Estimating CPU Performance using Amdahls Law
REF: https://www.pugetsystems.com/labs/articles/Estimating-CPU-Performance-using-Amdahls-Law-619/#AmdahlsLawLimitations
- Introduction
- What is Amdahls Law?
- Amdahls Law Limitations
- Step 1: Test your program with various number of CPU cores
- Step 2: Determining the parallelization fraction
- Step 3: Estimate CPU performance using the parallelization fraction
- Easy Mode - Using a Google Doc spreadsheet
- Conclusion
| # of Cores | Action Time (seconds) | Actual Speedup | Amdahl's Law Speedup (97% efficient) |
|---|---|---|---|
| 1 | 645.4 | 1 | 1 |
| 2 | 328.3 | 1.97 | 1.95 |
| 3 | 230 | 2.8 | 2.8 |
| 4 | 172 | 3.75 | 3.67 |
| 5 | 140.3 | 4.6 | 4.5 |
| 6 | 117.5 | 5.5 | 5.2 |
| 7 | 108 | 6 | 5.9 |
| 8 | 97.8 | 6.6 | 6.6 |
To find the parallelization fraction, you need to use the parallelization equation we listed earlier and plug in different values for P:
![]()
A good place to start might be to try P=.8 (or 80% parallel efficient) and perform this calculation for each # of cores. For example, for 4 cores the equation would be
![]()
which equals 2.5. Compare this to our actual speedup in our example (which was 3.75) and you will see that our example program is actually more than 80% efficient so we need to increase the parallelization fraction to something higher. In our case, the actual fraction was .97 (97%) which is pretty decent. You will notice that the results don't line up perfectly every single time since there is a certain margin of error that always exist when you run benchmarks - you simply have to average it out and get it as close as you can. Having this in a spreadsheet where you can graph both data series makes it much easier (see the Easy Mode - Using a Google Doc spreadsheet section for a link to a Google Doc with all the calculations already performed and a graph setup).
To estimate a CPU's performance, you need to know the operating frequency and how many cores both the CPU you used to benchmark with and the CPU you are interested in has. With those specs in hand, you first need to calculate how many effective cores both CPUs have which is done by using the equation:
![]()
Basically, this is using the same parallelization equation we used earlier only using the actual number of cores the CPU has. This gives us the effective number of CPU cores the CPU has when running your program if the program was actually 100% efficient. From this, we can multiple the number of effective cores with each CPU's operating frequency to get what is essentially how many operations per second the CPU is able to complete (or GFLOPs):
![]()
Finally, we can estimate how long it would take the CPU you are interested in to complete the same action you benchmarked by dividing the GFLOPS of the two CPUs and multiplying it by the time it took your test CPU to complete the action with all of it's cores enabled:
![]()
With this, you should end up with an estimation of how long it would take a CPU to complete the action you benchmarked.
| 1) To enter your own data, first make a copy of this spreadsheet through File->Make a Copy | ||||||
| 2) In the orange cells, enter you benchmark times for each core count | ||||||
| 3) Adjust the parallel efficiency (yellow cell) until the lines on the graph are close | ||||||
| 2) In the blue cells, enter the CPU name, total number of physical cores, and the CPU frequency of the CPUs you are interested in | ||||||
| 3) Limit CPU comparisons to ones that are within the same family. AMD vs Intel or different generations of CPUs will not give accurate comparisons. | ||||||
| 3) The green cells show the estimated benchmark time for each CPU | ||||||
| View more infomation on estimating CPU performance in our 'Estimating CPU Performance using Amdahls Law' article | ||||||
| # of CPU Cores | Benchmark Time | Calculated Speedup | Amdahl's Law Speedup | Parallel Efficiency: | ||
| 1 | 645.4 | 1 | 1 | 0.97 | ||
| 2 | 328.3 | 1.965884861 | 1.941747573 | Change between 0 and 1 | ||
| 3 | 230 | 2.806086957 | 2.830188679 | until both lines are close | ||
| 4 | 172 | 3.752325581 | 3.669724771 | |||
| 5 | 140.3 | 4.600142552 | 4.464285714 | |||
| 6 | 117.5 | 5.492765957 | 5.217391304 | |||
| 7 | 108 | 5.975925926 | 5.93220339 | |||
| 8 | 97.8 | 6.599182004 | 6.611570248 | |||
| 9 | 90.5 | 7.131491713 | 7.258064516 | |||
| 10 | 85.3 | 7.566236811 | 7.874015748 | |||
| 11 | 78.7 | 8.200762389 | 8.461538462 | |||
| 12 | 72.45 | 8.90821256 | 9.022556391 | |||
| 13 | 66.2 | 9.749244713 | 9.558823529 | |||
| 14 | 59.95 | 10.76563803 | 10.07194245 | |||
| 15 | 53.7 | 12.01862197 | 10.56338028 | |||
| 16 | 47.45 | 13.60168599 | 11.03448276 | |||
| 17 | 41.2 | 15.66504854 | 11.48648649 | |||
| 18 | 34.95 | 18.46638054 | 11.9205298 | |||
| 19 | 28.7 | 22.48780488 | 12.33766234 | |||
| CPU Model | Cores | Frequency* | Effective Cores | Relative GFLOPs | Estimated Benchmark Time | Improvement (%) |
| Tested CPU | 10 | 2.6 | 7.874015748 | 20.47244094 | 28.7 | - |
| Compare CPU1 | 8 | 3.2 | 6.611570248 | 21.15702479 | 27.8 | 3.14 |
| Compare CPU2 | 12 | 2.6 | 9.022556391 | 23.45864662 | 25 | 10.07 |
Computer performance by orders of magnitude
REF:
https://en.wikipedia.org/wiki/Computer_performance
https://en.wikipedia.org/wiki/Computer_performance_by_orders_of_magnitude
Deciscale computing (10−1)[edit]
- 5×10^−1 Speed of the average human mental calculation for multiplication using pen and paper
Scale computing (100)[edit]
- 1 OP/S the speed of the average human addition calculation using pen and paper
- 1 OP/S the speed of Zuse Z1
- 5 OP/S world record for addition set
Decascale computing (101)[edit]
- 5×10^1 Upper end of serialized human perception computation (light bulbs do not flicker to the human observer)
Hectoscale computing (102)[edit]
- 2.2×10^2 Upper end of serialized human throughput. This is roughly expressed by the lower limit of accurate event placement on small scales of time (The swing of a conductor's arm, the reaction time to lights on a drag strip, etc.)[1]
- 2×10^2 IBM 602 1946 computer.
Kiloscale computing (103)[edit]
- 92×10^3 Intel 4004 First commercially available full function CPU on a chip, released in 1971
- 500×10^3 Colossus computer vacuum tube supercomputer 1943
Megascale computing (106)[edit]
- 1×10^6 Motorola 68000 commercial computing 1979
- 1.2×10^6 IBM 7030 "Stretch" transistorized supercomputer 1961
Gigascale computing (109)[edit]
- 1×10^9 ILLIAC IV 1972 supercomputer does first computational fluid dynamics problems
- 1.354×10^9 Intel Pentium III commercial computing 1999
- 147.6×10^9 Intel Core i7-980X Extreme Edition commercial computing 2010[2]
Terascale computing (1012)[edit]
- 1.34×10^12 Intel ASCI Red 1997 Supercomputer
- 1.344×10^12 GeForce GTX 480 in 2010 from Nvidia at its peak performance
- 4.64×10^12 Radeon HD 5970 in 2009 from AMD (under ATI branding) at its peak performance
- 5.152×10^12 S2050/S2070 1U GPU Computing System from Nvidia
- 11.3×10^12 GeForce GTX 1080 Ti in 2017
- 13.7×10^12 Radeon RX Vega 64 in 2017
- 15.0×10^12 Nvidia Titan V in 2017
- 80×10^12 IBM Watson[3]
- 170×10^12 Nvidia DGX-1 The initial Pascal based DGX-1 delivered 170 teraflops of half precision processing.[4]
- 478.2×10^12 IBM BlueGene/L 2007 Supercomputer
- 960×10^12 Nvidia DGX-1 The Volta-based upgrade increased calculation power of Nvidia DGX-1 to 960 teraflops.[5]
Petascale computing (1015)[edit]
Main article: Petascale computing
- 1.026×10^15 IBM Roadrunner 2009 Supercomputer
- 2×10^15 Nvidia DGX-2 a 2 Petaflop Machine Learning system (the newer DGX A100 has 5 Petaflop performance)
- 11.5×10^15 Google TPU pod containing 64 second-generation TPUs, May 2017[6]
- 17.17×10^15 IBM Sequoia's LINPACK performance, June 2013[7]
- 20×10^15 Roughly the hardware-equivalent of the human brain according to Kurzweil. Published in his 1999 book: The Age of Spiritual Machines: When Computers Exceed Human Intelligence[8]
- 33.86×10^15 Tianhe-2's LINPACK performance, June 2013[7]
- 36.8×10^15 Estimated computational power required to simulate a human brain in real time.[9]
- 93.01×10^15 Sunway TaihuLight's LINPACK performance, June 2016[10]
- 143.5×10^15 Summit's LINPACK performance, November 2018[11]


Instructions per second - MIPS / DMIPS
REF : https://www.elektroda.com/rtvforum/topic2908657.html
DMIPS is Dhrystone MIPS. To help understand the meaning of this name, let’s divide it in two words and start with short explanation what is MIPS (million instructions per second), then try to get more familiar with the meaning of Dhrystone.
MIPS is a way to assess the speed and power of a computer by measuring the average number of instructions (expressed in millions), executed within a single second. Calculating MIPS, an important thing is to remember that different instruction require different time to be executed due to their complexity. Another factor that may have an impact on the resulting number of instructions executed within a second, is the quality of I/O speed. However, MIPS always refers only to the speed of CPU, not taking into account the other reasonable conditions which may influence the result. The fact that the high or low MIPS rating of a computer does not give any certainty your device will handle an application quicker or not, suggests that MIPS cannot be taken as a meaningful and reliable source of information about the actual performance of our device.
Dhrystone (D) – a synthetic computing benchmark program, designed to help assess the performance of a processor (CPU). Dhystone test was designed in the following idea: its basis is a standard loop of synthetic code, which imitates various operations in algorithms of a computer. DMPIS stands for Dhrystone MIPS, in which Dhrystone score must be divided by 1757 (1 MIPS machine or the number of Dhrystones in a second). This way of measuring the performance of a computer processor is much more meaningful and reliable than MIPS. By dividing the result of the above calculation by the frequency of a particular CPU, you can obtain another number expressed in DMIPS/MHz, which can be really useful when you want to compare the performance of your CPU at different clock speed.
