4.1 链式栈StackT
C++关键词:内部类/模板类/头插
C++自学精简教程 目录(必读)
C++数据结构与算法实现(目录)
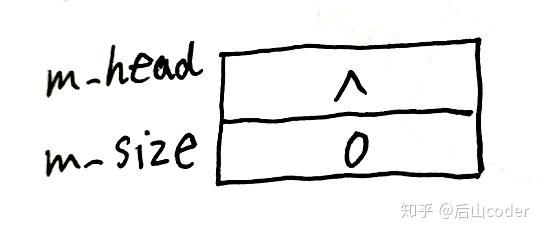
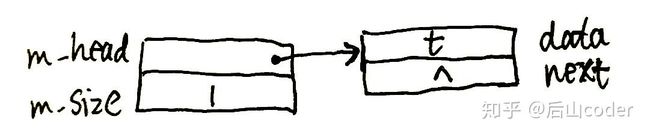
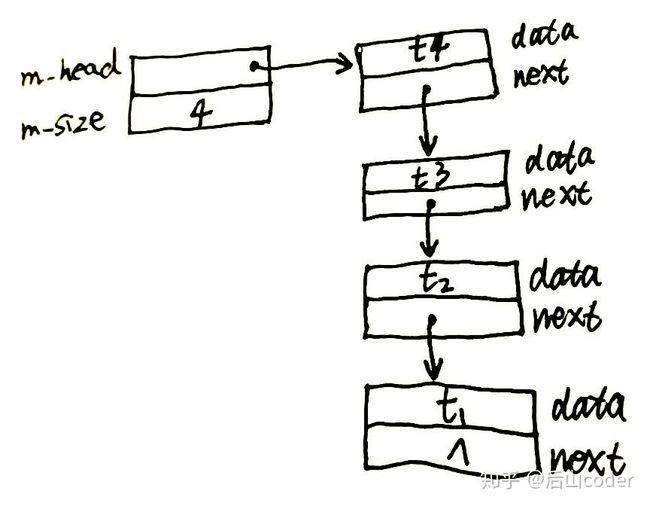
栈的内存结构
空栈:
有一个元素的栈:
多个元素的栈:
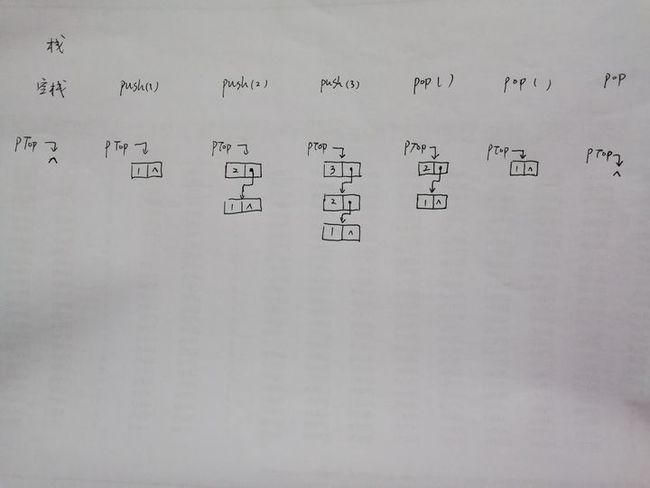
成员函数说明
0 clear 清空栈
clear 函数负责将栈的对内存释放,成员初始化为初始值,比如指针为空指针,计数成员变量赋0值。
1 copy 从另一个栈拷贝
copy 函数可以给 拷贝构造函数调用,也可以被 赋值操作调用。
由于拷贝构造函数发生在构造阶段,对象刚刚创建,不可能有内容,而赋值操作符就不一定了。
对象被赋值的时候,可能已经有元素了,所以这时候copy 内部需要先调用 clear 成员函数来清空自己管理的堆内存。让对象重新回到一个空的栈状态。
2 pop 弹出栈顶元素
pop 执行的时候,不需要检查栈是否为空。用户应该去调用 empty来检查栈是否为空。
或者用户确定调用pop的时候栈是不可能为空的,这样就避免了不必要的代码的执行。
这样做的注意目的是为了效率,类的接口各司其职,分工明确。
接口与测试用例
#include
#include
//------下面的代码是用来测试你的代码有没有问题的辅助代码,你无需关注------
#include
#include
#include
#include
#include
using namespace std;
struct Record { Record(void* ptr1, size_t count1, const char* location1, int line1, bool is) :ptr(ptr1), count(count1), line(line1), is_array(is) { int i = 0; while ((location[i] = location1[i]) && i < 100) { ++i; } }void* ptr; size_t count; char location[100] = { 0 }; int line; bool is_array = false; bool not_use_right_delete = false; }; bool operator==(const Record& lhs, const Record& rhs) { return lhs.ptr == rhs.ptr; }std::vector myAllocStatistic; void* newFunctionImpl(std::size_t sz, char const* file, int line, bool is) { void* ptr = std::malloc(sz); myAllocStatistic.push_back({ ptr,sz, file, line , is }); return ptr; }void* operator new(std::size_t sz, char const* file, int line) { return newFunctionImpl(sz, file, line, false); }void* operator new [](std::size_t sz, char const* file, int line)
{
return newFunctionImpl(sz, file, line, true);
}void operator delete(void* ptr) noexcept { Record item{ ptr, 0, "", 0, false }; auto itr = std::find(myAllocStatistic.begin(), myAllocStatistic.end(), item); if (itr != myAllocStatistic.end()) { auto ind = std::distance(myAllocStatistic.begin(), itr); myAllocStatistic[ind].ptr = nullptr; if (itr->is_array) { myAllocStatistic[ind].not_use_right_delete = true; } else { myAllocStatistic[ind].count = 0; }std::free(ptr); } }void operator delete[](void* ptr) noexcept { Record item{ ptr, 0, "", 0, true }; auto itr = std::find(myAllocStatistic.begin(), myAllocStatistic.end(), item); if (itr != myAllocStatistic.end()) { auto ind = std::distance(myAllocStatistic.begin(), itr); myAllocStatistic[ind].ptr = nullptr; if (!itr->is_array) { myAllocStatistic[ind].not_use_right_delete = true; } else { myAllocStatistic[ind].count = 0; }std::free(ptr); } }
