puppeteer实现浏览器自动化和爬虫
puppeteer实现浏览器自动化和爬虫
puppeteer 是谷歌官方出品的一个通过 DevTools 协议控制 headless Chrome 的 Node 库,它提供了一个高级 API 来通过 DevTools 协议控制 Chromium 或 Chrome,执行常见的操作,就像在真实的浏览器中一样,可以用来实现浏览器自动化测试或爬虫
puppeteer 是浏览器自动化的产品。安装后,它会下载一个版本的 Chromium,然后使用puppeteer-core 驱动工作
- puppeteer-core 是一个库,来帮助驱动任何支持 DevTools 协议的东西。puppeteer-core 在安装时不会下载 Chromium
在浏览器中手动执行的绝大多数操作都可以使用 puppeteer 来完成:
- 页面截图,生成页面 PDF
- 抓取 SPA(单页应用)并生成预渲染内容(即“SSR”服务器端渲染)
- 自动提交表单,进行 UI 测试,键盘输入等
- 创建一个时时更新的自动化测试环境, 使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中执行测试
- 捕获网站的 timeline trace,用来帮助分析性能问题
- 测试浏览器扩展
安装
(Nodejs 6.4以上版本环境下)安装 puppeteer 时,它会下载最新版本的 Chromium,以保证可以使用 API
-
使用 npm 安装
npm install puppeteer
-
使用 cnpm 安装
cnpm install puppeteer
注:使用 async、await,Nodejs 的版本不能低于 v7.6.0
使用
puppeteer 默认以 headless 模式(无头模式,不显示浏览器界面)运行,但是可以通过修改配置文件运行 “有头” 模式(显示浏览器界面)
新建 puppeteer.js:
//引入puppeteer
const puppeteer = require("puppeteer");
//使用async/await处理异步
(async () => {
//创建一个Browser(浏览器)实例
const browser = await puppeteer.launch({
//设置有头模式(默认为true,无头模式)
headless: false
});
//在浏览器中创建一个新的页面
const page = await browser.newPage();
//打开指定页面
await page.goto("https://blog.csdn.net/weixin_45426836?spm=1011.2124.3001.5343");
//......(执行的操作)
//关闭浏览器实例
await browser.close();
})();
设置页面尺寸(默认为 800px x 600px):
- 通过 Page.setViewport() 设置
const puppeteer = require("puppeteer"); (async () => { const browser = await puppeteer.launch(); const page = await browser.newPage(); //设置页面的尺寸 await page.setViewport({ width: 1400, height: 800, }); await page.goto("https://blog.csdn.net/weixin_45426836?spm=1011.2124.3001.5343"); await browser.close(); })(); - 通过 Browser 对象参数的 defaultViewport 设置
自适应尺寸:将 defaultViewport 设为 null,启动之后还是半屏显示,点击浏览器最大化按后,页面根据分辨率自适应大小(使用该设置进行页面截图仍是半屏显示的截图)const puppeteer = require("puppeteer"); (async () => { const browser = await puppeteer.launch({ //设置页面的尺寸 defaultViewport: { width: 1400, height: 800 } }); const page = await browser.newPage(); await page.goto("https://blog.csdn.net/weixin_45426836?spm=1011.2124.3001.5343"); await browser.close(); })();
常用 API:
Browser:当 puppeteer 连接到一个 Chromium 实例的时候会通过 puppeteer.launch 或 puppeteer.connect 创建一个 Browser 对象:
- browser.newPage():创建一个新页面,返回一个新的 Page 对象
- browser.close():关闭 Chromium 及其所有被打开的页面
- browser.pages():返回包含 Chromium 中所有页面的数组
- browser.userAgent():返回 Chromium 浏览器的 userAgent
Page:提供操作一个 tab 页或者 extension background page(扩展背景页) 的方法。一个 Browser 实例可以有多个 Page 实例:
- page.goto(url[, options]):打开指定 url 的页面,返回请求的响应
- page.close([options]):关闭页面
- page.goBack([options]):导航到页面历史的前一个页面,返回请求的响应
- page.goForward([options]):导航到页面历史的后一个页面,返回请求的响应
- page.reload([options]):重新加载页面,返回请求的响应
- page.content():返回页面的完整 html 代码,包括 doctype
- page.title():返回页面的标题
- page.url():返回页面的 url