To sum up, the main difference, next to the fact that DMIPS uses the Dhrystone program for its calculations, is the result which suggests the actual work can be done by a CPU, not just the speed. DMIPS takes into account many variables and thus it is more architecture independent.
REF:https://www.nxp.com/docs/en/application-note/AN4666.pdf
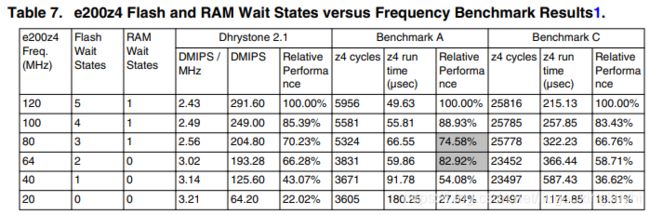
4 Effect of wait states versus frequency
Performance normally increases with frequency. However, it is not a linear relationship. One reason is additional wait states kick in for higher frequencies. The tests here give indications of what performance to expect when moving from executing at one frequency to another.
“Relative Performance” is calculated as the ratio of the metric between the fastest frequency and others:
• Relative Performance (Dhrystone 2.1) = (DMIPS) / (DMIPS at 120 MHz)
• Relative Performance (Benchmarks A, C) = (run time at 120 MHz) / (run time)
For example, from Table 7 the Dhrystone 2.1 Relative Performance for e200z4 frequency of 100 MHz = 291.60 / 249.00 = 85.39%. Configuration 120 MHz with five flash wait states and one RAM wait state (first row) is considered to deliver 100% performance. The relative performance gives an indication of performance increase (value >100%) or decrease (value <100%) when using different wait state configurations. Flash wait states are controlled by fields in the Platform Flash Controller, Platform Flash Configuration Register 0 (PFCR0). RAM wait states are controlled by a field in the Error Correction Status Module, Miscellaneous User-Defined Control Register (MUDCR).
REF:
https://johnloomis.org/NiosII/dhrystone/ECLDhrystoneWhitePaper.pdf
https://www.netlib.org/benchmark/dhry-c
# to unbundle, sh this file (in an empty directory)
echo RATIONALE 1>&2
sed >RATIONALE <<'//GO.SYSIN DD RATIONALE' 's/^-//'
-
-
- Dhrystone Benchmark: Rationale for Version 2 and Measurement Rules
-
- [published in SIGPLAN Notices 23,8 (Aug. 1988), 49-62]
-
-
- Reinhold P. Weicker
- Siemens AG, E STE 35
- [now: Siemens AG, AUT E 51]
- Postfach 3220
- D-8520 Erlangen
- Germany (West)
-
-
-
-
-1. Why a Version 2 of Dhrystone?
-
-The Dhrystone benchmark program [1] has become a popular benchmark for
-CPU/compiler performance measurement, in particular in the area of
-minicomputers, workstations, PC's and microprocesors. It apparently satisfies
-a need for an easy-to-use integer benchmark; it gives a first performance
-indication which is more meaningful than MIPS numbers which, in their literal
-meaning (million instructions per second), cannot be used across different
-instruction sets (e.g. RISC vs. CISC). With the increasing use of the
-benchmark, it seems necessary to reconsider the benchmark and to check whether
-it can still fulfill this function. Version 2 of Dhrystone is the result of
-such a re-evaluation, it has been made for two reasons:
-
-o Dhrystone has been published in Ada [1], and Versions in Ada, Pascal and C
- have been distributed by Reinhold Weicker via floppy disk. However, the
- version that was used most often for benchmarking has been the version made
- by Rick Richardson by another translation from the Ada version into the C
- programming language, this has been the version distributed via the UNIX
- network Usenet [2].
-
- There is an obvious need for a common C version of Dhrystone, since C is at
- present the most popular system programming language for the class of
- systems (microcomputers, minicomputers, workstations) where Dhrystone is
- used most. There should be, as far as possible, only one C version of
- Dhrystone such that results can be compared without restrictions. In the
- past, the C versions distributed by Rick Richardson (Version 1.1) and by
- Reinhold Weicker had small (though not significant) differences.
-
- Together with the new C version, the Ada and Pascal versions have been
- updated as well.
-
-o As far as it is possible without changes to the Dhrystone statistics,
- optimizing compilers should be prevented from removing significant
- statements. It has turned out in the past that optimizing compilers
- suppressed code generation for too many statements (by "dead code removal"
- or "dead variable elimination"). This has lead to the danger that
- benchmarking results obtained by a naive application of Dhrystone - without
- inspection of the code that was generated - could become meaningless.
-
-The overall policiy for version 2 has been that the distribution of
-statements, operand types and operand locality described in [1] should remain
-unchanged as much as possible. (Very few changes were necessary; their impact
-should be negligible.) Also, the order of statements should remain unchanged.
-Although I am aware of some critical remarks on the benchmark - I agree with
-several of them - and know some suggestions for improvement, I didn't want to
-change the benchmark into something different from what has become known as
-"Dhrystone"; the confusion generated by such a change would probably outweight
-the benefits. If I were to write a new benchmark program, I wouldn't give it
-the name "Dhrystone" since this denotes the program published in [1].
-However, I do recognize the need for a larger number of representative
-programs that can be used as benchmarks; users should always be encouraged to
-use more than just one benchmark.
-
-The new versions (version 2.1 for C, Pascal and Ada) will be distributed as
-widely as possible. (Version 2.1 differs from version 2.0 distributed via the
-UNIX Network Usenet in March 1988 only in a few corrections for minor
-deficiencies found by users of version 2.0.) Readers who want to use the
-benchmark for their own measurements can obtain a copy in machine-readable
-form on floppy disk (MS-DOS or XENIX format) from the author.
-
-
-2. Overall Characteristics of Version 2
-
-In general, version 2 follows - in the parts that are significant for
-performance measurement, i.e. within the measurement loop - the published
-(Ada) version and the C versions previously distributed. Where the versions
-distributed by Rick Richardson [2] and Reinhold Weicker have been different,
-it follows the version distributed by Reinhold Weicker. (However, the
-differences have been so small that their impact on execution time in all
-likelihood has been negligible.) The initialization and UNIX instrumentation
-part - which had been omitted in [1] - follows mostly the ideas of Rick
-Richardson [2]. However, any changes in the initialization part and in the
-printing of the result have no impact on performance measurement since they
-are outside the measaurement loop. As a concession to older compilers, names
-have been made unique within the first 8 characters for the C version.
-
-The original publication of Dhrystone did not contain any statements for time
-measurement since they are necessarily system-dependent. However, it turned
-out that it is not enough just to inclose the main procedure of Dhrystone in a
-loop and to measure the execution time. If the variables that are computed
-are not used somehow, there is the danger that the compiler considers them as
-"dead variables" and suppresses code generation for a part of the statements.
-Therefore in version 2 all variables of "main" are printed at the end of the
-program. This also permits some plausibility control for correct execution of
-the benchmark.
-
-At several places in the benchmark, code has been added, but only in branches
-that are not executed. The intention is that optimizing compilers should be
-prevented from moving code out of the measurement loop, or from removing code
-altogether. Statements that are executed have been changed in very few places
-only. In these cases, only the role of some operands has been changed, and it
-was made sure that the numbers defining the "Dhrystone distribution"
-(distribution of statements, operand types and locality) still hold as much as
-possible. Except for sophisticated optimizing compilers, execution times for
-version 2.1 should be the same as for previous versions.
-
-Because of the self-imposed limitation that the order and distribution of the
-executed statements should not be changed, there are still cases where
-optimizing compilers may not generate code for some statements. To a certain
-degree, this is unavoidable for small synthetic benchmarks. Users of the
-benchmark are advised to check code listings whether code is generated for all
-statements of Dhrystone.
-
-Contrary to the suggestion in the published paper and its realization in the
-versions previously distributed, no attempt has been made to subtract the time
-for the measurement loop overhead. (This calculation has proven difficult to
-implement in a correct way, and its omission makes the program simpler.)
-However, since the loop check is now part of the benchmark, this does have an
-impact - though a very minor one - on the distribution statistics which have
-been updated for this version.
-
-
-3. Discussion of Individual Changes
-
-In this section, all changes are described that affect the measurement loop
-and that are not just renamings of variables. All remarks refer to the C
-version; the other language versions have been updated similarly.
-
-In addition to adding the measurement loop and the printout statements,
-changes have been made at the following places:
-
-o In procedure "main", three statements have been added in the non-executed
- "then" part of the statement
-
- if (Enum_Loc == Func_1 (Ch_Index, 'C'))
-
- they are
-
- strcpy (Str_2_Loc, "DHRYSTONE PROGRAM, 3'RD STRING");
- Int_2_Loc = Run_Index;
- Int_Glob = Run_Index;
-
- The string assignment prevents movement of the preceding assignment to
- Str_2_Loc (5'th statement of "main") out of the measurement loop (This
- probably will not happen for the C version, but it did happen with another
- language and compiler.) The assignment to Int_2_Loc prevents value
- propagation for Int_2_Loc, and the assignment to Int_Glob makes the value of
- Int_Glob possibly dependent from the value of Run_Index.
-
-o In the three arithmetic computations at the end of the measurement loop in
- "main ", the role of some variables has been exchanged, to prevent the
- division from just cancelling out the multiplication as it was in [1]. A
- very smart compiler might have recognized this and suppressed code
- generation for the division.
-
-o For Proc_2, no code has been changed, but the values of the actual parameter
- have changed due to changes in "main".
-
-o In Proc_4, the second assignment has been changed from
-
- Bool_Loc = Bool_Loc | Bool_Glob;
-
- to
-
- Bool_Glob = Bool_Loc | Bool_Glob;
-
- It now assigns a value to a global variable instead of a local variable
- (Bool_Loc); Bool_Loc would be a "dead variable" which is not used
- afterwards.
-
-o In Func_1, the statement
-
- Ch_1_Glob = Ch_1_Loc;
-
- was added in the non-executed "else" part of the "if" statement, to prevent
- the suppression of code generation for the assignment to Ch_1_Loc.
-
-o In Func_2, the second character comparison statement has been changed to
-
- if (Ch_Loc == 'R')
-
- ('R' instead of 'X') because a comparison with 'X' is implied in the
- preceding "if" statement.
-
- Also in Func_2, the statement
-
- Int_Glob = Int_Loc;
-
- has been added in the non-executed part of the last "if" statement, in order
- to prevent Int_Loc from becoming a dead variable.
-
-o In Func_3, a non-executed "else" part has been added to the "if" statement.
