@Autowired与@Resource原理知识点详解
文章目录
- 前言
- springIOC
- 依赖注入的三种方式
-
- 属性注入(字段注入)
- 构造方法注入
- setter注入
- 用哪个?
- @Autowired
-
- 实现原理
- @Resource
-
- 实现原理
- 结论
- @Autowired与@Resource的不同
-
- 来源不同
- 参数不同
- 使用不同
- 装配顺序
前言
现在spring可以说是一统天下了,而spring有两个核心部分:IOC和AOP,AOP之前可以看一下之前的文章:Spring AOP原理使用详解
springIOC
AOP的不多做赘述了,说下IOC:Spring IOC 解决的是对象管理和对象依赖的问题,IOC容器可以理解为一个对象工厂,我们都把该对象交给工厂,工厂管理这些对象的创建以及依赖关系,而IOC有两个概念:控制反转及依赖注入。控制反转指的就是:把原有自己掌控的事交给别人去处理,更多的是一种思想或者可以理解为设计模式。
而依赖注入其实是控制反转的实现方式,通过依赖注入对象无需自行创建或者管理它的依赖关系,依赖关系将被自动注入到需要它们的对象当中去。
依赖注入的三种方式
其实还有一种基于XML的注入方式,但是现在这种方式过于繁琐且依赖冗余复杂的配置文件,再次不做讨论,仅说下常用的三种注入方式:
属性注入(字段注入)
该方式底层其实是基于Field注入的方式,也可以成为字段注入,因为注入方式实现比较简介,没有多于代码,所以这个在实际开发过程中比较常用:

该方式可以使用@Autowired、@Resource及@Inject来实现。后面会着重讲解这一部分。
构造方法注入
这种方式其实是spring官方比较推荐的方式,因为构造方法注入的时候会比较靠前,是在bean的实例化阶段就进行的:

但是有一点需要注意一下:如果只有一个构造方法的话可以不用加上@Autowired,但是如果有无参构造方法或者其他多个构造方法的话,就需要在指定的构造方法上面添加@Autowired注解了。
setter注入
我都不想列出来,但是又怕别人说我不知道这个(哈哈哈哈哈哈)。。。因为这种方式我觉得用的会越来越少的,因为这种代码太臃肿了,且好丑。。。

用哪个?
如果是开发的话,我建议直接属性(字段)注入完事儿,一般的业务场景基本不会有纰漏。但是如果想在bean实例化阶段进行一些处理操作或者是不在同一个IOC容器里面的话,我建议构造函数注入。
spring4以后推荐的是通过构造函数注入:
- 依赖不可变:这个好理解,通过构造方法注入依赖,在对象创建的时候就要注入依赖,一旦对象创建成功,以后就只能使用注入的依赖而无法修改了,这就是依赖不可变(通过 set 方法注入将来还能通过 set 方法修改)。
- 依赖不为空:通过构造方法注入的时候,会自动检查注入的对象是否为空,如果为空,则注入失败;如果不为空,才会注入成功。
- 完全初始化:由于获取到了依赖对象(这个依赖对象是初始化之后的),并且调用了要初始化组件的构造方法,因此最终拿到的就是完全初始化的对象了。
idea里面为什么不推荐使用属性(字段)注入:
- 对于 IOC 容器以外的环境,除了使用反射来提供它需要的依赖之外,无法复用该实现类。因为该类没有提供该属性的 set 方法或者相应的构造方法来完成该属性的初始化。换言之,要是使用属性注入,那么你这个类就只能在 IOC 容器中使用,要是想自己 new 一下这个类的对象,那么相关的依赖无法完成注入。
- 属性注入时机较晚。在一些是实列化阶段的一些操作,无法使用注入对象。
@Autowired

