Redis数据类型(list\set\zset)

"maybe it's why"
List类型
列表类型是⽤来存储多个有序的字符串,列表中的每个字符串称为元素(element),⼀个列表最多可以存储个2^32 - 1个元素。在Redis中,可以对列表两端插⼊(push)和弹出(pop),还可以获取指定范围的元素列表、获取指定索引下标的元素等。列表是⼀种⽐较灵活的数据结构,它可以充当栈和队列的⻆⾊,在实际开发上有很多应⽤场景。
如何理解List有序?
有序的意思是要根据上下文来理解,比如,有序有时候是在谈它是升序或者是降序。而List的有序则是在谈其内部元素的"顺序",如果两个List中所含的元素、个数都是一样,但是元素内部里的顺序位置是不同的,那么这两个List不是同一个。
(1) LPUSH\LPUSHX

将⼀个或者多个元素从左侧放⼊(头插)到list中。

在key存在时,将⼀个或者多个元素从左侧放⼊(头插)到list中。不存在,直接返回。
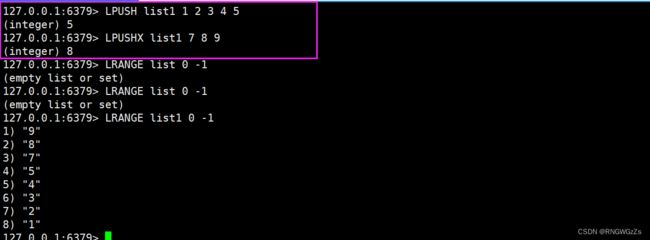
(2) RPUSH\RPUSHX

将⼀个或者多个元素从右侧放⼊(尾插)到list中。
 在key存在时,将⼀个或者多个元素从右侧放⼊(尾插)到list中。尾插效果同头插差不多,这里也就不做什么演示了。
在key存在时,将⼀个或者多个元素从右侧放⼊(尾插)到list中。尾插效果同头插差不多,这里也就不做什么演示了。
(3) LPOP\RPOP 
从list左侧取出元素(即头删)。
从list右侧取出元素(即尾删)。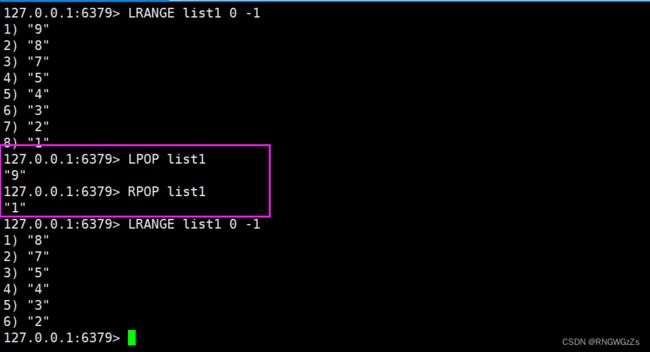
(4) LINDEX
 获取从左数第index位置的元素。
获取从左数第index位置的元素。 
(5) LINSERT\LLEN

