2.4 关系数据库
思维导图:

前言: 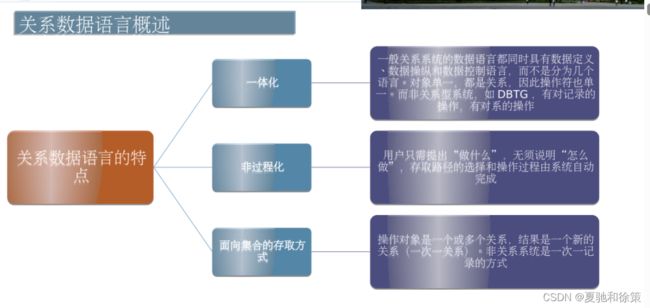
这段话描述了“关系数据库”及其背后的理论基础。首先,我们来拆分这段话并逐步解释每部分。
-
关系数据库是采用关系模型作为数据组织方式的数据库。
这句话的关键是“关系模型”。关系模型是一种表示和操作数据库的理论模型。它由数学家E.F. Codd于1970年提出。在关系模型中,数据被组织成“关系”,我们常常称之为“表”。每一个表由行和列组成,行代表实体或记录,列代表实体的属性。比如,一个“学生”表可以有“姓名”,“学号”,“专业”等列。
-
关系数据库是应用数学的方法来处理数据库中的数据,也就是说,它是建立在严格的数学理论基础之上的。

这部分强调了关系数据库的数学基础。当我们提及关系数据库中的“关系”,我们实际上是在引用集合论的概念,因为一个表其实就是一种数据的集合。此外,关系数据库中的操作,如选择、投影和连接等,都有明确的数学定义和属性。这使得关系数据库具有严格性,也意味着我们可以通过数学来预测和理解数据库操作的行为。
综上所述,这段话说明了关系数据库基于关系模型来组织数据,并且它的工作原理是基于严格的数学理论的。这种数学基础确保了关系数据库操作的可预测性和一致性。

2.4.1 关系模型的组成 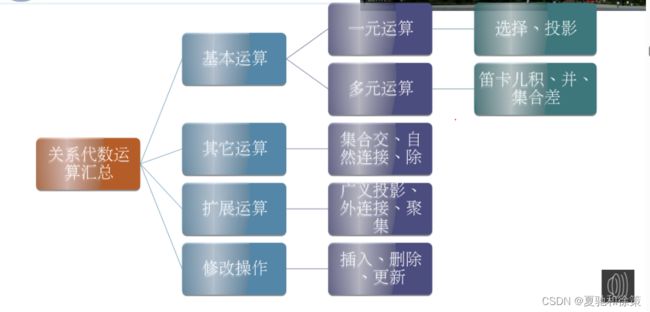
这段话详细描述了关系模型的三大组成部分:关系数据结构、关系操作集合和关系完整性约束。以下是对每部分的简要解释:
1. **关系数据结构**:
- 关系模型中的数据组织方式是一个二维表(关系),由行和列组成。
- 这个二维表代表现实世界的实体和它们之间的关系。
- 这种结构提供了一个简单、直观的方式来表示和理解数据。
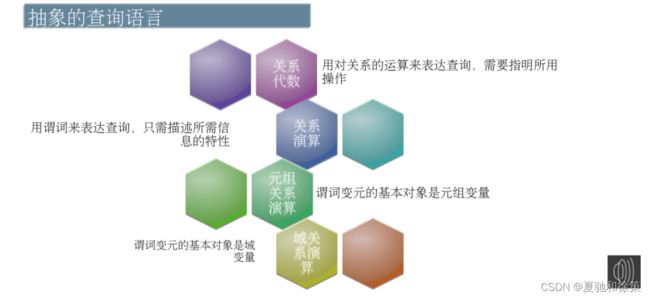
2. **关系操作集合**:
- 这部分描述了如何查询和操作关系模型中的数据。
- 初始的关系操作方式可以分为**关系代数**和**关系演算**:
- **关系代数**:使用运算来表示查询请求,如并、交、差等。
- **关系演算**:使用谓词逻辑来表达查询。它又分为两种:元组关系演算和域关系演算,其中元组关系演算关注行(元组),而域关系演算关注列(域)。
- 这三种语言(关系代数、元组关系演算和域关系演算)在功能上是等价的。
- 随后,为了提供一个更加高级和直观的方式来操作关系数据库,出现了**SQL**(结构化查询语言)。SQL不仅用于查询,还支持数据的定义和控制,并已成为关系数据库的标准语言。
- 关系操作通常使用集合的方式,例如选择、投影和连接等。
- 关系模型定义了一系列的操作,但并不规定具体的语法。具体的实现和语法是由数据库管理系统(DBMS)决定的。
3. **关系完整性约束**:
- 完整性约束确保数据的一致性和正确性。
- 关系模型定义了三种完整性约束:
- **实体完整性**:确保每个实体都有一个唯一的标识。
- **参照完整性**:确保数据库中的外键值与其关联的主键值匹配。
- **用户定义的完整性**:根据具体应用或业务需求定义的特定约束。
这三部分确保了关系模型的功能完备、操作的一致性和数据的完整性。

