MyDLNote-Enhancement:[2020CVPR] Zero-Reference Deep Curve Estimation for Low-Light Image Enhancement
Zero-Reference Deep Curve Estimation for Low-Light Image Enhancement

[paper] : https://arxiv.org/pdf/2001.06826.pdf
[project (github)] : https://li-chongyi.github.io/Proj_Zero-DCE.html
补充文件可以从 project 中下载到。
本文的亮点:
为了实现无参考训练,将弱光增强问题转换为曲线变换问题(比伽玛变换更自适应、更有效的变换)。这个曲线被称为 light-enhancement curve:LE-curve。
那没有参考,怎么训练呢?这归功于本文提出的损失函数,这是本文的关键。
另一篇无监督方法:EnlightenGAN: Deep Light Enhancement without Paired Supervision
个人疑点:
该方法避开了对于噪声和颜色失真的讨论。
Abstract
The paper presents a novel method, Zero-Reference Deep Curve Estimation (Zero-DCE), which formulates light enhancement as a task of image-specific curve estimation with a deep network.
本文的研究对象(light enhancement)和角度(将亮度增强作为一个利用深度网络进行图像曲线估计的任务)。
Our method trains a lightweight deep network, DCE-Net, to estimate pixel-wise and high-order curves for dynamic range adjustment of a given image. The curve estimation is specially designed, considering pixel value range, monotonicity, and differentiability. Zero-DCE is appealing in its relaxed assumption on reference images, i.e., it does not require any paired or unpaired data during training. This is achieved through a set of carefully formulated non-reference loss functions, which implicitly measure the enhancement quality and drive the learning of the network.
本文提出的 DCE-Net 的一些特性:
1. 轻量级深度网络 DCE-Net,用来估计像素和高阶曲线,以便对给定图像进行动态范围调整。
2. 特别设计了曲线估计,该模型考虑了像素值的范围、单调性和可微性。
3. Zero-DCE 吸引人的地方在于它训练时不需要任何配对或未配对的数据。这是通过一组非参考损失函数来实现的。
Our method is efficient as image enhancement can be achieved by an intuitive and simple nonlinear curve mapping. Despite its simplicity, we show that it generalizes well to diverse lighting conditions. Extensive experiments on various benchmarks demonstrate the advantages of our method over state-of-the-art methods qualitatively and quantitatively. Furthermore, the potential benefits of our Zero-DCE to face detection in the dark are discussed.
本文方法是效果说明。
Introduction
Many photos are often captured under suboptimal lighting conditions due to inevitable environmental and/or technical constraints. These include inadequate and unbalanced lighting conditions in the environment, incorrect placement of objects against extreme back light, and under-exposure during image capturing. Such low-light photos suffer from compromised aesthetic quality and unsatisfactory transmission of information. The former affects viewers’ experience while the latter leads to wrong message being communicated, such as inaccurate object/face recognition.
研究对象(low-light imaging)简单介绍。
In this study, we present a novel deep learning-based method, Zero-Reference Deep Curve Estimation (ZeroDCE), for low-light image enhancement. It can cope with diverse lighting conditions including nonuniform and poor lighting cases. Instead of performing image-to-image mapping, we reformulate the task as an image-specific curve estimation problem. In particular, the proposed method takes a low-light image as input and produces high-order curves as its output. These curves are then used for pixel-wise adjustment on the dynamic range of the input to obtain an enhanced image. The curve estimation is carefully formulated so that it maintains the range of the enhanced image and preserves the contrast of neighboring pixels. Importantly, it is differentiable, and thus we can learn the adjustable parameters of the curves through a deep convolutional neural network. The proposed network is lightweight and it can be iteratively applied to approximate higher-order curves for more robust and accurate dynamic range adjustment.
方法的特点:
1. 核心思想:将弱光增强任务重新表示为一个特定于图像的曲线估计问题;
2. 输入输出:以一个弱光图像作为输入,并产生高阶曲线作为输出;
3. 像素级调整;
4. 保持增强图像的范围并保持对比度;
5. 可微的,能通过深度卷积神经网络学习,曲线参数是可调的;
6. 轻量级;鲁棒性高;精确动态范围调整。
A unique advantage of our deep learning-based method is zero-reference, i.e., it does not require any paired or even unpaired data in the training process as in existing CNN-based [28,32] and GAN-based methods [12,38]. This is made possible through a set of specially designed non-reference loss functions including spatial consistency loss, exposure control loss, color constancy loss, and illumination smoothness loss, all of which take into consideration multi-factor of light enhancement. We show that even with zero-reference training, Zero-DCE can still perform competitively against other methods that require paired or unpaired data for training. An example of enhancing a lowlight image comprising nonuniform illumination is shown in Fig. 1. Comparing to state-of-the-art methods, Zero-DCE brightens up the image while preserving the inherent color and details. In contrast, both CNN-based method [28] and GAN-based EnlightenGAN [12] yield under-(the face) and over-(the cabinet) enhancement.
