Paperreading:ChatGPT is not all you need. A State of the Art Review of large Generative AI models
ChatGPT is not all you need. A State of the Art Review of large Generative AI models 最先进的大型AI生成模型综述
原文链接
Abstract
在过去两年中,已经发布了大量大型生成模型,例如 ChatGPT 或 Stable Diffusion。具体而言,这些模型能够执行诸如通用问答系统或自动创建艺术图像等任务,这些任务正在彻底改变多个领域。因此,这些生成模型对行业和社会的影响是巨大的,因为一些工作岗位可能会发生转变。例如,Generative AI 能够有效且创造性地将文本转换为图像,如 DALLE-2 模型;文本到 3D 图像,如 Dreamfusion 模型;图像到文本,如 Flamingo 模型;文本到视频,如 Phenaki 模型;文本到音频,如 AudioLM 模型;文本到其他文本,如 ChatGPT;文本编码,如 Codex 模型;文本到科学文本,如卡拉狄加模型,甚至创建算法如 AlphaTensor。这项工作包括试图以简洁的方式描述主要模型是受生成 AI 影响的部门,并提供最近发布的主要生成模型的分类。
1.Introduction
生成式 AI 是指可以生成新颖内容的人工智能,而不是像专家系统那样简单地分析或作用于现有数据 。特别是,专家系统包含知识库和推理引擎,推理引擎通过 if-else 规则数据库生成内容。然而,现代生成人工智能包含在语料库或数据集上训练的鉴别器或变换器模型,能够将输入信息映射到潜在的高维空间和生成器模型,能够生成随机行为,在每个新内容中创建新内容甚至根据与输入相同的提示进行试验,根据特定的方法执行无监督、半监督或监督学习。关于模型创建的内容,生成式人工智能模型不同于预测性机器学习系统,后者仅执行判别行为,解决分类或回归问题。特别是,这些模型能够区分信息并生成转换后的输入信息或提示的信息。
生成模型的关键方面是它们的架构和输入的数据是巨大的。例如,现在可以通过向模型提供整个维基百科、Github、社交网络、谷歌图片等内容来估计模型的参数。尽管有大量数据,但由于计算的兴起,我们可以设计深度神经网络 、transformers 和其他模型,例如生成对抗网络 (generative adversarial networks)或变分自动编码器(variational autoencoders) ,其容量为能够对数据的复杂性进行建模,而不会出现欠拟合。由于它们能够对具体或一般领域的语言或照片的高维概率分布进行建模,如果它们得到生成模型的补充,这些生成模型将照片语言的潜在高维语义空间映射到文本的多媒体表示,音频或视频我们可以将任何输入格式(如文本)映射到任何输出格式(如视频)。从这个意义上说,这项技术的应用是无穷无尽的,因为我们可以训练一个模型从不同的多媒体输入格式(例如文本)生成真正不同的多媒体格式,如视频、音频或文本。
