字符和字符串的库函数模拟与实现

前言:
相信大家平常在写代码的时候,用代码解决实际问题时苦于某种功能的实现,而望而止步,这个时候库函数的好处就体现出来了,当然个人代码编写能力强的可以自己创建一个函数,不过相当于库函数来说却是浪费了一点时间,库函数的准确性和有效性对我们的好处就显而易见了。本次重点是着重介绍字符函数和字符串函数的模拟和实现
本章重点知识点:
(1)求字符串长度
(2)长度不受限制的字符串函数
(3)长度受限制的字符串函数介
1、函数的介绍
1.1 strlen函数

size_t strlen (const char *str);
头文件名:#include
size_t 是表示无符号整数的意思,也就相当于unsigned int 。
实际用法:
#include
int main()
{
char arr1[] = "abcdef";
int net = strlen(arr1);printf("%d", net) ;
return 0;
}

众所周知字符串以'\0'为结束标志,strlen函数返回的是在字符串中 '\0' 前面出现的字符个数(不包 含 '\0' )。
1.2 strcpy函数

char *strcpy (char *destination, const char *source)
头文件名:#include
const函数用来限制 *source,也就是指针*source 不能随意改变数据。
比如:
int main()
{
int b = 10;
int* p = &b;
*p = 6;
return 0;
}

此时*p在没有const函数修饰的情况下*p可以随意更改所指的数据大小 。
int main()
{
int b = 10;
const int* p = &b;
*p = 6;
return 0;
}

而现在*p有了const函数修饰,现在运行程序就会报错。
所以该函数的用法就知道了,用指针*source所指向地址的数据复制到指针*destination中。
下面来看strcpy函数实际用法:
#include
#include
int main()
{
char arr1[20] = { 0 };
char arr2[20] = "abcdefgh";
strcpy(arr1, arr2);
printf("%s", arr1);
return 0;
}

为了arr2中能够完全的存放下arr1中的数据,所以arr2的空间与arr1一致,当然在arr2创建的空间足够大的前提下 arr[20]也可以变成这样写arr[],这样也是符合语法标准。
1.3 strcat函数

char *strcat (char *destination, const char *source)
头文件名:#include
const函数的用法在介绍strcpy函数时就已经讲到了对于还不太清楚的伙伴可以往上翻一下,了解明白,在此后就不做过多解释了。

此次strcat函数里的参数和strcpy函数里的参数的内容大致相同,不过用法确实大不相同。
从第一个图中几个关键词:来源,目的,串联等,应该不难想到,该函数应该是把后面字符串的内容连接到第一个 字符串后面。
实际应用:
#include
#include
int main()
{
char arr1[20000] = "abcdef";
char arr2[20] = "yangyang";
strcat(arr1, arr2);
printf("%s", arr1);
return 0;
}

运行后该函数的用法和我们所猜的差不多。在程序中,因为是把第二个字符串连接到第一个 字符串中,所以第一个字符串数组的空间必须大,所以我才给了arr1这么大的空间,当然在保证了第一个字符串数组足够大的情况下,arr2[20]也可以写成arr2[]。
1.4 strcmp函数


int strcmp(const char *str1, const char *str2)
头文件名:#include
此函数较前几个函数还是有很大不同,光两个参数就不能随意改变,而且返回值有很大区别,上面函数的函数返回值大多都是void型,而此函数的返回值是int型。根据图中的意思,该函数是一个比较两个字符串大小的函数。如果两个字符串相等就返回0,如果是第一个字符串大于第二个字符串就返回大于0的整数,反之就会返回小于0的数。在比较时前提是所比较的字符必须表示同一个大小,不然即使多,但实际比出来也是小。
实际应用:
#include
int main()
{
char arr1[] = "abcdefgh";
char arr2[] = "abcdefghgdhs";char abb1[] = "abcdef";
char abb2[] = "abc";char acc1[] = "abcdef";
char acc2[] = "abcdef";int num1 = strcmp(arr1, arr2);
int num2 = strcmp(abb1, abb2);
int num3 = strcmp(acc1, acc2);printf("num1 = %d\nnum2 = %d\nnum3 = %d\n", num1, num2, num3);
return 0;
}
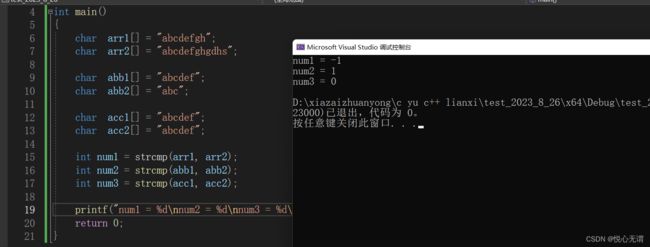
相信有了这个strcmp函数,大家在平常计算字符串长度会更加方便。
1.5 strncpy函数

char *strncpy(char *destinnation, const char *source, size_t num)
头文件名:#include
size_t是无符号整型,而根据图中的解释这个函数仅仅比strcpy函数多了第二个字符串可以指定多少字节的字符来复制在第一个字符串中的功能。
实际应用1:
#include
#include
int main()
{
char arr1[2000] = { 0 };
char arr2[] = "abcdef";strncpy(arr1, arr2, 5);
printf("%s\n", arr1);
return 0;
}

