《开发实战》12 | 异常处理:别让自己在出问题的时候变为瞎子
12 | 异常处理:别让自己在出问题的时候变为瞎子
捕获和处理异常容易犯的错
“统一异常处理”方式正是我要说的第一个错:不在业务代码层面考虑异常处理,仅在框架层面粗犷捕获和处理异常。
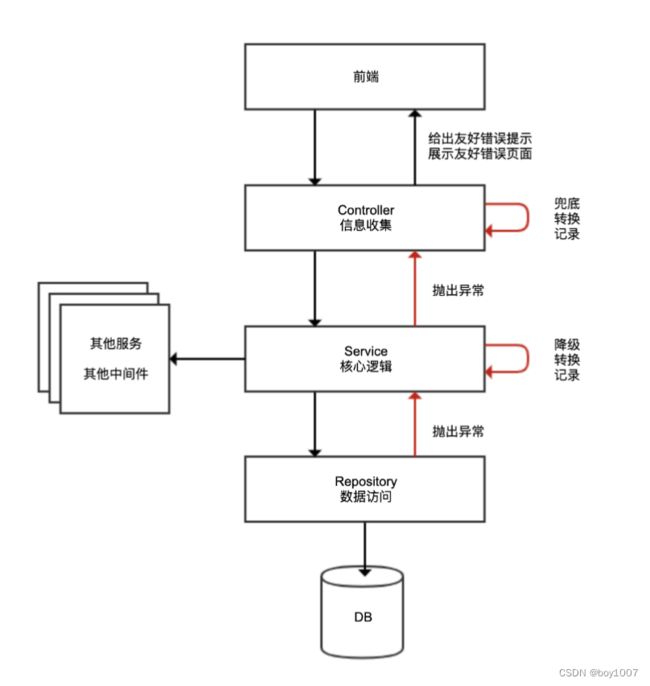
为了理解错在何处,先看看大多数业务应用都采用的三层架构:
- Controller 层负责信息收集、参数校验、转换服务层处理的数据适配前端,轻业务逻辑;
- Service 层负责核心业务逻辑,包括各种外部服务调用、访问数据库、缓存处理、消息处理等;
- Repository 层负责数据访问实现,一般没有业务逻辑。
@RestControllerAdvice
@Slf4j
public class RestControllerExceptionHandler {
private static int GENERIC_SERVER_ERROR_CODE = 2000;
private static String GENERIC_SERVER_ERROR_MESSAGE = "服务器忙,请稍后再试";
@ExceptionHandler
public APIResponse handle(HttpServletRequest req, HandlerMethod method, Exception BusinessException){
if (ex instanceof BusinessException) {
BusinessException exception = (BusinessException) ex;
log.warn(String.format("访问 %s -> %s 出现业务异常!", req.getRequestU));
return new APIResponse(false, null, exception.getCode(), exception);
} else {
log.error(String.format("访问 %s -> %s 出现系统异常!", req.getRequest
return new APIResponse(false, null, GENERIC_SERVER_ERROR_CODE, GENE
}
}
}
出现运行时系统异常后,异常处理程序会直接把异常转换为 JSON 返回给调用方
捕获了异常后直接生吞。在任何时候,我们捕获了异常都不应该生吞,也就是直接丢弃异常不记录、不抛出
丢弃异常的原始信息。我们来看两个不太合适的异常处理方式,虽然没有完全生吞异常,但也丢失了宝贵的异常信息。
抛异常
只记录了异常消息,却丢失了异常的类型、栈等重要信息:
catch (IOException e) {
//原始异常信息丢失
throw new RuntimeException("系统忙请稍后再试");
}
只知道文件读取错误的文件名,至于为什么读取错误、是不存在还是没权限,完全不知道。
catch (IOException e) {
//只保留了异常消息,栈没有记录
log.error("文件读取错误, {}", e.getMessage());
throw new RuntimeException("系统忙请稍后再试");
}
抛出异常时不指定任何消息
throw new RuntimeException();
应该这样抛:
catch (IOException e) {
log.error("文件读取错误", e);
throw new RuntimeException("系统忙请稍后再试");
}
或者,把原始异常作为转换后新异常的 cause,原始异常信息同样不会丢:
catch (IOException e) {
throw new RuntimeException("系统忙请稍后再试", e);
}
除了通过日志正确记录异常原始信息外,通常还有三种处理模式:
转换,即转换新的异常抛出。对于新抛出的异常,最好具有特定的分类和明确的异常消息,而不是随便抛一个无关或没有任何信息的异常,并最好通过 cause 关联老异常。
重试,即重试之前的操作。比如远程调用服务端过载超时的情况,盲目重试会让问题更严重,需要考虑当前情况是否适合重试。
恢复,即尝试进行降级处理,或使用默认值来替代原始数据。
小心 finally 中的异常
finally也会抛异常
@GetMapping("wrong")
public void wrong() {
try {
log.info("try");
//异常丢失
throw new RuntimeException("try");
} finally {
log.info("finally");
throw new RuntimeException("finally");
}
}
最后在日志中只能看到 finally 中的异常,虽然 try 中的逻辑出现了异常,但却被 finally中的异常覆盖了
因为一个方法无法出现两个异常。
修复方式:finally 代码块自己负责异常捕获和处理,或者可以把 try 中的异常作为主异常抛出,使用ddSuppressed 方法把 finally 中的异常附加到主异常上.