我们认为有必要对最流行的生成式 AI 模型进行最先进的审查,因为它们正在彻底改变艺术行业或大学等多个行业。由于模型现在能够生成真正的艺术内容或大文本来回答提示,这两个行业以及我们将在本手稿中详细介绍的其他行业将需要重新调整他们的活动以继续提供价值。从这个意义上说,生成式人工智能模型不会取代人类,而是会增强我们的内容,成为艺术家的灵感来源或改进教授生成的内容为了向可以从这些模型中受益的任何行业的专业人士提供信息,我们将本文的组织结构如下所示。首先,我们将提供行业中出现的主要生成模型的分类。然后,以下部分将分析分类法的每个类别。最后,我们用结论和进一步的工作部分来完成手稿。我们不会详细研究每个模型的技术方面,例如transformers,因为我们在本次审查中的目的是研究模型的应用和它们生成的内容,而不是研究它们的工作原理。对于深度学习模型和生成模型的详细解释,我们推荐其他参考文献 。
2.A Taxonomy of Generative AI models AI生成模型的分类

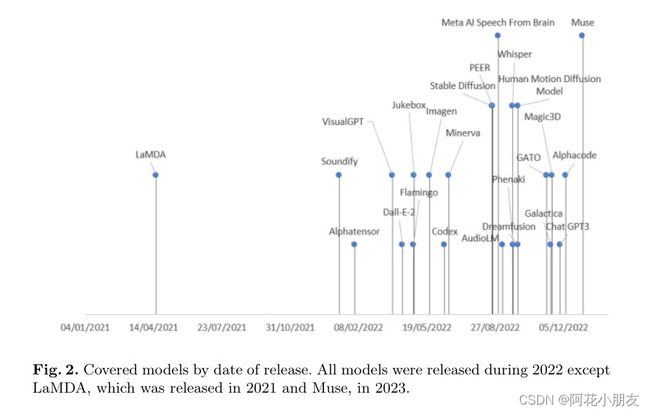
在详细分析每个模型之前,我们尝试将当前的生成人工模型组织成一个分类法,其类别代表每种多媒体输入和输出数据类型之间的主要映射。结果就是我们在图 1 中说明的那个。我们总共发现了 9 个类别,其中每个出现在图 1 中的模型将在下一节中详细描述。正如我们在图 2 中所示,每个涵盖的模型最近都已发布,因为我们在本手稿中的主要关注点是描述生成 AI 模型的最新进展。
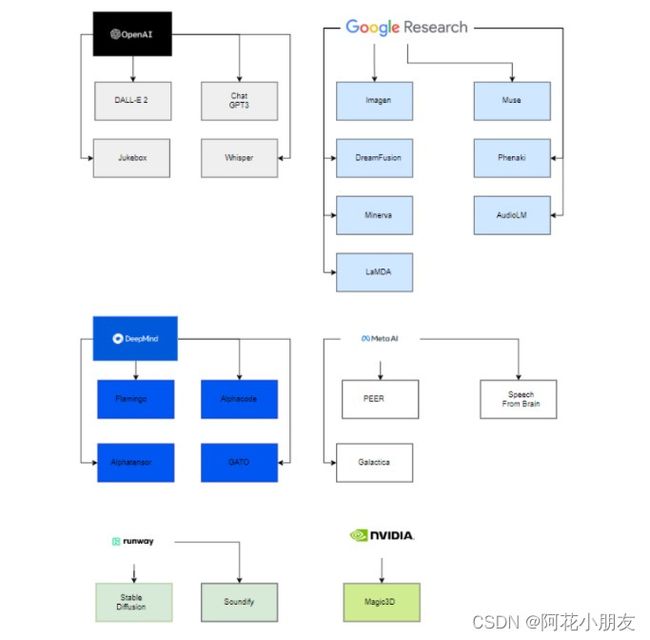
有趣的是,只有六个组织支持部署这些模型,如图 3 所示。这一事实背后的主要原因是为了为了能够估计这些模型的参数,必须拥有强大的计算能力和一支技术精湛、经验丰富的数据科学和数据工程团队。因此,只有图 3 所示的公司,在收购的初创公司的帮助下以及与学术界的合作,才能够成功部署生成式人工智能模型.
现在我们已经提供并分析了最新的生成式人工智能模型,接下来的部分将详细介绍图 1 中呈现的分类法的每个类别。
3.Generative AI models categories 生成式ai模型的类别
在本节中,我们将详细介绍上一节图 1 中描述的九个类别。对于每个类别,我们都说明了图 1 中所示模型的详细信息。
3.1 Text-to-image models
DALL·E 2: DALL·E 2 由 OpenAI 创建,能够根据包含文本描述的提示生成原始、真实和逼真的图像和艺术。幸运的是,可以使用 OPENAI API 访问此模型。DALL·E 2 设法结合了概念、属性和不同的风格。它使用了 CLIP 神经网络。 CLIP(对比语言-图像预训练)是一种在各种(图像、文本)对上训练的神经网络 [25]。使用 CLIP,可以用自然语言来指导预测最相关的文本片段,给定图像,该模型最近已合并为图像的成功表示学习器。具体而言,CLIP 嵌入具有几个理想的特性:它们对图像分布偏移具有鲁棒性,具有令人印象深刻的零样本能力,并且经过微调以实现最先进的结果。**为了获得完整的图像生成模型,CLIP 图像嵌入解码器模块与先验模型相结合,从给定的文本标题生成可能的 CLIP 图像嵌入。**我们在图 4 中说明了从提示生成的图像.