- While the program would not be incorrect without this "else" part, it is
- considered bad programming practice if a function can be left without a
- return value.
-
- To compensate for this change, the (non-executed) "else" part in the "if"
- statement of Proc_3 was removed.
-
-The distribution statistics have been changed only by the addition of the
-measurement loop iteration (1 additional statement, 4 additional local integer
-operands) and by the change in Proc_4 (one operand changed from local to
-global). The distribution statistics in the comment headers have been updated
-accordingly.
-
-
-4. String Operations
-
-The string operations (string assignment and string comparison) have not been
-changed, to keep the program consistent with the original version.
-
-There has been some concern that the string operations are over-represented in
-the program, and that execution time is dominated by these operations. This
-was true in particular when optimizing compilers removed too much code in the
-main part of the program, this should have been mitigated in version 2.
-
-It should be noted that this is a language-dependent issue: Dhrystone was
-first published in Ada, and with Ada or Pascal semantics, the time spent in
-the string operations is, at least in all implementations known to me,
-considerably smaller. In Ada and Pascal, assignment and comparison of strings
-are operators defined in the language, and the upper bounds of the strings
-occuring in Dhrystone are part of the type information known at compilation
-time. The compilers can therefore generate efficient inline code. In C,
-string assignemt and comparisons are not part of the language, so the string
-operations must be expressed in terms of the C library functions "strcpy" and
-"strcmp". (ANSI C allows an implementation to use inline code for these
-functions.) In addition to the overhead caused by additional function calls,
-these functions are defined for null-terminated strings where the length of
-the strings is not known at compilation time; the function has to check every
-byte for the termination condition (the null byte).
-
-Obviously, a C library which includes efficiently coded "strcpy" and "strcmp"
-functions helps to obtain good Dhrystone results. However, I don't think that
-this is unfair since string functions do occur quite frequently in real
-programs (editors, command interpreters, etc.). If the strings functions are
-implemented efficiently, this helps real programs as well as benchmark
-programs.
-
-I admit that the string comparison in Dhrystone terminates later (after
-scanning 20 characters) than most string comparisons in real programs. For
-consistency with the original benchmark, I didn't change the program despite
-this weakness.
-
-
-5. Intended Use of Dhrystone
-
-When Dhrystone is used, the following "ground rules" apply:
-
-o Separate compilation (Ada and C versions)
-
- As mentioned in [1], Dhrystone was written to reflect actual programming
- practice in systems programming. The division into several compilation
- units (5 in the Ada version, 2 in the C version) is intended, as is the
- distribution of inter-module and intra-module subprogram calls. Although on
- many systems there will be no difference in execution time to a Dhrystone
- version where all compilation units are merged into one file, the rule is
- that separate compilation should be used. The intention is that real
- programming practice, where programs consist of several independently
- compiled units, should be reflected. This also has implies that the
- compiler, while compiling one unit, has no information about the use of
- variables, register allocation etc. occuring in other compilation units.
- Although in real life compilation units will probably be larger, the
- intention is that these effects of separate compilation are modeled in
- Dhrystone.
-
- A few language systems have post-linkage optimization available (e.g., final
- register allocation is performed after linkage). This is a borderline case:
- Post-linkage optimization involves additional program preparation time
- (although not as much as compilation in one unit) which may prevent its
- general use in practical programming. I think that since it defeats the
- intentions given above, it should not be used for Dhrystone.
-
- Unfortunately, ISO/ANSI Pascal does not contain language features for
- separate compilation. Although most commercial Pascal compilers provide
- separate compilation in some way, we cannot use it for Dhrystone since such
- a version would not be portable. Therefore, no attempt has been made to
- provide a Pascal version with several compilation units.
-
-o No procedure merging
-
- Although Dhrystone contains some very short procedures where execution would
- benefit from procedure merging (inlining, macro expansion of procedures),
- procedure merging is not to be used. The reason is that the percentage of
- procedure and function calls is part of the "Dhrystone distribution" of
- statements contained in [1]. This restriction does not hold for the string
- functions of the C version since ANSI C allows an implementation to use
- inline code for these functions.
-
-o Other optimizations are allowed, but they should be indicated
-
- It is often hard to draw an exact line between "normal code generation" and
- "optimization" in compilers: Some compilers perform operations by default
- that are invoked in other compilers only when optimization is explicitly
- requested. Also, we cannot avoid that in benchmarking people try to achieve
- results that look as good as possible. Therefore, optimizations performed
- by compilers - other than those listed above - are not forbidden when
- Dhrystone execution times are measured. Dhrystone is not intended to be
- non-optimizable but is intended to be similarly optimizable as normal
- programs. For example, there are several places in Dhrystone where
- performance benefits from optimizations like common subexpression
- elimination, value propagation etc., but normal programs usually also
- benefit from these optimizations. Therefore, no effort was made to
- artificially prevent such optimizations. However, measurement reports
- should indicate which compiler optimization levels have been used, and
- reporting results with different levels of compiler optimization for the
- same hardware is encouraged.
-
-o Default results are those without "register" declarations (C version)
-
- When Dhrystone results are quoted without additional qualification, they
- should be understood as results obtained without use of the "register"
- attribute. Good compilers should be able to make good use of registers even
- without explicit register declarations ([3], p. 193).
-
-Of course, for experimental purposes, post-linkage optimization, procedure
-merging and/or compilation in one unit can be done to determine their effects.
-However, Dhrystone numbers obtained under these conditions should be
-explicitly marked as such; "normal" Dhrystone results should be understood as
-results obtained following the ground rules listed above.
-
-In any case, for serious performance evaluation, users are advised to ask for
-code listings and to check them carefully. In this way, when results for
-different systems are compared, the reader can get a feeling how much
-performance difference is due to compiler optimization and how much is due to
-hardware speed.
-
-
-6. Acknowledgements
-
-The C version 2.1 of Dhrystone has been developed in cooperation with Rick
-Richardson (Tinton Falls, NJ), it incorporates many ideas from the "Version
-1.1" distributed previously by him over the UNIX network Usenet. Through his
-activity with Usenet, Rick Richardson has made a very valuable contribution to
-the dissemination of the benchmark. I also thank Chaim Benedelac (National
-Semiconductor), David Ditzel (SUN), Earl Killian and John Mashey (MIPS), Alan
-Smith and Rafael Saavedra-Barrera (UC at Berkeley) for their help with
-comments on earlier versions of the benchmark.
-
-
-7. Bibliography
-
-[1]
- Reinhold P. Weicker: Dhrystone: A Synthetic Systems Programming Benchmark.
- Communications of the ACM 27, 10 (Oct. 1984), 1013-1030
-
-[2]
- Rick Richardson: Dhrystone 1.1 Benchmark Summary (and Program Text)
- Informal Distribution via "Usenet", Last Version Known to me: Sept. 21,
- 1987
-
-[3]
- Brian W. Kernighan and Dennis M. Ritchie: The C Programming Language.
- Prentice-Hall, Englewood Cliffs (NJ) 1978
-
//GO.SYSIN DD RATIONALE
echo README_C 1>&2
sed >README_C <<'//GO.SYSIN DD README_C' 's/^-//'
-This "shar" file contains the documentation for the
-electronic mail distribution of the Dhrystone benchmark (C version 2.1);
-a companion "shar" file contains the source code.
-(Because of mail length restrictions for some mailers, I have
-split the distribution in two parts.)
-
-For versions in other languages, see the other "shar" files.
-
-Files containing the C version (*.h: Header File, *.c: C Modules)
-
- dhry.h
- dhry_1.c
- dhry_2.c
-
-The file RATIONALE contains the article
-
- "Dhrystone Benchmark: Rationale for Version 2 and Measurement Rules"
-
-which has been published, together with the C source code (Version 2.0),
-in SIGPLAN Notices vol. 23, no. 8 (Aug. 1988), pp. 49-62.
-This article explains all changes that have been made for Version 2,
-compared with the version of the original publication
-in Communications of the ACM vol. 27, no. 10 (Oct. 1984), pp. 1013-1030.
-It also contains "ground rules" for benchmarking with Dhrystone
-which should be followed by everyone who uses the program and publishes
-Dhrystone results.
-
-Compared with the Version 2.0 published in SIGPLAN Notices, Version 2.1
-contains a few corrections that have been made after Version 2.0 was
-distriobuted over the UNIX network Usenet. These small differences between
-Version 2.0 and 2.1 should not affect execution time measurements.
-For those who want to compare the exact contents of both versions,
-the file "dhry_c.dif" contains the differences between the two versions,
-as generated by a file comparison of the corresponding files with the
-UNIX utility "diff".
-
-The file VARIATIONS contains the article
-
- "Understanding Variations in Dhrystone Performance"
-
-which has been published in Microprocessor Report, May 1989
-(Editor: M. Slater), pp. 16-17. It describes the points that users
-should know if C Dhrystone results are compared.
-
-Recipients of this shar file who perform measurements are asked
-to send measurement results to the author and/or to Rick Richardson.
-Rick Richardson publishes regularly Dhrystone results on the UNIX network
-Usenet. For submissions of results to him (preferably by electronic mail,
-see address in the program header), he has provided a form which is contained
-in the file "submit.frm".
-
-
-The following files are contained in other "shar" files:
-
-Files containing the Ada version (*.s: Specifications, *.b: Bodies):
-
- d_global.s
- d_main.b
- d_pack_1.b
- d_pack_1.s
- d_pack_2.b
- d_pack_2.s
-
-File containing the Pascal version:
-
- dhry.p
-
-
-February 22, 1990
-
- Reinhold P. Weicker
- Siemens AG, AUT E 51
- Postfach 3220
- D-8520 Erlangen
- Germany (West)
-
- Phone: [xxx-49]-9131-7-20330 (8-17 Central European Time)
- UUCP: ..!mcsun!unido!estevax!weicker
//GO.SYSIN DD README_C
echo VARIATIONS 1>&2
sed >VARIATIONS <<'//GO.SYSIN DD VARIATIONS' 's/^-//'
-
- Understanding Variations in Dhrystone Performance
-
-
-
- By Reinhold P. Weicker, Siemens AG, AUT E 51, Erlangen
-
-
-
- April 1989
-
-
- This article has appeared in:
-
-
- Microprocessor Report, May 1989 (Editor: M. Slater), pp. 16-17
-
-
-
-
-Microprocessor manufacturers tend to credit all the performance measured by
-benchmarks to the speed of their processors, they often don't even mention the
-programming language and compiler used. In their detailed documents, usually
-called "performance brief" or "performance report," they usually do give more
-details. However, these details are often lost in the press releases and other
-marketing statements. For serious performance evaluation, it is necessary to
-study the code generated by the various compilers.