2.4.2 关系的数据定义 
1. **域(Domain)**:一个域是一组具有相同数据类型的值的集合,比如自然数或字符集合。
2. **笛卡尔积(Cartesian Product)**:如果你有两个域,例如D₁和D₂,那么D₁和D₂的笛卡尔积就是所有可能的D₁和D₂的组合。例如,如果D₁表示学校名称,D₂表示学生名称,那么笛卡尔积就会列出所有学生与所有学校的可能组合。
3. **元组(Tuple)**:笛卡尔积中的每一个组合都是一个元组。如果它是由n个域组合而成的,我们称它为一个n元组。
4. **关系(Relation)**:在关系数据库中,关系是由笛卡尔积衍生出来的,它可以被表示为一个二维表。每一行是一个元组,每一列是一个域。
需要补充的部分:
- **键(Key)**:在关系数据库中,键是用来唯一标识关系中的元组的。有多种不同类型的键,如主键、候选键、超键等。主键是关系中用于唯一标识元组的属性或属性组合。
- **外键(Foreign Key)**:外键是一个关系中的属性或属性组合,其值必须匹配另一个关系的主键。
- **范式(Normalization)**:在关系数据库设计中,范式是用来评估和确保数据的逻辑结构减少冗余和避免不希望的数据模式的一种方法。
- **约束(Constraints)**:除了前面提到的完整性约束,关系数据库还支持其他类型的约束,如唯一性约束、默认约束和检查约束。

2.4.3 关系代数
这篇文本主要讨论了关系数据库,重点是关系数据库中用于操纵关系(或表)的数学运算及其相应的符号。
**1. 关系运算 (Relational Operations)**
- **传统的集合运算 (Traditional Set Operations)**
这些操作适用于关系,与传统集合的应用方式相同。
1. **并 (Union, 记作 U)** - 将具有相同属性和域的两个关系结合在一起,并移除重复项。
2. **差 (Difference, 记作 -)** - 检索在一个关系中但不在另一个关系中的元组。
3. **交 (Intersection, 记作 ∩)** - 检索在两个关系中都存在的元组。
4. **笛卡儿积 (Cartesian Product, 记作 ×)** - 将一个关系中的每个元组与另一个关系中的每个元组组合在一起。
- **专门的关系运算 (Specific Relational Operations)**
这些是针对关系的专门操作。
1. **选择 (Selection, 记作 σ)** - 选择满足条件的元组。
2. **投影 (Projection, 记作 Π)** - 选择指定的列。
3. **连接 (Join, 记作 ⨝)** - 将两个关系中的相关元组结合在一起。
4. **除 (Division)** - 在一个关系中识别与另一个关系中的所有元组相关的元组。
**2. 关系代数中使用的运算符 (Operators in Relational Algebra)**
除集合操作外,关系代数还使用:
- **算术比较符 (Arithmetic Comparison Operators)** 如 >, ≥, <, ≤, =, ≠。
- **逻辑运算符 (Logical Operators)** 如 非、与、或。
**3. 示例**
文本使用两个表,Course1和Course2,演示了关系上的传统集合操作:
- **并 (Union)** - 将两个表中的行组合在一起,不包含重复项。
- **差 (Difference)** - 检索存在于Course1但不在Course2中的行。
- **交 (Intersection)** - 从两个表中检索公共行。
- **笛卡儿积 (Cartesian Product)** - 将Course1的每一行与Course2的每一行组合,由列出的组合来证明这一点。
**结论**
这篇文章的要点是演示关系数据库模型中可用的各种数学运算。这些操作允许操纵和查询存储在关系或表中的数据,使数据库成为信息检索和管理的强大工具。

