注意力机制学习(全公式)
文章目录
- 注意力起源
-
- 背景
- 解法
-
- 【1】
- 【2】
- 【3】
- 注意力函数形式
-
- 【1】Nadaraya-Watson函数展开
- 【2】采用Nadaraya-Watson函数高斯展开
- 注意力机制表达式
-
- 注意力-掩蔽函数
- 加性注意力
- 缩放点积注意力
- Bahdanau注意力机制
注意力起源
背景
已有数据:
( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x n , y n ) (x_1,y_1),(x_2,y_2),\cdots,(x_n,y_n) (x1,y1),(x2,y2),⋯,(xn,yn)
任务:给一个新的 x x x求对应的 y y y。
解法
其实机器学习就是不断去估计逼近函数的样子。往往找到一种更好的逼近函数的形式,估计效果就会更好。
【1】
如果不考虑输入的 x x x,只是基于已有的数据估计 y y y,那么应该有:
y = b = b ( x 1 , ⋯ , x n , y 1 , ⋯ , y n ) \begin{split} y&=b \\&=b(x_1,\cdots,x_n,y_1,\cdots,y_n) \end{split} y=b=b(x1,⋯,xn,y1,⋯,yn)
此时函数的形式有多种多样,可以从方差最小角度、中位数角度、均值角度等等,比如对于 x i x_i xi进行聚类,类别规模最大同时类内方差最小的那个类别内的样本 x i x_i xi所对应的 y i y_i yi的均值作为对 y y y的估计。上述想法写成公式就是:
1.聚类:
{ ( x 1 , y 1 ) , ( x 2 , y 2 ) , ( x 3 , y 3 ) , ⋯ , ( x n , y n ) } p r o x y → { S 1 = { ( x 1 , y 1 ) , ( x 3 , y 3 ) } , S 2 = { ( x 2 , y 2 ) , ( x 4 , y 4 ) , ⋯ , ( x n , y n ) } } \{ (x_1,y_1),(x_2,y_2),(x_3,y_3),\cdots,(x_n,y_n)\} \underrightarrow{proxy}\{S_1=\{(x_1,y_1),(x_3,y_3)\},S_2=\{(x_2,y_2),(x_4,y_4),\cdots,(x_n,y_n)\}\} {(x1,y1),(x2,y2),(x3,y3),⋯,(xn,yn)}proxy{S1={(x1,y1),(x3,y3)},S2={(x2,y2),(x4,y4),⋯,(xn,yn)}}
2.比较:
∣ S 1 ∣ < ∣ S 2 ∣ , D ( S 2 ) ∣ S 2 ∣ 2 < D ( S 1 ) ∣ S 1 ∣ 2 \left| S_1 \right|<\left| S_2 \right|,\frac{D(S_2)}{{\left| S_2 \right|}^2}<\frac{D(S_1)}{{\left| S_1\right|}^2} ∣S1∣<∣S2∣,∣S2∣2D(S2)<∣S1∣2D(S1)
3.估计:
y = ∑ i ∈ S 2 y i ∣ S 2 ∣ y=\sum_{i\in S_2}\frac{y_i}{\left| S_2 \right|} y=i∈S2∑∣S2∣yi
当然也有其他的函数形式,正如前面所说,函数形式越精巧,估计效果越准确。
在无其他信息补充条件下,最简单的估计是: y = y 1 + y 2 + ⋯ + y n n y=\frac{y_1+y_2+\cdots+y_n}{n} y=ny1+y2+⋯+yn。
【2】
如果考虑输入的 x x x,估计 y y y则有:
y = f ( x , x 1 , ⋯ , x n , y 1 , ⋯ , y n ) \begin{split} y&=f(x,x_1,\cdots,x_n,y_1,\cdots,y_n) \end{split} y=f(x,x1,⋯,xn,y1,⋯,yn)
常见形式如下所示:
y = f ( x , x 1 , ⋯ , x n , y 1 , ⋯ , y n ) = w × x + b = w ( x , x 1 , ⋯ , x n , y 1 , ⋯ , y n ) × x + b ( x , x 1 , ⋯ , x n , y 1 , ⋯ , y n ) \begin{split} y&=f(x,x_1,\cdots,x_n,y_1,\cdots,y_n) \\&=w\times x+b \\&=w(x,x_1,\cdots,x_n,y_1,\cdots,y_n)\times{x}+b(x,x_1,\cdots,x_n,y_1,\cdots,y_n) \end{split} y=f(x,x1,⋯,xn,y1,⋯,yn)=w×x+b=w(x,x1,⋯,xn,y1,⋯,yn)×x+b(x,x1,⋯,xn,y1,⋯,yn)
当 w , b w,b w,b与 x x x无关时,有:
y = w × x + b = w ( x 1 , ⋯ , x n , y 1 , ⋯ , y n ) × x + b ( x 1 , ⋯ , x n , y 1 , ⋯ , y n ) \begin{split} y&=w\times x+b \\&=w(x_1,\cdots,x_n,y_1,\cdots,y_n)\times{x}+b(x_1,\cdots,x_n,y_1,\cdots,y_n) \end{split} y=w×x+b=w(x1,⋯,xn,y1,⋯,yn)×x+b(x1,⋯,xn,y1,⋯,yn)
此时是一次多项式,在最小化平方误差 ∑ i = 1 n ( w x i + b − y i ) 2 \sum_{i=1}^{n}(wx_i+b-y_i)^2 ∑i=1n(wxi+b−yi)2的目标下可以求出参数 w , b w,b w,b的表达式。
此时我们想更高程度的逼近数据的途径是增加逼近的阶数。也就是 y = b + w 1 x + w 2 x 2 + ⋯ + w n c n y=b+w_1x+w_2x^2+\cdots+w_nc^n y=b+w1x+w2x2+⋯+wncn。但是此种方法有个缺陷就是超参数n不好确定,也就是用几阶多项式去逼近最合适不好确定。
在传统思路下,想拟合的更精确无非就是阶次不断增加。
y = b + w 1 ∗ x + w 2 ∗ x 2 + ⋯ + w n ∗ x n + ⋯ y=b+w_1*x+w_2*x^2+\cdots+w_n*x^n+\cdots y=b+w1∗x+w2∗x2+⋯+wn∗xn+⋯
【3】
但是我们可以通过设计更加灵活的函数从而实现更准确地拟合,比如用插值多项式函数去拟合:
插值多项式函数满足: l i ( x i ) = 1 ; l i ( x t ) = 0 , t ≠ i ; l_i(x_i)=1;l_i(x_{t})=0,t \neq i; li(xi)=1;li(xt)=0,t=i;,所以有:
l i ( x ) = ( x − x 1 ) ( x − x 2 ) ⋯ ( x − x i − 1 ) ( x − x i + 1 ) ⋯ ( x − x n ) ( x i − x 1 ) ( x i − x 2 ) ⋯ ( x i − x i − 1 ) ( x i − x i + 1 ) ⋯ ( x i − x n ) l_i(x)=\frac{(x-x_1)(x-x_2)\cdots(x-x_{i-1})(x-x_{i+1})\cdots(x-x_n)}{(x_i-x_1)(x_i-x_2)\cdots(x_i-x_{i-1})(x_i-x_{i+1})\cdots(x_i-x_n)} li(x)=(xi−x1)(xi−x2)⋯(xi−xi−1)(xi−xi+1)⋯(xi−xn)(x−x1)(x−x2)⋯(x−xi−1)(x−xi+1)⋯(x−xn)
这样的话,根据给定数据点的拟合就可以写为:
y = ∑ i = 1 n l i ( x ) y i y=\sum_{i=1}^{n}l_i(x)y_i y=i=1∑nli(x)yi
可以验证如下:
y ∣ x = x 1 = ∑ i = 1 n l i ( x 1 ) y i = l 1 ( x 1 ) y 1 + 0 ∗ y 2 + ⋯ = y 1 y|_{x=x_1}=\sum_{i=1}^{n}l_i(x_1)y_i=l_1(x_1)y_1+0*y_2+\cdots=y_1 y∣x=x1=i=1∑nli(x1)yi=l1(x1)y1+0∗y2+⋯=y1