-
-Dhrystone was originally published in Ada (Communications of the ACM, Oct.
-1984). However, since good Ada compilers were rare at this time and, together
-with UNIX, C became more and more popular, the C version of Dhrystone is the
-one now mainly used in industry. There are "official" versions 2.1 for Ada,
-Pascal, and C, which are as close together as the languages' semantic
-differences permit.
-
-Dhrystone contains two statements where the programming language and its
-translation play a major part in the execution time measured by the benchmark:
-
- o String assignment (in procedure Proc_0 / main)
- o String comparison (in function Func_2)
-
-In Ada and Pascal, strings are arrays of characters where the length of the
-string is part of the type information known at compile time. In C, strings
-are also arrays of characters, but there are no operators defined in the
-language for assignment and comparison of strings. Instead, functions
-"strcpy" and "strcmp" are used. These functions are defined for strings of
-arbitrary length, and make use of the fact that strings in C have to end with
-a terminating null byte. For general-purpose calls to these functions, the
-implementor can assume nothing about the length and the alignment of the
-strings involved.
-
-The C version of Dhrystone spends a relatively large amount of time in these
-two functions. Some time ago, I made measurements on a VAX 11/785 with the
-Berkeley UNIX (4.2) compilers (often-used compilers, but certainly not the
-most advanced). In the C version, 23% of the time was spent in the string
-functions; in the Pascal version, only 10%. On good RISC machines (where less
-time is spent in the procedure calling sequence than on a VAX) and with better
-optimizing compilers, the percentage is higher; MIPS has reported 34% for an
-R3000. Because of this effect, Pascal and Ada Dhrystone results are usually
-better than C results (except when the optimization quality of the C compiler
-is considerably better than that of the other compilers).
-
-Several people have noted that the string operations are over-represented in
-Dhrystone, mainly because the strings occurring in Dhrystone are longer than
-average strings. I admit that this is true, and have said so in my SIGPLAN
-Notices paper (Aug. 1988); however, I didn't want to generate confusion by
-changing the string lengths from version 1 to version 2.
-
-Even if they are somewhat over-represented in Dhrystone, string operations are
-frequent enough that it makes sense to implement them in the most efficient
-way possible, not only for benchmarking purposes. This means that they can
-and should be written in assembly language code. ANSI C also explicitly allows
-the strings functions to be implemented as macros, i.e. by inline code.
-
-There is also a third way to speed up the "strcpy" statement in Dhrystone: For
-this particular "strcpy" statement, the source of the assignment is a string
-constant. Therefore, in contrast to calls to "strcpy" in the general case, the
-compiler knows the length and alignment of the strings involved at compile
-time and can generate code in the same efficient way as a Pascal compiler
-(word instructions instead of byte instructions).
-
-This is not allowed in the case of the "strcmp" call: Here, the addresses are
-formal procedure parameters, and no assumptions can be made about the length
-or alignment of the strings. Any such assumptions would indicate an incorrect
-implementation. They might work for Dhrystone, where the strings are in fact
-word-aligned with typical compilers, but other programs would deliver
-incorrect results.
-
-So, for an apple-to-apple comparison between processors, and not between
-several possible (legal or illegal) degrees of compiler optimization, one
-should check that the systems are comparable with respect to the following
-three points:
-
- (1) String functions in assembly language vs. in C
-
- Frequently used functions such as the string functions can and should be
- written in assembly language, and all serious C language systems known
- to me do this. (I list this point for completeness only.) Note that
- processors with an instruction that checks a word for a null byte (such
- as AMD's 29000 and Intel's 80960) have an advantage here. (This
- advantage decreases relatively if optimization (3) is applied.) Due to
- the length of the strings involved in Dhrystone, this advantage may be
- considered too high in perspective, but it is certainly legal to use
- such instructions - after all, these situations are what they were
- invented for.
-
- (2) String function code inline vs. as library functions.
-
- ANSI C has created a new situation, compared with the older
- Kernighan/Ritchie C. In the original C, the definition of the string
- function was not part of the language. Now it is, and inlining is
- explicitly allowed. I probably should have stated more clearly in my
- SIGPLAN Notices paper that the rule "No procedure inlining for
- Dhrystone" referred to the user level procedures only and not to the
- library routines.
-
- (3) Fixed-length and alignment assumptions for the strings
-
- Compilers should be allowed to optimize in these cases if (and only if)
- it is safe to do so. For Dhrystone, this is the "strcpy" statement, but
- not the "strcmp" statement (unless, of course, the "strcmp" code
- explicitly checks the alignment at execution time and branches
- accordingly). A "Dhrystone switch" for the compiler that causes the
- generation of code that may not work under certain circumstances is
- certainly inappropriate for comparisons. It has been reported in Usenet
- that some C compilers provide such a compiler option; since I don't have
- access to all C compilers involved, I cannot verify this.
-
- If the fixed-length and word-alignment assumption can be used, a wide
- bus that permits fast multi-word load instructions certainly does help;
- however, this fact by itself should not make a really big difference.
-
-A check of these points - something that is necessary for a thorough
-evaluation and comparison of the Dhrystone performance claims - requires
-object code listings as well as listings for the string functions (strcpy,
-strcmp) that are possibly called by the program.
-
-I don't pretend that Dhrystone is a perfect tool to measure the integer
-performance of microprocessors. The more it is used and discussed, the more I
-myself learn about aspects that I hadn't noticed yet when I wrote the program.
-And of course, the very success of a benchmark program is a danger in that
-people may tune their compilers and/or hardware to it, and with this action
-make it less useful.
-
-Whetstone and Linpack have their critical points also: The Whetstone rating
-depends heavily on the speed of the mathematical functions (sine, sqrt, ...),
-and Linpack is sensitive to data alignment for some cache configurations.
-
-Introduction of a standard set of public domain benchmark software (something
-the SPEC effort attempts) is certainly a worthwhile thing. In the meantime,
-people will continue to use whatever is available and widely distributed, and
-Dhrystone ratings are probably still better than MIPS ratings if these are -
-as often in industry - based on no reproducible derivation. However, any
-serious performance evaluation requires more than just a comparison of raw
-numbers; one has to make sure that the numbers have been obtained in a
-comparable way.
-
//GO.SYSIN DD VARIATIONS
echo dhry.h 1>&2
sed >dhry.h <<'//GO.SYSIN DD dhry.h' 's/^-//'
-/*
- ****************************************************************************
- *
- * "DHRYSTONE" Benchmark Program
- * -----------------------------
- *
- * Version: C, Version 2.1
- *
- * File: dhry.h (part 1 of 3)
- *
- * Date: May 25, 1988
- *
- * Author: Reinhold P. Weicker
- * Siemens AG, AUT E 51
- * Postfach 3220
- * 8520 Erlangen
- * Germany (West)
- * Phone: [+49]-9131-7-20330
- * (8-17 Central European Time)
- * Usenet: ..!mcsun!unido!estevax!weicker
- *
- * Original Version (in Ada) published in
- * "Communications of the ACM" vol. 27., no. 10 (Oct. 1984),
- * pp. 1013 - 1030, together with the statistics
- * on which the distribution of statements etc. is based.
- *
- * In this C version, the following C library functions are used:
- * - strcpy, strcmp (inside the measurement loop)
- * - printf, scanf (outside the measurement loop)
- * In addition, Berkeley UNIX system calls "times ()" or "time ()"
- * are used for execution time measurement. For measurements
- * on other systems, these calls have to be changed.
- *
- * Collection of Results:
- * Reinhold Weicker (address see above) and
- *
- * Rick Richardson
- * PC Research. Inc.
- * 94 Apple Orchard Drive
- * Tinton Falls, NJ 07724
- * Phone: (201) 389-8963 (9-17 EST)
- * Usenet: ...!uunet!pcrat!rick
- *
- * Please send results to Rick Richardson and/or Reinhold Weicker.
- * Complete information should be given on hardware and software used.
- * Hardware information includes: Machine type, CPU, type and size
- * of caches; for microprocessors: clock frequency, memory speed
- * (number of wait states).
- * Software information includes: Compiler (and runtime library)
- * manufacturer and version, compilation switches, OS version.
- * The Operating System version may give an indication about the
- * compiler; Dhrystone itself performs no OS calls in the measurement loop.
- *
- * The complete output generated by the program should be mailed
- * such that at least some checks for correctness can be made.
- *
- ***************************************************************************
- *
- * History: This version C/2.1 has been made for two reasons:
- *
- * 1) There is an obvious need for a common C version of
- * Dhrystone, since C is at present the most popular system
- * programming language for the class of processors
- * (microcomputers, minicomputers) where Dhrystone is used most.
- * There should be, as far as possible, only one C version of
- * Dhrystone such that results can be compared without
- * restrictions. In the past, the C versions distributed
- * by Rick Richardson (Version 1.1) and by Reinhold Weicker
- * had small (though not significant) differences.
- *
- * 2) As far as it is possible without changes to the Dhrystone
- * statistics, optimizing compilers should be prevented from
- * removing significant statements.
- *
- * This C version has been developed in cooperation with
- * Rick Richardson (Tinton Falls, NJ), it incorporates many
- * ideas from the "Version 1.1" distributed previously by
- * him over the UNIX network Usenet.
- * I also thank Chaim Benedelac (National Semiconductor),
- * David Ditzel (SUN), Earl Killian and John Mashey (MIPS),
- * Alan Smith and Rafael Saavedra-Barrera (UC at Berkeley)
- * for their help with comments on earlier versions of the
- * benchmark.
- *
- * Changes: In the initialization part, this version follows mostly
- * Rick Richardson's version distributed via Usenet, not the
- * version distributed earlier via floppy disk by Reinhold Weicker.
- * As a concession to older compilers, names have been made
- * unique within the first 8 characters.
- * Inside the measurement loop, this version follows the
- * version previously distributed by Reinhold Weicker.
- *
- * At several places in the benchmark, code has been added,
- * but within the measurement loop only in branches that
- * are not executed. The intention is that optimizing compilers
- * should be prevented from moving code out of the measurement
- * loop, or from removing code altogether. Since the statements
- * that are executed within the measurement loop have NOT been
- * changed, the numbers defining the "Dhrystone distribution"
- * (distribution of statements, operand types and locality)
- * still hold. Except for sophisticated optimizing compilers,
- * execution times for this version should be the same as
- * for previous versions.
- *
- * Since it has proven difficult to subtract the time for the
- * measurement loop overhead in a correct way, the loop check
- * has been made a part of the benchmark. This does have
- * an impact - though a very minor one - on the distribution
- * statistics which have been updated for this version.