Figure 1: Visual comparisons on a typical low-light image. The proposed Zero-DCE achieves visually pleasing result in terms of brightness, color, contrast, and naturalness, while existing methods either fail to cope with the extreme back light or generate color artifacts. In contrast to other deep learning-based methods, our approach is trained without any reference image.
![MyDLNote-Enhancement:[2020CVPR] Zero-Reference Deep Curve Estimation for Low-Light Image Enhancement_第1张图片](http://img.e-com-net.com/image/info8/7ce949cb18a943ffb580f6e2db45b824.jpg)
本文方法最核心的特点:无参考训练。
通过一套特别设计的非参考损失功能实现的,包括空间一致性损失、曝光控制损失、色彩稳定性损失和照明平滑损失,所有这些都考虑到光增强的多因素。
然而,读完上述内容,我个人的疑惑是:为什么没有提及去噪和颜色失真的问题?这两个问题,好像并不能通过像素级的非线性变换得到解决吧?即使可以,又是什么原理?
Our contributions are summarized as follows.
1) We propose the first low-light enhancement network that is independent of paired and unpaired training data, thus avoiding the risk of overfitting. As a result, our method generalizes well to various lighting conditions.
2) We design an image-specific curve that is able to approximate pixel-wise and higher-order curves by iteratively applying itself. Such image-specific curve can effectively perform mapping within a wide dynamic range.
3) We show the potential of training a deep image enhancement model in the absence of reference images through task-specific non-reference loss functions that indirectly evaluate enhancement quality.
本文的贡献:
1) 提出了第一个不依赖于配对和非配对训练数据的弱光增强网络,避免了过拟合的风险。因此,本文的方法可以很好地适用于各种照明条件。
2) 设计了一种特定于图像的曲线,它可以通过自我迭代逼近像素和高阶曲线。这种 image-specific 曲线可以有效地在较宽的动态范围内进行 mapping。
3) 展示了在没有参考图像的情况下,通过非参考损失函数来间接评估增强质量,在没有参考图像的情况下训练深度图像增强模。
Our Zero-DCE method supersedes state-of-the-art performance both in qualitative and quantitative metrics. More importantly, it is capable of improving high-level visual tasks, e.g., face detection, without inflicting high computational burden. It is capable of processing images in realtime (about 500 FPS for images of size 640×480×3 on GPU) and takes only 30 minutes for training.
训练只需要 30 分钟!
Methodology
We present the framework of Zero-DCE in Fig. 2. A Deep Curve Estimation Network (DCE-Net) is devised to estimate a set of best-fitting Light-Enhancement curves (LE-curves) given an input image. The framework then maps all pixels of the input’s RGB channels by applying the curves iteratively for obtaining the final enhanced image. We next detail the key components in Zero-DCE, namely LE-curve, DCE-Net, and non-reference loss functions in the following sections.
Figure 2: (a) The framework of Zero-DCE. A DCE-Net is devised to estimate a set of best-fitting Light-Enhancement curves (LE-curves) that iteratively enhance a given input image.
![MyDLNote-Enhancement:[2020CVPR] Zero-Reference Deep Curve Estimation for Low-Light Image Enhancement_第2张图片](http://img.e-com-net.com/image/info8/eaaeee177a5046288b86426572fc23b1.jpg)
设计了深度曲线估计网络 (DCE-Net),用于估计给定输入图像的一组最佳拟合光增强曲线 (LE-curves)。然后,通过迭代的曲线变换,调整输入图像的每一个像素,直到获得最终的输出。接下来,将详细介绍 Zero-DCE 中的关键组件,即 光增强曲线 LE-curve、DCE-Net 和 非参考损失函数。
Light-Enhancement Curve (LE-curve)
Inspired by the curves adjustment used in photo editing software, we attempt to design a kind of curve that can map a low-light image to its enhanced version automatically, where the self-adaptive curve parameters are solely dependent on the input image. There are three objectives in the design of such a curve: 1) each pixel value of the enhanced image should be in the normalized range of [0,1] to avoid information loss induced by overflow truncation; 2) this curve should be monotonous to preserve the differences (contrast) of neighboring pixels; and 3) the form of this curve should be as simple as possible and differentiable in the process of gradient backpropagation.