在特定位置插⼊元素,可以携带选项

获取list⻓度。

(6) LREM \ LTRIM\ LSET

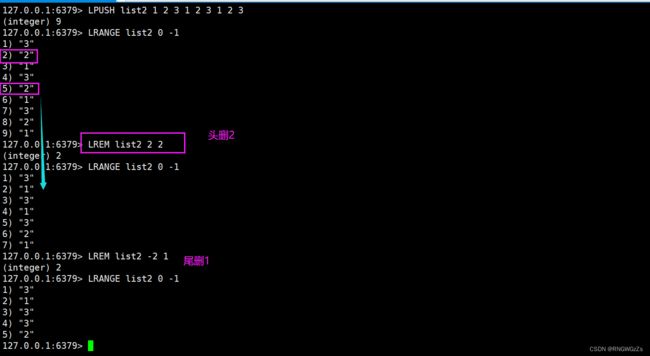

保留指定区间,区间以外的全部删除。

 根据下标,更改元素。
根据下标,更改元素。

(7) LRANGE

获取从start到end区间的所有元素,左闭右闭。

我们来谈谈越界访问?
如果我们用LRANGE,写出如下的命令,会发生什么?
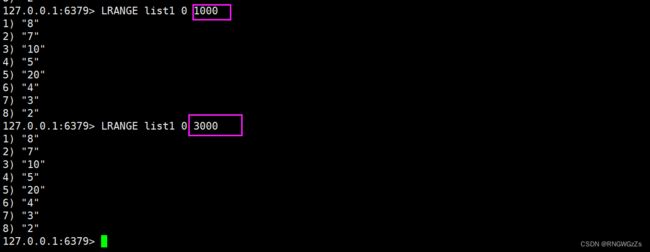
显然,此时的end下标已经远远超过了list包含元素的个数,但是在redis的处理之中并没有报错,而是调整为获取适当范围的元素。 
(8) List与消息队列

因为List支持高效的头插头删、尾插尾删,所以List既可以当做一个栈,又可以当做一个队列使用。在Stream类型没有出来之前,Redis有一个典型的应用场景,就是把List作为消息队列。
BLPOP\BRPOP
blpop和brpop是lpop和rpop的阻塞版本,和对应⾮阻塞版本的作⽤基本⼀致。
● 在列表中有元素的情况下,阻塞和⾮阻塞表现是⼀致的。但如果列表中没有元素,⾮阻塞版本会理解返回nil,但阻塞版本会根据timeout,阻塞⼀段时间,期间其余redis-cli可以执⾏其他命令,但要求执⾏该命令的客⼾端会表现为阻塞状态。
● 命令中如果设置了多个键,那么会从左向右进⾏遍历键,⼀旦有⼀个键对应的列表中可以弹出元
素,命令⽴即返回。
● 如果多个客⼾端同时多⼀个键执⾏pop,则最先执⾏命令的客⼾端会得到弹出的元素。


针对多个key进行操作:
 虽然List的这俩阻塞命令可以用来作为 “消息队列”,但它俩的功能实在有限,多少有点力不从心。
虽然List的这俩阻塞命令可以用来作为 “消息队列”,但它俩的功能实在有限,多少有点力不从心。
List命令小结:
| 操作类型 | 命令 | 时间复杂度 |
| 添加 | rpush key value [value...] | O(k),k为元素个数 |
| lpush key value [value...] | O(k),k为元素个数 | |
| linsert key |
O(k),k为pivot距离头尾的距离 | |
| 查找 | lrange key start end | O(s+n),s为start偏移量,n为start,end的范围 |
| lindex key index | O(n),n是索引偏移量 | |
| llen key | O(1) | |
| 删除 | lpop\rpop key | O(1) |
| lrem key count value | O(k),k为元素个数 | |
| ltrim key start end | O(k),k为元素个数 | |
| 修改 | lset key index value | O(n),n是索引偏移量 |
| 阻塞操作 | blpop/brpop | O(1) |
List的内部编码:
列表类型的内部编码有两种:
• ziplist:作为列表的内部编码实现来减少内存消耗。
• linkedlist:当列表类型⽆法满⾜ziplist的条件时,Redis会使⽤linkedlist作为列表的内部实现。
现如今,List底层的编码都是quicklist。


List使用场景
① 微博Timeline
每个⽤⼾都有属于⾃⼰的Timeline(微博列表),现需要分⻚展⽰⽂章列表。此时可以考虑使⽤列表,因为列表不但是有序的,同时⽀持按照索引范围获取元素。
● 每篇微博使⽤哈希结构存储,例如微博中3个属性:title、timestamp、content:
hmset mblog:1 title xx timestamp 1476536196 content xxxxx
hmset mblog:2 title xx timestamp 1476536196 content xxxxx
......
hmset mblog:n title xx timestamp 1476536196 content xxxxx
● 向⽤⼾Timeline添加微博,user:
lpush user:1 :mblogs mblog:1 mblog:3
...
lpush user:n :mblogs mblog:1 mblog:3
● 分⻚获取⽤⼾的Timeline,例如获取⽤⼾1的前10篇微博:
keylist = lrange user:1:mblogs 0 9
for key in keylist {
hgetall key
}
Set集合
集合类型也是保存多个字符串类型的元素的,但和列表类型不同的是,元素之间是⽆序且不允许重复。Redis除了⽀持集合内的增删查改操作,同时还⽀持多个集合取交集、并集、差集,合理地使⽤好集合类型,能在实际开发中解决很多问题。
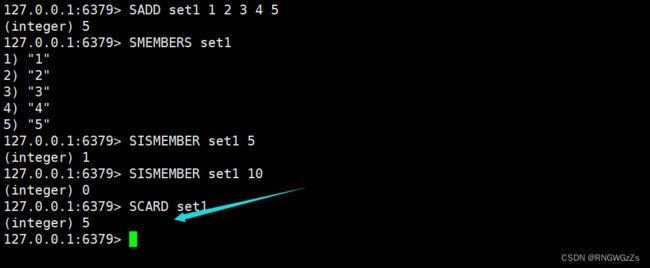
(1) SADD\SMEMBERS\SISMEMBER
 将⼀个或者多个元素添加到set中。注意,重复的元素⽆法添加到set中。
将⼀个或者多个元素添加到set中。注意,重复的元素⽆法添加到set中。