- *
- * All changes within the measurement loop are described
- * and discussed in the companion paper "Rationale for
- * Dhrystone version 2".
- *
- * Because of the self-imposed limitation that the order and
- * distribution of the executed statements should not be
- * changed, there are still cases where optimizing compilers
- * may not generate code for some statements. To a certain
- * degree, this is unavoidable for small synthetic benchmarks.
- * Users of the benchmark are advised to check code listings
- * whether code is generated for all statements of Dhrystone.
- *
- * Version 2.1 is identical to version 2.0 distributed via
- * the UNIX network Usenet in March 1988 except that it corrects
- * some minor deficiencies that were found by users of version 2.0.
- * The only change within the measurement loop is that a
- * non-executed "else" part was added to the "if" statement in
- * Func_3, and a non-executed "else" part removed from Proc_3.
- *
- ***************************************************************************
- *
- * Defines: The following "Defines" are possible:
- * -DREG=register (default: Not defined)
- * As an approximation to what an average C programmer
- * might do, the "register" storage class is applied
- * (if enabled by -DREG=register)
- * - for local variables, if they are used (dynamically)
- * five or more times
- * - for parameters if they are used (dynamically)
- * six or more times
- * Note that an optimal "register" strategy is
- * compiler-dependent, and that "register" declarations
- * do not necessarily lead to faster execution.
- * -DNOSTRUCTASSIGN (default: Not defined)
- * Define if the C compiler does not support
- * assignment of structures.
- * -DNOENUMS (default: Not defined)
- * Define if the C compiler does not support
- * enumeration types.
- * -DTIMES (default)
- * -DTIME
- * The "times" function of UNIX (returning process times)
- * or the "time" function (returning wallclock time)
- * is used for measurement.
- * For single user machines, "time ()" is adequate. For
- * multi-user machines where you cannot get single-user
- * access, use the "times ()" function. If you have
- * neither, use a stopwatch in the dead of night.
- * "printf"s are provided marking the points "Start Timer"
- * and "Stop Timer". DO NOT use the UNIX "time(1)"
- * command, as this will measure the total time to
- * run this program, which will (erroneously) include
- * the time to allocate storage (malloc) and to perform
- * the initialization.
- * -DHZ=nnn
- * In Berkeley UNIX, the function "times" returns process
- * time in 1/HZ seconds, with HZ = 60 for most systems.
- * CHECK YOUR SYSTEM DESCRIPTION BEFORE YOU JUST APPLY
- * A VALUE.
- *
- ***************************************************************************
- *
- * Compilation model and measurement (IMPORTANT):
- *
- * This C version of Dhrystone consists of three files:
- * - dhry.h (this file, containing global definitions and comments)
- * - dhry_1.c (containing the code corresponding to Ada package Pack_1)
- * - dhry_2.c (containing the code corresponding to Ada package Pack_2)
- *
- * The following "ground rules" apply for measurements:
- * - Separate compilation
- * - No procedure merging
- * - Otherwise, compiler optimizations are allowed but should be indicated
- * - Default results are those without register declarations
- * See the companion paper "Rationale for Dhrystone Version 2" for a more
- * detailed discussion of these ground rules.
- *
- * For 16-Bit processors (e.g. 80186, 80286), times for all compilation
- * models ("small", "medium", "large" etc.) should be given if possible,
- * together with a definition of these models for the compiler system used.
- *
- **************************************************************************
- *
- * Dhrystone (C version) statistics:
- *
- * [Comment from the first distribution, updated for version 2.
- * Note that because of language differences, the numbers are slightly
- * different from the Ada version.]
- *
- * The following program contains statements of a high level programming
- * language (here: C) in a distribution considered representative:
- *
- * assignments 52 (51.0 %)
- * control statements 33 (32.4 %)
- * procedure, function calls 17 (16.7 %)
- *
- * 103 statements are dynamically executed. The program is balanced with
- * respect to the three aspects:
- *
- * - statement type
- * - operand type
- * - operand locality
- * operand global, local, parameter, or constant.
- *
- * The combination of these three aspects is balanced only approximately.
- *
- * 1. Statement Type:
- * ----------------- number
- *
- * V1 = V2 9
- * (incl. V1 = F(..)
- * V = Constant 12
- * Assignment, 7
- * with array element
- * Assignment, 6
- * with record component
- * --
- * 34 34
- *
- * X = Y +|-|"&&"|"|" Z 5
- * X = Y +|-|"==" Constant 6
- * X = X +|- 1 3
- * X = Y *|/ Z 2
- * X = Expression, 1
- * two operators
- * X = Expression, 1
- * three operators
- * --
- * 18 18
- *
- * if .... 14
- * with "else" 7
- * without "else" 7
- * executed 3
- * not executed 4
- * for ... 7 | counted every time
- * while ... 4 | the loop condition
- * do ... while 1 | is evaluated
- * switch ... 1
- * break 1
- * declaration with 1
- * initialization
- * --
- * 34 34
- *
- * P (...) procedure call 11
- * user procedure 10
- * library procedure 1
- * X = F (...)
- * function call 6
- * user function 5
- * library function 1
- * --
- * 17 17
- * ---
- * 103
- *
- * The average number of parameters in procedure or function calls
- * is 1.82 (not counting the function values as implicit parameters).
- *
- *
- * 2. Operators
- * ------------
- * number approximate
- * percentage
- *
- * Arithmetic 32 50.8
- *
- * + 21 33.3
- * - 7 11.1
- * * 3 4.8
- * / (int div) 1 1.6
- *
- * Comparison 27 42.8
- *
- * == 9 14.3
- * /= 4 6.3
- * > 1 1.6
- * < 3 4.8
- * >= 1 1.6
- * <= 9 14.3
- *
- * Logic 4 6.3
- *
- * && (AND-THEN) 1 1.6
- * | (OR) 1 1.6
- * ! (NOT) 2 3.2
- *
- * -- -----
- * 63 100.1
- *
- *
- * 3. Operand Type (counted once per operand reference):
- * ---------------
- * number approximate
- * percentage
- *
- * Integer 175 72.3 %
- * Character 45 18.6 %
- * Pointer 12 5.0 %
- * String30 6 2.5 %
- * Array 2 0.8 %
- * Record 2 0.8 %
- * --- -------
- * 242 100.0 %
- *
- * When there is an access path leading to the final operand (e.g. a record
- * component), only the final data type on the access path is counted.
- *
- *
- * 4. Operand Locality:
- * -------------------
- * number approximate
- * percentage
- *
- * local variable 114 47.1 %
- * global variable 22 9.1 %
- * parameter 45 18.6 %
- * value 23 9.5 %
- * reference 22 9.1 %
- * function result 6 2.5 %
- * constant 55 22.7 %
- * --- -------
- * 242 100.0 %
- *
- *
- * The program does not compute anything meaningful, but it is syntactically
- * and semantically correct. All variables have a value assigned to them
- * before they are used as a source operand.
- *
- * There has been no explicit effort to account for the effects of a
- * cache, or to balance the use of long or short displacements for code or
- * data.
- *
- ***************************************************************************
- */
-
-/* Compiler and system dependent definitions: */
-
-#ifndef TIME
-#define TIMES
-#endif
- /* Use times(2) time function unless */
- /* explicitly defined otherwise */
-
-#ifdef TIMES
-#include
-#include
- /* for "times" */
-#endif
-
-#define Mic_secs_Per_Second 1000000.0
- /* Berkeley UNIX C returns process times in seconds/HZ */
-
-#ifdef NOSTRUCTASSIGN
-#define structassign(d, s) memcpy(&(d), &(s), sizeof(d))
-#else
-#define structassign(d, s) d = s
-#endif
-
-#ifdef NOENUM
-#define Ident_1 0
-#define Ident_2 1
-#define Ident_3 2
-#define Ident_4 3
-#define Ident_5 4
- typedef int Enumeration;
-#else
- typedef enum {Ident_1, Ident_2, Ident_3, Ident_4, Ident_5}
- Enumeration;
-#endif
- /* for boolean and enumeration types in Ada, Pascal */
-
-/* General definitions: */
-
-#include
- /* for strcpy, strcmp */
-
-#define Null 0