此函数比strcpy用的范围更大,更适应如今变化多端的局面。
1.6 strncat函数

char *strncat (char *destination, const char *source, size_t num)
头文件名:#include
此函数也比strcat函数多了第二个字符串可以指定多少字符连接在第一个字符串的后面的功能其它大体都是相同。
实际应用:
#include
#include
int main()
{
char arr1[2000] = "abcd";
char arr2[] = "abcdefgh";strncat(arr1, arr2, 4);
printf("%s\n", arr1);
return 0;
}

更方便大家的使用。
1.7 strncmp函数


int strncmp ( const char * str1, const char * str2, size_t num );
头文件名:#include
此函数较strcmp函数也只是多了可以指定用多少字节的字符来比较的功能,其它的大体相同。比上面几个函数有点不同,此函数的后面的数字是作用于两个字符串,而不仅仅作用于第二个字符串了。
实际应用:
#include
#include
int main()
{
char arr1[] = "abcd";
char arr2[] = "abcdefgh";char arr3[] = "abcdef";
char arr4[] = "abcd";int num1 = strncmp(arr1, arr2, 2);
int num2 = strncmp(arr1, arr2, 6);
int num3 = strncmp(arr1, arr2, 4);
int num4 = strncmp(arr3, arr4, 6);printf("num1 = %d\nnum2 = %d\nnum3 = %d\n", num1, num2, num3);
printf("%d\n", num4);
return 0;
}

多出的功能也只是为了方便使用,更灵活。
1.8 strstr函数

char * strstr ( const char *str1, const char * str2)
头文件名:#include
根据图中的意思,此函数大概就是寻找子函数,并打印子函数及其后面的内容,返回值也是char *指针。
实际应用:
#include
#include
int main()
{
char arr1[20] = "abcdefgh";
char arr2[20] = "de";char *str = strstr(arr1, arr2);
printf("%s\n", str);
return 0;
}

1.9 strtok函数

char * strtok ( char * str, const char * sep )
头文件名:#include
此函数的参数和strstr函数的参数大致相同表达的意思有些许的差别,由const函数可知该函数的第二个参数是不能变,而图中拆分字样,那第一个参数应该是等同于标识符,把第二个参数分成多组字符然后再打,分隔符的顺序是没有讲究的,随便放就可以。
sep参数是个字符串,定义了用作分隔符的字符集合
第一个参数指定一个字符串,它包含了0个或者多个由sep字符串中一个或者多个分隔符分割的标 记。
实际应用:
#include
#include
int main()
{
char arr1[20] = "abc@def、jkm.klj";
char arr2[10] = "@、.";
char coop[20] = { 0 };
strcpy(coop, arr1);
char* str = NULL;
for (str = strtok(coop, arr2); str != NULL; str = strtok(NULL, arr2))
{
printf("%s\n", str);
}
return 0;
}
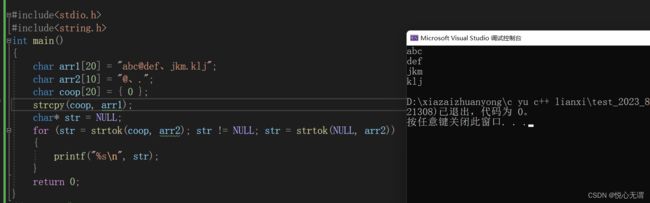
上面那段for循环那段函数可有有些人看不懂,它可以还可以替换成:
str = strtok(coop, arr2);
printf("%s\n", str);str = strtok(NULL, arr2);
printf("%s\n", str);str = strtok(NULL, arr2);
printf("%s\n", str);str = strtok(NULL, arr2);
printf("%s\n", str);
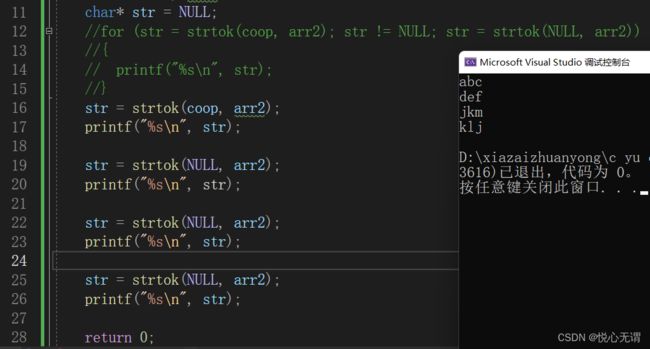
两种写法是表达一样的意思。
1.10 strerror函数

char *strerror(int errnum )
头文件名:#include
根据图中的意思,这个函数大概就是:返回错误码,所对应的错误信息。
实际应用:
#include