IMAGEN:Imagen 是一种文本到图像扩散模型 ,由大型变换器语言模型组成。至关重要的是,使用该模型观察到的主要发现是,在纯文本语料库上预先训练的大型语言模型在编码文本以进行图像合成方面非常有效 。准确地说,使用 Imagen,已经发现增加语言模型的大小比增加图像扩散模型的大小更能提高样本保真度和图像-文本对齐。该模型由谷歌创建,API 可以在他们的网页上找到。为了评估他们的模型,谷歌创建了 Drawbench,这是一组 200 个提示,支持文本到图像模型的评估和比较。最具体地说,该模型基于预训练的文本编码器(如 BERT ),它执行从文本到一系列词嵌入的映射,以及一系列条件扩散模型,这些模型将这些嵌入映射到分辨率越来越高的图像。我们在图 5 中显示了根据提示生成的图像。

Stable Diffusion:Stable Diffusion是一种开源的潜在扩散模型,由慕尼黑大学的 CompVis 小组开发。该模型与其他模型的主要区别在于使用了潜在扩散模型,并且它可以执行图像修改,因为它可以在其潜在空间中执行操作。对于 Stable Diffusion,我们可以通过他们的网站使用 API。更具体地说,Stable Diffusion 由两部分组成:文本编码器和图像生成器 。图像信息创建者完全在潜在空间中工作。此属性使其比以前在像素空间中工作的扩散模型更快。

Muse:该模型是一种文本到图像转换器模型,可实现最先进的图像生成,同时比扩散或自回归模型更高效。具体来说,它是在离散标记空间中的掩码建模任务上进行训练的。因此,由于使用了离散标记并且需要更少的采样迭代,因此效率更高。与自回归模型 Parti 相比,Muse 由于并行解码,效率更高。 Muse 在推理时间上比 Imagen-3B 或 Parti-3B 快 10 倍,比 Stable Diffusion v 1.4 快 3 倍。 Muse 也比 Stable Diffusion 更快,尽管这两个模型都在 VQGAN 的潜在空间中工作。
DALL·E 2、IMAGEN 和 Muse 模型生成的图像与左侧栏中出现的提示的比较。第一列图像包含 DALL·E 2 生成的结果,第二列包含使用 IMAGEN 获得的结果,第三列包含 Muse 创建的图像:

3.2 Text-to-3D models
上一节中描述的模型处理文本提示到 2D 图像的映射。但是,对于游戏等行业,需要生成 3D 图像。在本节中,我们简要介绍两种文本到 3D 模型:Dreamfusion 和 Magic3D。
Dreamfusion:DreamFusion 是由 Google Research 开发的文本到 3D 模型,它使用预训练的 2D 文本到图像扩散模型来执行文本到 3D 合成 。特别是,Dreamfusion 将以前的 CLIP 技术替换为从 2D 扩散模型的蒸馏中提取的损失。具体来说,扩散模型可以用作一般连续优化问题中的损失来生成样本。至关重要的是,参数空间中的采样比像素中的采样要困难得多,因为我们想要创建从随机角度渲染时看起来像好的图像的 3D 模型。为了解决这个问题,这个模型使用了一个可微分的生成器。其他方法侧重于对像素进行采样,但是,该模型侧重于创建从随机角度渲染时看起来像好图像的 3D 模型。我们在图 8 中举例说明了Dreamfusion 从一个特定角度创建的图像以及可以从其他文本提示生成的所有变体。为了看到完整的动画图像,我们建议访问 Dreamfusion 的网页。

Magic3D: 该模型是NVIDIA公司制作的文本转3D模型。虽然 Dreamfusion 模型取得了显着的效果,但该方法存在两个问题:主要是处理时间长和生成的图像质量低。然而,Magic3D 使用两阶段优化框架解决了这些问题。首先,Magic3D 先验构建低分辨率扩散,然后使用稀疏 3D 哈希网格结构进行加速。使用它,带纹理的 3D 网格模型通过高效的可微分渲染得到进一步优化。相比之下,在人类评估方面,该模型取得了更好的结果,因为 61.7% 的人更喜欢该模型而不是 DreamFusion。正如我们在图 9 中看到的,与 DreamFusion 相比,Magic3D 在几何和纹理方面实现了更高质量的 3D 形状。

3.3 Image-to-Text models
有时,获取描述图像的文本也很有用,这恰好是对前面小节中分析的图像的逆映射。在本节中,我们将分析执行此任务的两个模型以及其他模型:Flamingo 和 VisualGPT。