设计的 LE-curve (自适地调整曲线参数,并完全依赖于输入图像)应当具备如下几个关键:
1. 归一化在 [0, 1] 范围内;避免因溢出截断引起的信息损失;
2. 曲线应是单调递增的,保持信息的梯度/对比度;
3. 曲线简单,可微分,可训练的。
To achieve these three objectives, we design a quadratic curve, which can be expressed as:
,
where
denotes pixel coordinates,
is the enhanced version of the given input
,
is the trainable curve parameter, which adjusts the magnitude of LE-curve and also controls the exposure level. Each pixel is normalized to
and all operations are pixel-wise. We separately apply the LE-curve to three RGB channels instead of solely on the illumination channel. The three-channel adjustment can better preserve the inherent color and reduce the risk of over-saturation. We report more details in the supplementary material.
根据前面分析,构建的 LE-curve 是一个二次曲线,定义为 ![]() 。
。
将 LE-curve 分别应用于三个RGB通道,而不是仅仅应用于亮度(illumination )通道。在三个彩色通道调整可以更好地保留固有色彩,减少过饱和度的风险。
- Higher-Order Curve.
The LE-curve defined in Eq. (1) can be applied iteratively to enable more versatile adjustment to cope with challenging low-light conditions. Specifically,
where
is the number of iteration, which controls the curvature. In this paper, we set the value of
and
二阶不够,通过迭代,实现高阶曲线。作者认为由于曲率更高,因此调节能力更强。迭代次数设置为 8。
- Pixel-Wise Curve.
A higher-order curve can adjust an image within a wider dynamic range. Nonetheless, it is still a global adjustment since
where
is a parameter map with the same size as the given image. Here, we assume that pixels in a local region have the same intensity (also the same adjustment curves), and thus the neighboring pixels in the output result still preserve the monotonous relations. In this way, the pixel-wise higher-order curves also comply with three objectives.
高阶曲线还是不够的,因为它依然是对全部图像使用统一的 。
因此, 也应该是每个像素不同的。因此,将公式中的 换成矩阵 。
这里假设局部区域的像素强度相同 (因此调整曲线相同),这样输出结果中的相邻像素仍然保持单调的关系。这样,像素方向的高阶曲线也符合前面提及的三个关键。
到此,曲线就介绍完了。那么,这个曲线参数是如何通过网络训练实现优化的呢?
DCE-Net
To learn the mapping between an input image and its best-fitting curve parameter maps, we propose a Deep Curve Estimation Network (DCE-Net). The input to the DCE-Net is a low-light image while the outputs are a set of pixel-wise curve parameter maps for corresponding higherorder curves. We employ a plain CNN of seven convolutional layers with symmetrical concatenation. Each layer consists of 32 convolutional kernels of size 3×3 and stride 1 followed by the ReLU activation function. We discard the down-sampling and batch normalization layers that break the relations of neighboring pixels. The last convolutional layer is followed by the Tanh activation function, which produces 24 parameter maps for 8 iterations (n = 8), where each iteration requires three curve parameter maps for the three channels. The detailed architecture of DCE-Net is provided in the supplementary material. It is noteworthy that DCE-Net only has 79,416 trainable parameters and 5.21G Flops for an input image of size 256×256×3. It is therefore lightweight and can be used in computational resource-limited devices, such as mobile platforms.
The architecture of Deep Curve Estimation Network (DCE-Net).
![MyDLNote-Enhancement:[2020CVPR] Zero-Reference Deep Curve Estimation for Low-Light Image Enhancement_第3张图片](http://img.e-com-net.com/image/info8/2c52d2d6f38746ebaa80c5a854a483b2.jpg)
网络结构:
backbone:conv-ReLU 重复 6 次 + conv-Than,而且注意到,是对称级联的,即第 1/2/3 层输出和第 6/5/4 层输出进行通道级联(concatenation);
conv:32 个通道, 3×3 ,stride 1;
输出:R/G/B 三个通道 8 次迭代的 值,因此是 24 个通道。
可见,输入的图像,要用 LE-curve 依次操作 8 次。
Non-Reference Loss Functions
个人认为,损失函数的设计才是本文的重中之重。
To enable zero-reference learning in DCE-Net, we propose a set of differentiable non-reference losses that allow us to evaluate the quality of enhanced images. The following four types of losses are adopted to train our DCE-Net.
- Spatial Consistency Loss.
The spatial consistency loss
encourages spatial coherence of the enhanced image through preserving the difference of neighboring regions between the input image and its enhanced version:
where
is the number of local region, and
is the four neighboring regions (top, down, left, right) centered at the region
. We denote
and
as the average intensity value of the local region in the enhanced version and input image, respectively. We empirically set the size of the local region to 4×4. This loss is stable given other region sizes.