获取⼀个set中的所有元素,注意,元素间的顺序是⽆序的。

判断⼀个元素在不在set中。
(2) SCARD
 获取⼀个set的基数(cardinality),即set中的元素个数。
获取⼀个set的基数(cardinality),即set中的元素个数。
(3) SPOP\SREM 
从set中删除并返回⼀个或者多个元素。注意,由于set内的元素是⽆序的,所以取出哪个元素实际是未定义⾏为,即可以看作随机的。 
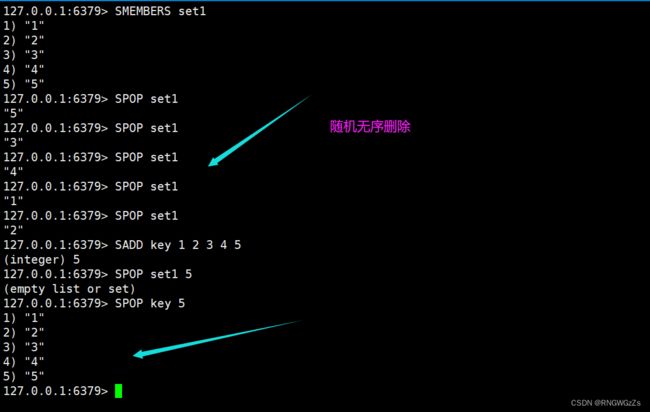
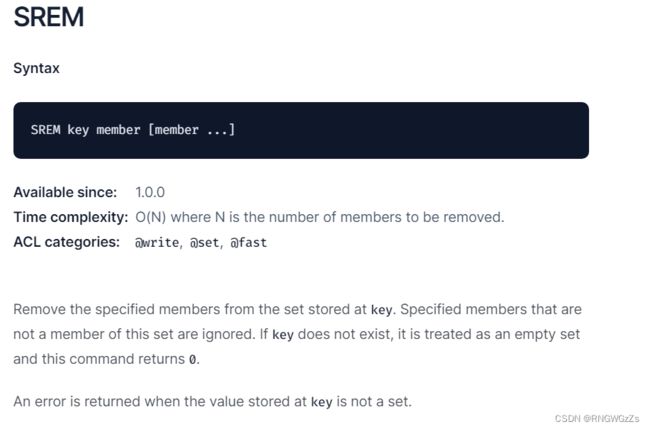 将指定的元素从set中删除。
将指定的元素从set中删除。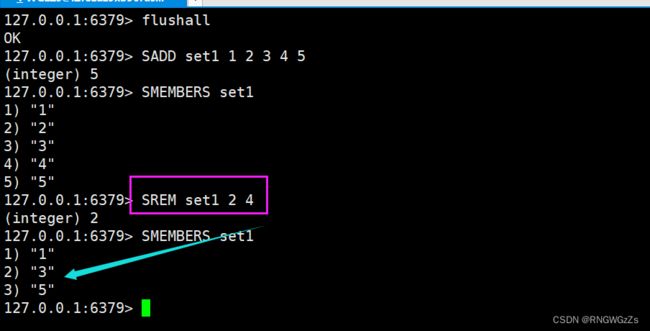
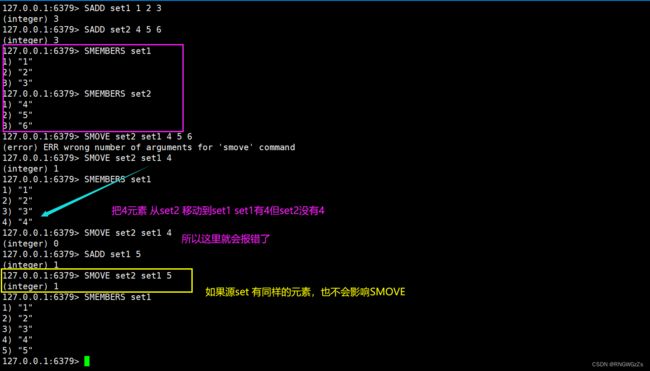
(4) SMOVE

