MySQL数据库操作
DDL 创建 删除 修改数据库,数据表(create drop alter)
DML 管理数据表的数据(insert updata delete)
DQL 查询数据表的数据(select)
DCL 控制数据库组件的存取(事务commit、rollback)
MySQL中注释:1、单行注释“#”,2、单行注释“--”,3、多行注释“/**/”
WHERE 限制条件
= 等于
<> 不等于。注释:在 SQL 的一些版本中,该操作符可被写成 !=
> 大于
< 小于
>= 大于等于
<= 小于等于
BETWEEN 在某个范围内
LIKE 搜索某种模式
OR/IN 指定针对某个列的多个可能值
AND/&& 同时满足and前后的两个条件
MySQL中数据类型
| 整数类型 | 大小 | 描述 |
| tinyint | 1byte | 非常小整数 |
| smallint | 2byte | 小整数 |
| mediumint | 3byte | 中等大小整数 |
| int | 4byte | 标准的整数 |
| bigint | 8byte | 大整数 |
| 小数类型 | 大小 | 描述 |
| float | 4byte | 单精度浮点型 |
| double | 8byte | 双精度浮点型 |
| 日期和时间类型 | 大小 | 描述 |
| year | 1byte | 年份 |
| time | 3byte | 时间 |
| date | 3byte | 日期 |
| datetime | 8byte | 日期+时间 |
| timestamp | 4byte | 时间戳 |
| 字符串类型 | 大小 | 描述 |
| char(M) | M个字符 | 固定长度的字符串 |
| varchar(M) | M个字符 | 可变长度的字符串 |
| tinytext | 2^8-1 byte | 非常小的字符串 |
| text | 2^16-1 byte | 小型字符串 |
| 二进制类型 | 大小 | 描述 |
| bit(M) | M位的二进制数 | 小的二进制数 |
| binary(M) | M byte | 普通二进制数项 |
一、管理数据库
1、DDL 创建数据库
create database 库名;
2、DDL 删除数据库
DROP DATABASE 库名;
3、查看所有数据库
show databases;
4、选择数据库
#在创建表之前一定要先选择数据库
use 数据库名称;
二、管理数据表
1、DDL 创建数据表
USE s_students;
CREATE TABLE tablename(
#列信息
字段名词 数据类型 是否主键/是否为空/默认值 自增 ...
);
CREATE TABLE user(
id INT PRIMARY KEY auto_increment,
name VARCHAR(100)
);
2、DDL 修改数据表
(1)添加表列ADD:ALTER TABLE 表名 ADD 列名 类型;
USE s_students;
ALTER TABLE student ADD s_tel INT;
(2)修改列类型MODIFY:ALTER TABLE 表名 MODIFY 列名;
USE s_students;
ALTER TABLE student MODIFY age int NOT NULL; --将age修改为整型不能为空
ALTER TABLE new_student MODIFY name VARCHAR(100); --将name修改为100个字符大小
(3)修改列名 CHANGE:ALTER TABLE 表名 CHANGE 旧列名 新列名 类型;
USE s_students;
ALTER TABLE student CHANGE s_tel tel DOUBLE;
(4)删除列 DROP:ALTER TABLE 表名 DROP 列名;
USE s_students;
ALTER TABLE student DROP tel;
(5)修改表名:RENAME TABLE 表名 TO 新表名;
USE s_students;
RENAME TABLE student TO new_student;
(6)修改字符集character set:ALTER TABLE 表名 character set 字符集;
注意:列如果为主键,则不能修改,如果非要修改,可以通过以下两种方式
1、删除主键,再修改列并定义新的主键
-- 删除原有主键
ALTER TABLE 表名 DROP PRIMARY KEY;
-- 定义新的主键
ALTER TABLE 表名 ADD PRIMARY KEY (列名);
2、先将该列修改为非主键,再修改列并设置列为主键
3、DDL 删除数据表
(1)直接删除:DROP TABLE 表名;
(2)判断表是否存在,如果存在则删除表:DROP TABLE IF EXISTS 表名;
4、查看所有数据表
USE s_students;
SHOW TABLES;
