Redis常用命令,你了解哪些呢?
目录
前置工作:先进入Redis客户端
1、Redis最核心的两个命令:get & set
set:存键值对
get:根据key,取出value
2、Redis全局命令
2.1、keys ---查询当前服务器上匹配的key
2.1.1. ? 匹配任意一个字符
2.1.2. * 匹配0个或任意多个字符
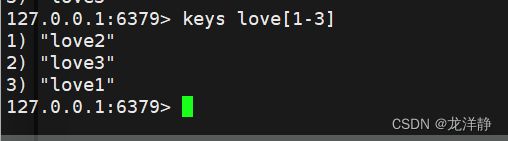
2.1.3. [123] 只能匹配到1 2 3 ,别的都不可以-固定选项
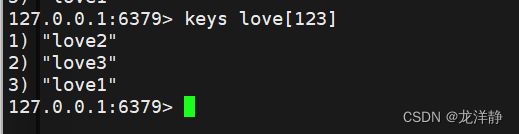
2.1.4. [^e] 排除e ,除了e其他都能匹配
2.1.5. [1-3]匹配1-3这个区间内的字符,包含边界值
2.1.6 keys的注意事项
2.2、 exists 判定key是否存在
2.3、del 删除指定的key
2.4、 expire 给指定的key设置过期时间
2.5、ttl 查看key的过期时间还剩多少
3、为什么redis的很多命令都支持一次对多个key进行操作
4、redis的key的过期策略是如何实现的?
5、使用定时器实现redis的过期策略思路
5.1、基于优先级队列实现的定时器
5.2、基于时间轮实现的定时器
前置工作:先进入Redis客户端
命令:redis-cli

1、Redis最核心的两个命令:get & set
redis中是以键值对的方式去存储数据,所以存储存储,当然要有存的这个操作啦~
set:存键值对
语法格式:set key value
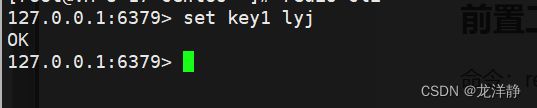
返回ok则存键值对成功~
存好了之后,后面使用就是需要通过key取出value值啦~
- 这里的key和value加不加单双引号都可以,就是表示一个字符串类型~
- redis中的命令不区分大小写
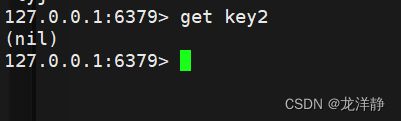
get:根据key,取出value
语法格式: get key

- key value存在则返回value值
- key value不存在,则返回nil 【类似于null】
2、Redis全局命令
Redis中支持很多的数据结构,整体上说就是Redis键值对结构,key固定是字符串,value实际上会有很多种类型~
全局命令就是能够搭配任意一个数据结构来使用的命令
2.1、keys ---查询当前服务器上匹配的key
通过一些特殊符号(通配符)来描述key的模样,匹配上模样的key就能被查询出来~
2.1.1. ? 匹配任意一个字符
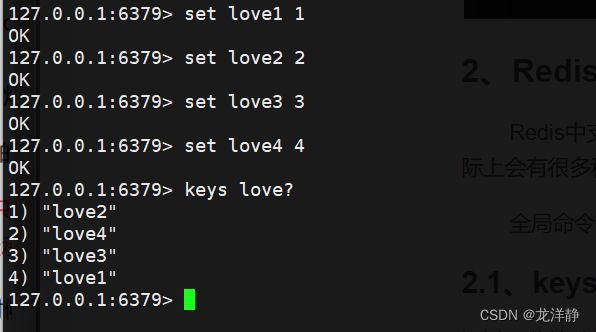
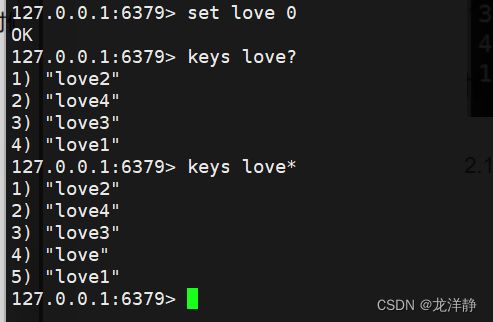
2.1.2. * 匹配0个或任意多个字符
2.1.3. [123] 只能匹配到1 2 3 ,别的都不可以-固定选项
2.1.4. [^e] 排除e ,除了e其他都能匹配
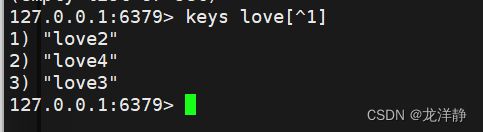
2.1.5. [1-3]匹配1-3这个区间内的字符,包含边界值
2.1.6 keys的注意事项
- keys命令的时间复杂度是O(n)
- keys * 要慎用 -- keys * 的时间可能会非常长,导致redis被阻塞了,无法给其他客户端提供服务,此时可能会导致请求直接去数据库查询了,请求量比较大的情况下,容易让mysql挂掉~
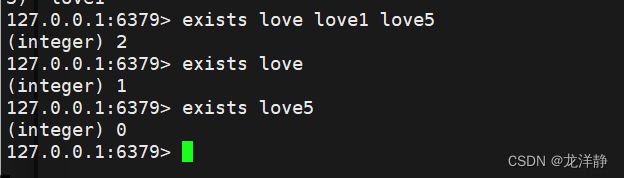
2.2、 exists 判定key是否存在
- 语法格式:exists key [key ...]