- /* Value of a Null pointer */
-#define true 1
-#define false 0
-
-typedef int One_Thirty;
-typedef int One_Fifty;
-typedef char Capital_Letter;
-typedef int Boolean;
-typedef char Str_30 [31];
-typedef int Arr_1_Dim [50];
-typedef int Arr_2_Dim [50] [50];
-
-typedef struct record
- {
- struct record *Ptr_Comp;
- Enumeration Discr;
- union {
- struct {
- Enumeration Enum_Comp;
- int Int_Comp;
- char Str_Comp [31];
- } var_1;
- struct {
- Enumeration E_Comp_2;
- char Str_2_Comp [31];
- } var_2;
- struct {
- char Ch_1_Comp;
- char Ch_2_Comp;
- } var_3;
- } variant;
- } Rec_Type, *Rec_Pointer;
-
-
//GO.SYSIN DD dhry.h
echo dhry_1.c 1>&2
sed >dhry_1.c <<'//GO.SYSIN DD dhry_1.c' 's/^-//'
-/*
- ****************************************************************************
- *
- * "DHRYSTONE" Benchmark Program
- * -----------------------------
- *
- * Version: C, Version 2.1
- *
- * File: dhry_1.c (part 2 of 3)
- *
- * Date: May 25, 1988
- *
- * Author: Reinhold P. Weicker
- *
- ****************************************************************************
- */
-
-#include "dhry.h"
-
-/* Global Variables: */
-
-Rec_Pointer Ptr_Glob,
- Next_Ptr_Glob;
-int Int_Glob;
-Boolean Bool_Glob;
-char Ch_1_Glob,
- Ch_2_Glob;
-int Arr_1_Glob [50];
-int Arr_2_Glob [50] [50];
-
-extern char *malloc ();
-Enumeration Func_1 ();
- /* forward declaration necessary since Enumeration may not simply be int */
-
-#ifndef REG
- Boolean Reg = false;
-#define REG
- /* REG becomes defined as empty */
- /* i.e. no register variables */
-#else
- Boolean Reg = true;
-#endif
-
-/* variables for time measurement: */
-
-#ifdef TIMES
-struct tms time_info;
-extern int times ();
- /* see library function "times" */
-#define Too_Small_Time 120
- /* Measurements should last at least about 2 seconds */
-#endif
-#ifdef TIME
-extern long time();
- /* see library function "time" */
-#define Too_Small_Time 2
- /* Measurements should last at least 2 seconds */
-#endif
-
-long Begin_Time,
- End_Time,
- User_Time;
-float Microseconds,
- Dhrystones_Per_Second;
-
-/* end of variables for time measurement */
-
-
-main ()
-/*****/
-
- /* main program, corresponds to procedures */
- /* Main and Proc_0 in the Ada version */
-{
- One_Fifty Int_1_Loc;
- REG One_Fifty Int_2_Loc;
- One_Fifty Int_3_Loc;
- REG char Ch_Index;
- Enumeration Enum_Loc;
- Str_30 Str_1_Loc;
- Str_30 Str_2_Loc;
- REG int Run_Index;
- REG int Number_Of_Runs;
-
- /* Initializations */
-
- Next_Ptr_Glob = (Rec_Pointer) malloc (sizeof (Rec_Type));
- Ptr_Glob = (Rec_Pointer) malloc (sizeof (Rec_Type));
-
- Ptr_Glob->Ptr_Comp = Next_Ptr_Glob;
- Ptr_Glob->Discr = Ident_1;
- Ptr_Glob->variant.var_1.Enum_Comp = Ident_3;
- Ptr_Glob->variant.var_1.Int_Comp = 40;
- strcpy (Ptr_Glob->variant.var_1.Str_Comp,
- "DHRYSTONE PROGRAM, SOME STRING");
- strcpy (Str_1_Loc, "DHRYSTONE PROGRAM, 1'ST STRING");
-
- Arr_2_Glob [8][7] = 10;
- /* Was missing in published program. Without this statement, */
- /* Arr_2_Glob [8][7] would have an undefined value. */
- /* Warning: With 16-Bit processors and Number_Of_Runs > 32000, */
- /* overflow may occur for this array element. */
-
- printf ("\n");
- printf ("Dhrystone Benchmark, Version 2.1 (Language: C)\n");
- printf ("\n");
- if (Reg)
- {
- printf ("Program compiled with 'register' attribute\n");
- printf ("\n");
- }
- else
- {
- printf ("Program compiled without 'register' attribute\n");
- printf ("\n");
- }
- printf ("Please give the number of runs through the benchmark: ");
- {
- int n;
- scanf ("%d", &n);
- Number_Of_Runs = n;
- }
- printf ("\n");
-
- printf ("Execution starts, %d runs through Dhrystone\n", Number_Of_Runs);
-
- /***************/
- /* Start timer */
- /***************/
-
-#ifdef TIMES
- times (&time_info);
- Begin_Time = (long) time_info.tms_utime;
-#endif
-#ifdef TIME
- Begin_Time = time ( (long *) 0);
-#endif
-
- for (Run_Index = 1; Run_Index <= Number_Of_Runs; ++Run_Index)
- {
-
- Proc_5();
- Proc_4();
- /* Ch_1_Glob == 'A', Ch_2_Glob == 'B', Bool_Glob == true */
- Int_1_Loc = 2;
- Int_2_Loc = 3;
- strcpy (Str_2_Loc, "DHRYSTONE PROGRAM, 2'ND STRING");
- Enum_Loc = Ident_2;
- Bool_Glob = ! Func_2 (Str_1_Loc, Str_2_Loc);
- /* Bool_Glob == 1 */
- while (Int_1_Loc < Int_2_Loc) /* loop body executed once */
- {
- Int_3_Loc = 5 * Int_1_Loc - Int_2_Loc;
- /* Int_3_Loc == 7 */
- Proc_7 (Int_1_Loc, Int_2_Loc, &Int_3_Loc);
- /* Int_3_Loc == 7 */
- Int_1_Loc += 1;
- } /* while */
- /* Int_1_Loc == 3, Int_2_Loc == 3, Int_3_Loc == 7 */
- Proc_8 (Arr_1_Glob, Arr_2_Glob, Int_1_Loc, Int_3_Loc);
- /* Int_Glob == 5 */
- Proc_1 (Ptr_Glob);
- for (Ch_Index = 'A'; Ch_Index <= Ch_2_Glob; ++Ch_Index)
- /* loop body executed twice */
- {
- if (Enum_Loc == Func_1 (Ch_Index, 'C'))
- /* then, not executed */
- {
- Proc_6 (Ident_1, &Enum_Loc);
- strcpy (Str_2_Loc, "DHRYSTONE PROGRAM, 3'RD STRING");
- Int_2_Loc = Run_Index;
- Int_Glob = Run_Index;
- }
- }
- /* Int_1_Loc == 3, Int_2_Loc == 3, Int_3_Loc == 7 */
- Int_2_Loc = Int_2_Loc * Int_1_Loc;
- Int_1_Loc = Int_2_Loc / Int_3_Loc;
- Int_2_Loc = 7 * (Int_2_Loc - Int_3_Loc) - Int_1_Loc;
- /* Int_1_Loc == 1, Int_2_Loc == 13, Int_3_Loc == 7 */
- Proc_2 (&Int_1_Loc);
- /* Int_1_Loc == 5 */
-
- } /* loop "for Run_Index" */
-
- /**************/
- /* Stop timer */
- /**************/
-
-#ifdef TIMES
- times (&time_info);
- End_Time = (long) time_info.tms_utime;
-#endif
-#ifdef TIME
- End_Time = time ( (long *) 0);
-#endif
-
- printf ("Execution ends\n");
- printf ("\n");
- printf ("Final values of the variables used in the benchmark:\n");
- printf ("\n");
- printf ("Int_Glob: %d\n", Int_Glob);
- printf (" should be: %d\n", 5);
- printf ("Bool_Glob: %d\n", Bool_Glob);
- printf (" should be: %d\n", 1);
- printf ("Ch_1_Glob: %c\n", Ch_1_Glob);
- printf (" should be: %c\n", 'A');
- printf ("Ch_2_Glob: %c\n", Ch_2_Glob);
- printf (" should be: %c\n", 'B');
- printf ("Arr_1_Glob[8]: %d\n", Arr_1_Glob[8]);
- printf (" should be: %d\n", 7);
- printf ("Arr_2_Glob[8][7]: %d\n", Arr_2_Glob[8][7]);
- printf (" should be: Number_Of_Runs + 10\n");
- printf ("Ptr_Glob->\n");
- printf (" Ptr_Comp: %d\n", (int) Ptr_Glob->Ptr_Comp);
- printf (" should be: (implementation-dependent)\n");
- printf (" Discr: %d\n", Ptr_Glob->Discr);
- printf (" should be: %d\n", 0);
- printf (" Enum_Comp: %d\n", Ptr_Glob->variant.var_1.Enum_Comp);
- printf (" should be: %d\n", 2);
- printf (" Int_Comp: %d\n", Ptr_Glob->variant.var_1.Int_Comp);
- printf (" should be: %d\n", 17);
- printf (" Str_Comp: %s\n", Ptr_Glob->variant.var_1.Str_Comp);
- printf (" should be: DHRYSTONE PROGRAM, SOME STRING\n");
- printf ("Next_Ptr_Glob->\n");
- printf (" Ptr_Comp: %d\n", (int) Next_Ptr_Glob->Ptr_Comp);
- printf (" should be: (implementation-dependent), same as above\n");
- printf (" Discr: %d\n", Next_Ptr_Glob->Discr);
- printf (" should be: %d\n", 0);
- printf (" Enum_Comp: %d\n", Next_Ptr_Glob->variant.var_1.Enum_Comp);
- printf (" should be: %d\n", 1);
- printf (" Int_Comp: %d\n", Next_Ptr_Glob->variant.var_1.Int_Comp);
- printf (" should be: %d\n", 18);
- printf (" Str_Comp: %s\n",
- Next_Ptr_Glob->variant.var_1.Str_Comp);
- printf (" should be: DHRYSTONE PROGRAM, SOME STRING\n");
- printf ("Int_1_Loc: %d\n", Int_1_Loc);
- printf (" should be: %d\n", 5);
- printf ("Int_2_Loc: %d\n", Int_2_Loc);
- printf (" should be: %d\n", 13);
- printf ("Int_3_Loc: %d\n", Int_3_Loc);
- printf (" should be: %d\n", 7);
- printf ("Enum_Loc: %d\n", Enum_Loc);
- printf (" should be: %d\n", 1);
- printf ("Str_1_Loc: %s\n", Str_1_Loc);
- printf (" should be: DHRYSTONE PROGRAM, 1'ST STRING\n");
- printf ("Str_2_Loc: %s\n", Str_2_Loc);
- printf (" should be: DHRYSTONE PROGRAM, 2'ND STRING\n");
- printf ("\n");
-
- User_Time = End_Time - Begin_Time;
-
- if (User_Time < Too_Small_Time)
- {
- printf ("Measured time too small to obtain meaningful results\n");
- printf ("Please increase number of runs\n");
- printf ("\n");
- }
- else
- {
-#ifdef TIME
- Microseconds = (float) User_Time * Mic_secs_Per_Second
- / (float) Number_Of_Runs;
- Dhrystones_Per_Second = (float) Number_Of_Runs / (float) User_Time;
-#else