1.11 memcpy函数

void *memcpy (void *destination , const void * source, size_t num)
头文件名:#include
虽然此函数也是复制函数但是较前面几个函数不同,这是内存函数。由它是void型就大致知道,大部分结构都能复制,比较灵活。也能指定多少数据复制,只不过第三个参数是以字节为单位
实际应用:
#include
#include
int main()
{
int abb1[10] = { 1,2,3,4,5,6,7,8,9,10 };
int abb2[20] = { 0 };char arr1[10] = "abcdefghi";
char arr2[20] = { 0 };memcpy(abb2, abb1, 20);
memcpy(arr2, arr1, 20);int i = 0;
for (i = 0; i < 20; i++)
{
printf("%d ", abb2[i]);
}
printf("\n");printf("%s\n", arr2);
return 0;
}
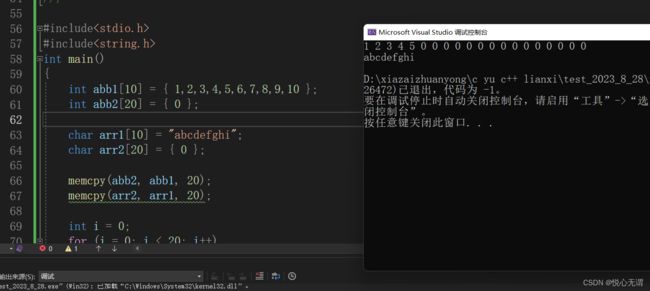
从上图中可知当空间过剩时会用0来补上,而当是字符串传递时就不会,如下图:

1.12 memmove函数

void *memmove( void *destination, const void *source, size_t num)
头文件名:#include
此函数和memcpy函数功能大体相同,memmove可以说成是memcpy的子集,memcpy只能复制两个来自不同空间,不能有所重叠。而memmove函数它可以复制同一个空间的值,可以重叠,它后面第三个参数也是以字节为单位。
实际应用:
#include
#include
int main()
{
int abb[10] = { 1,2,3,4,5,6,7,8,9,10 };
memmove(abb + 4, abb, 24);
int i = 0;
for (i = 0; i < 10; i++)
{
printf("%d ", abb[i]);
}
return 0;
}

1.13 memcmp函数


int memcmp( const void *ptr1, const void *ptr2, size_t num)
#include
#include
int main()
{
char arr1[20] = "abcdefgh";
char arr2[20] = "abcdef";
//因为该指定的字节是作用于两个参数,故只能比较相等时或者另一个大于另一个,而不能比较小的时候的大小
int num1 = memcmp(arr1, arr2, 20);
int num2 = memcmp(arr1, arr2, 2);printf("num1 = %d\n", num1);
printf("num2 = %d\n", num2);return 0;
}

1.14 memset函数

void *memset(void *ptr, int value, size_t num)
头文件名:#include
由图中表达的意思,这就是一个填充函数,也就是用第二个int型参数,再根据第三个参数所制定的字节数,从而把in型参数填充到第一个参数中。
实际应用:
#include
#include
int main()
{
char arr1[20] = "abcdefgh";
memset(arr1, '0', 8);
printf("%s\n", arr1);
return 0;
}

库函数的讲解就讲解在此,希望大家能有所收获。
2、库函数的模拟实现
2.1 模拟实现strlen函数
第一种方法:使用了临时变量。利用临时变量来计数,最后返回临时变量的值即可。
int my_strlen(char* arr)
{
int count = 0;
while (*arr++ != '\0')
{
count++;
}
return count;
}
第二种方法:不使用临时变量(递归)。使用递归也是过程最简单的。
int my_strlen(char* arr)
{
if (*arr == '\0')
return 0;
else return 1 + my_strlen(arr + 1);
}
第三种方法:使用两个指针。利用指针与指针之间的距离长度来算字符的大小。
int my_strlen(char* arr)
{
char* p = arr;
while (*p != '\0')
p++;
return p - arr;}
2.2 模拟实现strcpy
第一种写法:是利用字符串以‘\0’为结束标志的特性,来依次把值存过去。
void my_strcpy(char* arr, char* aee)
{
while (*aee != '\0')
{
*arr = *aee;
arr++;
aee++;
}
}
另一种写法:这种写法相较于传统的写法有很大不同,是直接构造char*的函数,首先利用一个指针来记录目的指针的初始位置,在利用另一个带有目的数据的指针来传入目的指针里,最后再传回用来记录目的指针的初始位置指针。
char * my_strcpy(char* arr, char* aee)
{
char* net = arr;
while (*arr++ = *aee++)
{
;
}
return net;
}
2.3模拟实现strcat函数
该方法是利用了指针与字符串的特性。
void my_strcat(char* arr1, char* arr2)
{
while (*arr1)
arr1++ ;while (*arr2 != '\0')
{
*arr1 = *arr2;
arr1++;
arr2++;
}
}
2.4 模拟实现strcmp函数
int my_strcmp(char* arr1, char* arr2)
{
while (*arr1 == *arr2)
{
if (*arr1 = '\0')
return 0;
arr1++;
arr2++;
}
if (*arr1 > *arr2)
return 1;
else return -1;
}
2.5 模拟实现strstr函数
char* my_strstr(char* str1, char* str2)
{
char* cp = str1;
char* s1 = cp;
char* s2 = str2;
while (*cp)
{
s1 = cp;
s2 = str2;
while (*s1 && *s2 && *s1 == *s2)
{
s1++;
s2++;
}
if (*s2 == '\0')
return cp;
cp++;
}}