Flamingo:一种由 Deepmind 创建的视觉语言模型,它在广泛的开放式视觉和语言任务中使用少量学习,只需提示一些输入/输出示例。具体来说,Flamingo 的输入包含视觉条件自回归文本生成模型,能够摄取一系列与图像和/或视频交错的文本标记,并生成文本作为输出。对模型连同照片或视频进行查询,然后模型使用文本答案进行回答。可以在图 10 中观察到一些示例。Flamingo 模型利用两个互补模型:一个分析视觉场景的视觉模型和一个执行基本推理形式的大型语言模型。语言模型是在大量文本数据上训练的。

VisualGPT:VisualGPT 是 OpenAI制作的图像字幕模型。具体来说,VisualGPT 利用预训练语言模型 GPT-2 中的知识。为了弥合不同模态之间的语义鸿沟,设计了一种具有不饱和整流门函数的新型编码器-解码器注意机制。至关重要的是,该模型的最大优势在于它不需要像其他图像到文本模型那样多的数据。特别是,提高图像字幕网络中的数据效率将使快速数据管理、稀有物体的描述以及专业领域的应用成为可能。最有趣的是,这个模型的 API 可以在 GitHub 上找到。我们在图 11 中包含了模型针对提供给模型的三幅图像生成的文本提示的三个示例。

3.4 Text-to-Video models
正如我们在前面的小节中看到的,现在可以从文本生成图像。因此,下一个合乎逻辑的步骤是生成视频,即由文本生成图像序列。在本节中,我们提供有关能够执行此任务的两个模型的信息:phenaki 和 Soundify。
Phenaki:该模型由 Google Research 开发,能够在给定一系列文本提示的情况下执行逼真的视频合成。最有趣的是,我们可以从 GitHub 访问模型的 API。特别是,Phenaki 是第一个可以从开放域时间变量提示生成视频的模型。为了解决数据问题,它对大型图像-文本对数据集以及较少数量的视频-文本示例进行联合训练,可以产生超出视频数据集可用范围的泛化。这主要是由于图像-文本数据集具有数十亿个输入,而文本-视频数据集要小得多。同样,限制来自可变长度视频的计算能力。该模型由三部分组成:C-ViViT 编码器、训练转换器和视频生成器。编码器获得视频的压缩表示。第一个标记被转换为嵌入。接下来是时间变换器,然后是空间变换器。在空间变换器的输出之后,他们在没有激活的情况下应用单个线性投影将标记映射回像素空间。因此,即使提示是新的概念组合,该模型也会根据开放域提示生成时间上连贯且多样化的视频。视频可能长达几分钟,而模型是在 1.4 秒的视频上训练的。下面我们在图 12 和图 13 中显示了通过一系列文本提示以及从一系列文本提示和图像创建视频的一些示例。

在这里插入图片描述
Soundify:在视频编辑中,声音占故事的一半。但是,对于专业的视频编辑,问题来自于寻找合适的声音、对齐声音、视频和调整参数 。为了解决这个问题,Soundify 是 Runway 开发的一个将音效与视频匹配的系统。该系统使用优质音效库和 CLIP(之前提到的具有零镜头图像分类功能的神经网络)。具体来说,该系统分为三部分:分类、同步和混合。该分类通过对其中的声音发射器进行分类来将效果与视频相匹配。为了减少不同的声音发射器,视频根据绝对颜色直方图距离进行分割。在同步部分,确定间隔,将效果标签与每个帧进行比较,并精确定位高于阈值的连续匹配。在混音部分,效果被分成大约一秒的块。至关重要的是,块是通过淡入淡出拼接的。
3.5 Text-to-Audio models
正如我们在上一小节中所见,图像并不是唯一重要的非结构化数据格式。对于视频、音乐和许多上下文,音频可能至关重要。因此,我们在本小节中分析输入信息为文本且输出信息为音频的三个模型。
AudioLM:此模型由 Google 开发,用于生成具有长期一致性的高质量音频。特别是,AudioLM 将输入音频映射到一系列离散标记中,并将音频生成作为该表示空间中的语言建模任务。通过对大量原始音频波形语料库进行训练,AudioLM 学会在给定简短提示的情况下生成自然且连贯的延续。尽管在没有任何音乐符号表示的情况下接受训练,但该方法可以通过生成连贯的钢琴音乐延续来扩展到语音之外。与其他模型一样,可以通过 GitHub 找到 API。音频信号涉及多个抽象尺度。在音频合成方面,多个音阶使得在显示一致性的同时实现高音频质量非常具有挑战性。该模型通过结合神经音频压缩、自监督表示学习和语言建模方面的最新进展来实现这一目标。