@Autowired注解,可以对成员变量、方法和构造函数进行标注,来完成自动装配的工作,@Autowired标注可以放在成员变量上,也可以放在成员变量的set方法上,也可以放在任意方法上表示,自动执行当前方法,如果方法有参数,会在IOC容器中自动寻找同类型参数为其传值。在上面已经讲解过了。
这里必须明确:@Autowired是根据类型进行自动装配的,如果需要按名称进行装配,则需要配合@Qualifier使用。
实现原理
源码跟踪下bean的实例化及初始化,以下源码定位流程就先不截图了,等到关键重要地方再截图:
-
SpringApplication#run()方法的this.refreshContext。
-
AbstractApplicationContext#refresh方法的this.finishBeanFactoryInitialization(beanFactory);该方法会初始化所有非延迟加载的单例bean,包括我们在应用中声明的各种业务Bean,Bean的实例化和初始化过程逻辑都在这个函数中。
-
上述finishBeanFactoryInitialization方法中有this.getBean(weaverAwareName)方法。
-
AbstractBeanFactory#doGetBean()方法中有createBean()方法。
-
进入AbstractAutowireCapableBeanFactory#createBean()方法,该方法内有doCreateBean()方法:

doCreateBean()方法是用来构建bean的,bean的实例化及初始化逻辑都是在doCreateBean()方法里面。该方法代码截图一下吧,重点关注两个方法:

-
先看下applyMergedBeanDefinitionPostProcessors方法:

可以看到该方法里面调用了所有的MergedBeanDefinitionPostProcessor的postProcessMergedBeanDefinition方法,其中有一个我们一直在找的实现类:AutowiredAnnotationBeanPostProcessor,这个就是用来处理依赖注入的后置处理器。MergedBeanDefinitionPostProcessor的postProcessMergedBeanDefinition方法如下:

AutowiredAnnotationBeanPostProcessor会对bean进行注解扫描,如果扫描到了@Autowired和@Value注解,就会把对应的方法或者属性封装起来,最终封装成InjectionMetadata对象。 -
我们再看第二个重要方法populateBean(),这是个非常重要的方法:填充Bean实例属性完成依赖对象的注入,此时Bean中需要依赖注入的成员已经在第六步的applyMergedBeanDefinitionPostProcessors中被对应的后置处理器(AutowiredAnnotationBeanPostProcessor)进行了存储。
这个方法内部进行部分截图:

这段代码肯定不会return,因为postProcessAfterInstantiation是为true的?重点定位到postProcessPropertyValues方法:

-
可以看到有两个实现类:一个就是AutowiredAnnotationBeanPostProcessor而另一个是CommonAnnotationBeanPostProcessor。@Resource是通过CommonAnnotationBeanPostProcessor的postProcessPropertyValues实现的,我们先以@Autowired为例说明下,进入到AutowiredAnnotationBeanPostProcessor的postProcessPropertyValues方法内:


查看findAutowiringMetadata()方法:

查看下buildAutowiringMetadata()部分方法:

当调用findAutowiringMetadata()方法时,会根据autowiredAnnotationTypes这个全局变量中的元素类型来进行注解的解析,而这个全局变量在AutowiredAnnotationBeanPostProcessor的构造方法中进行了初始化:

构造方法初始化的时候会向autowiredAnnotationTypes全局集合变量里面加入@Autowired、@Inject、@Value
以上说明了findAutowiringMetadata()方法只解析出bean中带有@Autowired注解、@Inject和@Value注解的属性和方法。然后调用metadata.inject()方法,进行属性填充,继续跟踪:

以上代码中:checkedElements用于检查元素防止重复注入,bean中@Autowired 注入点会被提前解析成元信息并保存到InjectionMetadata中(对于@Resource,@LookUp等注解被解析后,也会解析成对应的InjectedElement的子类:ResourceElement、LookUpElement,但是这两个注解是在CommonAnnotationBeanPostProcessor后置处理器进行处理的),遍历InjectedElement集合继续执行注入逻辑element.inject():

-
该方法对应两个实现类分别为:AutowiredFieldElement及AutowiredMethodElement,字面意思对应分别为字段注入及方法注入实现,两者实现逻辑基本相同,我们以AutowiredFieldElement为例:

ReflectionUtils.makeAccessible(field);利用Java的反射,为属性进行赋值,我们重点看下resolveFieldValue():