- page.browser():返回当前 page 实例所属的 browser 实例
- page.cookies([…urls]):返回指定任何 url 下的 cookie,不指定返回当前页面域名的 cookie
- page.setCookie(…cookies):设置页面的 cookie
- page.deleteCookie(…cookies):删除页面的 cookie
- page.emulate(options):根据指定的参数和 user agent 生成模拟器(例如 iPhone, Mac, Android 等,参数使用:puppeteer.devices[“iPhone 6”])
- page.emulateMedia(mediaType):改变页面的 css 媒体类型(支持的值为 ‘screen’、‘print’ 和 null,null 为禁用媒体模拟)
- page.setUserAgent(userAgent):设置页面的 UserAgent 信息
- page.setViewport(viewport):设置页面的 viewport 信息(默认尺寸为 800px x 600px)
- page.viewport():返回页面的 viewport 信息
- page.$(selector):此方法在页面内执行 document.querySelector(如果没有元素匹配指定选择器,返回 null)
- page.$$(selector):此方法在页面内执行 document.querySelectorAll(如果没有元素匹配指定选择器,返回 [ ])
- page.$eval(selector, pageFunction[, …args]):此方法在页面内执行 document.querySelector,然后把匹配到的元素作为第一个参数传给 pageFunction 函数。可以用于获取元素,然后再通过函数获取元素的属性
- page.click(selector[, options]):点击匹配到的元素
- page.type(selector, text[, options]):向匹配的元素输入指定的内容(如果有多个匹配的元素,输入到第一个匹配的元素)
- page.focus(selector):使匹配到的元素获得焦点
- page.hover(selector):使匹配到的元素滚动到视野中,将鼠标悬停在元素的中心
- page.evaluate(pageFunction[, …args]):在页面执行自定义的 js 函数
- page.waitFor(selectorOrFunctionOrTimeout[, options[, …args]]):等待指定参数完成(指定匹配的元素出现在页面中,指定时间之后…)
- page.waitForSelector(selector[, options]):等待指定匹配的元素出现在页面中
- page.addScriptTag(options):注入一个指定 src(url) 或者代码(content)的 script 标签到当前页面
- page.addStyleTag(options):添加一个指定 link(url) 或者代码(content)的 style 标签到当前页面
- page.screenshot([options]):对当前页面截图,返回截图的buffer
- page.pdf([options]):生成当前页面的 pdf 格式的文件,返回 pdf buffer
Keyboard:提供一个接口来管理虚拟键盘
- keyboard.down(key[, options]):按下键盘上指定键,触发 keydown 事件(按下之后没有被释放,一般会持续的触发该按键,需要通过 keyboard.up() 释放)
- keyboard.up(key):释放指定键,触发 keyup 事件
- keyboard.press(key[, options]):按下键盘上指定键并释放(keyboard.down() 和 keyboard.up() 的快捷操作)
- keyboard.type(text, options):向焦点元素中输入指定的文本
Mouse :提供一个接口来管理虚拟鼠标
- mouse.move(x, y,[options]):移动鼠标指针到指定的位置,触发 mousemove 事件
- mouse.down([options]):按下鼠标按键(默认按下左键),触发 mousedown 事件
- mouse.up([options]):松开鼠标按键,触发 mouseup 事件
- mouse.click(x, y,[options]):移动鼠标指针到指定的位置,然后按下鼠标按键(默认按下左键)(mouse.move() 和 mouse.down() 或 mouse.up() 的快捷操作)
使用 node 命令执行:
node puppeteer.js
puppeteer 页面截图:
//引入puppeteer
const puppeteer = require("puppeteer");
//使用async/await处理异步
(async () => {
//创建一个Browser(浏览器)实例
const browser = await puppeteer.launch();
//在浏览器中创建一个新的页面
const page = await browser.newPage();
//设置页面的尺寸
await page.setViewport({
width: 1400,
height: 800,
});
//打开页面
await page.goto("https://baidu.com/");
//页面截图(设置截图路径)
await page.screenshot({path: "example.png"});
//关闭浏览器实例
await browser.close();
})();
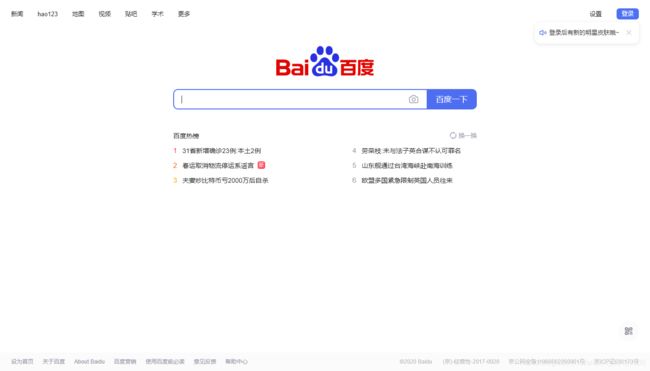
执行命令会在根目录下生成 example.png(页面截图)
example.png:
puppeteer 生成页面 PDF
//引入puppeteer
const puppeteer = require("puppeteer");
