c语言数组输入n个字符串判断最短,六大算法设计技巧:贪婪法、分治法、动态规划、随机化算法、回溯法和分支限界法...
接上一节图论算法原理和实现,本节讨论六大算法设计技巧,前面的文章都是讨论数据结构及其算法,例如线性表、栈、队列、散列表、树、图等,其算法都是相对简单的,即使是相对复杂的图论算法,其主要算法都是基于DFS和BFS。这里说的算法技巧是什么样的概念呢?首先它是直接面向实际问题的,当使用基本的一些数据结构和算法无法解决的时候,那么就要考虑这六大算法设计技巧了,所以,和一般的数据结构和算法并没有什么不同。
而这些设计技巧一般都是针对难题的,当然也可以针对一般问题,首先要会设计一个算法,然后要保证设计该算法有好的时间界。即使保证不了好的世界界,你至少要保证对一个问题有一个解。另外要特别注意一点,虽然这里是讨论算法设计技巧,但是还是要有标准的数据结构的,没有封装好数据结构的代码可是很难看得懂。

一、算法设计的基础知识
设计算法的第一步不是直接写代码,第一步最重要的是准确描述当前面对的问题,一般来说,书上或其它面试题会提供问题的详细描述,但是在开发中却没人提供问题描述,这就要求自己能够准确描述问题了。因为如果你不理解问题,那么接下来编写代码将会非常糟糕,也可能会造成算法的非一般性。
首先来看数据结构、算法和有限状态机的关系,有限状态机和计算机密切相关。下面的内容非必要,看自己的需要或可直接跳到贪婪算法的部分。
1、有限状态机(finite-state machine,FSM或FSA)

有限状态机是指有限个状态以及这些状态之间的转移和动作,它是一种数学计算模型,有限状态机在任一时刻只处在一种状态中,我们用的计算机就是一个有限状态机。
状态机的组成
现态,指当前所处的状态;次态,指满足条件转移的新状态;条件,又称为事件,满足条件可能会执行的一个动作或状态转移;动作,满足条件后执行的动作行为或转移行为,转移就是一个动作。
状态机的工作逻辑
状态机中状态存储过去的信息,满足状态转移条件,执行一个转移动作,状态变更为下一个状态,动作是某一时刻进行的活动描述。如上面的状态转移图,在状态closed中输入一个open动作,这时进行状态转移,转移到状态opened,但是如果在状态opened中也输入一个open动作,也会响应,但是不需要转移状态。
状态机的分类
接受器或识别器是比较简单的状态机,也就做序列检测器,它根据输入回答是否被机器接受,参数一个“是或否”的输出,如下图是一个FSM接受器:
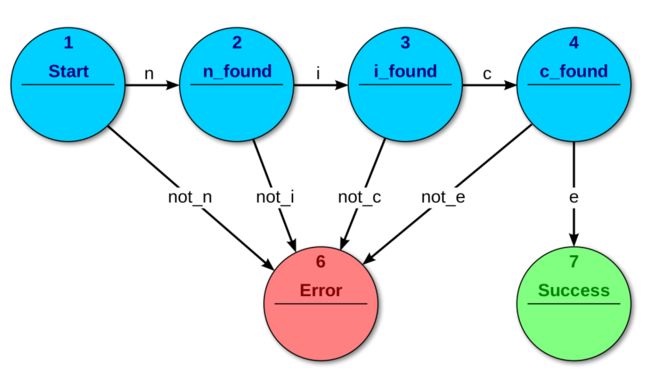
这个FSM接受器,检查字符串“nice”。这上面的图中,你可以看到一个状态机可以使用一个图(graph)表示,顶点表示某一个状态,边表示状态转移条件,有向边表示状态转移方向,没有入边的顶点为初始状态(初始状态也可以有入边),有入边的顶点为接受状态,或最终状态,接受状态接受一个合法的输入。
接收器的数学模型,用于表示当前状态和下一个状态的关系,假设S为非空状态集合,E为输入字母符号集合,状态转移函数为:f: S x E -> S,初始状态s属于S。
另一种状态机叫做变换器,它使用动作,根据输入或当前状态产生输出。其中又可分为Moore机和Mealy机,Moore机是只使用进入动作的FSM,输出只依赖当前状态。Mealy机是只使用输入动作的FSM,输出依赖于当前状态和输入。
每个状态对每个输入只有一种转移方式的状态机又称为确定型FSM,每个状态对每个输入没有或有多个转移方式的状态机又称为非确定型FSM,非确定型FSM可转为确定型FSM。
状态机的表示法
上面提到的使用一个图Graph表示FSM是一种常用的方式,另一种是使用状态转移表,表的横向为多个状态S,纵向为多个条件C,表示状态S条件C下转移到状态s。
状态机和算法的关系
计算机本质是一个有限状态机,算法是一种数据或抽象数据类型的运算规则,而数据的本质上来说是一种状态,算法的实现是实现某一种形式的状态机。
因而在设计算法之前可以使用状态机的方式表示或描述一个问题的解,下面是一些参考步骤:
确定数据的初始或边界状态,状态边界值。
状态的转移方式,这一步就是确定状态转移函数,假设状态空间为S,输入状态位E,当前状态属于S或SxE,主要是确定当前状态和下一个状态的关系。
状态转移方程,该方程是对某一状态机的完整描述,确定的状态关系包括边界状态,普通状态转移或某些特殊情况。
算法是根据状态转移方程实现状态机的自动运行,当然以上描述都是相当抽象的描述,后面介绍算法设计技巧的时候不一定严格按照这些步骤,因为我们还可以有其它更形象的描述。
2、问题、数据抽象和解
问题是由人对现实和期望的差异产生,也就是说,当产生需求的时候就会有问题了,算法在开发中就是解决需求问题。问题由自然语言描述,主要是对其意义的理解,必须有对问题的完整描述(不管是在脑中的描述还是自然语言描述),否则会导致不理解问题而不知如何解。
一个算法问题会有完整的描述,大抵可分为说明部分和问题部分,说明部分提供对问题的详细信息的理解,包含问题的主要数据信息。问题部分包含解的形式,提供问题的类型,如最优化问题或一般性问题,有必要将问题部分进行多次转化,尽量找到符合本节提到的六种算法设计技巧的基本模式(记住,一定要对问题有完整的理解)。
数据抽象
由问题的描述我们可以进行数据抽象,这一步我们可以得到数据实体的封装,或直接选择一种数据结构及其算法解决该问题,例如检查两个用户的共同好友,可以使用并查集直接解决,但如果还不能立即解决,那就需要继续分析该问题。
我们可以用状态向量表示一个数据实体,如x=(a1, a2, a3, …, am),a1到am为x的数据成员。数据集状态空间可表示为D={x1, x2, x3, …, xn},n为数据集D的规模,1到n为数据x在D中的索引或关键字i,那么一个数据x=S(i)。
解的形式
一个问题的解可用一个图或树表示,即解的状态空间树T,在该树或图中可找到问题的一个或多个解,树的特征可以使解可能获得更好的时间复杂度,树根表示初始状态,边表示状态转移。
结点表示问题的子问题的解或一个阶段的状态,求解问题的时候,我们常常都需要将问题分解为子问题,若问题是求q,则子问题或子步骤也是求q,子问题可根据规模n进行划分,不过难点还是在于如何划分子问题。
假设问题的解为y,假设y与x有关,y可能包含多个状态,即y={b1, b2, b3, …, bk}(解y的状态和数据x的状态并不同),也就是y=f(x),其中x=S(i),y=f(S(i))=f(i)(x也可能有多个索引或关键字,即y=f(I, j, k, …))。
那么对于求解问题的状态方程,首先是边界状态,可表示为f(K)=M,K为边界集,转移方程可表示为f(i+1) = g(f(i)),也需要考虑一些特殊的情况。
3、算法设计
综上,求解一个问题的时候,首先是理解问题,确定问题的类型,看看是否能对应本节的六大算法技巧之一。然后对问题中的信息进行抽象,结构化问题中能提供的数据,若能使用已知的算法解决则直接使用,否则进一步进行详细的算法设计。在分析问题的时候,尽可能构建一棵状态空间树,并找出状态转移方程。
以上的一大堆内容不一定对你有帮助,这里是出于严格,只有在你掌握好设计技巧自然没问题了,否则,最好要保证问题有解,然后再保证好的时间界,因为连问题都不会解那就没什么意义了。
二、贪婪算法(greedy algorithm)
1、贪婪算法的基本概念
使用贪婪算法在求解问题的时候,总是做出在当前看来是最好的选择,贪婪算法不从整体最优考虑,它是某种意义上的局部最优解,但是使用它仍有可能得到整体最优解,或最优解的近似解。如上图,如果一个问题能分解成多个子问题,那么贪婪算法在求解每个子问题的时候都是根据当前情况使用最优选择。
贪婪算法在不需要最佳解的时候,是一种高效算法,但是如果需要绝对最优解,则需要证明才能使用,贪婪算法一般是用作问题的辅助算法或一些结果不太精确的问题,如果用贪婪算法不能解决的时候可以考虑使用动态规划。
这是一种很直觉式的算法,通俗的来说第一印象就是优先找出第一个最优解。例如找零钱问题,给定零钱c,要求找出一种方式使得纸币或硬币最少。运用贪婪算法就是:不管如何先尝试使用最大值的纸币找钱,如果大于c再尝试第二最大值纸币。
其它应用贪婪算法的例子还有:Dijkstra算法、Prim算法、Kruskal算法、找零钱问题、任务调度问题、汽车加油问题等。一般来说最优化问题都可以考虑使用贪婪算法。
贪婪算法在状态机中的描述是:每个阶段的最优状态由上一个阶段的最优状态得到,解的状态集结构为线性表的形式。
贪婪算法的特征:通过一系列最优解得到最终解;问题的最优解包含子问题的最优解;一般都是使用for或while迭代循环;优化算法可以使用优先队列。
贪婪算法的一般模式为:使用while或for迭代求解,求解每个子问题,并得到子问题的最优解y,合并每个最优解y得到最终解。
2、背包问题
问题描述:给定n个有重量w和价值p的物品,以及一个容量为c的背包,要求装物品进背包,使得其价值最大。
可选的贪婪策略如下:
优先选择最大价值的物品
优先选择重量最小的物品
优先选择价值密度最大的物品,价值密度=价值/重量
我们可以将物品按照贪婪策略放入一个优先队列中,要注意的是对于该问题应用贪婪策略不一定得到最优解,但可以得到近似解。
下面的算法使用优先价值密度的贪婪策略,其中主要贪婪算法部分的代码如下(完整源码请到github查看:贪婪算法求解背包问题):
// 贪心算法求最大价值
float knapsack_max_price(Knapsack *knapsack){