将⼀个元素从源set取出并放⼊⽬标set中。
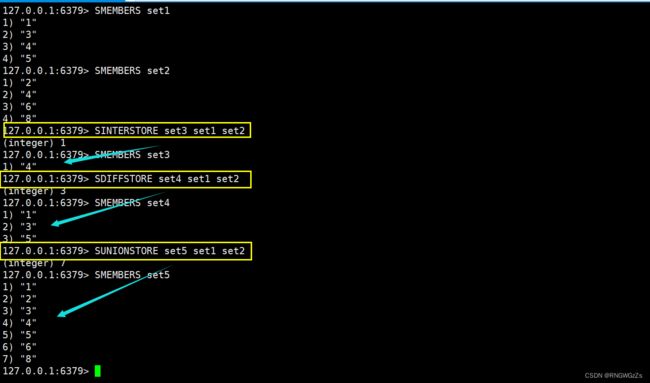
(5) SINTER\SUNION\SDIFF
Redis中的Set集合也支持求交、求并、求差,这里也就不多说什么是交并差的概念了。

获取给定set的交集中的元素。

获取给定set的并集中的元素。 获取给定set的差集中的元素。
获取给定set的差集中的元素。

(6) SINTERSTORE\SUNIONSTORESDIFFSTORE
我们上述的一系列操作,仅仅是将求得的结果输出在显示器上。但求这些结果更多的时候是需要被保存的。

获取给定set的交集中的元素并保存到⽬标set中。
获取给定set的并集中的元素并保存到⽬标set中。

获取给定set的差集中的元素并保存到⽬标set中。
Set命令小结
| 命令 | 时间复杂度 |
| sadd key element [ element ...] | O(k),k为元素个数 |
| srem key element [ element ...] | O(k),k为元素个数 |
| scard key | O(1) |
| sismember key element | O(1) |
| srandmemeber key [count] | O(n),n是count |
| spop key [count] | O(n),n是count |
| smembers key | O(k),k为元素个数 |
| sinter key [key...]\sinterstore | O(m*k),k为多个集合中元素最小的个数,m是键个数 |
| sunion key [key...]\sunionstore | O(k),k为多个集合的元素总和 |
| sdiff key [key...]\sdiffstore | O(k),k为多个集合的元素总和 |
Set内部编码
集合类型的内部编码有两种:
• intset(整数集合):当集合中的元素都是整数并且元素的个数⼩于set-max-intset-entries配置
(默认512个)时,Redis会选⽤intset来作为集合的内部实现,从⽽减少内存的使⽤。
• hashtable(哈希表):当集合类型⽆法满⾜intset的条件时,Redis会使⽤hashtable作为集合
的内部实现。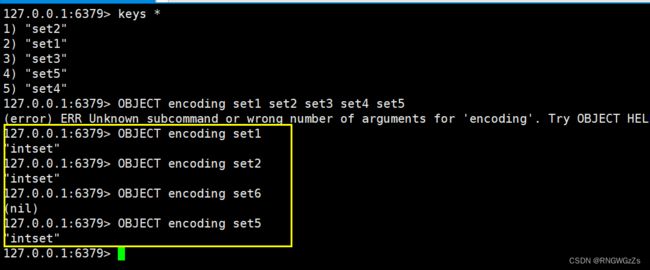
Set使用场景:
① 标签
集合类型⽐较典型的使⽤场景是标签(tag)。例如A⽤⼾对娱乐、体育板块⽐较感兴趣,B⽤⼾对历史、新闻⽐较感兴趣,这些兴趣点可以被抽象为标签。许多公司通过用户的这些隐私,对于增强⽤⼾体验和⽤⼾黏度都⾮常有帮助。
一旦给某些用户打上标签后,通过Set集合的交并差计算,很容易找到两个人的共同爱好等相似的行为。基于这样的标签,衍生出"用户关系",例如谁谁和你有多少个共同好友之类的……
② SetUV
如何衡量一个互联网产品?那就是看它的用户量。计算用户量的指标有两种方案:
PV: page view 用户每次访问这个服务器,都会产生一个pv,pv_count++。
UV: user view 每个用户访问服务器,产生一个uv,uv_count++,但如果是同一个用户多次请求访问这个服务器,uv则不会增加。
所以,这个uv的过程自动带有去重的要求,Set集合类型正好可以满足需求。
Zset集合
所谓的Zset集合本质是什么?其实伙同Set集合差别不大,而是新增了"权值"的概念。
它保留了集合不能有重复成员的,其中有序集合中的每个元素都有⼀个唯⼀的浮点类型的分数(score)与之关联,使得有序集合中的元素是可以维护有序性的,但这个有序不是⽤下标作为排序依据⽽是⽤这个分数。
比如,我们想给列举一下三国战力standing:
"一吕二赵三典韦,四关五马六张飞"。