//使用async/await处理异步
(async () => {
//创建一个Browser(浏览器)实例
const browser = await puppeteer.launch();
//在浏览器中创建一个新的页面
const page = await browser.newPage();
//设置页面的尺寸
await page.setViewport({
width: 1400,
height: 800,
});
//打开页面
await page.goto("https://baidu.com/");
//生成页面PDF(设置PDF路径)
await page.pdf({path: "example.pdf", format: "A4"});
//关闭浏览器实例
await browser.close();
})();
执行命令会在根目录下生成 example.pdf(页面 PDF)
puppeteer 爬虫
使用 puppeteer 爬取:百度新闻 => 国内 => 即时新闻列表(标题和链接地址)
//引入puppeteer
const puppeteer = require("puppeteer");
//引入node文件系统模块(fs)
const fs = require("fs");
//引入node文件路径模块(path)
const path = require("path");
//创建爬取数据的函数
let getNewList = async () => {
//创建一个Browser(浏览器)实例
const browser = await puppeteer.launch();
//在浏览器中创建一个新的页面
const page = await browser.newPage();
//打开百度新闻页面
await page.goto("http://news.baidu.com/");
//等待“国内”导航按钮出现
await page.waitForSelector("#channel-all > div > ul > li:nth-child(3) > a");
//点击“国内”导航按钮,进入国内新闻页面
await page.click("#channel-all > div > ul > li:nth-child(3) > a");
//等待“即时新闻列表”出现
await page.waitForSelector("#instant-news > ul");
//通过evaluate函数执行自定义的js代码获取要爬取的数据
const newList = await page.evaluate(() => {
//创建一个空数组接收爬取的数据
let data = [];
//获取所有即时新闻列表li元素
let elements = document.querySelectorAll("#instant-news > ul > li");
//利用循环将即时新闻列表的标题和链接地址添加到一个数组中
for (let i=0; i<elements.length; i++) {
//获取新闻的标签
let title = elements[i].innerText;
//获取新闻的链接地址
let url = elements[i].firstChild.getAttribute('href');
//将获取到的标题和链接地址添加到数组中
data.push({
title,
url
});
}
//返回数组
return data;
});
//关闭浏览器实例
await browser.close();
//返回爬取的数据
return newList;
}
//执行函数获取爬取的数据
getNewList().then(res => {
//将爬取的数据转为json格式
let list = JSON.stringify(res);
//指定存储数据的json文件
let file = path.join(__dirname, "newList.json");
//将爬取的数据写入json文件
fs.writeFile(file, list, err => {
if (err) {
console.log(err);
} else {
console.log("success");
}
})
})
执行命令会在根目录下生成 newList.json(爬取的百度新闻国内即时新闻列表)
newList.json:
[
{
title: '倡导清洁能源取暖,让环保与温暖同行!',
url: 'http://baijiahao.baidu.com/s?id=1685083001881996849'
},
{
title: '关于减塑环保必胜客做了件大事 而且还做得挺漂亮',
url: 'http://baijiahao.baidu.com/s?id=1685499582365297158'
},
{
title: '「我的脱贫故事」脱贫前我们也害怕“开学”丨剑河',
url: 'http://baijiahao.baidu.com/s?id=1685501813192308560'
},
{
title: '山西留美学子靳蕾被聘为“中华环保志愿者公益形象',
url: 'http://baijiahao.baidu.com/s?id=1685513310840028026'
},
{
title: '忻城县2020年公开选拔县属国有企业领导人员面',
url: 'http://baijiahao.baidu.com/s?id=1685544017875709933'
},
{
title: '107名长沙市五星级环保好少年集中受表彰',
url: 'http://baijiahao.baidu.com/s?id=1685597128244025396'
},
{
title: '《圭塘河岸》一书发行 谱写新的“长江之歌”',
url: 'http://baijiahao.baidu.com/s?id=1685606433440976520'
},
{
title: '莫再错过!山东高考补报名12月14日-15日进',
url: 'http://baijiahao.baidu.com/s?id=1685607182699503282'
}
]