最好还是使用try-with-resources 语句的做法。对于实现了 AutoCloseable 接口的资源,建议使用 try-with-resources 来释放资源,否则也可能会产生刚才提到的,释放资源时出现的异常覆盖主异常的问题。比如如下我们定义一个测试资源,其 read 和 close 方法都会抛出异常:
public class TestResource implements AutoCloseable {
public void read() throws Exception{
throw new Exception("read error");
}
@Override
public void close() throws Exception {
throw new Exception("close error");
}
}
@GetMapping("useresourcewrong")
public void useresourcewrong() throws Exception {
TestResource testResource = new TestResource();
try {
testResource.read();
} finally {
testResource.close();
}
}
而改为 try-with-resources 模式之后:
@GetMapping("useresourceright")
public void useresourceright() throws Exception {
try (TestResource testResource = new TestResource()){
testResource.read();
}
}
千万别把异常定义为静态变量
public class Exceptions {
public static BusinessException ORDEREXISTS = new BusinessException("订单已经存在");
...
}
@GetMapping("wrong")
public void wrong() {
try {
createOrderWrong();
} catch (Exception ex) {
log.error("createOrder got error", ex);
}
try {
cancelOrderWrong();
} catch (Exception ex) {
log.error("cancelOrder got error", ex);
}
}
private void createOrderWrong() {
//这里有问题
throw Exceptions.ORDEREXISTS;
}
private void cancelOrderWrong() {
//这里有问题
throw Exceptions.ORDEREXISTS;
}
cancelOrder got error 的提示对应了 createOrderWrong 方法。显然,cancelOrderWrong 方法在出错后抛出的异常,其实是 createOrderWrong 方法出错的异常
修复方式
public class Exceptions {
public static BusinessException orderExists(){
return new BusinessException("订单已经存在", 3001);
}
}
提交线程池的任务出了异常会怎么样?
提交 10 个任务到线程池异步处理,第 5 个任务抛出一个RuntimeException,每个任务完成后都会输出一行日志:
@GetMapping("execute")
public void execute() throws InterruptedException {
String prefix = "test";
ExecutorService threadPool = Executors.newFixedThreadPool(1, new ThreadFactoryBuilder().setNameFormat(prefix+"%d").get());
//提交10个任务到线程池处理,第5个任务会抛出运行时异常
IntStream.rangeClosed(1, 10).forEach(i -> threadPool.execute(() -> {
if (i == 5) throw new RuntimeException("error");
log.info("I'm done : {}", i);
}));
threadPool.shutdown();
threadPool.awaitTermination(1, TimeUnit.HOURS);
}
观察日志发现:任务 1 到 4 所在的线程是 test0,任务 6 开始运行在线程 test1。因此从线程名的改变可以知
道因为异常的抛出老线程退出了,线程池只能重新创建一个线程。如果每个异步任务都以异常结束,那么线程池可能完全起不到线程重用的作用。
因为没有手动捕获异常进行处理,ThreadGroup 帮我们进行了未捕获异常的默认处理,向标准错误输出打印了出现异常的线程名称和异常信息。显然,这种没有以统一的错误日志格式记录错误信息打印出来的形式,对生产级代码是不合适的,
修复方式有 种:
- 以 execute 方法提交到线程池的异步任务,最好在任务内部做好异常处理;设置自定义的异常处理程序作为保底,比如在声明线程池时自定义线程池的未捕获异常处理程序:
new ThreadFactoryBuilder()
.setNameFormat(prefix+"%d")
.setUncaughtExceptionHandler((thread, throwable)-> log.error("ThreadPool {} got exception", thread, throwable))
.get()
- 设置全局的默认未捕获异常处理程序:
static {
Thread.setDefaultUncaughtExceptionHandler((thread, throwable)->
log.error("Thread {} got exception", thread, throwable));
}
把 execute 方法改为 submit,修改代码后重新执行程序可以看到如下日志,说明线程没退出,异常也没记录被生吞了.
查看 FutureTask 源码可以发现,在执行任务出现异常之后,异常存到了一个 outcome 字段中,只有在调用 get 方法获取 FutureTask 结果的时候,才会以 ExecutionException 的形式重新抛出异常:
修改后的代码如下所示,我们把 submit 返回的 Future 放到了 List 中,随后遍历 List 来捕获所有任务的异常。这么做确实合乎情理。既然是以 submit 方式来提交任务,那么我们应该关心任务的执行结果,否则应该以 xecute 来提交任务:
List tasks = IntStream.rangeClosed(1, 10).mapToObj(i -> threadPool.submit(() -> {
if (i == 5) throw new RuntimeException("error");
log.info("I'm done : {}", i);
})).collect(Collectors.toList());
tasks.forEach(task-> {
try {
task.get();
} catch (Exception e) {
log.error("Got exception", e);
}
});
确保正确处理了线程池中任务的异常,如果任务通过 execute 提交,那么出现异常会导致线程退出,大量的异常会导致线程重复创建引起性能问题,我们应该尽可能确保任务不出异常,同时设置默认的未捕获异常处理程序来兜底;