if(knapsack == NULL || knapsack->size == 0)
return 0;
GNode *node;
float max_price = 0;
while(!knapsack_is_empty(knapsack) && knapsack->left_capacity > 0){
node = knapsack_top(knapsack);
if(node->flag == Available && node->good.weight <= knapsack->left_capacity){
max_price += node->good.price;
node->flag = Chosen;
knapsack->left_capacity -= node->good.weight;
}
else
node->flag = Invalid;
knapsack_pop(knapsack);
}
return max_price;
}
这里的实现使用最大二叉堆封装数据,以上是贪婪算法相对规范的写法,而且要记住优化的贪婪算法一般都会考虑使用优先队列,如果你使用其它高级语言如Java、C++可以直接使用内置的二叉堆或优先队列。
3、Huffman编码
Huffman是用于文件压缩的,对于huffman编码是如何应用贪婪算法的还有一段距离,我们首先需要理解一些涉及编码的基本概念。
我们在编程中使用的字符串其编码一般是使用ASCII字符集进行编码,当然还有其它字符集可用,假设一个字符集的大小为C,则需要使用logC个比特位才能完全表示这些字符,单纯使用ASCII字符集编码会造成文件很大。
例如ASCII字符集有256个字符,使用大小为8位即1个字节保存一个字符,存储每个字符都使用1字节将会非常浪费空间。
文件压缩使用字符出现的频率进行调节,让代码的长度从字符到字符的变化不能,同时保证经常出现的字符其代码要短,如果字符出现的频率一样,那么很难节省空间。这也就是说,存储每个字符的时候尽量使用变长的位数储存。
Trie树,huffman编码使用一个trie树对数据进行编码,trie的例子如下图:

Trie树从根结点开始,0表示左分支,1表示右分支,叶子结点表示一个字符,以记录路径的方式给字符编码,在trie树中有以下几个重要概念:
结点路径长:根结点到该结点的边数。
树的路径长:所有叶子结点的路径长之和,叶子结点的路径长等于树的高度d,也就是一个字符的编码数。
结点带权路径长:结点的权值为字符出现的频率w=f,带权路径长=d x w,等于一个字符的总编码数。
树的带权路径长:所有叶子结点的带权路径长。
那么如何使压缩文件体积最小呢?就是求一个树的带权路径长最小的trie树了,也就是求文件压缩的最小编码。我们让权值最小(出现频率低)的字符在最深结点,权值最大的字符深度最小,这样就可以保证带权路径长最小。

Huffman算法步骤,请参照上图,假设字符数为C,huffman算法围绕由树组成的深林进行,选取最小权值的两棵树T1和T2组成一棵新树,重复镜像C-1次,初始化时有C棵单结点树(如上图的第一步),最终将生成最优huffman树,其算法详细步骤如下:
按照字符的频率使用优先队列构建C个字符结点(最小堆)。
从优先队列中取出两个结点:L和R。
创建一个新结点T作为根结点,左右儿子分别为L和R。
将T放入到优先队列中。
重复以上操作,知道队列只剩下一个元素,这个元素就是trie树的根结点了。
以上使用优先队列实现的huffman算法时间复杂度为O(ClogC),如果只是使用链表实现优先队列,则时间复杂度为(C^2)。下面是使用C语言的huffman算法的编码实现(简单起见,这里只实现编码的部分),注意这里只贴出使用了贪婪算法的代码(完整源码请到github查看:贪婪算法生成trie树、实现huffman算法):
void huffman_encode(char *string){
if(string == NULL || strlen(string) < 1)
return;
char ch[256];
memset(ch, 0, 256);
// count frequencies of char
for (int i = 0; i < strlen(string); ++i)
ch[string[i]]++;
int length = 0;
for (int k = 0; k < 256; ++k)
if(ch[k] != 0)
length++;
// create single node tree
Heap *min_heap = new_heap(length, compare);
for (int j = 0; j < 256; ++j) {
if(ch[j] != 0){
CNode *node = malloc(sizeof(CNode));
node->ch = j;
node->w = ch[j];
node->left = node->right = NULL;
heap_push(min_heap, node);
}
}
// create trie tree/huffman tree
CNode *left, *right;
while(min_heap->size != 1){
left = heap_top(min_heap);
heap_pop(min_heap);
right = heap_top(min_heap);
heap_pop(min_heap);
CNode *root = malloc(sizeof(CNode));
root->ch = -1;
root->w = left->w + right->w;
root->left = left;
root->right = right;
heap_push(min_heap, root);
}
// traverse huffman tree
CNode *_root = heap_top(min_heap);
heap_clear(min_heap);
Pair pairs[256]; // 可用散列表代替
char chs[258];
memset(chs, '\0', 258);
dfs(_root, pairs, chs);
// print huffman code
int count = 0;
for (int l = 0; l < strlen(string); ++l) {
// printf("[%c]%s ", string[l], pairs[string[l]].code);
printf("%s", pairs[string[l]].code);
count += strlen(pairs[string[l]].code);
}
printf("\nafter coding amount of bit: %d, to original: %d, compression rate: %.3f", count, strlen(string) * 8, count / ((float)strlen(string) * 8));
printf("\n");
huffman_tree_clear(_root);
}
以上算法主要是涉及使用优先队列或堆,另外还有还有一个地方可以使用散列表,另外如果你查看github上的完整源码,里面还使用DFS遍历huffman树,这个其实就是一个回溯算法,回溯算法在下面会讲到。
虽然这里没有提供huffman编解码的完整实现,不过这里还是给出一个参考思路:
首先读取文件字符(文件又可分为文本文件和二进制文件)。
搜索并统计字符的频率。
使用huffman算法对文件进行编码,先生成huffman树。
对于编码,我们需要遍历huffman树得到编码字符,将编码字符写入硬盘。
并且对于写入硬盘的数据需要构造文件头信息表,提供编码信息、文件类型、字符数C等。
对于解码部分,首先读取编码文件字符,根据文件头进行解码,根据编码字符构造huffman树,遍历huffman树还原文件内容。
4、近似装箱问题
这个问题是这样的:给定n项物品,每个物品的大小为si,其中1<=i<=n,0
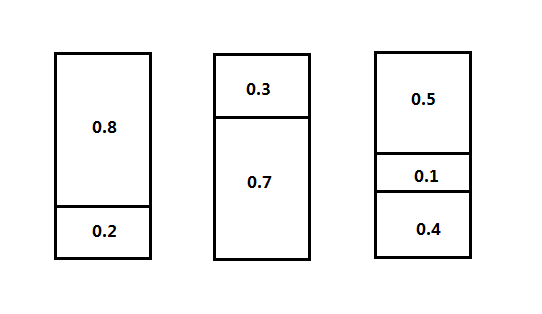
下面我们按照算法的执行环境讨论解决这个问题的两种算法:联机算法和脱机算法,联机算法是算法在任意时刻读入数据一次,并被立即处理给出解;脱机算法是一种离线算法,也就是先完全输入全部数据,然后一次性处理并得到解。
联机算法,允许无限计算的情况下是否总能给出最优解,也就是任意时刻放入一件物品,再处理下一件,而且不能改变决定,需要保证联机算法在任意时刻成立,但是联机装箱问题不存在最优算法。
存在使得任意联机装箱算法至少使用4/3最优箱子数的输入,在联机算法中,有三种算法能保证所用的箱子数不多于两倍的最优箱子数。
下项适合算法:
按顺序处理一件物品时,检查它是否能装进箱子。能装进则放入箱子,否则开辟一个新的箱子。
下项算法所用的箱子数不超过最优箱子数的2倍,时间复杂度为O(n)。
存在一些物品序列使得该算法所用的箱子数为2M-2,M为最优箱子数。
首次适合算法:
依次扫描箱子,若遇到第一个能放下物品的箱子则放入其中。若放不下,则开辟一个新的箱子。
该算法保证解最多为最优箱子数的2倍,箱子数不多于17/10M,时间复杂度为O(n^2)或O(nlogn)。
该算法用的箱子大约比最优箱子数多2%。
最佳适合算法:
和首次适合算法类型,但不是放入第一个能放入的箱子中,而是放入能放入的最满箱子中(空间最小)。