2.6 模拟实现memcpy函数
void my_memcpy(void* arr1,const void* arr2, int se)
{
char* ret = arr1;
while (se)
{
*(char*)arr1 = *(char*)arr2;
arr1 = (char*)arr1 + 1;
arr2 = (char*)arr2 + 1;
se--;
}
return ret;
首先我们需要用一个指针来记录目标函数的起始位置。为什么要记录呢?也就是为了我们最后返回去,不然我们操作完目标函数的指针的位置不在起始位置。
关于为什么要这样写 :
arr1 = (char*)arr1 + 1;
arr2 = (char*)arr2 + 1;
而不是这样写:
arr1++;
arr2++;
这是因为当初创建my_memcpy函数时我们为了瞒住各种数据的需求,就用void型,而在void型中arr1++和arr2这样写就是错误的,系统不知道你是什么类型,它怎么知道加多少呢也就是会造成系统错误。
可能有的人会说不是在上一步已经进行了强制数据转换了吗,而我要说的是强制数据转换只是在那一个过程转换了,而在下一个过程它有又会失效,不信的话你们可以去试试,我就不作过多的解释。
2.7 模拟实现memmove函数
void *my_memmove( void* dest,const void* trst, int se)
{
void* ret = dest;
if (dest < trst)
{
while (se--)
{
*((char*)dest) = *(char*)trst;
dest = (char*)dest + 1;
trst = (char*)trst + 1;
}
}
else
{
while (se--)
{
*((char*)dest + se) = *((char*)trst + se);
}
}
return ret;
}
此函数模拟的难度应该就在于为什么要判断。这个总共分为两种情况,第一种情况是dest在trst前面时,只能从前面传入数据才能正确表达,也就是在执行函数时这样的表达:
my_memmove(arr1, arr1+2, 8);
也就是此种情况。
而第二种情况就是dest在trst的后面时,只能从后面开始传入数据才能正确表达,也就是在执行函数时这样的表达:
my_memmove(arr1 + 2, arr1, 8);
两种表达的意思在代码运行时是两种情况。
我们先来讲讲第一种情况:dest在trst的前面看能不能从后面开始传入数据:
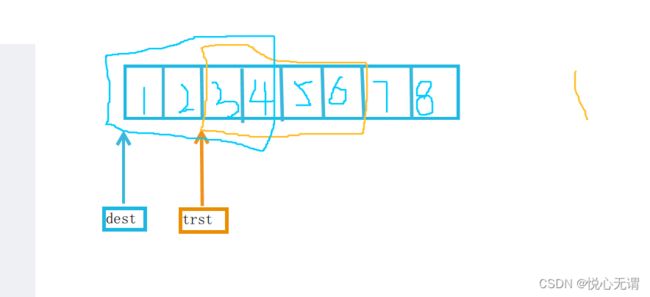
按照常规就是把trst中的数据依次放在dest中也就是6放在dest中4的位置,然后trst中的5放在dest中3的位置,相信此时大家已经看出来了由于dest和trst都是指针,它们中数据的改变会影响目标函数,此时由于之前的移动原本trst中还没有传过去的3和4已经被5和6给代替了,所以如果继续传的话大概率是5和6一直交替。
而相反如果从前面开始传入就不会覆盖数据,大家可以试一试。
第二种情况也就是这样的一个过程,大家可以仔细想一想其中的逻辑关系或者在纸上画一下感受一下。
感谢语
字符和字符串的库函数模拟与实现,在这里也就讲完了,由于我自己的知识水平,可能在某些方面讲的不是那么通俗易懂,有些知识讲的不是很完整,大家多多包容包容,再次感谢大家的观看,谢谢!

我们一起加油 GO GO GO !