- Microseconds = (float) User_Time * Mic_secs_Per_Second
- / ((float) HZ * ((float) Number_Of_Runs));
- Dhrystones_Per_Second = ((float) HZ * (float) Number_Of_Runs)
- / (float) User_Time;
-#endif
- printf ("Microseconds for one run through Dhrystone: ");
- printf ("%6.1f \n", Microseconds);
- printf ("Dhrystones per Second: ");
- printf ("%6.1f \n", Dhrystones_Per_Second);
- printf ("\n");
- }
-
-}
-
-
-Proc_1 (Ptr_Val_Par)
-/******************/
-
-REG Rec_Pointer Ptr_Val_Par;
- /* executed once */
-{
- REG Rec_Pointer Next_Record = Ptr_Val_Par->Ptr_Comp;
- /* == Ptr_Glob_Next */
- /* Local variable, initialized with Ptr_Val_Par->Ptr_Comp, */
- /* corresponds to "rename" in Ada, "with" in Pascal */
-
- structassign (*Ptr_Val_Par->Ptr_Comp, *Ptr_Glob);
- Ptr_Val_Par->variant.var_1.Int_Comp = 5;
- Next_Record->variant.var_1.Int_Comp
- = Ptr_Val_Par->variant.var_1.Int_Comp;
- Next_Record->Ptr_Comp = Ptr_Val_Par->Ptr_Comp;
- Proc_3 (&Next_Record->Ptr_Comp);
- /* Ptr_Val_Par->Ptr_Comp->Ptr_Comp
- == Ptr_Glob->Ptr_Comp */
- if (Next_Record->Discr == Ident_1)
- /* then, executed */
- {
- Next_Record->variant.var_1.Int_Comp = 6;
- Proc_6 (Ptr_Val_Par->variant.var_1.Enum_Comp,
- &Next_Record->variant.var_1.Enum_Comp);
- Next_Record->Ptr_Comp = Ptr_Glob->Ptr_Comp;
- Proc_7 (Next_Record->variant.var_1.Int_Comp, 10,
- &Next_Record->variant.var_1.Int_Comp);
- }
- else /* not executed */
- structassign (*Ptr_Val_Par, *Ptr_Val_Par->Ptr_Comp);
-} /* Proc_1 */
-
-
-Proc_2 (Int_Par_Ref)
-/******************/
- /* executed once */
- /* *Int_Par_Ref == 1, becomes 4 */
-
-One_Fifty *Int_Par_Ref;
-{
- One_Fifty Int_Loc;
- Enumeration Enum_Loc;
-
- Int_Loc = *Int_Par_Ref + 10;
- do /* executed once */
- if (Ch_1_Glob == 'A')
- /* then, executed */
- {
- Int_Loc -= 1;
- *Int_Par_Ref = Int_Loc - Int_Glob;
- Enum_Loc = Ident_1;
- } /* if */
- while (Enum_Loc != Ident_1); /* true */
-} /* Proc_2 */
-
-
-Proc_3 (Ptr_Ref_Par)
-/******************/
- /* executed once */
- /* Ptr_Ref_Par becomes Ptr_Glob */
-
-Rec_Pointer *Ptr_Ref_Par;
-
-{
- if (Ptr_Glob != Null)
- /* then, executed */
- *Ptr_Ref_Par = Ptr_Glob->Ptr_Comp;
- Proc_7 (10, Int_Glob, &Ptr_Glob->variant.var_1.Int_Comp);
-} /* Proc_3 */
-
-
-Proc_4 () /* without parameters */
-/*******/
- /* executed once */
-{
- Boolean Bool_Loc;
-
- Bool_Loc = Ch_1_Glob == 'A';
- Bool_Glob = Bool_Loc | Bool_Glob;
- Ch_2_Glob = 'B';
-} /* Proc_4 */
-
-
-Proc_5 () /* without parameters */
-/*******/
- /* executed once */
-{
- Ch_1_Glob = 'A';
- Bool_Glob = false;
-} /* Proc_5 */
-
-
- /* Procedure for the assignment of structures, */
- /* if the C compiler doesn't support this feature */
-#ifdef NOSTRUCTASSIGN
-memcpy (d, s, l)
-register char *d;
-register char *s;
-register int l;
-{
- while (l--) *d++ = *s++;
-}
-#endif
-
-
//GO.SYSIN DD dhry_1.c
echo dhry_2.c 1>&2
sed >dhry_2.c <<'//GO.SYSIN DD dhry_2.c' 's/^-//'
-/*
- ****************************************************************************
- *
- * "DHRYSTONE" Benchmark Program
- * -----------------------------
- *
- * Version: C, Version 2.1
- *
- * File: dhry_2.c (part 3 of 3)
- *
- * Date: May 25, 1988
- *
- * Author: Reinhold P. Weicker
- *
- ****************************************************************************
- */
-
-#include "dhry.h"
-
-#ifndef REG
-#define REG
- /* REG becomes defined as empty */
- /* i.e. no register variables */
-#endif
-
-extern int Int_Glob;
-extern char Ch_1_Glob;
-
-
-Proc_6 (Enum_Val_Par, Enum_Ref_Par)
-/*********************************/
- /* executed once */
- /* Enum_Val_Par == Ident_3, Enum_Ref_Par becomes Ident_2 */
-
-Enumeration Enum_Val_Par;
-Enumeration *Enum_Ref_Par;
-{
- *Enum_Ref_Par = Enum_Val_Par;
- if (! Func_3 (Enum_Val_Par))
- /* then, not executed */
- *Enum_Ref_Par = Ident_4;
- switch (Enum_Val_Par)
- {
- case Ident_1:
- *Enum_Ref_Par = Ident_1;
- break;
- case Ident_2:
- if (Int_Glob > 100)
- /* then */
- *Enum_Ref_Par = Ident_1;
- else *Enum_Ref_Par = Ident_4;
- break;
- case Ident_3: /* executed */
- *Enum_Ref_Par = Ident_2;
- break;
- case Ident_4: break;
- case Ident_5:
- *Enum_Ref_Par = Ident_3;
- break;
- } /* switch */
-} /* Proc_6 */
-
-
-Proc_7 (Int_1_Par_Val, Int_2_Par_Val, Int_Par_Ref)
-/**********************************************/
- /* executed three times */
- /* first call: Int_1_Par_Val == 2, Int_2_Par_Val == 3, */
- /* Int_Par_Ref becomes 7 */
- /* second call: Int_1_Par_Val == 10, Int_2_Par_Val == 5, */
- /* Int_Par_Ref becomes 17 */
- /* third call: Int_1_Par_Val == 6, Int_2_Par_Val == 10, */
- /* Int_Par_Ref becomes 18 */
-One_Fifty Int_1_Par_Val;
-One_Fifty Int_2_Par_Val;
-One_Fifty *Int_Par_Ref;
-{
- One_Fifty Int_Loc;
-
- Int_Loc = Int_1_Par_Val + 2;
- *Int_Par_Ref = Int_2_Par_Val + Int_Loc;
-} /* Proc_7 */
-
-
-Proc_8 (Arr_1_Par_Ref, Arr_2_Par_Ref, Int_1_Par_Val, Int_2_Par_Val)
-/*********************************************************************/
- /* executed once */
- /* Int_Par_Val_1 == 3 */
- /* Int_Par_Val_2 == 7 */
-Arr_1_Dim Arr_1_Par_Ref;
-Arr_2_Dim Arr_2_Par_Ref;
-int Int_1_Par_Val;
-int Int_2_Par_Val;
-{
- REG One_Fifty Int_Index;
- REG One_Fifty Int_Loc;
-
- Int_Loc = Int_1_Par_Val + 5;
- Arr_1_Par_Ref [Int_Loc] = Int_2_Par_Val;
- Arr_1_Par_Ref [Int_Loc+1] = Arr_1_Par_Ref [Int_Loc];
- Arr_1_Par_Ref [Int_Loc+30] = Int_Loc;
- for (Int_Index = Int_Loc; Int_Index <= Int_Loc+1; ++Int_Index)
- Arr_2_Par_Ref [Int_Loc] [Int_Index] = Int_Loc;
- Arr_2_Par_Ref [Int_Loc] [Int_Loc-1] += 1;
- Arr_2_Par_Ref [Int_Loc+20] [Int_Loc] = Arr_1_Par_Ref [Int_Loc];
- Int_Glob = 5;
-} /* Proc_8 */
-
-
-Enumeration Func_1 (Ch_1_Par_Val, Ch_2_Par_Val)
-/*************************************************/
- /* executed three times */
- /* first call: Ch_1_Par_Val == 'H', Ch_2_Par_Val == 'R' */
- /* second call: Ch_1_Par_Val == 'A', Ch_2_Par_Val == 'C' */
- /* third call: Ch_1_Par_Val == 'B', Ch_2_Par_Val == 'C' */
-
-Capital_Letter Ch_1_Par_Val;
-Capital_Letter Ch_2_Par_Val;
-{
- Capital_Letter Ch_1_Loc;
- Capital_Letter Ch_2_Loc;
-
- Ch_1_Loc = Ch_1_Par_Val;
- Ch_2_Loc = Ch_1_Loc;
- if (Ch_2_Loc != Ch_2_Par_Val)
- /* then, executed */
- return (Ident_1);
- else /* not executed */
- {
- Ch_1_Glob = Ch_1_Loc;
- return (Ident_2);
- }
-} /* Func_1 */
-
-
-Boolean Func_2 (Str_1_Par_Ref, Str_2_Par_Ref)
-/*************************************************/
- /* executed once */
- /* Str_1_Par_Ref == "DHRYSTONE PROGRAM, 1'ST STRING" */
- /* Str_2_Par_Ref == "DHRYSTONE PROGRAM, 2'ND STRING" */
-
-Str_30 Str_1_Par_Ref;
-Str_30 Str_2_Par_Ref;
-{
- REG One_Thirty Int_Loc;
- Capital_Letter Ch_Loc;
-
- Int_Loc = 2;
- while (Int_Loc <= 2) /* loop body executed once */
- if (Func_1 (Str_1_Par_Ref[Int_Loc],
- Str_2_Par_Ref[Int_Loc+1]) == Ident_1)
- /* then, executed */
- {
- Ch_Loc = 'A';
- Int_Loc += 1;
- } /* if, while */
- if (Ch_Loc >= 'W' && Ch_Loc < 'Z')
- /* then, not executed */
- Int_Loc = 7;
- if (Ch_Loc == 'R')
- /* then, not executed */
- return (true);
- else /* executed */
- {
- if (strcmp (Str_1_Par_Ref, Str_2_Par_Ref) > 0)
- /* then, not executed */
- {
- Int_Loc += 7;
- Int_Glob = Int_Loc;
- return (true);
- }
- else /* executed */
- return (false);
- } /* if Ch_Loc */
-} /* Func_2 */
-
-
-Boolean Func_3 (Enum_Par_Val)
-/***************************/
- /* executed once */
- /* Enum_Par_Val == Ident_3 */
-Enumeration Enum_Par_Val;
-{
- Enumeration Enum_Loc;
-
- Enum_Loc = Enum_Par_Val;
- if (Enum_Loc == Ident_3)
- /* then, executed */
- return (true);
- else /* not executed */
- return (false);
-} /* Func_3 */
-
//GO.SYSIN DD dhry_2.c
echo dhry_c.dif 1>&2
sed >dhry_c.dif <<'//GO.SYSIN DD dhry_c.dif' 's/^-//'
-7c7
-< * Version: C, Version 2.1
----
-> * Version: C, Version 2.0
-9c9
-< * File: dhry.h (part 1 of 3)
----
-> * File: dhry_global.h (part 1 of 3)
-11c11
-< * Date: May 25, 1988
----
-> * Date: March 3, 1988
-30c30
-< * In addition, Berkeley UNIX system calls "times ()" or "time ()"
----
-> * In addition, UNIX system calls "times ()" or "time ()"
-44c44
-< * Please send results to Rick Richardson and/or Reinhold Weicker.
----
-> * Please send results to Reinhold Weicker and/or Rick Richardson.