比起最优算法,不会坏过1.7倍左右,时间复杂度和首次适合算法一样,为O(nlogn)时表现更好。
脱机算法,先将物品进行降序排序(非增,从大到小),然后应用首次适合算法,又叫做首次适合递减算法,使用该算法使用的箱子数不超过(4M+1)/3;或者使用最佳适合算法,又叫做最佳适合递减算法。
我们这里主要面向的是脱机的情况(和联机算法也差不多),使用首次适合递减算法,实现的贪婪算法一般步骤为:
先对物品进行降序排序,这里可以直接使用快排。
创建一个最大堆,装入箱子,关键字(权值)为箱子的剩余容量。
循环取出物品s,从堆中取出堆顶的箱子t,若t能装进s则装入,否则(包括堆中为空的情况)则创建一个新的箱子。
处理完成后,重新将箱子t入队。
重复以上过程,直至处理完所有的物品。
这里使用一个最大堆,因而时间复杂度为O(nlogn),下面是使用C语言实现的主要代码部分(完整实现请查看github项目:近似装箱问题):
int binpacking(double capacity, Item items[], int n){
if(capacity < 0 || items == NULL || n < 1)
return -1;
qsort(items, n, sizeof(items[0]), q_compare);
Heap *max_heap = new_heap(n, compare);
Box *box;
for (int i = 0; i < n; ++i) {
box = heap_top(max_heap);
if(box == NULL || items[i] > box->left){
box = (Box*)malloc(sizeof(Box));
box->capacity = box->left = capacity;
box->left -= items[i];
heap_push(max_heap, box);
}
else{
box->left -= items[i];
heap_max_decrease_key_just(max_heap, 0);
}
}
int size = max_heap->size;
for (int j = 0; j < size; ++j)
printf("%.2f ", ((Box*)(max_heap->array[j].value))->left);
printf("\n");
heap_clear(max_heap);
return size;
}
要注意的问题是,上面使用float单精度表示小数的时候可能会出现一些误差,误差会造成计算出的结果是过大的,可以尝试使用双精度double,若仍有误差可以约定一个误差范围或者将所有的数扩大100倍计算。
三、分治算法(divide and conquer)
1、分治算法的基本概念
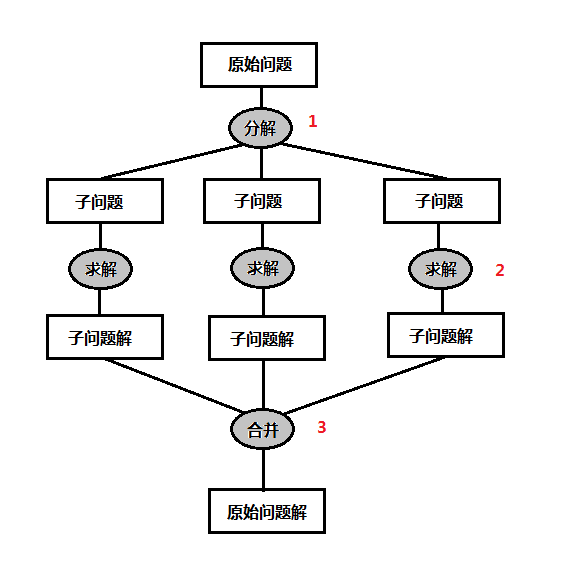
分治算法是将一个难以解决的问题,分解成规模较小的相同问题进行求解得到问题的解,分治算法也是一个很好的算法策略,但是时间界还是要看具体的问题而定,直觉的说,分治算法就是问题可在宏观上分部分解决。
分治算法一般由三步组成,如上图所示,首先第一步是将问题分解成子问题进行递归解决,子问题与原问题的形式相同;第二步是根据子问题求解得到子问题的解;第三部是合并问题的解,这一步通常需要详细考虑或进行技术性的处理。
分治算法的解析,首先要注意递归算法不等于分治算法,分治算法至少包含两个递归,只含有一个递归的不是分治算法。另外所谓的子问题一般就是指按照问题规模n划分为最小可解决的问题规模,而这一步需要对数据进行分类处理,采取何种分类依据按照具体问题而定,例如可能需要预先排序数据。而合并问题的解这一步有可能没那么简单,有可能需要分析各个子问题解的关系,同时要注意合并问题解所用的时间。
分治算法的时间复杂度,一般地可表示为T(n)=aT(n/b)+n^k,其中n为问题规模,a为递归调用的次数,也就是求解子问题的次数,b为对问题规模的分解次数或对问题的划分次数,k为合并解的时间的指数,如下图:
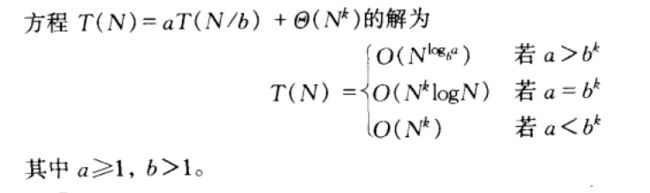
下图是分治算法是上面时间复杂度定理的推广:

分治算法的应用例子,如最大子序列和问题,选择问题(使用五分化中项的快速选择算法的运行时间为O(n)),求两个(已排序)数组的中位数,树的遍历,归并排序和快速排序,快速傅里叶变换等。
分治算法的基本特征:
问题缩小到一定程序可以很容易解决,大多问题都能满足这个条件,可以试着缩小问题规模n进行简单求解,这可以得到子问题的一般形式。
最优子结构,问题可分解为k个相同的子问题,这是分治算法的前提,大多问题也满足。
利用子问题的解合并为问题的解,这是分治算法的关键,不满足这条可以考虑贪婪算法或动态规划。
子问题之间是相互独立的,不包含公共子问题(其实包含也没关系),但是包含公共子问题使用动态规划会更好。
分治算法的一般模式:
和递归算法形式类型。
若当前问题规模p <= n0,进行求解,其中p为子问题的规模,n0为阀值,表示当问题规模小于等于n0时问题可以容易解出。
若p>n0,则将问题分解成k个子问题,递归求解k个子问题。
合并k个子问题的解。
2、最近点问题
这个问题是这样的:对于平面上的点集P,点p1=(x1,y1),点p2=(x2,y2),p1和p2的欧式距离为[(x1-x2)^2+(y1-y2)^2]^1/2,问题是找出任意一对距离最短的点,若p1和p2在同一位置则距离为0,这个问题可以求最小距离值或求这对顶点。
分治算法:首先我们先对点集P中点的x坐标进行排序,这是因为应用分治算法这里选择按照x坐标的范围进行划分。
那么如何分解问题呢?我们可以将点集按照x坐标的排列分为左右两部分PL和PR,中间区域为PC,这样最短对要不都在PL或PR,或一个在PL一个在PR也就是PC中。
分别递归求左右两部分PL和PR的最小距离dl和dr,那么只要求得dc我们就可以得到最小的点对距离了。令m=min{dl, dr},那么此时PC区域的宽度为2m,求dc我们可以只计算那些x坐标限制为2m这个区域以内的点(因为如果dc要比m还小,x坐标只能相差m,如下图)。
而对于PC区域任意两点的y坐标(PC又称为带),因为并没对y坐标分区,所以基准在哪里无法确定,但是我们可以确定该区域内任意两点的y坐标相差不大于m,假设大于m的话,那么算出来的dc一定大于m。

我们可以使用线性的方式求解dc,并更新m,求出的m也就是子问题的解了,求所有m的最小值就该问题的解。
下面我讨论上面算法的时间复杂度,你可以参考上面的分治算法时间复杂度定理进行判断,首先这里是将问题进分为两部分,并且需要调用两次,因而a和b都是2,假设不对y坐标进行排序的话,那么计算dc需要O(n^2),因而k=2,也就是a
如果使用对x和y坐标进行排序的的表P和Q(预先排序),则时间复杂度可以达到O(nlogn),同样的计算dc和O(n^2)是一样的,同样也是要求y有序,只是预先排序了,多花费一些空间而已。
这里还差一个边界条件,当n=1的时候可以返回INIT_MAX,如果只有两个点n=2,直接求这两个点的距离,如果有三个点,同样可以直接求最短距离。
下面使用C语言解决最近点问题,这里主要是求最小值(求点对可以使用一个结构体或对象),下面是主要的分治算法部分(完整源码请查看github项目:分治算法解决最近点问题):
static double _shortest_distance(Point points[], int left, int right){
if(left == right)
return INT_MAX;
if(left + 1 == right)
return distance(&points[left], &points[right]);
if(left + 2 == right)
return min(min(distance(&points[left], &points[left + 1]), distance(&points[left], &points[right])),
distance(&points[left + 1], &points[right]));
int center = (left + right) / 2;
double c = points[center].x;
double dl = _shortest_distance(points, left, center);
double dr = _shortest_distance(points, center + 1, right);
double m = min(dl, dr);
Point Q[right - left + 1];
int n = 0;
for (int k = left; k <= right; ++k) {
if(fabs(points[k].x - c) < m)
Q[n] = points[k], n++;
}
qsort(Q, n, sizeof(Point), compare_y);
// O(n)
for (int i = 0; i < n; ++i) {
for (int j = i + 1; j < n; ++j) {
if(Q[j].y - Q[i].y > m)
break;
if(distance(&Q[i], &Q[j]) < m)
m = distance(&Q[i], &Q[j]);
}
}
return m;