5、查看表结构(字段名词 数据类型 是否主键等)
USE s_students;
DESC stu_info;
三、管理数据表的数据(DML增删改)
1、增insert
#插入的是整行数据而非某一列数据
INSERT INTO table_name (column1,column2,column3,...) VALUES (value1,value2,value3,...);
INSERT INTO new_student(id, `name`, age) VALUES (1, '张三', 55);
INSERT INTO new_student(id, `name`, age) VALUES (2, '李四', 666),(21,'多条数据',777);
INSERT INTO new_student VALUES (3,'测试省略添加列表',22); --省略字段列表相当于添加全部
INSERT INTO new_student SET sex = '男'; --插入sex是男的一行数据其他字段设置为空
2、删delete
(1)删除表中所有数据
DELETE FROM new_student;
(2)删除表中某些数据
DELETE FROM table_name WHERE some_column=some_value;
DELETE FROM new_student WHERE id=2;
3、改update
#更新某一行某一列数据(带where)/某一整列数据(不带where)
UPDATE table_name SET column1=value1,... WHERE some_column=some_value;
UPDATE new_student SET name='mysql',age=21 WHERE id=2;
UPDATE new_student SET sex = '女' where id !=3;
UPDATE new_student SET sex = '男';
四、查询数据表的数据(DQL)
1、查select
(1)无条件查询
SELECT * FROM 表名;
(2)有条件查询
1、查询指定字段的内容
select 字段1,字段2,... from 表名;
SELECT id,name FROM new_student;
2、单个条件查询(or/in)
SELECT * FROM new_student WHERE id=2;
SELECT * FROM new_student WHERE age=22 or age=21;
SELECT * FROM new_student WHERE id>5;
SELECT id,name FROM new_student WHERE id IN (2,3);
3、多个条件查询(and)
SELECT * FROM new_student WHERE age=22 AND name='测试省略添加列表';
4、查询...到...之间的内容(between...and.../ && / and)
SELECT * FROM new_student WHERE age BETWEEN 21 AND 22; --包含21和22
SELECT * FROM new_student WHERE age > 23 AND age < 26;
SELECT * FROM new_student WHERE age > 23 && age < 26;
(3)查询不为NULL的值(is not null)
SELECT * FROM new_student WHERE age IS NOT NULL;
(4)模糊查询(like)
_:单个任意字符
%:多个任意字符
#查询表中name字段第一个字为“同”的整行记录
SELECT * FROM new_student WHERE name LIKE '同%';
#查询表中name字段以“表”结尾的整行记录
SELECT * FROM new_student WHERE name LIKE '%表';
#查询表中name字段第三个字为“d”,后面是任意字符的整行记录(通常_要搭配%一起使用)
SELECT * FROM new_student WHERE name LIKE '__d%';
(5)去重查询(distinct):取出该列去重后的列数据
#SELECT DISTINCT 列名称 FROM 表名称;
SELECT DISTINCT age FROM new_student;
(6)排序查询(order by)
#以升序排序查询
SELECT * FROM new_student ORDER BY age;
#以降序排序查询
SELECT * FROM new_student ORDER BY age DESC;
(7)聚合函数:取出列聚合后对应的值而非整行记录
1.count:计算个数(字段名称,则统计不为null的个数;数字,则统计包含null的个数)
2.max:计算最大值
3.min:计算最小值