2.4.5 专门的关系运算
简要回顾一下这些概念:
1. **选择 (Selection)**: 这是一个行操作,从关系R中选择满足特定条件的元组。例如,查询男性作者的信息,从作者表中选择性别为男的记录。
2. **投影 (Projection)**: 这是一个列操作,从关系R中选择出某些属性列,形成一个新的关系。例如,查询所有作者的编号和姓名,从作者表中选择AuthorID和Name两个属性。
3. **连接 (Join)**: 连接是在两个关系之间的操作,它从这两个关系的笛卡尔积中选取满足某些条件的元组。例如,查询某个作者出版的图书信息,可能需要连接作者表和出版表。
- **等值连接 (Equijoin)**: 连接条件基于等于运算符。
- **自然连接 (Natural Join)**: 两个关系中的共有属性必须有相同的值,并且结果中删除重复的列。
4. **除 (Division)**: 这是一个行和列都涉及的操作。给定两个关系R和S,R与S的除运算结果是一个新关系,满足某些条件的R的元组。
除了上述基本概念,还介绍了关系模型的一些基本性质,如列的同质性、属性的唯一性、行和列的顺序的不重要性等。此外,还定义了关系模式和关系代数。





 总结:
总结:
关系数据库是一个复杂的领域,下面我为你总结关系数据库的重点、难点和易错点:
**重点:**
1. **关系模型基础**:理解关系、元组、属性、域和关系模式的概念。
2. **关系操作**:学会使用选择、投影、连接、除等关系运算。
3. **完整性约束**:域约束、实体完整性和参照完整性。
4. **关系代数**:作为关系数据库的理论基础,它为SQL语言提供了数学基础。
5. **SQL语言**:学习SQL的DDL、DML和DCL部分,理解SQL查询的编写。
6. **规范化**:为了避免数据冗余和异常,数据需要被组织到某种“正常形式”中。
**难点:**
1. **连接操作**:理解等值连接、自然连接、外连接、左连接、右连接等的区别。
2. **规范化理论**:理解不同的正规形式(如1NF, 2NF, 3NF, BCNF等)并应用它们以解决实际问题。
3. **子查询与关联子查询**:理解子查询的执行顺序和它们如何与主查询交互。
4. **事务管理**:理解事务、ACID属性、锁以及并发控制的概念。
**易错点:**
1. **误用关键字**:例如在SQL中使用`AND`和`OR`时,不注意它们的优先级。
2. **数据插入错误**:尝试插入不满足参照完整性约束的数据。
3. **忘记提交或回滚事务**:导致资源长时间锁定或未保存的数据更改。
4. **规范化过度**:过度规范化可能导致数据库性能下降和查询复杂化。
5. **忽略索引**:不适当地使用或完全忽略索引,导致查询效率低下。
6. **不恰当的数据类型选择**:例如使用VARCHAR来存储日期或使用INT来存储小数。
总的来说,关系数据库涉及许多理论和实践的知识。为了深入理解并有效地使用它,需要不断地学习和实践。
