”以及随机访问的假象,重担子就落在了deque的迭代器身上,因此deque的迭代器设计就比较复杂,如下图所示:
3.
deque实际是通过一个中控指针数组来控制多段连续空间buffer的。
3.deque的优缺点
1.
与vector比较,deque的优势是:头部插入和删除时,不需要搬移元素,效率特别高,而且在扩容时,也不需要搬移大量的元素,因此其效率是必vector高的。
与list比较,其底层是连续空间,空间利用率比较高,不需要存储额外字段。
2.
但是,deque有一个致命缺陷:不适合遍历,因为在遍历时,deque的迭代器要频繁的去检测其是否移动到某段小空间的边界,导致效率低下,而序列式场景中,可能需要经常遍历,因此在实际中,需要线性结构时,大多数情况下优先考虑vector和list,deque的应用并不多,而目目前能看到的一个应用场景就是,STL用其作为stack和queue的底层数据结构。
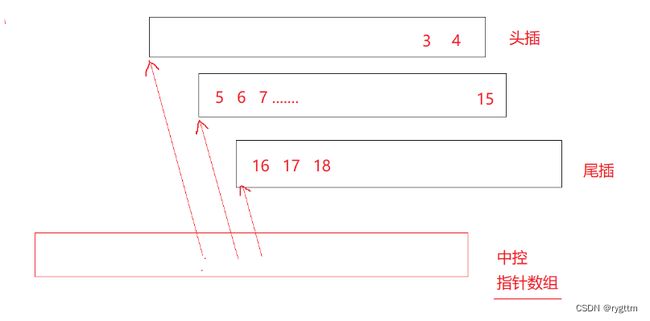
3.
deque在中间插入删除时,也是需要挪动数据的,只不过挪动数据的代价没有vector大而已。deque为什么头插头删效率高不用挪动数据呢?实际就是因为在头插的时候,deque又重新开辟了一块儿空间,让中控数组去控制这个新开辟的buffer,所以如果发生大量中间插入删除时,deque的效率相比list不够极致。
deque支持随机访问的效率实际也不够极致,因为他需要遍历中控数组判断数据在哪个缓冲区,然后在确定缓冲区的具体位置,所以他的随机访问效率相比vector来说也不够极致。
4.为什么选择deque作为stack和queue的适配容器?(vector排序快,list中间插入删除牛,deque吸取两个容器的部分优点)
1.
虽然deque与vector和list的优点来比较,哪个都比不过,但比他们的缺点时,又比vector和list强一些,所以这是一个比较中庸的容器,比上不足,比下有余。
2.
但用deque去作stack和queue的默认适配容器还是不错的,只要中间插入删除少,偶尔进行下标的随机访问,避开deque的缺点,deque用起来还是不错的。
而如果在使用时进行大量的随机访问,我们还是用vector容器,如果要进行中间位置大量的插入删除,还是用list容器。

3.
切记一点,不要用deque容器来进行排序,因为大量的随机访问会导致deque的效率极低,而库里面的sort算法用的又是快排,快排会进行三数取中从而导致大量的随机访问,所以不要用deque来进行排序,如果非要排序,建议将deque中的数据拷贝到vector,然后用vector来进行sort快排。
4.
这里也可以透露出另外一个知识点,vector的排序比list快的原因就是vector支持大量的随机访问,对于快排来说,vector这样的容器非常的友好,这也正是为什么我们喜欢用vector来进行排序的原因。