【数据结构】带头双向循环链表及其实现
目录
1.带头双向循环链表
2.带头双向循环链表实现
2.1初始化
2.2销毁
2.3头插
2.4链表打印
2.5头删数据
2.6尾插数据
2.7尾删数据
2.8链表判空
2.9查找一个数据
2.10在pos位置前插入数据
2.11删除pos位置
2.12求链表的长度
2.顺序表和链表的比较
1.带头双向循环链表
我们已经实现了无头单向循环链表
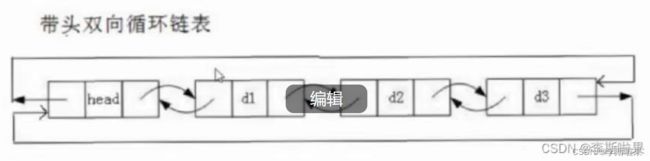
带头双向链表结构如下:
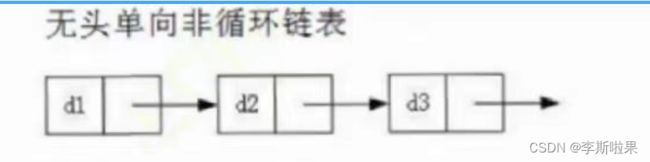
对于无头单向非循环链表,其具有以下特点:
- 第一个节点即为存储有效数据的节点
- 每个节点有包括数据域和指针域,这个指针指向下一个节点
- 空链表为NULL
对于带头双向循环链表,其具有以下特点
- 第一个节点为哨兵头节点,其数据域不存储有效数据
- 每个节点包含数据域和两个指针域prev和next,prev指针指向后一个节点,next指针指向前一个节点,对于哨兵头节点,其prev指针指向链表的尾节点,对于尾节点,其next指针指向哨兵头节点,因此形成了一个循环的结构
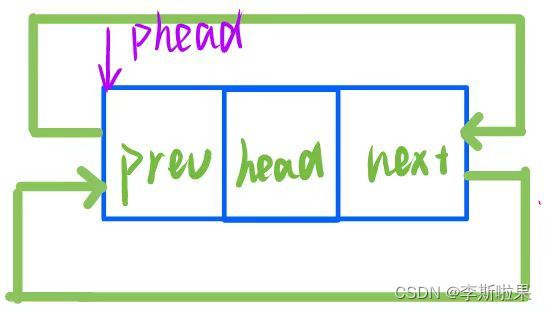
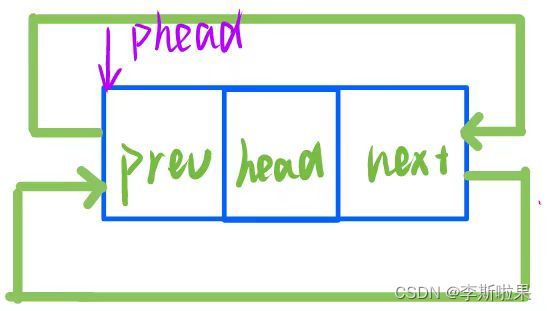
- 空链表时链表包含一个哨兵头节点,如下图:
2.带头双向循环链表实现
2.1初始化
对于一个带头双向循环链表,初始化后其为有一个哨兵头节点的结构
即初始化需要动态开辟一个节点作为哨兵头节点,其具有以下结构
//初始化
LTNode* ListInit(LTNode** pphead)
{
LTNode* guard = (LTNode*)malloc(sizeof(LTNode));//哨兵头节点
if (guard == NULL)
{
perror("malloc fail");
exit(-1);
}
else
{
guard->next = guard;
guard->prev = guard;
return guard;
}
}
2.2销毁
因为链表所有节点的空间都是动态开辟的,因此对链表进行操作后,为了避免内存泄漏,需要释放这些节点所占用的空间,销毁链表遍历释放每个节点即可,需要注意哨兵头节点也是动态开辟的空间,也需要释放
//销毁
void ListDestroy(LTNode* phead)
{
assert(phead);
//遍历释放每个节点
LTNode* cur = phead->next;
while (cur != phead)
{
LTNode* next = cur->next;//保存下一个节点
free(cur);
cur = next;
}
//释放哨兵头节点
free(phead);
phead = NULL;//参数为一级指针,形参的改变不影响实参
}
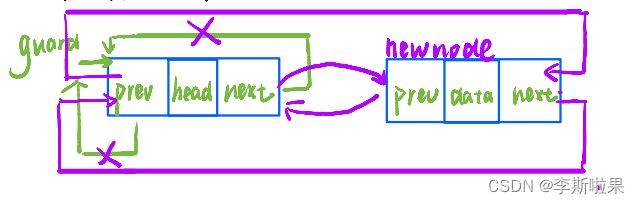