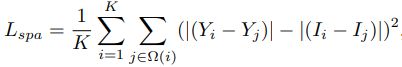
空间一致性损失:通过保持输入图像与增强图像相邻区域的梯度来促进增强图像的空间一致性。
具体地,计算输入图像和增强图像在通道维度的平均值(将R、G、B三通道加起来求平均);将得到的两个灰度图像分解为若干 4×4 patches(不重复,覆盖全图);然后计算 patch 内中心位置 i 与每个其它位置 j 的像素差值,求平均。
- Exposure Control Loss.
To restrain under-/over-exposed regions, we design an exposure control loss
to control the exposure level. The exposure control loss measures the distance between the average intensity value of a local region to the well-exposedness level
. We follow existing practices [23,24] to set
where
represents the number of nonoverlapping local regions of size 16×16,
曝光控制损失:测量的是局部区域的平均强度值与良好曝光水平(![]() ,经验设置)之间的距离。
,经验设置)之间的距离。
具体地,将增强图像转为灰度图,然后分解为若干 4×4 patches(不重复,覆盖全图);然后计算 patch 内的平均值。
- Color Constancy Loss.
Following Gray-World color constancy hypothesis [2] that color in each sensor channel averages to gray over the entire image, we design a color constancy loss to correct the potential color deviations in the enhanced image and also build the relations among the three adjusted channels. The color constancy loss
can be expressed as:
where
denotes the average intensity value of
channel in the enhanced image,
represents a pair of channels.
色彩恒常性损失:纠正增强图像中可能出现的色彩偏差,并建立三个调整通道之间的关系。
没有很理解原文的这句话 “color in each sensor channel averages to gray over the entire image”是什么意思。
但根据公式大概可以理解为,灰世界颜色恒常性假设,R、G、B 通道的全局平均值与整个彩色图像的全局平均值相近。因此,三个通道的平均值,两两相减应该很小。
- Illumination Smoothness Loss.
To preserve the monotonicity relations between neighboring pixels, we add an illumination smoothness loss to each curve parameter map
is defined as:
where
is the number of iteration,
and
represent the horizontal and vertical gradient operations, respectively.

光照平滑损失:保持相邻像素间的单调关系,在每条曲线参数图 上都要添加。(公式写错了吧,第二项)
具体地,所有通道、所有迭代次数的 (也就是网络的输出),其横竖的梯度平均值应该很小。
- Total Loss.
The total loss can be expressed as:
where
and
are the weights of the losses
Experiments
Ablation Study
- Contribution of Each Loss.
看下结果。
![MyDLNote-Enhancement:[2020CVPR] Zero-Reference Deep Curve Estimation for Low-Light Image Enhancement_第4张图片](http://img.e-com-net.com/image/info8/4e34998c7f2240cc9c400074411107cf.jpg)
- Effect of Parameter Settings.
三个数字分别表示网络的卷积层数、每层卷积的通道数、迭代次数。The Zero-DCE7−32−8 and ZeroDCE7−32−16 produce most visually pleasing results with natural exposure and proper contrast. (e)和(f)的效果比较好。
![MyDLNote-Enhancement:[2020CVPR] Zero-Reference Deep Curve Estimation for Low-Light Image Enhancement_第5张图片](http://img.e-com-net.com/image/info8/ac03ec553d794cdeb5cd2fb339477572.jpg)
- Impact of Training Data.
To test the impact of training data, we retrain the Zero-DCE on different datasets:
1)Zero-DCE: 360 multi-exposure sequences from the Part1 of SICE dataset [4] (To bring the capability of wide dynamic range adjustment into full play, we incorporate both low-light and over-exposed images into our training set.);
2)Zero-DCELow:only 900 low-light images out of 2,422 images in the original training set;
3)ZeroDCELargeL:9,000 unlabeled low-light images provided in the DARK FACE dataset [37];
4)Zero-DCELargeLH:4800 multi-exposure images from the data augmented combination of Part1 and Part2 subsets in the SICE dataset [4].
![MyDLNote-Enhancement:[2020CVPR] Zero-Reference Deep Curve Estimation for Low-Light Image Enhancement_第6张图片](http://img.e-com-net.com/image/info8/766c738d2cce4dfe9bb99058e9da0d2d.jpg)
重要结论:
训练数据集中,需要包含过曝光图像(over-exposure),这是因为,为了充分发挥宽动态范围调整的能力,将低光和过度曝光的图像都纳入到训练集。
但是,太多的过度曝光图像参与训练,也不是好事,例如 Zero-DCELargeLH 的效果没有 Zero-DCE 好。