- 返回值:key存在的个数-->针对多个key来说是有用滴【key是唯一的,这里指的个数,意思是一次判定多个key是否存在,返回个数】
- 时间复杂度O(1)
例:
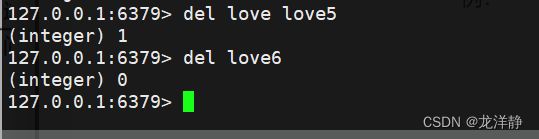
2.3、del 删除指定的key
- 语法格式:del key [key ...]
- 返回值:删除掉的key的个数
- 时间复杂度O(1)
例:
注:
删除操作,需不需要谨慎对待?
分情况。具体来说:redis主要的应用场景就是作为缓存,此时redis里存的只是一个热点数据,全量数据是在MySQL数据库中的,这种情况下,把redis中的key删掉一个或几个,问题不大~但如果把redis中的一大半以上的数据都给删除了,问题就会很大,为什么?当redis中没有这些数据,请求来了,就会去MySQL中找,请求大的话,MySQL就比较容易挂掉~ 此外如果说,直接把redis就当做数据库来用,那删数据,哪怕是删了一个,影响也很大~ 再此外,redis作为消息队列时,这种情况下,删数据影响大不大就需要看具体的业务类场景了~
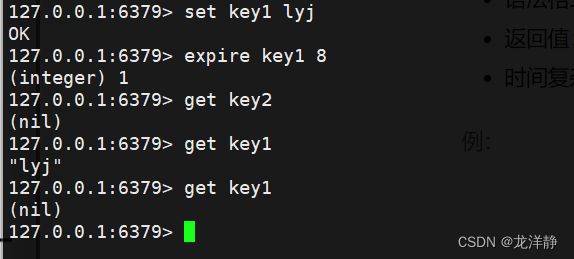
2.4、 expire 给指定的key设置过期时间
- 语法格式: expire key seconds
- 返回值:成功为1,失败为0
- 时间复杂度O(1)
- 适用场景:手机验证码等
例:
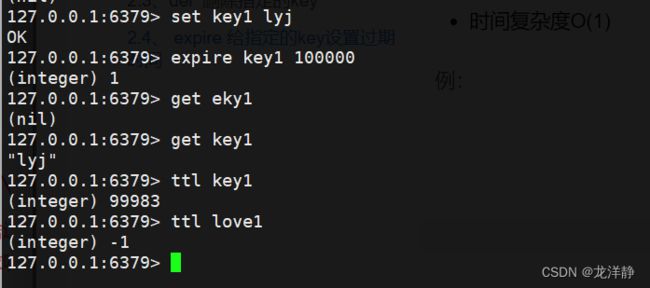
2.5、ttl 查看key的过期时间还剩多少
- 语法格式: ttl key
- 返回值:有过期时间则返回剩余时间,无【key存在】则返回-1,key不存在返回-2
- 时间复杂度O(1)
例:
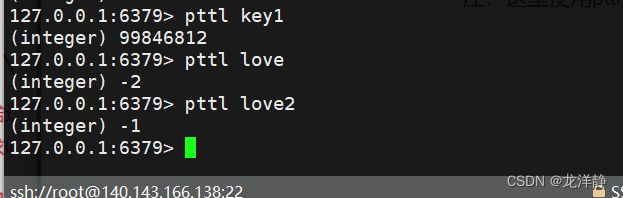
注:这里使用pttl也可以:
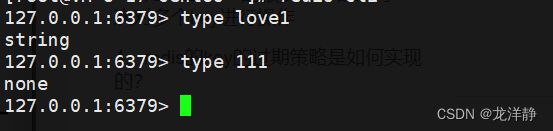
2.6、type 查看key对应value的数据类型
- 语法格式:type key
- 返回格式:对应的数据类型,无key则返回none
- 时间复杂度:O(1)
- redis中所有的key都是string,key对应的value值可能存在多种类型
例:
3、为什么redis的很多命令都支持一次对多个key进行操作
redis是一个客户端 服务器 结构的程序,客户端和服务器之间通过网络来通信~
如果redis不支持一次对多个key进行操作,那必然会产生更多轮次的网络通信,而网络通信中,对数据的封装和分用都需要时间,更何况你的客户端和服务器不一定在一个主机上,中间还隔得很远~
因此,redis的很多命令都支持一次就能操作多个key
4、redis的key的过期策略是如何实现的?