2.3头插
头插数据有两种情况:
1️⃣空链表时头插
2️⃣非空链表时头插
由上图可以发现:由于带头双向循环链表结构的特殊性,空链表头插和非空链表头插时操作相同
//创建节点
LTNode* BuyNode(LTDataType x)
{
LTNode* newnode = (LTNode*)malloc(sizeof(LTNode));
if (newnode == NULL)
{
perror("malloc fail");
exit(-1);
}
newnode->data = x;
newnode->prev = newnode->next = NULL;
return newnode;
}
//头插数据
void ListPushFront(LTNode* phead, LTDataType x)
{
assert(phead);
LTNode* newnode = BuyNode(x);
LTNode* next = phead->next;
phead->next = newnode;
newnode->prev = phead;
newnode->next = next;
next->prev = newnode;
}
2.4链表打印
为了方便调试,可以编写打印函数展示我们所创建的链表,遍历打印每个节点的数据域即可
//打印链表
void ListPrint(LTNode* phead)
{
assert(phead);
LTNode* cur = phead->next;
while (cur != phead)
{
printf("%d<=>", cur->data);
cur = cur->next;
}
printf("\n");
}2.5头删数据
头删数据需要判断链表是否为空,空链表则不能进行数据的删除
特殊情况分析:只有一个节点时头删
由上图可以发现:仅有一个节点时的头删操作和一般情况下头删操作步骤相同
//头删数据
void ListPopFront(LTNode* phead)
{
assert(phead);
//空链表则不能删除
assert(!ListEmpty(phead));
LTNode* first = phead->next;//first为第一个有效数据节点
phead->next = first->next;
first->next->prev = phead;
free(first);
first = NULL;
}
2.6尾插数据
尾插数据有两种情况:
1️⃣空链表时尾插
2️⃣非空链表时头插
由上图可以发现:空链表尾插和非空链表尾插时操作相同,所以不用分情况讨论
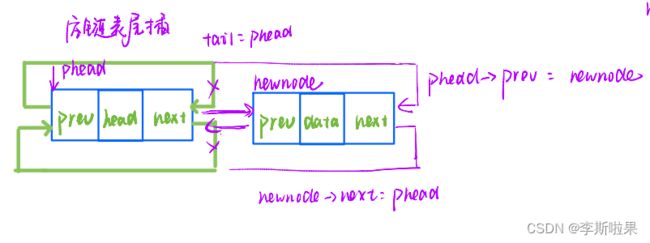
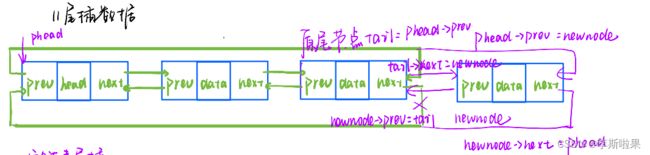
//尾插数据
void ListPushBack(LTNode* phead, LTDataType x)
{