}
以上算法的效率可以达到O(nlogn),主要是由于对y坐标排序的处理。
3、长整数相乘
整数相乘是用于求两个n位数X和Y相乘。
使用分治算法分析该问题:我们可以将X和Y分别分成两部分XL和XR、YL和YR,这时X=(XL)P + (XR),Y=(YL)P + (YR),则XY=(XL)(YL)Q + [(XL)(YR) + (XR)(YL)]P + (XR)(YR),这个算式一共包含4次乘法,其中P是10的k次方,Q是10的2k次方,k=n/2。
这样将两个数分成了两部分,使用4次递归调用,这样时间复杂度就是O(n^2)了,这样的效率其实并不好,但是可以稍微减低一下,减少一次递归调用,上面的式子中一项可以使用其它项代替,即:(XL)(YR) + (XR)(YL) = (XL – XR)(YR – YL) + (XL)(YL) + (XR)(YR),这样时间就可以达到O(n^1.59)。
合并解中主要是计算P和Q的部分,也就是添加0,这需要使用O(n)的附加时间,也就是k=1(时间复杂度定理中的k),最后XY的值也就完成了。
这里要注意,这个分治算法并不是最好的算法,但是会比二次算法更好,也不是常用的算法,但是这里还是要动手实现,主要是要练习分治算法。
当然还有边界情况,当两个乘数都是1位数的时候,返回两个数相乘的结果,为0则直接返回0。
下面是使用C语言实现的整数乘法,更详细源码请查看github项目:整数乘法。
static long multi(long X, long Y, int n){
if(X == 0 || Y == 0)
return 0;
if(n == 1)
return X * Y;
long P = (long)pow(10, (double)n / 2);
long Q = P * P;
long XL = X / P;
long XR = X % P;
long YL = Y / P;
long YR = Y % P;
// XL * YL * Q + ((XL - XR) * (YR - YL) + XL * YL + XR * YR) * P + XR * YR;
long XLYL = multi(XL, YL, n / 2);
long XRYR = multi(XR, YR, n / 2);
long XLXRYRYL = multi(XL - XR, YR - YL, n / 2);
return XLYL * Q + (XLXRYRYL + XLYL + XRYR) * P + XRYR;
}
以上算法其实用性就暂时不考虑了,比如如果两个数的位数不同,这里特别提一下分治算法的一般模式。由上面两个例子你可以看到,首先肯定是分析问题并且对问题进行划分,然后还要考虑合并解的问题,最后要考虑边界情况。
分治算法的算法模式和树的DFS遍历是类似的,或者说就是以划分问题为主的DFS遍历,一旦你正确地划分了问题,那么解决问题的重点就在于处理合并解和边界情况。
回想一下归并排序和快速排序两个分治算法,你可以发现这两个算法模式似乎并不相同,但是我们参考一下树的DFS遍历,DFS遍历中又有先序遍历、中序遍历和后序遍历(都是以根结点为参考点)。
如果先对问题进行处理,再进行划分递归调用,那么就是DFS先序遍历,快速排序的一般形式就是先序遍历。如果先划分递归处理问题,再处理问题,那么就是DFS后序遍历,归并排序和上面的两个例子也是DFS后序遍历。
边界情况是比较容易考虑的,只需要将n缩小到边界情况就可以得到。划分问题则稍微困难,这个给出的方式就是:对数据进行分类,分类就包括排序,又如快排中的“大的一类和小的一类”。
这里有个小小的建议是,记住归并排序和快速排序的一般形式,因为这两个算法是非常经典的分治算法。
4、矩阵乘法
该问题是求两个n x n矩阵A和B相乘,解决这个问题的一般运算时间为O(n^3),下面介绍的分治算法又称为Strassen算法,不过该算法的适用性仍然有限,但是证明任何看似其复杂度是固有的算法,仍然有可能得到进一步的优化,下面主要使用分治算法的思想进行解释,但不给出实现。
首先分治算法的第一步是对n进行划分,这里是将每个矩阵分成4部分,也就是AB两个矩阵一共有8部分,即8个n/2 x n/2的矩阵,问题变成了计算8个n/2矩阵的乘法,以及4个n/2矩阵的加法,也就是需要8个递归调用,规模按照n/2划分,下面是分解的图解:


这里可以使用类似于上面整数乘法中的简化策略,将递归次数降低到7次,此时其时间复杂度为O(n^2.81),这里计算4个n/2矩阵的加法使用时间为O(n^2)。
四、动态规划(dynamic programing)
1、动态规划的基本概念
动态规划可以说是这几个算法设计技巧里面最重要的一个,适当运用动态规划可以获得惊人的效率。使用动态规划解决的问题一般要求问题具有最优子结构和重叠子问题,不过这个这里想侧重的是数学形式化,运用归纳法使用动态规划可以将一个问题的解数学形式化了,下面我们会进行详细讨论。
动态规划是将多阶段问题转化成一系列的互相联系的单阶段决策问题,然后逐一解决。这仍然是分类的问题,人为地引入时间因素,我们可以将问题按照时段划分并转化为多阶段的动态模型,时间划分是指执行的时段,另外一个划分是引入空间因素进行划分。
动态规划将问题分为多个单阶段(按照问题的规模n划分),各个单阶段互相联系,我们可以将子问题的解存储在一个表中,以后用到可以直接使用,这样可以避免重复计算并且节省时间(注意区分子问题是很重要的)。
动态规划的特征:
问题状态需要满足最优化原理,也就是每个阶段的最优状态只由之前的状态得到,或又称为最优子结构,一个问题的解包含子问题的最优解。
问题中的状态需要满足无后效性,不管以前的状态是如何得到的。
重叠子问题,这样子问题的解可以被多次使用。
动态规划算法由以下几个步骤完成:
动态规划分析或划分阶段:刻画最优解的结构特征,也就是划分问题,分析最优解的结构,可以按照时间或空间特征划分,可能需要划分后是阶段是有序或可排序的。这里有个简单的小技巧,可以将问题规模按照“选或不选”递推出最优解,或使用二分法将解限制在某一部分,或者使用左右双索引进行逼近。
简单地说这一步就是设子问题的解为S(i)或S(i, j),i、j一般和n有关。
使用归纳法推导状态转移方程:使用归纳法是很简单的,我们首先是确定状态和状态变量,根据问题提取影响子问题解的变量。
确定状态方程主要是考虑边界情况和一般情况,一般完成这一步后,一个递归形式的解就得出来了,但是这还不能有好的效率。
动态规划的实现:其实现都是使用表T存储每个子问题的解,上面预设的子问题解为S(i),则表的每个元素为T(k)=S(i),也有可能是一个二维表。
使用表的情况下也有两种方法,一种是使用递归算法(又称为自上而下),另一种是自下而上,从基准情况开始计算解。另外也可以不用表,直接使用自下而上的迭代法,这里的上下类似于下面开始讨论的斐波那契数列的树表示形式,从上而下是从根结点开始向下推导,从下而上是从树叶开始推导。
动态规划的时间,运行时间和子问题数和解决每个子问题的时间有关,假设子问题数为t,解决每个子问题的时间为H,则动态规划时间为O(tH)。
动态规划的应用例子,如背包问题、最长公共子串问题、最长回文子串、导弹拦截问题、最大化投资回报问题等。
2、数值问题
这里给出的数值问题是应用动态规划的一些经典形式,可以帮助你更好理解动态规划。
首先第一个问题是计算斐波那契数,斐波那契数列是这样的:
fib(i)=1,当i<=2的时候。
fib(i)=fib(i-b)
+ fib(i-2),当i>2时。
动态规划求解:首先第一步是设子问题的解,在这里很明显就是fib(i),第二步是确定状态方程,上面给出的两个式子就是本问题的状态方程了,到这里已经可以使用递归算法求解了,但是动态规划还有一个特点,就是重用子问题的解。
一般地,写成递归形式的状态方程很有可能有重复的子问题,必须要明白子问题指的是什么,在这里假设求解的是fib(n),那么子问题就是fib(i),假设n=5,以上问题解的状态空间树如下:

我们可以看到,因为i<=2的时问题已经可以直接解,当n=5的时候就只有4个子问题,如fib(2)如果用递归算法的话,需要计算3次,但是动态规划可以使用一个表S储存,S的大小一般和子问题的大小一样。
下面使用表的方式和迭代的方式计算斐波那契数,表的方式相对直观一些,但是迭代的方式更好,只是以后用到动态规划直接使用迭代是有些困难的,这种情况不妨试着使用表。对于递归算法和不用动态规划的递归形式是一样的,只是使用了表储存解。
使用一般递归算法计算斐波那契数的时间复杂度为O(2^n),这里子问题只有O(n)个,使用动态规划则只需要O(n)的时间,下面是使用C语言实现的动态规划算法(更多代码可以查看github项目:动态规划计算斐波那契数):
int fib_table(int n){
int table[n];
table[0] = table[1] = 1;
if(n - 1 <= 1)
return 1;
for (int i = 2; i < n; ++i) {
table[i] = table[i - 1] + table[i - 2];
}
return table[n - 1];
}
extern int fib_terative(int n){
if(n <= 2)
return 1;
int fib1 = 1;
int fib2 = 1;
int fibn = 0;
for (int i = 3; i <= n; ++i) {
fibn = fib1 + fib2;