#define new new(__FILE__, __LINE__)
struct MyStruct { void ReportMemoryLeak() { std::cout << "Memory leak report: " << std::endl; bool leak = false; for (auto& i : myAllocStatistic) { if (i.count != 0) { leak = true; std::cout << "leak count " << i.count << " Byte" << ", file " << i.location << ", line " << i.line; if (i.not_use_right_delete) { cout << ", not use right delete. "; } cout << std::endl; } }if (!leak) { cout << "No memory leak." << endl; } }~MyStruct() { ReportMemoryLeak(); } }; static MyStruct my; void check_do(bool b, int line = __LINE__) { if (b) { cout << "line:" << line << " Pass" << endl; } else { cout << "line:" << line << " Ohh! not passed!!!!!!!!!!!!!!!!!!!!!!!!!!!" << " " << endl; exit(0); } }
#define check(msg) check_do(msg, __LINE__);
//------上面的代码是用来测试你的代码有没有问题的辅助代码,你无需关注------
//2020-07-09
template
class Stack
{
public:
Stack(void);
Stack(const Stack& _stack);
Stack& operator=(const Stack& _stack);
~Stack(void);
public:
inline const T& top(void) const;
inline bool empty(void) const;
inline size_t size(void) const;
void push(const T& _item);
void pop(void);
void clear(void);
private:
void copy(const Stack& stack1);
private:
struct CStackitem
{
public:
CStackitem(void);
CStackitem(const T& _data, CStackitem* next = nullptr);
public:
CStackitem(CStackitem& _item) = delete;// = delete 表示禁止编译器生成默认版本的函数,主要用来禁止该类型对象拷贝
CStackitem& operator=(CStackitem& _item) = delete;
public:
CStackitem* next = nullptr;//这里的初始化会在所有构造函数执行之前先执行,所以构造函数里就不用再对该成员初始化了
T data;
};
private:
CStackitem m_head;//注意这里不是指针类型
size_t m_size = 0;
};
template
Stack::CStackitem::CStackitem(void)
//(1) your code 对1个成员变量初始化
{
}
template
Stack::CStackitem::CStackitem(const T& _data, CStackitem* _next)
:data(_data), next(_next)
{
}
template
Stack::Stack(void)
//(3) your code 对1个成员变量初始化
{
}
template
Stack::Stack(const Stack& _stack)
{
//(4) your code 使用 copy 即可
}
template
Stack& Stack::operator=(const Stack& _stack)
{
//(5) your code 记得判断同一个对象赋值给自己
return *this;
}
template
Stack::~Stack(void)
{
clear();
}
template