在主观评价方面,评分者被要求听一段 10 秒的样本,并判断它是人类语音还是合成延续。基于收集到的 1000 个评分,该率为 51.2%,这与随机分配标签相比在统计上并不显着。这告诉我们,人类无法区分合成样本和真实样本。
ukebox:这是一个由 OpenAI 开发的模型,可以在原始音频域中生成带有歌声的音乐。同样,它的 API 可以在 GitHub 中找到。以前,文本到音乐类型中的早期模型以指定时间、音高和速度的钢琴卷轴的形式象征性地生成音乐。具有挑战性的方面是尝试将音乐直接制作为一段音频的非符号方法。事实上,原始音频的空间维度非常高,这使得问题非常具有挑战性。因此,关键问题是对原始音频进行建模会产生远程依赖性,这使得学习音乐的高级语义在计算上具有挑战性。为了解决这个问题,该模型试图通过分层 VQ-VAE 架构来解决它,将音频压缩到离散空间,损失函数旨在保留最多的信息量。该模型制作来自不同流派的歌曲,例如摇滚、嘻哈和爵士乐。但是,该模型仅限于英文歌曲。具体来说,它的训练数据集来自 LyricWiki 的 120 万首歌曲。 VQ-VAE 有 50 亿个参数,并在 9 秒的音频片段上训练了 3 天。
Whisper:该模型是由 OpenAI 开发的音频到文本转换器。它完成了该领域的几项任务:多语言语音识别、翻译和语言识别。与之前的案例一样,它的 API 可以在 GitHub 网站上找到。语音识别系统的目标应该是开箱即用地在广泛的环境中可靠地工作,而不需要为每个部署分布对解码器进行有监督的微调。这很难,因为缺乏高质量的预训练解码器。具体来说,这个模型是在 680,000 小时的标记音频数据上训练的。这些数据是从互联网上收集的,这导致了一个非常多样化的数据集,涵盖了来自许多不同环境、录音设置、说话者和语言的广泛分布的音频。该模型确保数据集仅来自人声,因为机器学习语音会损害模型。文件在 30 秒的片段中被打破,与该时间片段内出现的转录本子集配对。该模型有一个编码器-解码器转换器,因为该架构已被验证可以可靠地扩展。我们可以通过下图观察模型的架构特征。我们可以看到不同类型的数据和学习顺序。
3.6 Text-to-Text models
前面的模型都是将一种非结构化数据类型转换为另一种数据类型。但是,对于文本,将文本转换为另一种文本以满足一般问答等任务非常有用。以下四种模型处理文本,也输出文本,以满足不同的需求。
ChatGPT:流行的 ChatGPT 是 OpenAI 的一种模型,它以对话方式进行交互。众所周知,该模型会回答后续问题、挑战不正确的前提并拒绝不适当的请求。更具体地说,ChatGPT 背后的算法基于转换器。然而,训练是通过人类反馈的强化学习进行的。特别是,初始模型是使用有监督的微调进行训练的:人类 AI 训练员将提供他们扮演双方的对话,即用户和 AI 助手。然后,这些人将获得模型编写的回复,以帮助他们撰写回复。该数据集与 InstructGPT的数据集混合,后者被转换为对话格式。可以在他们的网站上找到演示,也可以在 OpenAI 的网站上找到 API。我们在图中总结了 ChatGPT 训练的主要步骤,可在 ChatGPT 演示网站上找到。最后,ChatGPT 还能够生成代码和简单的数学运算。
在这里插入图片描述
LaMDA:LaMDA 是对话应用程序的语言模型。与大多数其他语言模型不同,LaMDA 接受了对话训练。它是一系列专门用于对话的基于 Transformer 的神经语言模型,具有多达 137B 个参数,并在 1.56T 公共对话数据和网络文本的单词上进行了预训练。微调可以确保模型的安全性和事实基础。只有 0.001% 的训练数据用于微调,这是该模型的一大成就。特别是,对话模式利用了 Transformer 在文本中呈现长期依赖关系的能力。具体来说,它们通常非常适合模型缩放。因此,LaMDA 使用单个模型来执行多项任务:它生成多个响应,这些响应经过安全过滤,基于外部知识源并重新排序以找到最高质量的响应。我们在图 15 中说明了与模型的对话示例。

PEER:由 Meta AI 研究开发的协作语言模型,在编辑历史上进行训练以涵盖整个写作过程。它基于四个步骤:计划、编辑、解释和重复。重复这些步骤,直到文本处于不需要进一步更新的令人满意的状态。该模型允许将撰写论文的任务分解为多个更容易的子任务。此外,**该模型还允许人类随时进行干预并将模型引导至任何方向。它主要基于维基百科编辑历史的训练。该方法是一种自我训练,使用模型填充缺失数据,然后在该合成数据上训练其他模型。这样做的缺点来自评论非常嘈杂和缺乏引用,这试图通过并不总是有效的检索系统来弥补。该框架是基于迭代过程的。