fib2 = fib1;
fib1 = fibn;
}
return fibn;
}
第二个例子也是一些数值计算的问题,其实和计算斐波那契数差不多,它的定义如下:
C(i)=1,当i=0时。
C(n)=(2/n)*sum(C(i),
{i,0,n-1})+n,其中sum是求和运算,后面的大括号表示i从0到n-1。
使用动态规划求解,三个步骤:第一步是定义子问题,这里已经有定义了,第二步是确定状态方程,这里也已经有了,第三步是实现,这个问题可以使用迭代的方式实现,如果是这样的话还是建议画一下求解树分析一下会比较好,或者就用表,使用表其实和状态方程形式是差不多的,该问题可以使用O(n)的时候求解,但是这里就不给出实现了,有兴趣的朋友可以动手试下。
3、矩阵乘法
该问题是这样的,n个矩阵相乘A1A2…An,求矩阵相乘的最少乘法次数,可以通过相乘的顺序安排获得最少乘法次数,也就是通过加括号的方式(不熟识矩阵相乘的话可以去百度百科看一下定义,以便好理解该问题)。
首先我们看一下为什么加括号可以获得更好的解,例如A:5×4、B:4×6、C:6×9三个矩阵相乘,若为(AB)C则乘法次数为:5x4x6+5x6x9=390,若为A(BC)乘法次数为:5x4x9+4x6x9=396,所以存在一种括号化的方式,使得矩阵相乘的乘法次数最少。
下面使用动态规划的三个步骤解决该问题,第一步是设置子问题解,这里可以设m(i,j)为第i个矩阵到第j个矩阵的最小乘法次数,下一步是确定状态转移方程:
对于i=j的情况,m(i,j)=0。
对于i
这样m(i,j)=min{min(i,k) + min(k+1,j) + pi-1 pk pj},最后一项中,Ai的大小为pi-1 x pi,pi-1为Ai的行数,pi为Ai的列数,pi-1 pk pj表示最后两部分两个矩阵相乘的乘法次数。
第三步是算法的实现,这里可以使用自底向上的方式:使用表或者直接迭代,不过这里有个k,我们需要给予k从i到j的一个迭代。
这里的实现不实现矩阵相乘,只实现这个括号化算法,所以输入仅仅是n个矩阵的行列的大小数组,我们可以使用s(i,j)存储加括号的位置,s(i,j)表示第i个矩阵到第j个矩阵加括号的最好位置。
下面使用动态规划计算矩阵乘法的最优位置的主要算法部分(可查看github项目:最优矩阵乘法):
/*
* {2, 3, 5, 9, 6, 7} => A0:2x3 A1:3x5 A2:5x9 A3:9x6 A4:6x7
* n is size of the matrix
* assume [0][4]=1 => (A0 A1)(A2 A3 A4)
*/
void matrix_opt(const int *m, int n, int *s){
if(m == NULL || n - 1 < 3 || s == NULL)
return;
int p[n * n];
for (int x = 0; x < n; ++x)
p[x * n + x] = 0;
for (int l = 1; l < n; ++l) {
for (int i = 0; i < n - l; ++i) {
int j = i + l;
p[i * n + j] = INT_MAX;
for (int k = i; k < j; ++k) {
int q = p[i * n + k] + p[(k + 1) * n + j] + m[i] * m[k + 1] * m[j + 1];
if(p[i * n + j] > q){
p[i * n + j] = q;
s[i * n + j] = k;
}
}
}
}
}
这里解释一下代码,其中l是步长,从步长l=1开始计算,也就是两个相邻矩阵,因为这是最基本的情况,i从0开始,i最大情况为n-l。以上动态规划最特别的地方是使用了步长,注意多一个中间k变量的情况都可能会用到这种模式,所以不妨花点时间理解一下这个代码,下面的几个例子都会有k的情况。
4、最优二叉查找树
这个最优二叉查找树和上面提到的huffman树有点类似,它是这样的:
存在n个单词或关键字wi,及其对应的出现频率pi,其中wi一般称为关键字,pi又称为概率。
这里的问题是求期望存取时间最小的二叉树。
其中每个单词或关键字在树中的深度为di,也就是访问每个单词或关键字wi需要执行di+1次。
构造这个最优二叉树可表示为M值最小的树,M=sum{pi*(di + 1), {i, 1, n}},这里M表示运算次数,和huffman树类似求该树就是求M最小。
运用动态规划构造最优二叉查找树的具体算法步骤如下:
设n个单词或关键字序列中,存在子序列也有最优解,也就是其子树的构造M也是最优的,即子树的结点为:wi, wi+1, …, wj-1, wj,wi为关键字升序序列。
这里设最优二叉查找树的根为wk,这个设法和上一个例子类似的,其中i<=k<=j。
设结点i到j的最小运算代价为m(i, j),根为第k个结点,则可得到以下的状态方程:
m(i, j)
= pi,当i=j时。
m(i, j)
= min{1 * pk + sum{pi*(dl+1), {l,i,k-1}} + sum{pi*(dr+1), {r,k+1,j}}},当i
上面的式子又可表示为:m(i, j) = min{ m(i, k – 1) + m(k + 1, j), {i<=k<=j} + sum{pt,
{t, i, j}}}。
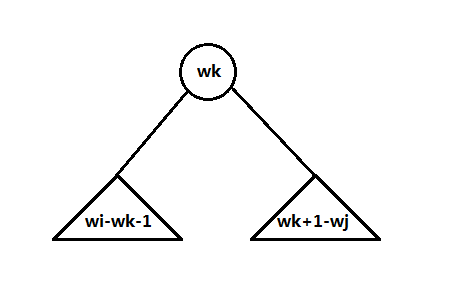
下面就是实现了,核心算法模式还是模仿上面一个例子的形式,注意有k变量的情形应用也较多,对于这种情况一般就是使用步长来控制。你可以使用标准的二叉树定义形式,也就是使用结构体或对象储存关键字、数据、左右儿子等,也可以只使用一个数组,下面是使用C语言实现的核心代码(完整源码可查看github项目:最优二叉查找树):
// core algorithm for creating optimal binary search tree
void optree_build(Optree *optree){
if(optree == NULL || optree->n == 0)
return;
// qsort(optree->list, optree->n, sizeof(ONode), compare);
int n = optree->n;
double m[n * n];
int s[optree->n * optree->n];
for (int i = 0; i < optree->n; ++i) {
m[i * n + i] = optree->list[i].p;
}
int j;
double psum;
for (int l = 1; l < optree->n; ++l) {
for (int i = 0; i < optree->n - l; ++i) {
j = i + l;
m[i * n + j] = INT_MAX;
psum = 0;
for (int x = i; x <= j; ++x) {
psum += optree->list[x].p;
}
for (int k = i; k <= j; ++k) {
double q = m[i * n + (k - 1)] + m[(k + 1) * n + j] + psum;
if(m[i * n + j] > q){
m[i * n + j] = q;
s[i * n + j] = k;
}
}
}
}
optree->root = build_tree(optree, s, 0 , optree->n - 1);
}
Github完整源码提供输出的是使用BFS打印该二叉树,但是总是感觉不太对,就不继续调试了,如有错误欢迎指正。
5、所有点对的最短路径
这是一个图论算法中的最短路径问题,这里是求有向有权图G的所有点对的最短路径,允许有负值边,但无负值圈。
动态规划求所有点对的最短路径的具体算法步骤如下:
设Dk(i,j)表示第i个顶点到第j个顶点可能包含{1, 2, .., k}而不包含其它顶点的路径,Dk(i,j)表示的是最短路径。如D0(i,j)直接表示i和j之间的距离,D1(i,j)表示最短路径可能经过1而不经过其它顶点,D2(i,j)表示最短路径可能经过1、2而不经过其它顶点,Dn(i,j)表示i到j的最短路径,所有顶点都可能经过。
当k=0时,Dk(i,j) = d(i,j)。
当1<=k<=n时,Dk(i,j) = min{Dk-1(i,j), Dk-1(i,k)
+ Dk-1(k,j)},这个式子表示从i到j的最短路径中,要不经过第k个顶点要不不经过,第一项表示不经过第k个顶点,第二项表示经过第k个顶点,并且表示为两部分之和。
以上算法和上面的例子的算法也是类似的,关键还是处理变量k,注意这里的k是不受i和j限制的。该最短路径算法的时间为O(V^3),但是在稠密图的情况下,该算法比Dijkstra算法更快。
下面的实现中使用一个数组表示一个有向有权图(更多实现细节请查看github项目:使用动态规划解决所有点对的最短路径):
void graph_shortest_path_of_pair(Graph *graph){
if(graph == NULL)
return;
int n = graph->n;
for (int m = 0; m < n; ++m) {
graph->d[m * n + m] = 0;
graph->path[m * n + m] = m;
}