-59c59
-< * History: This version C/2.1 has been made for two reasons:
----
-> * History: This version C/2.0 has been made for two reasons:
-123,129d122
-< * Version 2.1 is identical to version 2.0 distributed via
-< * the UNIX network Usenet in March 1988 except that it corrects
-< * some minor deficiencies that were found by users of version 2.0.
-< * The only change within the measurement loop is that a
-< * non-executed "else" part was added to the "if" statement in
-< * Func_3, and a non-executed "else" part removed from Proc_3.
-< *
-165,167c158,160
-< * -DHZ=nnn
-< * In Berkeley UNIX, the function "times" returns process
-< * time in 1/HZ seconds, with HZ = 60 for most systems.
----
-> * -DHZ=nnn (default: 60)
-> * The function "times" returns process times in
-> * 1/HZ seconds, with HZ = 60 for most systems.
-169c162
-< * A VALUE.
----
-> * THE DEFAULT VALUE.
-176,178c169,171
-< * - dhry.h (this file, containing global definitions and comments)
-< * - dhry_1.c (containing the code corresponding to Ada package Pack_1)
-< * - dhry_2.c (containing the code corresponding to Ada package Pack_2)
----
-> * - dhry_global.h (this file, containing global definitions and comments)
-> * - dhry_pack_1.c (containing the code corresponding to Ada package Pack_1)
-> * - dhry_pack_2.c (containing the code corresponding to Ada package Pack_2)
-350a344
-> #ifndef TIMES
-353,354c347,354
-< /* Use times(2) time function unless */
-< /* explicitly defined otherwise */
----
-> #endif
-> /* Use "times" function for measurement */
-> /* unless explicitly defined otherwise */
-> #ifndef HZ
-> #define HZ 60
-> #endif
-> /* Use HZ = 60 for "times" function */
-> /* unless explicitly defined otherwise */
-363c363
-< /* Berkeley UNIX C returns process times in seconds/HZ */
----
-> /* UNIX C returns process times in seconds/HZ */
-7c7
-< * Version: C, Version 2.1
----
-> * Version: C, Version 2.0
-9c9
-< * File: dhry_1.c (part 2 of 3)
----
-> * File: dhry_pack_1.c (part 2 of 3)
-11c11
-< * Date: May 25, 1988
----
-> * Date: March 3, 1988
-18c18
-< #include "dhry.h"
----
-> #include "dhry_global.h"
-50,51d49
-< #define Too_Small_Time 120
-< /* Measurements should last at least about 2 seconds */
-55a54,55
-> #endif
->
-58d57
-< #endif
-73a73
->
-84a85
->
-99,100c100,102
-< /* Was missing in published program. Without this statement, */
-< /* Arr_2_Glob [8][7] would have an undefined value. */
----
-> /* Was missing in published program. Without this */
-> /* initialization, Arr_2_Glob [8][7] would have an */
-> /* undefined value. */
-105c107
-< printf ("Dhrystone Benchmark, Version 2.1 (Language: C)\n");
----
-> printf ("Dhrystone Benchmark, Version 2.0 (Language: C)\n");
-281c283
-< /******************/
----
-> /**********************/
-338c340
-< /******************/
----
-> /**********************/
-347a350,351
-> else /* not executed */
-> Int_Glob = 100;
-349a354
->
-7c7
-< * Version: C, Version 2.1
----
-> * Version: C, Version 2.0
-9c9
-< * File: dhry_2.c (part 3 of 3)
----
-> * File: dhry_pack_2.c (part 3 of 3)
-11c11
-< * Date: May 25, 1988
----
-> * Date: March 3, 1988
-18c18
-< #include "dhry.h"
----
-> #include "dhry_global.h"
-189,190d188
-< else /* not executed */
-< return (false);
//GO.SYSIN DD dhry_c.dif
echo submit.frm 1>&2
sed >submit.frm <<'//GO.SYSIN DD submit.frm' 's/^-//'
-DHRYSTONE 2.1 BENCHMARK REPORTING FORM
-MANUF:
-MODEL:
-PROC:
-CLOCK:
-OS:
-OVERSION:
-COMPILER:
-CVERSION:
-OPTIONS:
-NOREG:
-REG:
-NOTES:
-DATE:
-SUBMITTER:
-CODESIZE:
-MAILTO: uunet!pcrat!dry2
//GO.SYSIN DD submit.frm
SYSTEM SPECIFICATIONS (PEAK PERFORMANCE)
https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/a100/pdf/nvidia-a100-datasheet.pdf
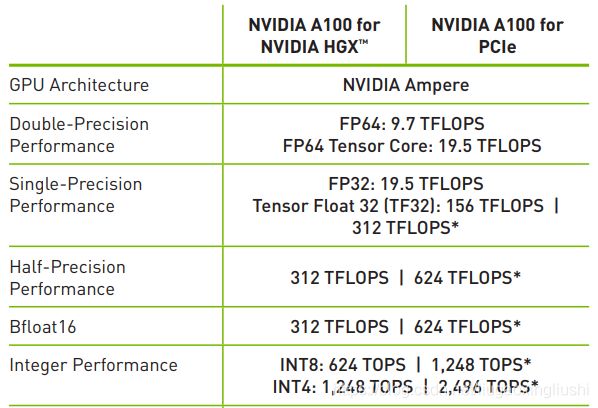
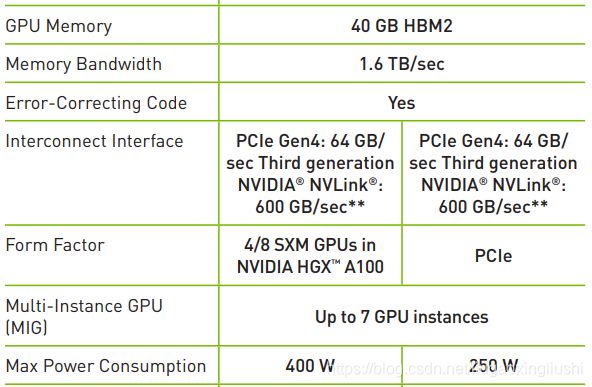
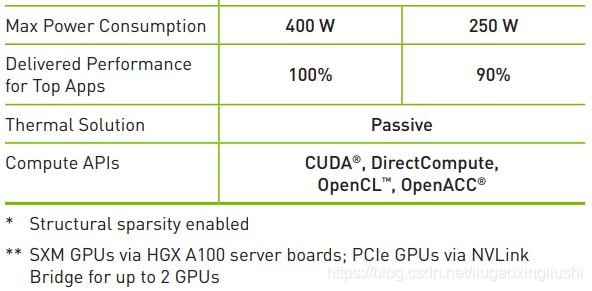
FLOPS
REF: https://en.wikipedia.org/wiki/FLOPS
Computational performance[edit]
FLOPS and MIPS are units of measure for the numerical computing performance of a computer. Floating-point operations are typically used in fields such as scientific computational research. The unit MIPS measures integer performance of a computer. Examples of integer operation include data movement (A to B) or value testing (If A = B, then C). MIPS as a performance benchmark is adequate when a computer is used in database queries, word processing, spreadsheets, or to run multiple virtual operating systems.[3][4] Frank H. McMahon, of the Lawrence Livermore National Laboratory, invented the terms FLOPS and MFLOPS (megaFLOPS) so that he could compare the supercomputers of the day by the number of floating-point calculations they performed per second. This was much better than using the prevalent MIPS to compare computers as this statistic usually had little bearing on the arithmetic capability of the machine.
FLOPS on an HPC-system can be calculated using this equation:
![]()
This can be simplified to the most common case: a computer that has exactly 1 CPU:
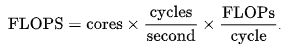
FLOPS can be recorded in different measures of precision, for example, the TOP500 supercomputer list ranks computers by 64 bit (double-precision floating-point format) operations per second, abbreviated to FP64.[6] Similar measures are available for 32-bit (FP32) and 16-bit] (FP16) operations.
TOPS
REF: https://newsroom.intel.com/wp-content/uploads/sites/11/2017/12/ad-comp-fact-sheet.pdf
(Tera Operations Per Second) TOPS is a measurement of the overall performance of an SoC (complete system on one chip). The term may also mean "total OPS" or "theoretical OPS." See SoC and teraFLOPS.
Tera Operations Per Second (TOPS) is a common performance metric used for high-performance SoCs; TOPS per watt extends that measurement to describe performance efficiency. The higher the TOPS per watt the better. Higher TOPS/watt systems produce less heat, are easier and less expensive to cool and consume less power leading to greater fuel economy or longer range in for an EV. For Intel and Mobileye customers, this ultimately translates to lower vehicle and operating costs and more design choices and greater flexibility in terms of where you place the compute box inside an autonomous vehicle.
REF:https://semiengineering.com/tops-memory-throughput-and-inference-efficiency/#:~:text=What%20is%20TOPS%3F,of%20MAC%20operations)%20x%202.
Almost every AI company gives TOPS but little other information.
What is TOPS? It means Trillions or Tera Operations per Second. It is primarily a measure of the maximum achievable throughput but not a measure of actual throughput. Most operations are MACs (multiply/accumulates), so TOPS = (number of MAC units) x (frequency of MAC operations) x 2.
So more TOPS means more silicon area, more cost, more power and maybe more throughput, but that depends on other aspects of the inference accelerator.
TOPS is not enough information. You need to know the throughput for your model, your image size, your batch size – this will tell you if the chip or IP will meet your throughput requirement.
REF: https://medium.com/analytics-vidhya/not-all-tops-are-created-equal-e1911ffb4a82
Deep Learning processor companies often highlight their products’ blazing-fast speeds in terms of metrics such as Tera Operations per Second (TOP/s) or Tera Multiply-Accumulate Instructions per Second (TMAC/s). What does this really mean, and are these numbers actually useful?
But first, what does this have to do with deep learning?
Let’s consider a convolution layer with 3x3x100 filters and 100 output channels.
- Let’s say that this layer has an input grid of size 50x50x100. So, for the forward-pass, this requires 3*3*100*100*50*50 = 225,000,000 MACs, which is equivalent to 450,000,000 OPs, because one MAC is two OPs.
- But, when a processor company says that a processor can do a certain number of MACs per second or OPs per second, will you actually achieve that number? Well, the numbers quoted by processor companies are “peak” (i.e. theoretical best-case) numbers.
- In reality, your mileage may vary. For example, in a recent paper called EMBench, it was shown that two deep neural networks (DNNs) with the same number of MACs can have a 10x difference in latency on the same computing platform.
What’s causing these slowdowns? In the following, we present an (incomplete) list of the problems that can prevent your DNN from achieving the theoretical peak speed on a computing platform. We primarily focus on common problems that can limit the speed of DNN inference, but many of these also are relevant for DNN training.