部分同学猜测哈?会不会是将redis中的key进行遍历一下,该删删该留留呢?还挺暴力哈!但是这种操作,效率非常的低,再加上redis本身就是以单线程来工作的,这样就是导致效率非常的低~
redis的过期策略:
- 定期删除
- 惰性删除
定期删除:在一段时间中,抽取部分key进行检测,该删删,该留留,一段时间后再来一次~
惰性删除:当key的过期时间到了,但他还没有被删除,key还存在,而后等到下次使用到这个key时,再检查过期时间,该删删,该留留
上述两者虽然能够处理一些过期的key,但是依然会存在很多过期的key可能未被及时删除,因此redis有提供了很多的内存淘汰策略~
Redis中未引用定时器的方式来清理过期key,考虑是不想引入多线程~
5、使用定时器实现redis的过期策略思路
5.1、基于优先级队列实现的定时器
优先级队列中,采用“过期时间越早,优先级越高”的思路~
当redis中,有很多key设置了过期时间,那就可以将这些key加入到优先级队列中,指定优先级规则是过期时间你越早的,先出队列,例如我们可以使用小根堆作为辅助,对首元素就是最早要过期的key。
此时呢,定时器只要分配一个线程,让这个线程去检查对首元素是否过期,过期则删除,没有过去的话,再根据对首元素的过期时间来设置等待时间,到了时间后,再来检查~ 那这里呢,如果临时加了一个新任务,例如上次设置等待1小时再检查,而这个任务半小时后过期,怎么办?我们可以在添加新任务时,唤醒刚才的线程,重新检查一下对首元素,再调整等待时间~
5.2、基于时间轮实现的定时器
把时间划分为很多个小段,具体划分要根据需求~
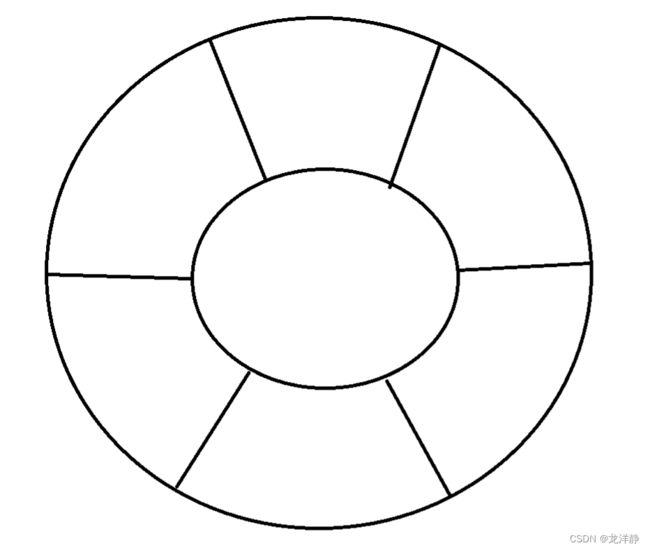
例如上述这样的,每个小间隔都是一个时间间隔,例如:10s
每个小间隔中,都挂着一个链表~
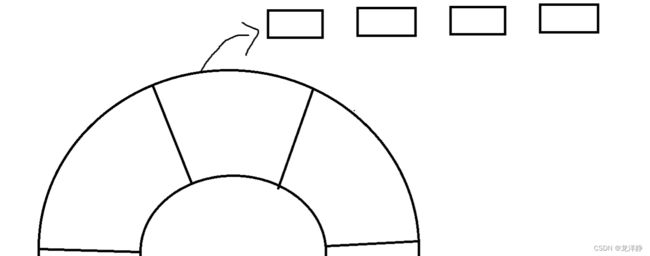
每个链表都是一个任务~
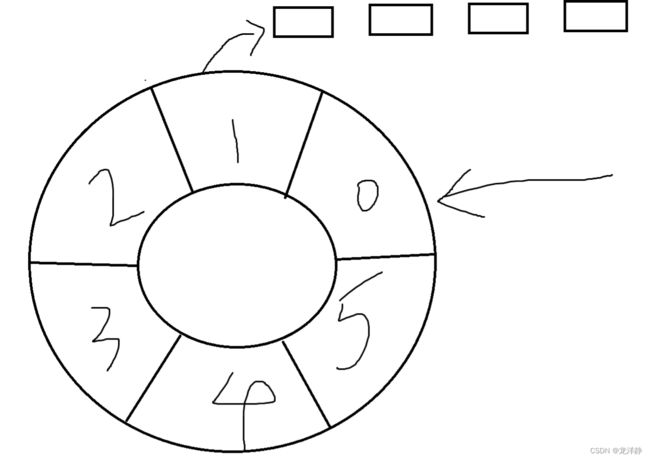
可能是10s后尝试执行第一个格子中链表的任务,再10s后执行第二个,依次进行~
对于实践论来说,每个格子的时间,共多少格子,都要根据实际业务场景来调整~
好啦~本期到这里了,下期见啦~