for (int k = 0; k < n; ++k) {
for (int i = 0; i < n; ++i) {
for (int j = 0; j < n; ++j) {
if(graph->d[i * n + k] == INT_MAX || graph->d[k * n + j] == INT_MAX)
continue;
if(graph->d[i * n + k] + graph->d[k * n + j] < graph->d[i * n + j]){
graph->d[i * n + j] = graph->d[i * n + k] + graph->d[k * n + j];
graph->path[i * n + j] = k;
}
}
}
}
}
上面处理k的情况也是不一样的,因为这里的k是不受i和j限制的,不妨也好好理解一下这个模式,因为动态规划中使用迭代的方式是比较好的了,如果使用递归的话,当然很好理解,但是效率不高。
五、随机化算法(randomized algorithm)
1、随机化算法的基本概念
随机化算法比较简单,它就是在算法中使用了随机函数的算法,而且随机函数的返回值直接或间接影响算法的执行流程或执行结果。算法期间,随机数至少有一次用于决策,算法的运行时间和输入和随机数有关,随机化算法的最坏时间一般和非随机化算法的最坏时间相同。
不存在坏的输入,只有坏的随机数,使用不同的随机数会影响期望时间,因此如何选择随机数则变得比较关键了,下面会首先介绍随机数发生器。对于随机化算法的应用例子有:快速排序,随机化选择枢纽元素,以及检测一个大数是否是素数,另外的例子是下面介绍的跳跃表。
2、随机数发生器
计算机不可能产生真的随机数,计算机只能生成伪随机数,这里我们的目标是生成伪随机数序列。
生成随机数序列的一个常用的方法是使用线性同余数发生器,即Xi+1 = AXi mod M,其中Xi的初始值X0叫做种子,但是注意如果取X0=0则该序列不是随机的。只要A和M选取正确,取其它1<=X0
但是该算法在M-1个数以后,随机序列将会重复,周期为M-1,我们当然是想让该周期尽可极大,这里的建议首先是素数,建议取M=2^31 – 1
= 2147483647,A=48271,注意随意修改A和M有可能会失败。
算法实现:首先Xi+1用于计算下一个X,我们可以使用一个static的全局变量储存,对于X0可设置为1,还可以使用其它自定义值:系统时钟或用户输入。
这里获取随机数我们使用Xi+1
= AXi mod M,当前的计算值作为下一个随机数的种子,但是AXi这个乘法有可能会溢出。为了避免出现这个问题,我们使用这个算法:Xi+1 = A(Xi mod Q) – R(Xi
/ Q) + MS(Xi),其中Q = M/A,R =
M%A,这里称余项指的是除了MS(Xi)的项,那么如果余项小于0那么S(Xi) = 1,否则S(Xi)=0,在这里算法中,只要INT_MAX >= 2^31 – 1,以上算法可以正常工作。
但是一般库的发生器一般算法是使用:Xi+1 = (AXi + C) mod 2^B,B匹配机器整数的位数,C是奇数,但是对于长随机序列的情况并不适用,所以下面的算法实现使用上一个算法。
下面使用C语言实现随机数发生器,生成整数随机数(完整源码查看github项目:随机数发生器):
int random_int(void){
int temp = A * (state % Q) - R * (state / Q);
if(temp >= 0)
state = temp;
else
state = temp + M;
return state;
}
3、跳跃表(skip list)
跳跃表是一种随机数据结构,主要是使用了随机化算法,应用于以O(logn)期望时间支持查找插入的数据结构,每次操作的期望时间都为O(logn),基于随机数发生器。
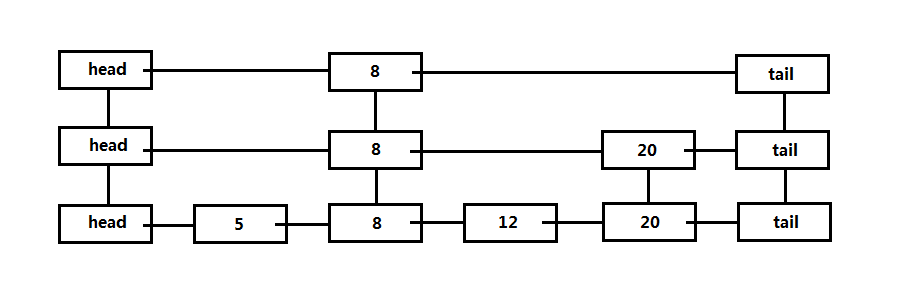
跳跃表的基本概念:
它是一种随机数据结构。
跳跃表是在链表的基础上进行改进,所有数据已排序,使用随机化算法决定是否提升表的高度。
由很多层结构组成,每一层都是一个有序链表。
跳跃表的最底层链表包含所有元素。
跳跃表使用典型的空间换取时间的算法。
跳跃表的数据结构设计:
对于表中的每个结点,包括数据或关键字、上下左右指针,以及结点类型:头结点、数据结点和尾结点。
对于跳跃表包括头尾结点、表大小、高度以及使用的随机化算法。
跳跃表的基本操作算法:
查找find(k),k为结点的关键字或数据,搜索方向为:尽可能向右走,走不了再向下找,其操作步骤如下:
先取出跳跃表最顶部的头部指针node。
使用一个while循环,再使用while循环向表右方向移动,循环条件为:node.right != tail && k >= node.right.value,若符合条件则:node=node.right。
若node.down != null,则node = node.down,否则跳出循环。
返回node,该node.value <= k。
插入数据add(k),k为数据或关键字,我们主要是在这里使用随机化算法,插入操作的步骤如下:
使用上面的查找操作:node=find(k),这里可以选择在k==node.value的时候不插入,因为k>=node.value(表中关键字为升序),所以我们是在node的右边插入新结点(注意这种情况该node一定是最底层的node,所以插入操作是在最底层的链表中插入)。
在每一层使用随机数决定在当前node是否增加一层,这里使用抛硬币的方式。概率界限为p,随机数小于p增加高度,大于p停止操作。我们可以取p为1/2,也可以取p等于1/4等。
也可以使用随机数生成指定的层数,或者也可以使用最大层数限制,但是有缺陷。最后,我们需要往左更新指针。
遍历操作,可以按照高度从上而下,从左到右,头部到尾部进行遍历。
删除delete(k),首先执行node=find(k),如果k!=node.value直接结束,否则进行删除操作,这里只需要按照链表的一般方式进行删除操作即可。
这里使用C语言实现跳跃表,下面是主要是声明部分,实现代码中使用的随机算法是上面实现的随机数生成器,详细实现请查看github项目:跳跃表。
typedef void* value;
typedef enum stype{
HEAD, DATA, TAIL
} SType;
typedef struct snode{
int key;
value value;
struct snode *up, *down, *left, *right;
// SType type;
} SNode;
typedef struct skiplist{
SNode *head;
int size;
int height;
} SkipList;
extern SkipList *slist_new(void);
extern int slist_is_empty(SkipList *slist);
extern SNode *slist_find(SkipList *slist, int key);
extern value slist_search(SkipList *slist, int key);
extern void slist_add(SkipList *slist, int key, value value);
extern void slist_traverse(SkipList *slist);
extern void slist_delete(SkipList *slist, int key);
extern void slist_clear(SkipList *slist);
4、素性测试
素性测试是检测一个大数是否是素数,首先我们要介绍一下关于素数检测的一些基本概念:
这里介绍的算法可以确定一个数一定不是素数,但是也不是100%确定是素数,其准确性依赖于算法做出的随机选择,所以该算法偶尔会出错,但是可以让它出错的比率任意小。
算法的关键是费马定理,其中费马小定理是这样的:
若P是素数,且0 < A < P,那么A^(P – 1)恒等于1(mod P),也就是等价于A^(P – 1) % P = 1 % P。
可以使用该算法反过来验证一个数是否是素数,如果等式不成立可以肯定不是素数,但是成立也不一定是素数,其中不少素数的最小P=341。
随机化算法是从1 < A < P-1中选取A,对于某些数A的选择可能会骗过该算法,这样的数集叫做Carmichael数,应该尽量选择与P互素的A。
平方探测定理的特殊情况:如果P是素数,而且0 < X < P,那么X^2恒等1(mod P)仅有的两个解为X=1,X=P-1,这可用于测试一个数不是素数。
下面是详细的实现算法,该算法有25%的概率会出错,75%的概率是对的。
static long witness(long a, long i, long N){
long X, Y;
if(i == 0)
return 1;
X = witness(a, i/2, N);
if(X == 0)
return 0;
Y = (X * X) % N;
if(Y == 1 && X != 1 && X != N - 1)
return 0;
if(i % 2 != 0)
Y = (a * Y) % N;
return Y;
}
int is_prime(long N){
for (int i = 0; i < 5; ++i) {