bool Stack::empty(void) const
{
return m_size == 0;
}
template
void Stack::pop(void)
{
//(9) your code 注意对象获取成员用"."操作符,指针获取成员用"->"操作符
}
template
void Stack::clear(void)
{
//(6) your code 可以利用 pop 来实现
}
template
void Stack::copy(const Stack& from)
{
//(7) your code 请先使用 clear ,再遍历链表来实现
}
template
size_t Stack::size(void) const
{
return m_size;
}
template
void Stack::push(const T& item)
{
//(8) your code, 注意 这样写新创建的节点 CStackitem* p = new CStackitem(item, first);
}
template
const T& Stack::top(void) const
{
return m_head.next->data;
}
int main(int argc, char** argv)
{
Stack stack1;
check(stack1.size() == 0);
stack1.push(1);
check(stack1.size() == 1);
auto stack2 = stack1;
auto top = stack2.top();
check(top == 1);
check(stack2.size() == 1);
stack1 = stack2;// 1 and 1
stack1.push(2);// 2 1
top = stack2.top();
check(top == 1);
check(stack1.size() == 2);
check(stack1.top() == 2);
stack1.clear();
check(stack1.size() == 0 && stack1.empty());
for (size_t i = 0; i < 10; i++)
{
stack1.push(i);
}
while (!stack1.empty())
{
std::cout << stack1.top() << " ";
stack1.pop();
}
cout << endl;
check(stack1.size() == 0 && stack1.empty());
//copy constructor
{
Stack from;
from.push(1);
from.push(2);
Stack to(from);
check(to.size() == 2);
check(to.top() == 2);
to.pop();
check(to.top() == 1);
to.pop();
check(to.empty());
}
}
输出:
line:155 Pass
line:157 Pass
line:160 Pass
line:161 Pass
line:165 Pass
line:166 Pass
line:167 Pass
line:169 Pass
9 8 7 6 5 4 3 2 1 0
line:180 Pass
line:188 Pass
line:189 Pass
line:191 Pass
line:193 Pass
Memory leak report:
No memory leak.还没完!
现在我们来思考一个更具价值的问题:栈有必要重新实现一次吗?答案是否定的。
回忆我们之前的工作,我们实现了动态数组vector和链表list,这两个容器都支持在末尾增加和删除元素。
这正是栈的功能。
也就是说我们其实已经实现过栈了。
我们可以直接把动态数组和链表替换任何需要栈的地方,只不过类型的名字还不叫栈而异。
那么我们该怎么做才比较好呢?
那就是利用已经实现的容器包装出另一个容器。具体做法就是,假如我们打算用链表来实现栈(当然用数组实现也是类似的)。
可以把一个链表对象作为栈的成员变量。
对栈的操作都通过栈的成员函数转发给这个链表来做。
这种做法的好处:
(1)稳定!稳定!稳定!
因为链表的实现中有大量的细节,很容易出错。如果我们也在链表中再来一遍的话,指不定又会写出bug来。这在正式开发环境中代价是极其高昂的。没有客户愿意接受一个经常喜欢出洋相的产品。
让测试人员从头开始测试一遍产品他们的工作量几乎要翻倍。这会极大的资源浪费。竞争对手可能已经跑在了前面。
原来对链表的测试用例已经把链表的稳定性保证了,所以现在的不确定性只是在栈对链表的包装上。
由于包装的代码就是接口转发,只要类型写对,接口名别调用错了就可以了,所以出问题的概率极大的降低了。
这种以基础容器制造其他容器的做法在软件开发中叫模块化封装。
链表是一个模块,栈的是一个模块。用链表封装出了一个栈。
(2)减少开发工作量
由于使用了现成的代码,所以有些底层的代码直接拿来用,这就节省了工作量。提高了开发效率。
祝你好运!
答案在此
链式栈StackT(答案)_C++开发者的博客-CSDN博客