4.sum:计算和
5.avg:计算平均数
| 效率排行 | count的方式 | 原因 |
| 1 | count(*) | 对key_len最短的二级索引进行遍历,如果没有,那么就根据聚簇索引进行遍历(不读取聚簇索引的值) |
| 2 | count(1) | 对聚簇索引进行遍历(不读取聚簇索引的值) |
| 3 | count(索引字段) | 对聚簇索引进行遍历(读取索引的值) |
| 4 | count(非索引字段) | 全表扫描(比如普通字段name) |
#表中id值进行求和
SELECT SUM(id) as 'id总和' FROM new_student;
#取表中id最小的id值
SELECT MIN(id) FROM new_student;
(8)MySQL运算符
1、执行运算符:加减乘除
SELECT age+6 FROM new_student; #返回age+6的值
2、比较运算符:大于、等于、小于、不等于,返回1表示true,返回0表示false
SELECT age>23 FROM new_student;
3、逻辑运算符:与 或 非,返回1表示true,返回0表示false
SELECT age>23 && id<10 FROM new_student;
(9)分组查询(group by):取出select的内容
#按照性别分组,分别查询男女同学的最小年龄
SELECT sex , MIN(age) FROM new_student GROUP BY sex;
#按照性别分组,分别查询男女同学平均年龄和男女同学人数
SELECT sex , AVG(age), COUNT(id) FROM new_student GROUP BY sex;
(10)HAVING 对GROUP BY产生的组施加条件
1. HAVING 子句必须紧随 GROUP BY 子句,并出现在 ORDER BY 子句(如果有的话)之前,语法如下:
SELECT column1,column2
FROM table1,table2
WHERE [conditions]
GROUP BY column1,column2
HAVING [conditions]
ORDER BY column1,column2
2. HAVING与WHERE的区别:
- WHERE发生在HAVING之前,在执行HAVING之前,会先将不符合WHERE条件的数据过滤掉
- WHERE过滤的是行,而HAVING过滤的是分组聚集后的数据
(11)分页查询LIMIT(第一条记录的索引是0)
#查表中的前4条记录
SELECT * FROM new_student LIMIT 4;
#查询表中第2~4条记录(即第二行开始查,总共查3条)
SELECT * FROM new_student LIMIT 1,3;
(12)主键
#表中的一个字段,该字段的值是每行数据的唯一标识,每张表都要有一个主键,也只能有一个主键,一般定义为int类型,因为int类型存储空间小,同时可以设置为自增,避免冲突,主键值必须唯一
CREATE TABLE class(
id INT PRIMARY KEY aut_increment,
name VARCHAR(100)
);
--删除主键ALTER TABLE 表名 DROP PRIMARY KEY;
(13)外键
#表中的某个字段为外键,与另一张表的主键进行关联,从而将两张表的数据建立级联关系,外键的取值必须是主键主键中已经存储的值,如果是主键中没有的值,则外键无法存储
CREATE TABLE student(
id INT PRIMARY KEY auto_increment,
name VARCHAR(50),
cid INT,
#外键的取值范围必须是主键中存储的值
FOREIGN KEY(cid) REFERENCES class(id)
);
--删除外键(解除外键约束)
alter table 数据表 drop foreign key 外键名称; #外键名称不是表的列名称
(14)数据表关系
1、一对多(如一个班级对应多个学生)
#主表
CREATE TABLE class(
id INT PRIMARY KEY auto_increment,
name VARCHAR(100)
);
#从表
CREATE TABLE student(
id INT PRIMARY KEY auto_increment,
name VARCHAR(50),
cid INT,
FOREIGN KEY(cid) REFERENCES class(id)
);
2、多对多(如user选课表-->user表和课程表)
#两张主表
CREATE TABLE user(
id INT PRIMARY KEY auto_increment,
name VARCHAR(20)
);
CREATE TABLE course(
id INT PRIMARY KEY auto_increment,
name VARCHAR(20)
);
#一张从表