-
重点看下resolveDependency()方法,该方法主要调用了doResolveDependency()方法,接下来重点分析一下doResolveDependency()这个方法,源码如下:
@Nullable
public Object doResolveDependency(DependencyDescriptor descriptor, @Nullable String beanName,
@Nullable Set autowiredBeanNames, @Nullable TypeConverter typeConverter) throws BeansException {
InjectionPoint previousInjectionPoint = ConstructorResolver.setCurrentInjectionPoint(descriptor);
try {
Object shortcut = descriptor.resolveShortcut(this);
if (shortcut != null) {
return shortcut;
}
Class type = descriptor.getDependencyType();
Object value = getAutowireCandidateResolver().getSuggestedValue(descriptor);
if (value != null) {
if (value instanceof String) {
String strVal = resolveEmbeddedValue((String) value);
BeanDefinition bd = (beanName != null && containsBean(beanName) ?
getMergedBeanDefinition(beanName) : null);
value = evaluateBeanDefinitionString(strVal, bd);
}
TypeConverter converter = (typeConverter != null ? typeConverter : getTypeConverter());
try {
return converter.convertIfNecessary(value, type, descriptor.getTypeDescriptor());
}
catch (UnsupportedOperationException ex) {
// A custom TypeConverter which does not support TypeDescriptor resolution...
return (descriptor.getField() != null ?
converter.convertIfNecessary(value, type, descriptor.getField()) :
converter.convertIfNecessary(value, type, descriptor.getMethodParameter()));
}
}
Object multipleBeans = resolveMultipleBeans(descriptor, beanName, autowiredBeanNames, typeConverter);
if (multipleBeans != null) {
return multipleBeans;
}
Map matchingBeans = findAutowireCandidates(beanName, type, descriptor);
if (matchingBeans.isEmpty()) {
if (isRequired(descriptor)) {
raiseNoMatchingBeanFound(type, descriptor.getResolvableType(), descriptor);
}
return null;
}
String autowiredBeanName;
Object instanceCandidate;
if (matchingBeans.size() > 1) {
autowiredBeanName = determineAutowireCandidate(matchingBeans, descriptor);
if (autowiredBeanName == null) {
if (isRequired(descriptor) || !indicatesMultipleBeans(type)) {
return descriptor.resolveNotUnique(descriptor.getResolvableType(), matchingBeans);
}
else {
// In case of an optional Collection/Map, silently ignore a non-unique case:
// possibly it was meant to be an empty collection of multiple regular beans
// (before 4.3 in particular when we didn't even look for collection beans).
return null;
}
}
instanceCandidate = matchingBeans.get(autowiredBeanName);
}
else {
// We have exactly one match.
Map.Entry entry = matchingBeans.entrySet().iterator().next();
autowiredBeanName = entry.getKey();
instanceCandidate = entry.getValue();
}
if (autowiredBeanNames != null) {
autowiredBeanNames.add(autowiredBeanName);
}
if (instanceCandidate instanceof Class) {
instanceCandidate = descriptor.resolveCandidate(autowiredBeanName, type, this);
}
Object result = instanceCandidate;
if (result instanceof NullBean) {
if (isRequired(descriptor)) {
raiseNoMatchingBeanFound(type, descriptor.getResolvableType(), descriptor);
}
result = null;
}
if (!ClassUtils.isAssignableValue(type, result)) {
throw new BeanNotOfRequiredTypeException(autowiredBeanName, type, instanceCandidate.getClass());
}
return result;
}
finally {
ConstructorResolver.setCurrentInjectionPoint(previousInjectionPoint);
}
}
其中有个resolveMultipleBeans()方法,该方法用于处理注入时属性为数组集合等情况,比如我们在bean中使用注入如下:

可以看下该方法的关键代码:

该方法内调用了findAutowireCandidates()方法主要用于根据类型查找依赖,大致可以分为三步:先查找内部依赖,再根据类型查找,最后没有可注入的依赖则进行补偿。其中@Qualifier注解就是在这个函数中处理的。实现从容器中找到所有对应类型的bean,最终会调用getBean()方法,这样当对应类型的对象还没被创建时,就会去创建。
我们再返回doResolveDependency()方法,查看下面的逻辑:

可以看到又一次调用了findAutowireCandidates()方法,会查找对应类型的bean,如果没有查找到并且该属性是必须要要注入的,则会抛异常。
继续往下走,可以看到:

如果查找对应类型bean>1,则会执行determineAutowireCandidate()方法,从字面意思来看的话是决定选择注入属性。可以看到执行完该方法后,如果autowireedBeanName为null也就是说无法决定使用哪一个,则抛异常。我们重点看下determineAutowireCandidate()方法的逻辑:

这个逻辑就比较明确了,相同类型的选取规则就是:首先选取@Primary注解的对象;其次根据@Priority来选取优先级高的对象;最后根据属性名称与spring的beanName来判断。如果按照这个还是没有选择出来的话,就会抛出异常(throw new NoUniqueBeanDefinitionException))。
再次返回doResolveDependency()方法,在执行完determineAutowireCandidate()方法后,会执行如下逻辑:


可以看到通过beaName及类型,调用getBean()方法向容器获取依赖bean对象,若该对象还没有构建,则会构建该对象,直到依赖的所有对象都已构建好,然后进行属性注入。后面的就是一直校验及判断逻辑了,在此不做赘述。
11. 至此AutowiredAnnotationBeanPostProcessor通过postProcessPropertyValues()方法完成了自动装配。以上就是@Autowired注解的实现原理。
@Resource
实现原理
@Resource的实现原理与@Autowired原理基本类似,不做赘述,只说明一下不同点:
1.@Resource注解的实现是通过后置处理器CommonAnnotationBeanPostProcessor类的postProcessPropertyValues()方法实现的。
2. CommonAnnotationBeanPostProcessor的findResourceMetadata()方法只解析出bean中带有@Resource注解、@WebServiceRef和@EjB注解的属性和方法


3. 查找顺序,看源码:

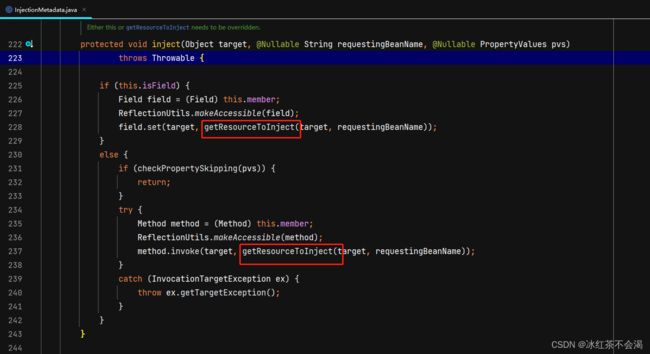
首先会判断是否是属性(字段)注入,我们以属性输入为例,重点看下getResourceToInject(target, requestingBeanName):
protected Object getResourceToInject(Object target, @Nullable String requestingBeanName) {
return this.lazyLookup ? CommonAnnotationBeanPostProcessor.this.buildLazyResourceProxy(this, requestingBeanName) : CommonAnnotationBeanPostProcessor.this.getResource(this, requestingBeanName);
}
(这个代码为啥不换行,截图都不好截取。)
看代码描述如果是@Lazy则会返回一个代理对象,如果不是的话就执行CommonAnnotationBeanPostProcessor.this.getResource(this, requestingBeanName)逻辑,我们看下该逻辑代码:

继续查看this.autowireResource(this.resourceFactory, element, requestingBeanName):

如图示:第二与第三的执行逻辑是一样的,所以关键就是第一个的判断条件,如果this.fallbackToDefaultTypeMatch && element.isDefaultName && !factory.containsBean(name)为true,那么获取属性的逻辑与@Autowired的逻辑一样。如果为false,是根据resource = factory.getBean(name, element.lookupType)获取属性,此时是根据ByName注入属性。
如果 !factory.containsBean(name)为true的话,说明容器内按照名称查找该name的bean是没有的,所以会执行beanFactory.resolveDependency()方法,执行@Autowired相同逻辑。
结论
根据上面源码分析,严谨来说,@Resource并不是传统意义所说的先按照name再按照type注入属性的,有三个if分支,第一个if是先判断有没有name相关bean再执行ByType—@Primary—@Priority—byName。
@Autowired与@Resource的不同
简单描述下,能说上来就行:
来源不同
@Autowired是Spring定义的注解,而@Resource是JSR-250定义的注解。
参数不同
@Autowired只包含一个参数:required,表示是否开启自动准入,默认是true。而@Resource包含七个参数,其中最重要的两个参数是:name 和 type。@Autowired如果要使用byName,需要使用@Qualifier一起配合。而@Resource如果指定了name,则用byName自动装配,如果指定了type,则用byType自动装配。
使用不同
@Autowired能够用在:构造器、方法、参数、成员变量和注解上,而@Resource能用在:类、成员变量和方法上。
装配顺序
@Autowired默认按byType自动装配,而@Resource默认byName自动装配。