制定计划、收集文件、执行编辑和解释它的整个过程可以重复多次,直到得出一个文本序列。对于训练,使用了 DeepSpeed transformer。
Meta AI Speech from Brain:Meta AI 开发的模型,用于帮助无法通过语音、打字或手势进行交流的人们。以前的技术依赖于需要神经外科干预的侵入性大脑记录技术。该模型试图直接从非侵入性大脑记录中解码语言。这将提供更安全、更具可扩展性的解决方案,使更多人受益。这种提出的方法的挑战来自每个人大脑的噪音和差异以及传感器的放置位置。深度学习模型通过对比学习进行训练,并用于最大限度地对齐非侵入性大脑记录和语音。一种称为 wave2vec 2.0 **的自监督学习模型。用于识别听有声读物的志愿者大脑中语音的复杂表征。用于测量神经元活动的两种非侵入性技术是脑电图和脑磁图。训练数据来自四个开源数据集,代表 169 名志愿者收听有声读物的 150 小时录音。 EEG 和 MEG 记录被插入大脑模型,该模型由具有残留连接的标准深度卷积网络组成。这些录音来自个人的大脑。然后,该模型同时具有声音的语音模型和 MEG 数据的大脑模型。结果表明,该算法的几个组成部分有利于解码性能。同样,分析表明该算法随着 EEG 和 MEG 记录的增加而改进。这项研究表明,尽管数据存在噪声和可变性,但经过自我监督训练的 AI 可以解码感知语音。这项研究的最大局限在于它侧重于语音感知,但最终目标是将这项工作扩展到语音生成。
3.7 Text-to-Code models
虽然我们已经介绍了文本到文本模型,但并非所有文本都遵循相同的语法。一种特殊类型的文本是代码。在编程中,知道如何将想法转化为代码是必不可少的。为此,Codex 和 Alphacode 模型会有所帮助。
Codex:由 OpenAI 创建的 AI 系统,可将文本翻译成代码。它是一种通用编程模型,因为它基本上可以应用于任何编程任务。编程可以分为两部分:将问题分解为更简单的问题,并将这些问题映射到已经存在的现有代码(库、API 或函数)中。第二部分是程序员时间限制最多的部分,也是Codex最擅长的地方。为训练收集的数据是 2020 年 5 月从 GitHub 上托管的公共软件存储库收集的,其中包含 179GB 的低于1MB的python文件该模型是根据 GPT-3 进行微调的,GPT-3 已经包含强大的自然语言表示。演示和 API 可以在 Open AI 的网站上找到。
Alphacode:其他语言模型已经展示了令人印象深刻的代码生成能力,但这些系统在评估更复杂、未见过的问题时仍然表现不佳。然而,Alphacode 是一个用于为需要更深入推理的问题生成代码的系统。三个组成部分是实现这一成就的关键:拥有用于训练和评估的广泛数据集、大型且高效的基于 Transformer 的架构以及大规模模型采样。在训练方面,该模型首先通过总计 715.1 GB 代码的 GitHub 存储库进行预训练。这是一个比 Codex 的预训练数据集更广泛的数据集。为了更好地训练,从 Codeforces 平台引入了微调数据集。通过这个平台,代码竞赛在验证阶段进行,我们在这个阶段提高了模型的性能。关于基于转换器的架构,他们使用编码器-解码器转换器架构。与常用的仅解码器架构相比,该架构允许双向描述和额外的灵活性。同样,他们使用浅层编码器和深度编码器来提高模型的效率。为了降低采样成本,使用了多查询注意力。
3.8 Text-to-Science models
正如** Galactica 和 Minerva **模型所显示的那样,甚至科学文本也成为生成式 AI 的目标。尽管要在该领域取得成功还有很长的路要走,但研究自动科学文本生成的首次尝试至关重要。
Galactica:Galactica 是 Meta AI 和 Papers with Code 开发的自动组织科学的新型大型模型。该模型的主要优点是能够在不过度拟合的情况下对其进行多个时期的训练,其中上游和下游性能通过使用重复标记得到改善。数据集设计对该方法至关重要,因为所有数据均以通用降价格式处理,以混合不同来源的知识。引文通过特定的标记进行处理,该标记允许研究人员在给定任何输入上下文的情况下预测引文。模型预测引用的能力随着规模的扩大而提高,并且模型在引用分布方面变得更好。此外,该模型可以执行涉及 SMILES 化学公式和蛋白质序列的多模态任务。具体而言,Galactica 在仅解码器设置中使用 Transformer 架构,并为所有模型尺寸激活 GeLU。