assert(phead);
LTNode* tail = phead->prev;//tail为原尾节点
LTNode* newnode = BuyNode(x);
tail->next = newnode;
newnode->prev = tail;
phead->prev = newnode;
newnode->next = phead;
}
2.7尾删数据
尾删数据需要判断链表是否为空,空链表则不能进行数据的删除
非空链删除
特殊情况分析:只有一个节点时尾删
由上图可以发现:仅有一个节点时的尾删操作和一般情况下尾删操作步骤相同
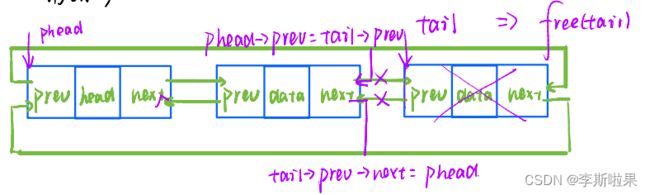
//尾删数据
void ListPopBack(LTNode* phead)
{
assert(phead);
LTNode* tail = phead->prev;//tail为尾节点
phead->prev = tail->prev;
tail->prev->next = phead;
}
2.8链表判空
当链表中只有哨兵头节点时,链表即为空
//判空
bool ListEmpty(LTNode* phead)
{
assert(phead);
return phead->next == phead;
}
2.9查找一个数据
从存储有效数据的第一个节点开始遍历链表,查找所给数据
如果找到了,则返回该节点的地址,返回地址也可以对该节点进行修改
遍历结束,没找到,则返回NULL
//查找一个数据
LTNode* ListFind(LTNode* phead, LTDataType x)
{
assert(phead);
//遍历查找
LTNode* cur = phead->next;
while (cur != phead)
{
if (cur->data == x)
{
return cur;//返回节点地址,可以进行修改
}
cur = cur->next;
}
return NULL;
}
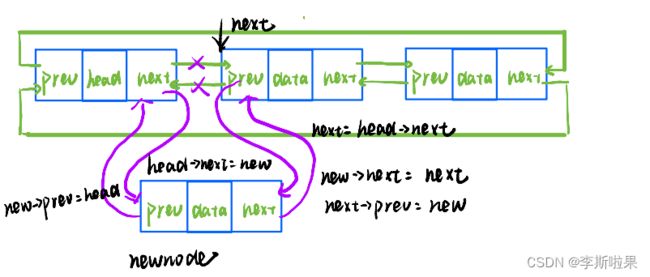
2.10在pos位置前插入数据
在pos之前插入数据,需要直到pos前一个节点的地址。在带头双向循环链表中,pos节点中prev指针域存储了前一个节点的地址,使插入数据更加方便,步骤如下:
特殊情况:空链表时,只能在哨兵头节点之前插入,且步骤与上述相同
需要函数调用者保证pos的有效性
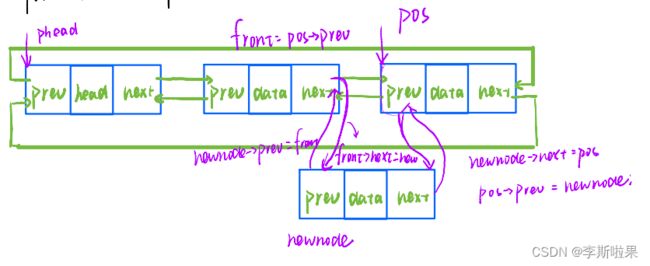
//在pos之前插入
void ListInsert(LTNode* pos, LTDataType x)
{
assert(pos);
LTNode* front = pos->prev;
LTNode* newnode = BuyNode(x);
front->next = newnode;
newnode->prev = front;
newnode->next = pos;