有序集合提供了获取指定分数和元素范围查找、计算成员排名等功能,合理地利⽤有序集合,可以帮助我们在实际开发中解决很多问题。
列表List vs 集合Set vs 有序集合Zset:
| 数据结构 | 重复元素 | 有序无序 | 有序依据 | 应用场景 |
| 列表List | 是 | 是 | 索引下标 | 消息队列等 |
| Set | 否 | 否 | 标签、社交等 | |
| Zset | 否 | 是 | 分数score | 排行榜系统等 |
Zset命令
ZADD:
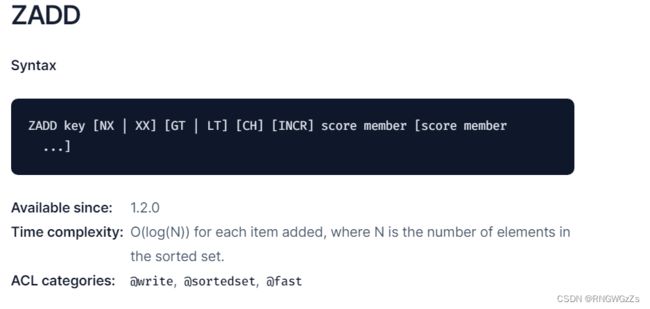
添加或者更新指定的元素以及关联的分数到zset中,分数应该符合double类型。 对于有序集合来说,Mermber里的更不像键值对,而是一组pair,因为它们互相都可以找到对方! 

• XX:仅仅⽤于更新已经存在的元素,不会添加新元素。
• NX:仅⽤于添加新元素,不会更新已经存在的元素。
• CH:默认情况下,ZADD返回的是本次添加的元素个数,但指定这个选项之后,就会还包含本次更
新的元素的个数。
• INCR:此时命令类似ZINCRBY的效果,将元素的分数加上指定的分数。此时只能指定⼀个元素和分数
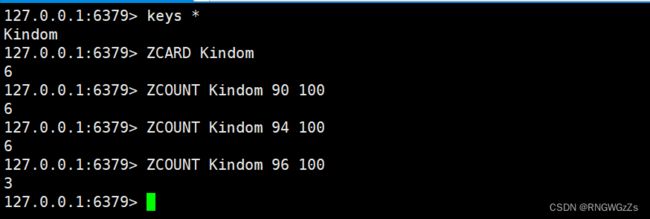
ZCARD\ZCOUNT:

获取⼀个zset的基数(cardinality),即zset中的元素个数。

返回分数在min和max之间的元素个数,默认情况下,min和max都是包含的。

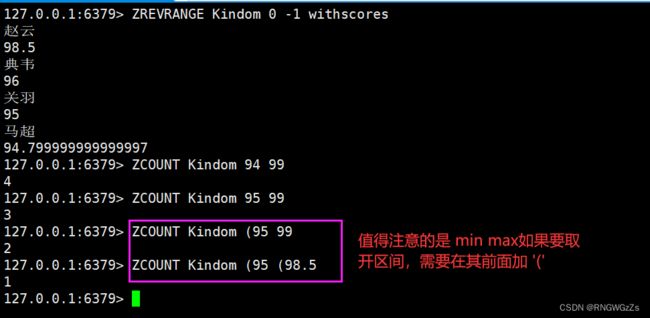
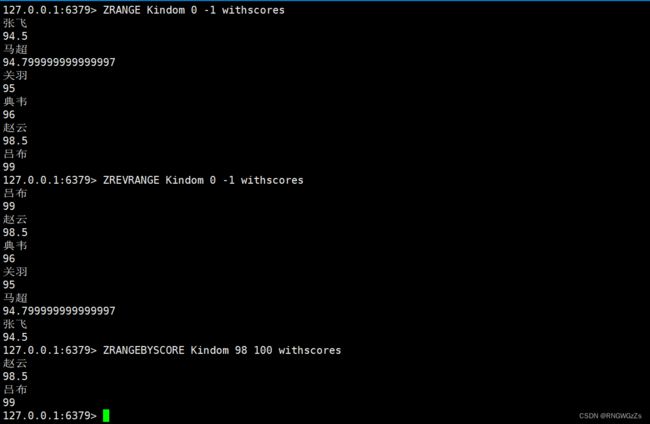
ZRANGE\ZREVRANGE\ZRANGEBYSCORE:

返回指定区间⾥的元素,分数按照升序。带上WITHSCORES可以把分数也返回。

返回指定区间⾥的元素,分数按照降序。带上WITHSCORES可以把分数也返回。

返回分数在min和max之间的元素,默认情况下,min和max都是包含的。
ZPOPMAX\ZPOPMIN:

删除并返回分数最⾼的count个元素。 删除并返回分数最低的count个元素。
删除并返回分数最低的count个元素。
 其中还有BZPOPMIN\BZPOPMAX这两个命令,这是它们的阻塞版本,也就不再此做过多讲解。
其中还有BZPOPMIN\BZPOPMAX这两个命令,这是它们的阻塞版本,也就不再此做过多讲解。
ZRANK\ZREVRANK:
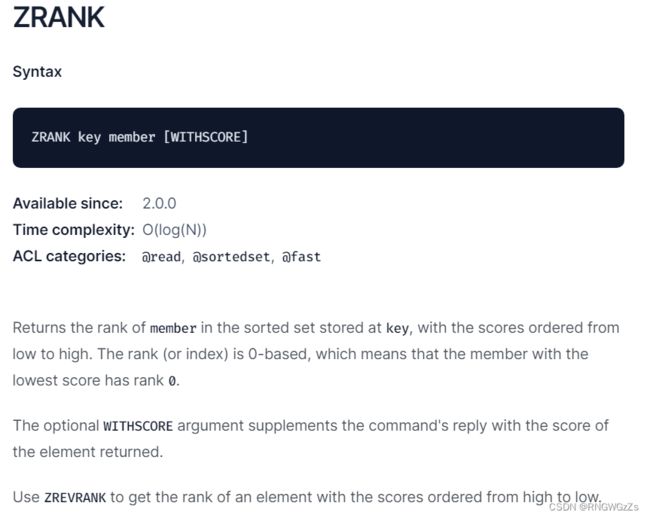
返回指定元素的排名,升序。 返回指定元素的排名,降序。
返回指定元素的排名,降序。
ZREM:
 删除指定的元素。
删除指定的元素。