if(witness(random_int_range(2, N -2), N - 1, N) != 1)
return 0;
}
return 1;
}
六、回溯算法(backtracking algorithm)
1、回溯算法的基本概念
回溯算法是穷举法的一种巧妙实现,一般性能不理想,但是相对于穷举法来说也有显著的节省,对于某些问题如NP完全问题可以取得较好的效果,回溯算法是一种通用解题方法。
回溯算法是一种选优搜索法,首先要确定选优条件为x,按照x向前搜索,若不符合条件,则撤回一步重新尝试,这一步称为回溯,满足回溯条件的点叫做回溯点,回溯法一般是寻找问题的所有解(或一个解),或面向有多种决策的问题。
如果你熟识树或图的话,其实回溯法就是DFS法,所以其算法基本模式是使用DFS遍历,或者可以说这里问题的解可用一个状态空间树(可能是多叉树)表示:
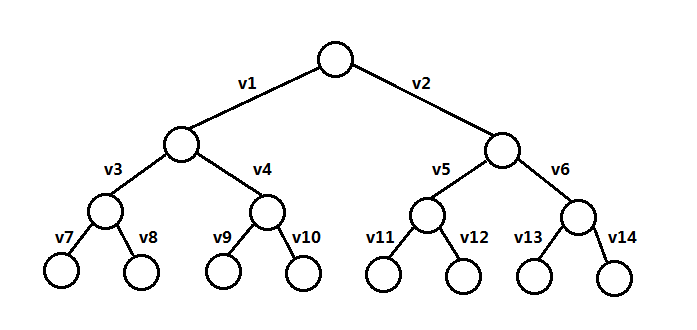
回溯法就是从根结点开始向下搜索,如果在一个结点上发现解不符合要求,则向上回溯,继续搜索其它路径。代码实现上,回溯一般都要恢复原来的状态。
2、收费公路重建问题
这个问题是这样的:
存在n个点pi的点集P,1<=i<=n。
xi为点pi的x坐标,可设x1=0,所有点从左到右给出,也就是P点集有序(非降序)。
点对的距离为d=|xi – xj|,i != j,这样一共有k=n(n-1)/2个点对,这些点对距离的集合为D,其中D为非降序。
该问题是将这些距离集D重新构造一个点集P,也就是根据已知的k个距离反推出n个点。
这个问题在物理学和分子生物学中也有应用,没有算法能保证可以使用多项式时间解决该问题,这里的算法时间一般为O(n^2logn),最坏情况为指数时间。
下面使用回溯法解决该问题,首先我们有待求的点集P={xi},其中1<=i<=n,这里可设x1=0,然后是已知距离的集合D,D的大小为k=n(n-1)/2,使用回溯法其实本质就是穷举法(尝试所有可能性),下面是回溯法的具体步骤:
首先确定P1=0,Pn=Dmax。
使用T数组标记D中某元素是否已被使用。
下面使用递归算法,边界条件为:若P中填满并且D元素已被全部使用(即T中所有标记为1),则返回1或true。
遍历D中未被使用的元素,可使用一个left和right界定未被使用的元素的范围:
取出未被使用的最大元素作为点p。
检查p和P中已存在的点,计算|Pi-P|是否属于D,若属于则在T中标记,将p添加到P中,否则尝试下一次循环获取p。
若p符合要求,则递归计算下一个位置的点。
若递归返回正确,则表示有解,可尝试获取多个解,或直接返回一个解,否则表示当前路径无解,继续尝试下一轮。
这里有个优化细节,其中D可使用AVL树或伸展树来储存,遍历D的时候可以使用左右left和right进行界限。这里就不重新实现了,请查看我的另一篇文章使用JavaScript实现的代码:使用回溯法解决收费公路重建问题,不过其中D还是使用数组储存的,你可以改为树储存。
3、机器博弈问题
这是个问题是关于游戏中的人机博弈,如西洋跳棋或国际象棋,这里的例子使用三连游戏棋(tic-tac-toe),这里的博弈是一种均衡的概念,保证双方策略最优,假设双方都是为自己着想,双方都是想赢棋的。

如上图是一个三连棋,两人轮流在九格棋盘上划加字或圆圈,任一方把三个同一记号画成横线、直线、斜线则是胜者。
这里游戏的角色只有两个:人和计算机,这里的问题是构造一个从不输棋而且当有机会时总能赢棋的算法。
下面介绍两个博弈策略,后一个是前一个的优化版本。
极小极大策略
这里使用一个赋值函数标记位置的好坏,对于计算机一方在位置P的值v使用三种标记,该标记表示,在任意位置开始到棋盘结束的一轮棋中(博弈),双方所处的情况,表示走这一步棋让人和机器处于什么情况:
使计算机获胜则为v=+1,以下人的情况为相反情况。
人机平局为v=0。
使计算机输棋为v=-1。
v的值决定于:
满棋盘结束则v=0.
棋盘未满但是可以判断出胜负,可能为-1或1,取决于胜的角色是哪一个。
考察棋盘能确定输赢的位置叫做终端位置(terminal position):
如果一个位置P不是终端位置,可通过递归假设双方最优棋步,确定该位置的值,也就是假设双方都是走有利于自己的棋步。
对于计算机来说希望v大,对于人来说则希望v小,这个就叫做极小极大策略。
走一步棋P的位置选取策略:
位置P的后继位置(successor position)为:从P走一步棋可达到的任何位置Ps,如上图,P的位置为所有可能走的位置中的最大值。
该算法是模拟计算所有可能下棋的位置,每下一步棋都模拟完每个位置到棋盘结束的胜算,从中选择一个最优位置。这里你可以想到,决定胜负的是最后一步棋(也就是最后一步棋自然就会显示胜负了)。
对于计算机下棋,从所有的位置找到一个最大v的P,v越大计算机越可能胜。为了找到最优的P,需要进一步模拟人下棋的所有可能情况。
对于人下棋,从所有位置找到一个最小v的P,v越小人越可能胜。
该算法的问题是:计算机开局的情况下,计算代价最高,搜索全部棋盘的所有可能位置不可能,可使用求值函数进行选步最大化,求值函数的计量可考虑棋子和位置元素的相对量和强度。另外可增加计算机向前看步数目,使用表来存储已经计算过的位置,可使用置换表,通过散列实现。
使用回溯法解决人机博弈问题的详细算法步骤如下:
首先确定角色为计算机C和人H。
棋盘为B,最好的位置p,该位置的值v={Loss(输), Draw(平), Win(胜)},p为最好下棋的位置。
初始化计算机C:初始位置p=1,初始最好值v=Loss,计算机选取v的时候找最大值,v最大值等于计算下一轮人下棋的最小值Hv。
初始化人H:初始位置p=1,初始最好值v=Win。
边界条件,这时则是终端位置,B已满或已经可判断胜负。检查B是否已满,已满表示平局(p=p,v=Draw)。或者快速检查是否已胜,若检查三点一线在某一点下棋会胜则返回(p=wp,v=CW),否则表示不是终端位置。
非终端位置,初始化v的值,在B中循环取出一个可用的位置,在可用位置上模拟下棋,递归模拟对方下棋,进行上一步的悔棋操作(回溯操作),也就是撤回当前的位置的棋子,继续尝试下一个位置。
如果递归返回的v=response符合要求,则更新v=response,以及p=i。
以上算法可对照下面的代码实现进行理解:
void game_find_comp_move_basic(Board *board, int *bestp, int *value){
int dc, response;
if(game_board_is_full(board))
*value = Draw;
else if(game_immiediate_comp_win(board, bestp))
*value = Win;
else{
*value = Loss;
int n = board->n;
for (int i = 0; i < n * n; ++i) {
if(game_board_is_empty(board, i)){
game_place(board, i, Comp);
game_find_human_move_basic(board, &dc, &response);
game_unplace(board, i);
if(response > *value){
*value = response;
*bestp = i;
}
}
}
}
}
以上是计算计算机最优选择的部分代码,完整源码请查看github项目:人机博弈,测试建议还是使用n=3,n大于3已经好难算出来了,n=4的时候上界是4^17。
α-β裁剪
α-β裁剪的目的是改进DFS,减少DFS搜索的结点数,也就是增加向前看步数,α-β裁减限制的搜索结点数为根号n,比非裁减树增加2倍的搜索深度(向前看步数)。
α-β裁剪简单的来说就是,当计算机要找大的v值的时候,就不要去搜索比v低的分支了,其实就是一个剪枝操作。
α-β裁剪算法是在上面极小极大策略中进行改进,在人机回溯算法中增加α-β参数,α初始值为-1,β初始值为1,其中
α裁剪是针对计算机行棋,v初始值为α,如下图C-max为计算机行棋,目标值肯定大于或等于44,H-min为人行棋,目标值肯定小于或等于40,这样对于右子树就不再向下搜索了。
If(v < β)则尝试所有路径,否则v=β,v对于计算机已经达到最大值,不再需要尝试其它路径。

β裁剪是针对人行棋,v初始值为β,如下图:

If(v > α)则尝试所有路径,否则v=α,v对于人已经达到最大值,不再需要尝试其它路径。
下面是对计算机部分的算法实现,完整实现请查看github项目:
// alpha = -1, beta = 1
void game_find_comp_move(Board *board, int *bestp, int *value, int alpha, int beta){
int dc, response;
if(game_board_is_full(board))
*value = Draw;
else if(game_immiediate_comp_win(board, bestp))
*value = Win;
else{
*value = alpha;
int n = board->n;
for (int i = 0; i < n * n && *value < beta; ++i) {
if(game_board_is_empty(board, i)){
game_place(board, i, Comp);