pos->prev = newnode;
}
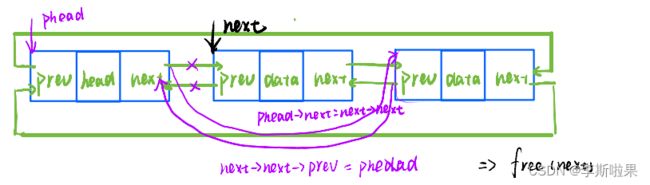
2.11删除pos位置
pos节点中既存储了其前一个节点的位置,又存储了其后一个节点的位置
删除pos位置:链表不为空时才能删除,链接其前后节点并释放pos节点即可
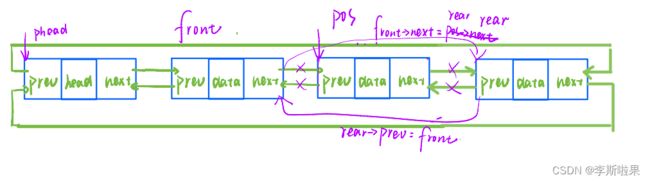
//删除pos位置
void ListErase(LTNode* phead, LTNode* pos)
{
assert(phead);
assert(pos);
assert(!ListEmpty(phead));
LTNode* front = pos->prev;
LTNode* rear = pos->next;
front->next = rear;
rear->prev = front;
free(pos);
pos = NULL;
}
2.12求链表的长度
遍历链表统计节点个数即可
//求链表的长度
int ListSize(LTNode* phead)
{
assert(phead);
LTNode* cur = phead->next;
int size = 0;
while (cur != phead)
{
++size;
cur = cur->next;
}
return size;
}2.顺序表和链表的比较
| 不同点 | 顺序表 | 链表 |
| 存储空间 | 物理上一定连续 | 逻辑上连续,物理上不一定连续 |
| 随机访问 | 支持,且时间复杂度为O(1) | 不支持,访问任意元素的时间复杂度为O(N) |
| 任意位置插入或删除元素 | 需要挪动元素,效率低 | 只需要修改指针的方向,效率较高 |
| 插入 | 动态顺序表,空间不够时需要扩容 | 随用随取,不存在容量的概念 |
| 应用场景 | 元素高效存储,需要随机访问 | 任意位置频繁插入或删除 |
| 缓存利用率 | 高 | 低 |
总结:
顺序表的优点:
- 尾插和尾删的效率高
- 元素通过下标访问,物理存储空间连续,支持随机访问
顺序表的缺点:
- 头部插入和中间位置插入需要挪动元素,效率低
- 扩容操作存在性能消耗和空间浪费
链表的优点:
- 任意位置插入和删除的时间复杂度为O(N),效率高
- 按需申请和释放内存,不存在空间浪费
链表的缺点:
- 不支持随机访问
扩展:
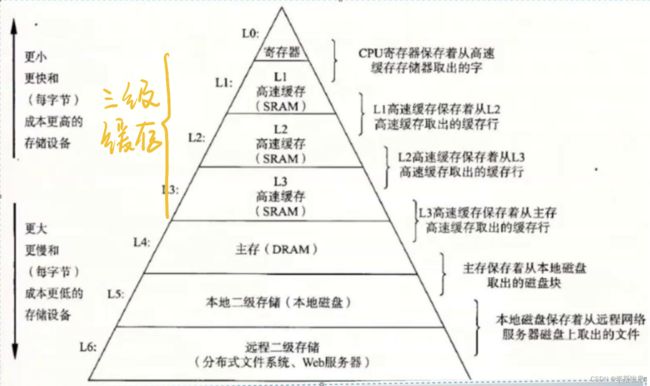
顺序表的优点:相对链表,CPU高速缓存命中率高
CPU执行指令,不会直接访问内存,通常为以下两步:
- 数据在三级缓存,命中,直接访问
- 若数据不在三级缓存,则先加载到缓存,再访问
顺序表结构使用数组实现:
如上图:要访问0x11223344中的数据,则从0x11223344开始的一段数据都加载进去缓存,加载多少取决于硬件
对于链表,因为其物理存储空间不连续,因此加载到缓存中的这一段数据中可能存在无效数据,导致缓存污染