Minerva:能够使用逐步推理解决数学和科学问题的语言模型。 Minerva 非常明确地专注于为此目的收集训练数据。它解决了定量推理问题,大规模制作模型并采用一流的推理技术。具体来说,Minerva 通过逐步生成解决方案来解决这些问题,这意味着包括计算和符号操作,而不需要计算器等外部工具。
3.9 Other models
由研究公司 Deepmind 创建的** Alphatensor **因其发现新算法的能力而成为业界完全革命性的模型。在已发布的示例中,Alpha Tensor 创建了一种更高效的矩阵乘法算法,这非常重要,因为提高算法的效率会影响很多计算,从神经网络到科学计算例程。
该方法基于深度强化学习方法,其中训练代理 AlphaTensor 玩单人游戏,目标是在有限因子空间内找到张量分解。在 TensorGame 的每一步,玩家选择如何组合矩阵的不同条目以进行相乘。根据达到正确乘法结果所需的选定运算次数分配分数。为了解决代理 TensorGame,开发了 AlphaTensor。 AlphaTensor 使用专门的神经网络架构来利用合成训练游戏的对称性。
GATO:是Deepmind做的一个单一的通才智能体。它作为一种多模式、多任务、多实施的通才政策。具有相同权重的相同网络可以承载与播放 Atari、字幕图像、聊天、堆叠积木等截然不同的功能。在所有任务中使用单一神经序列模型有很多好处。它减少了对具有归纳偏差的手工制定政策模型的需求。它增加了训练数据的数量和多样性。这个通用代理在许多任务上都取得了成功,并且可以用很少的额外数据进行调整以在更多任务上取得成功。 r 在模型规模的操作点进行训练,允许实时控制现实世界的机器人,目前在 GATO 的情况下约为 1.2B 参数。
其他已发布的生成式 AI 模型能够生成人体动作,或者在 ChatBCG 的情况下,使用 ChatGPT 作为替代模型生成幻灯片。
4 Conclusions and further work
通过这篇论文,我们可以观察到生成式人工智能所具有的能力。我们已经在文本到图像或文本到音频等任务中看到了大量的创造力和个性化。它们在文本到科学或文本到代码的任务中也很准确。这可以在很大程度上帮助经济,因为它可以帮助优化创造性和非创造性任务。
然而,由于目前构建它们的方式,这些模型面临着许多限制。在数据集方面,找到一些模型的数据,如文本到科学或文本到音频非常困难,使得训练模型非常耗时。特别是,数据集和参数必须非常庞大,这使得训练变得更加困难。模型最大的问题之一是从数据集中的问题中尝试解决方案,而模型在解决这些问题时遇到了更多麻烦。同样,在计算方面,运行它们需要大量的时间和计算能力。为了运行模型,需要很多天和先进的计算机。此外,这些模型面临来自需要控制的数据的偏差。 Galactica 模型试图通过一个无偏差层来控制这个问题,但它仍然是生成人工智能的一个主要问题。
通过 Minerva 模型,我们可以看到该模型知道求解方程式所需的步骤。这是开创性的,因为这些模型的最大局限之一是模型不能准确理解它们在做什么。而且,它仍然是一个行业的起点;因此准确性仍然是一个问题。例如,文本到视频模型仅由 Phenaki 代表,因为制作准确的视频非常困难。文本到科学的模型确实找到了一些准确性,但该准确性仍然远远落后于专业人士在日常基础上实际依赖该技术的水平。此外,由于缺乏对伦理的理解,这些模型需要受到约束。 Phenaki 在其论文中甚至承认,像文本到视频这样的系统可以用来创建深度造假。最后,我们仍处于发现这种情报的确切目的的阶段。有文章将 Google 与 ChatGPT3 进行比较,这完全不准确,因为 ChatGPT3 不会实时更新其信息。我们应该意识到这些模型的局限性,以便在接下来的几年中尝试和改进它们。
References
- Alayrac, J.-B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., Lenc, K., Mensch, A., Millican, K., Reynolds, M., et al. Flamingo: a visual language model for few-shot learning. arXiv preprint arXiv:2204.14198 (2022).