game_find_human_move(board, &dc, &response, *value, beta);
game_unplace(board, i);
if(response > *value){
*value = response;
*bestp = i;
}
}
}
}
}
该算法相比上面的则是相当快了,你可以试下n=4的情况,除了首次计算其它基本都是很快算出来。
七、分支限界法(branch and bound)
1、分支限界法的基本概念
分支限界法和上面的回溯法想法类似,都是搜索解空间树,而分支限界法使用的则是BFS广度优先遍历。分支限界法常以广度优先或最小耗费(最大效益)优先的方式搜索问题的解空间树,一般是求满足约束条件的一个解,或是某种意义下的最优解。
每个结点只有一次机会成为扩展结点,成为扩展结点后,则产生所有儿子结点,一旦儿子结点不满足,则被舍弃。问题的解可表示成状态空间树,每个状态结点都有一个特别的值bound(i),问题的解可表示成状态空间树,产生很多分支,这就是“分支”的意思,限界是在树的每个深度上对每个结点给一个范围限制(也就是剪枝)。
我们可以使用一个限界函数,对目标函数进行估算:down <= bound(i) <= up,这可以选取最优的分支或剪掉不符合要求的分支,注意:分支限界法的本质还是穷举法。
因为使用BFS遍历,所以分支限界法通常有以下两种形式:
队列分支限界法,按照先进先出选取结点。
优先队列分支限界法,安装优先级选取结点。
要特别注意的是,分支限界法是有“限界”的,也就是说一定要有剪枝操作,否则就变成回溯法那样了(回溯法也可以设计适当的剪枝操作),下面是分支限界法和回溯法的不同:
回溯法一般是求解满足约束条件的所有解,分支限界法求解满足约束条件的一个解,或某种意义下的最优解。
回溯法以深度优先搜索空间树,分支限界法以广度优先或最小耗费优先搜索空间树。
下面是使用分支限界法的解题参考步骤:
首先要构建限界函数(approximate cost function),又称为估值函数f(x),根据当前状态和目标状态进行估值计算,该值可以决定是否使用当前状态作为扩展分支,实现剪枝,减少不必要的操作。
结点x的代价f(x)估值为:f(x)=g(x)+h(x),g(x)为根结点到当前结点x的实际代价值,h(x)为从当前x到目标解结点的估计代价值。
寻找限界函数,可根据问题的约束条件找到限界函数,如果根据约束条件仍然找不到,该问题解决可能又很深的结点,或可采取类似A*算法的方式。
最后就是使用BFS搜索解空间树了,若当前结点满足限界[down, up],则将其入队,否则舍弃该结点,重复以上步骤,这一步是比较简单的。
分支限界法的应用例子如:单源最短路径、布线问题、装载问题、背包问题、巡回售货员问题等。
2、八数码问题

该问题描述如下(对照上图):
3×3的棋盘上有8个棋子,棋子标记为1-8。
棋盘留有一个空格,用0表示,空格周围的棋子可以移动。
给出一个初始棋盘布局s和目标棋盘布局t,找出一种从初始布局移动为目标布局最小步骤的方法。
该问题可以求最小步骤,或非最小步骤,只需移动为目标布局即可。
解决该问题的可用方法:
BFS,暴力解法。
DFS暴力解法。
A*算法,和分支限界法类似。
使用分支限界法解决八数码问题,详细步骤如下:
首先是构建估值函数f(x)。设任意方向移动一个棋子花费1个单元的消耗(最多有4个方向,也就是4个分支),g(x)为从根结点到当前结点的路径长,也就是x的深度(根到x的移动步骤数)。
h(x)是不在目标位置的非空棋子的数量,也就是当前布局与目标布局对比,其数字不对应的数量。至少需要h(x)步才能从x移动到目标布局,注意:空格0可算可不算。
则f(x)=g(x) + h(x),进而选择在当前深度f(x)最优的结点,这里可以选择最小的f(x)。
最后就是使用一个优先队列(最小堆)和BFS进行计算。
以上的算法其实就有点类似A*算法了,这里其实也是结合A*算法的概念讨论的,A*算法是一个很高效的算法,D算法则是A*算法的动态版本,还有其它变体。
下面是使用分支限界法实现的主要代码部分(完整实现请查看github项目:八数码问题):
int puzzle_solve(Puzzle *puzzle){
if(puzzle == NULL)
return -1;
Heap *min = new_heap(10, compare);
heap_push(min, puzzle->s);
Square *s;
int n = puzzle->n;
while(!heap_is_empty(min)){
s = heap_top(min);
heap_pop(min);
if(h_cost(s->boxes, puzzle->t->boxes, n) == 0){
free(puzzle->t->boxes);
puzzle->t = s;
return s->level;
}
for (int i = 0; i < 4; ++i) {
if (is_safe(puzzle, s->i + row[i], s->j + col[i])){
Square* ch = square_new(n, s->boxes, s, 1 + s->level);
swap(&ch->boxes[s->i * n + s->j], &ch->boxes[(s->i + row[i]) * n + (s->j + col[i])]);
ch->i = s->i + row[i];
ch->j = s->j + col[i];
ch->p = ch->level + h_cost(ch->boxes, puzzle->t->boxes, n);
heap_push(min, ch);
}
}
}
return -1;
}
3、N皇后问题
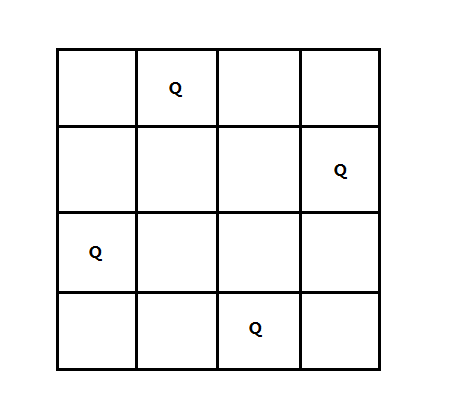
N皇后问题是将n个皇后放在n
x n的棋盘上,任意两个皇后不能互相攻击,也就是任意两个皇后不同行、同列,也不能在同一对角线上。
分支限界法步骤:
构造限界函数,这里可以直接根据问题的约束条件构建:皇后不同行、同列和同对角线。也就是说在同一深度上,每个状态需要满足约束条件,否则舍弃。
使用一个普通队列,结合BFS进行计算。
这里就不具体实现了,其实和上面的八数码问题也是一样的,有兴趣的朋友可以动手试试。
4、巡回售货员问题
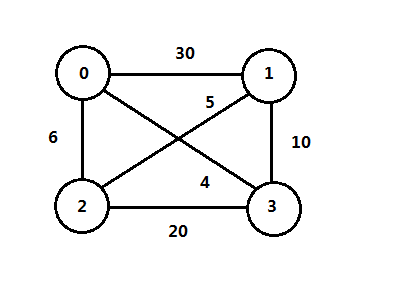
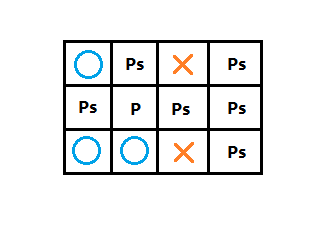
该问题是著名的NP-完全问题,该问题是这样的:
在一个城市图中,起点城市为s。
求从s出发经过每个城市一次,回到原点s的路径。
并且该路径p的总权值最小,权值可为路径长或旅费。
使用分支限界法解决巡回售货员问题的具体步骤如下:
首先确定限界函数,使用矩阵表示该图。第一步是计算根结点的下界cost:
行计算,找出当前行的最小值m,让行的每个元素分别减去m得到新的行。
列计算,在行计算得到的新矩阵的基础上,找出当前列的最小值p,让每个元素分别减去p等到新的列。
根结点的下界cost为:cost = 所有行的m +
所有列的p。具体推算步骤如下图:
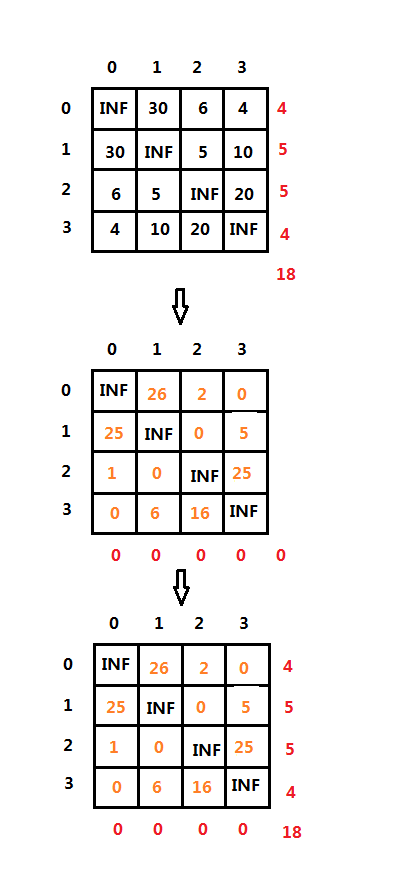
第二步是计算其它结点E(i, j)的下界cost:
基于父结点i,将i的所有出边、j的所有入边以及边(j, 0)的权值都置为INF。
计算以j为起点的cost P(j),方式使用和根结点同样的计算形式。
结点j的下界cost = 父结点的cost +
C(i, j) + P(i),其中C(i, j)为顶点i到顶点j的权值。具体推算步骤如下图所示:

其它也就是使用优先队列和BFS进行计算了,其难点主要是寻找边界函数,或者叫做估值函数。这里先不实现了,有兴趣的朋友可以动手试试,不过这个问题挺经典的,下次找个时间再单独实现。
八、结语
终于写完了!除了图论算法那一章,这也是目前写得最长的一篇了。本节介绍的六大算法设计技巧可是相当重要,下面是以上代码的github项目地址:
你可能学过设计模式,如果你不懂的话,也不要紧,懂算法设计技巧以及数据结构就行了!掌握算法设计技巧至少不会写出低效率的代码,既然都会数据结构了,那也不至于不会使用接口来扩展了,大体总结如下:
解决实际问题基本上使用上面的六大算法设计技巧已足够,贪婪法是最直观的,而且本人认为是最容易的一个,结合优先队列基本上可以得到一个高效率的算法了。
分治算法的本质是对问题的划分(分类),难度适中,能否获得好的效率还是要参考其时间定理,因而分治算法并不能保证有好的效率,模式上有先序遍历和后序遍历两种(也就是先处理问题再分解问题,还是先分解问题再合并解)。
动态规划是最难的一个,也是比较重要的一个,其本质实际上就是归纳法,使用归纳法列出状态方程,然后使用表辅助遍历求解,后面准备出更多与动态规划相关的案例。
随机化算法难度一般,它其实就是在算法中使用随机数,就应用上来说获取随机数并不难,难的是在算法中怎么用。
回溯法也是本人认为又容易又好用的一个,因为受树和图的影响,这个算法其实就是遍历空间树,重点是看能不能找到一个方式进行剪枝操作。
分支限界法本人也认为比较容易的一个,同样也是遍历空间树,但是其难点是构造一个限界函数(用于剪枝),这个函数在A*算法中又称为启发函数,构造该函数第一是参考问题的约束条件,第二使用F = G + H构造,H的值为当前结点到目标解结点的估值。