ZINCRBY:
为指定的元素的关联分数添加指定的分数值。
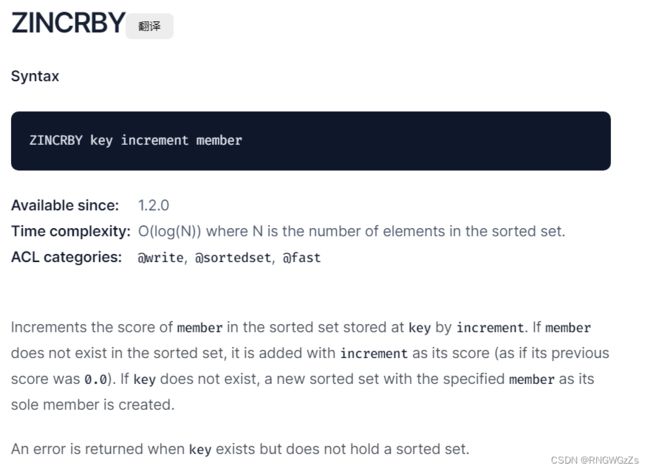
为指定的元素的关联分数添加指定的分数,并且会移动元素保证其有序。

ZINTERSTORE\ZUNIONSTORE\ZDIFFSTORE:
Zset有序集合也有支持交并差的运算。

求出给定有序集合中元素的交集并保存进⽬标有序集合中,在合并过程中以元素为单位进⾏合并,元素对应的分数按照不同的聚合⽅式和权重得到新的分数。
 求出给定有序集合中元素的并集并保存进⽬标有序集合中,在合并过程中以元素为单位进⾏合并,元素对应的分数按照不同的聚合⽅式和权重得到新的分数。
求出给定有序集合中元素的并集并保存进⽬标有序集合中,在合并过程中以元素为单位进⾏合并,元素对应的分数按照不同的聚合⽅式和权重得到新的分数。

求出给定有序集合中元素的差集并保存进⽬标有序集合中,在求差集过程中以元素为单位进⾏合并,元素对应的分数按照不同的聚合⽅式和权重得到新的分数。
也许你会疑问,为什么我们很多命令也是支持多个keys,比如说zadd、mget、mset等等,为什么这些命令没有要求写明需要多少个key呢?
其实你看这些命令的差别就在于,Zset有序集合系列如果不写明key有多少个,有可能会让key和参数搞混淆。
Zset命令小结:
| 命令 | 时间复杂度 |
| zadd key score member [score member] | O(k*log(n)) ,k是添加成员个数,n是当前有序集合元素个数 |
| zcard key | O(1) |
| zscore key member | O(1) |
| zrank/zrevrank key member | O(log(n)),n是当前有序集合的个数 |
| zrem key member [member...] | O(k*log(n)),k是删除成员的个数,n是当前有序集合的元素个数 |
| zincrby key increment member | O(log(n)),n是当前有序集合的个数 |
| zrange/zrevrange key start end [withsocres] | O(k+log(n)),k是删除成员的个数,n是当前有序集合的元素个数 |
| zcount | O(log(n)),n是当前有序集合的个数 |
| zremrangebyrank key min max | O(k+log(n)),k获取成员的个数,n是当前有序集合的元素个数 |
| zremrangebyscore key min max | O(k+log(n)),k获取成员的个数,n是当前有序集合的元素个数 |
| zinterstore destination numkeys key [key...] | O(n*k) + O(m * log(m)),n是输入的集合中最小的元素个数, k是集合个数,m是目标集合元素个数 |
| zunion destination numkeys key [key ...] | O(n*k) + O(m * log(m)),n是输入的集合中最小的元素个数, k是集合个数,m是目标集合元素个数 |
Zset内部编码:
有序集合类型的内部编码有两种:
• ziplist:Redis会⽤ziplist来作为有序集合的内部实现,ziplist可以有效减少内存的使⽤。
• skiplist:当ziplist条件不满⾜时,有序集合会使⽤skiplist作为内部实现,因为此时ziplist的操作效率会下降。

skiplist 是一种复杂链表,它一个节点可能存有多个下个节点的地址。但并非本节要细说的。
ZSet的应用场景:
Zset有序集合最关键的应用场景无非就是一些排行有关的榜单: 比如说微博热搜、游戏等级排行等等,最关键的要点是,这些数值是可能随时进行变动的,随之而来的排名也会相应进行变化。

当然,对于游戏排行榜,比如说啥段位、分数、等级十分清晰明了,可是遇到复杂度场景,比如说微博热搜:

本篇到此结束,感谢你的阅读。
祝你好运,向阳而生~