- Anantrasirichai, N., and Bull, D. Artificial intelligence in the creative industries: a review. Artificial Intelligence Review (2021), 1–68.
- Bhavya, B., Xiong, J., and Zhai, C. Analogy generation by prompting large language models: A case study of instructgpt. arXiv preprint arXiv:2210.04186 (2022).
- Borsos, Z., Marinier, R., Vincent, D., Kharitonov, E., Pietquin, O., Sharifi, M., Teboul, O., Grangier, D., Tagliasacchi, M., and Zeghidour, N. Audiolm: a language modeling approach to audio generation. arXiv preprint arXiv:2209.03143 (2022).
- Budzianowski, P., and Vuli ́ c, I. Hello, it’s gpt-2–how can i help you? towards the use of pretrained language models for task-oriented dialogue systems. arXiv preprint arXiv:1907.05774 (2019).
- Chang, H., Zhang, H., Barber, J., Maschinot, A., Lezama, J., Jiang, L., Yang, M.-H., Murphy, K., Freeman, W. T., Rubinstein, M., et al. Muse: Text-to-image generation via masked generative transformers. arXiv preprint arXiv:2301.00704 (2023).
- Chen, J., Guo, H., Yi, K., Li, B., and Elhoseiny, M. Visualgpt: Data-efficient adaptation of pretrained language models for image captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2022), pp. 18030–18040.
- Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H. P. d. O., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G., et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374 (2021).
- Creswell, A., White, T., Dumoulin, V., Arulkumaran, K., Sengupta, B., and Bharath, A. A. Generative adversarial networks: An overview. IEEE signal processing magazine 35, 1 (2018), 53–65.
- Daras, G., and Dimakis, A. G. Discovering the hidden vocabulary of dalle-2. arXiv preprint arXiv:2206.00169 (2022).
- D ́ efossez, A., Caucheteux, C., Rapin, J., Kabeli, O., and King, J.-R. Decoding speech from non-invasive brain recordings. arXiv preprint arXiv:2208.12266 (2022).
- Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018).
- Dhariwal, P., Jun, H., Payne, C., Kim, J. W., Radford, A., and Sutskever, I. Jukebox: A generative model for music. arXiv preprint arXiv:2005.00341 (2020).
- Ding, S., and Gutierrez-Osuna, R. Group latent embedding for vector quantized variational autoencoder in non-parallel voice conversion. In INTERSPEECH (2019), pp. 724–728.
- Fawzi, A., Balog, M., Huang, A., Hubert, T., Romera-Paredes, B., Barekatain, M., Novikov, A., R Ruiz, F. J., Schrittwieser, J., Swirszcz, G., et al. Discovering faster matrix multiplication algorithms with reinforcement learning. Nature 610, 7930 (2022), 47–53.
- Kandlhofer, M., Steinbauer, G., Hirschmugl-Gaisch, S., and Huber, P. Artificial intelligence and computer science in education: From kindergarten to university. In 2016 IEEE Frontiers in Education Conference (FIE) (2016), IEEE, pp. 1–9.
- Kingma, D., Salimans, T., Poole, B., and Ho, J. Variational diffusion models. Advances in neural information processing systems 34 (2021), 21696–21707.
- LeCun, Y., Bengio, Y., and Hinton, G. Deep learning. nature 521, 7553 (2015), 436–444.
- Li, Y., Choi, D., Chung, J., Kushman, N., Schrittwieser, J., Leblond, R., Eccles, T., Keeling, J., Gimeno, F., Dal Lago, A., et al. Competition-level code generation with alphacode. Science 378, 6624 (2022), 1092–1097.
- Lin, C.-H., Gao, J., Tang, L., Takikawa, T., Zeng, X., Huang, X., Kreis, K., Fidler, S., Liu, M.-Y., and Lin, T.-Y. Magic3d: High-resolution text-to-3d content creation. arXiv preprint arXiv:2211.10440 (2022).
- Lin, D. C.-E., Germanidis, A., Valenzuela, C., Shi, Y., and Martelaro, N. Soundify: Matching sound effects to video. arXiv preprint arXiv:2112.09726 (2021).
- Lin, T., Wang, Y., Liu, X., and Qiu, X. A survey of transformers. AI Open (2022).