CREATE TABLE user_course(
id INT PRIMARY KEY auto_increment,
uid INT,
cid INT,
FOREIGN KEY(uid) REFERENCES user(id),
FOREIGN KEY(cid) REFERENCES course(id)
);
2、内连接查询
#把两张表用inner join连接起来,然后追加条件
SELECT * FROM student INNER JOIN class WHERE student.`name` = '张三' AND student.cid = class.id;
-- SELECT * FROM student;
-- SELECT * FROM class;
SELECT * FROM student INNER JOIN class; #这样查询取的是上面两条笛卡尔积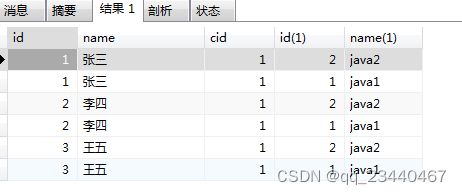
#更多用内连接做通用查询,显示内连接和隐式内连接区别是inner join可以用逗号表示
-
--语法1 (隐式内连接) -
select 字段1,字段2... -
from 表1,表2... -
where 过滤条件; -
--语法2 (显式内连接) -
select 字段1,字段2... -
from 表1 inner join 表2 ... -
where 过滤条件;
3、外连接查询
(1)左连接:左表所有数据和右表满足条件的数据
#student的别名s class的别名c 使用LEFT JOIN...ON...将两张表进行级联
SELECT * FROM student s LEFT JOIN class c ON s.cid = c.id;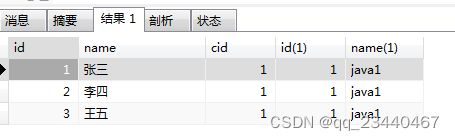
#左连接:左表所有数据和右表满足条件的数据
SELECT * FROM student s LEFT JOIN class c ON s.cid = c.id AND s.id = 1; 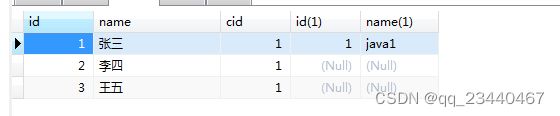
(2)右连接:右表所有数据和左表满足条件的数据
SELECT * FROM student s RIGHT JOIN class c ON s.cid = c.id AND s.id = 1;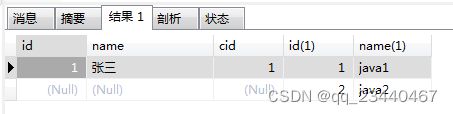
#写连接查询,先把表的关系关联起来,再去加业务逻辑
SELECT * FROM user u, course c, user_course uc WHERE u.id = uc.uid and c.id = uc.cid and u.id = 1; #多对多关系级联查询
4、子查询(嵌套查询)
举例:使用数据表关系的一对多
#查询张三信息,包括个人信息和所在班级信息
SELECT cid FROM student WHERE name = '张三'; #得到外键值
SELECT * FROM class WHERE id = (SELECT cid FROM student WHERE name = '张三'); #外键值作为参数传入查询语句
#通过从表查询的外键值作为入参来查询主表得到个人信息和班级信息,因为外键的取值必须是主键主键中已经存储的值
#第一条sql的结果作为第二条sql的条件做一个查询
5、索引
索引类似书的目录,目的是提高查询效率
1、索引设计原则
1、出现在where语句中的列,而不是select后面的列
2、索引的值尽量唯一
3、不要添加过多的索引
2、添加索引
alter table 数据表 add index 索引名(需要添加索引的数据表列名称);
或者
create index 索引名 数据表 (需要添加索引的数据表列名称);
3、删除索引
alter table 数据表 drop index 索引名; #没有外键约束才能删索引
或者
drop index 索引名 on 数据表;
五、DCL 数据控制语言
(1)管理用户
①添加用户
create user '用户名'@'主机名' identified by '密码';
②删除用户
drop user '用户名'@'主机名';
(2)权限管理
①查询权限
show grants for '用户名'@'主机名';
②授予权限
--语法
grant 权限列表 on 数据库名.表名 to '用户名'@'主机名';
--授予faker用户所有权限,在任意数据库任意表上
grant all on *.* to 'faker'@'localhost';
③撤销权限
--语法
grant 权限列表 on 数据库名.表名 to '用户名'@'主机名';
--授予faker用户所有权限,在任意数据库任意表上
grant all on *.* to 'faker'@'localhost';
参考文章:http://c.biancheng.net/view/2574.html