所以用拉格朗日插值基函数对已有数据的拟合效果较好,并且不会受到人为设计的超参数影响。
注意力函数形式
我们把使用插值函数对数据进行拟合的表达式抽象一下:
y = ∑ i = 1 n l i ( x ) y i y=\sum_{i=1}^{n}l_i(x)y_i y=i=1∑nli(x)yi
然后根据 l i ( x ) l_i(x) li(x)所具有的特殊属性 l i ( x i ) = 1 ; l i ( x t ) = 0 , t ≠ i ; l_i(x_i)=1;l_i(x_{t})=0,t \neq i; li(xi)=1;li(xt)=0,t=i;可知: l i ( x ) l_i(x) li(x)可以写为: l ( x , x i ) l(x,x_i) l(x,xi)。
y = ∑ i = 1 n l i ( x ) y i = ∑ i = 1 n l ( x , x i ) y i y=\sum_{i=1}^{n}l_i(x)y_i=\sum_{i=1}^{n}l(x,x_i)y_i y=i=1∑nli(x)yi=i=1∑nl(x,xi)yi
把待估计的自变量 x x x看作查询,已有数据 x i x_i xi看作键,所以 l ( x , x i ) l(x,x_i) l(x,xi)相当于衡量 x x x与 x i x_i xi的匹配度,然后根据匹配度对值 y i y_i yi进行加权,就可以得到结果。
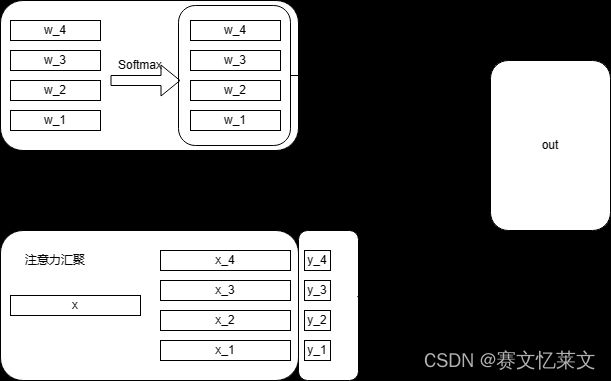
同样,可以通过将这个抽象函数具体化来达到较好的性能。调整这个函数可以实现不同的性能。
【1】Nadaraya-Watson函数展开
比较著名的就是以Nadaraya-Watson的方式设计上述 l ( x , x i ) l(x,x_i) l(x,xi)。
Nadaraya-Watson的方式可以理解为把匹配度权重函数 l ( x , x i ) l(x,x_i) l(x,xi)替换为了 x x x与 x i x_i xi之间的距离向量的函数: l ( x , x i ) = K ( x − x i ) ∑ j = 1 n K ( x − x j ) l(x,x_i)=\frac{K(x-x_i)}{\sum_{j=1}^{n}K(x-x_j)} l(x,xi)=∑j=1nK(x−xj)K(x−xi),当然通过不同物理意义上的距离函数,可以修改这个展开,实现不同的拟合效果。
f ( x ) = ∑ i = 1 n K ( x − x i ) ∑ j = 1 n K ( x − x j ) y i f(x)=\sum_{i=1}^{n}\frac{K(x-x_i)}{\sum_{j=1}^{n}K(x-x_j)}y_i f(x)=i=1∑n∑j=1nK(x−xj)K(x−xi)yi
(展开不唯一性)如果我们让 K ( x − x i ) K(x-x_i) K(x−xi)也满足上面匹配度函数的性质 K ( x i − x i ) = 1 ; K ( x t − x i ) = 0 , t ≠ i K(x_i-x_i)=1;K(x_t-x_i)=0,t\neq i K(xi−xi)=1;K(xt−xi)=0,t=i,也就是让 K ( x − x i ) = ( x − x 1 ) ( x − x 2 ) ⋯ ( x − x i − 1 ) ( x − x i + 1 ) ⋯ ( x − x n ) ( x i − x 1 ) ( x i − x 2 ) ⋯ ( x i − x i − 1 ) ( x i − x i + 1 ) ⋯ ( x i − x n ) K(x-x_i)=\frac{(x-x_1)(x-x_2)\cdots(x-x_{i-1})(x-x_{i+1})\cdots(x-x_n)}{(x_i-x_1)(x_i-x_2)\cdots(x_i-x_{i-1})(x_i-x_{i+1})\cdots(x_i-x_n)} K(x−xi)=(xi−x1)(xi−x2)⋯(xi−xi−1)(xi−xi+1)⋯(xi−xn)(x−x1)(x−x2)⋯(x−xi−1)(x−xi+1)⋯(x−xn),那么这时这个Nadaraya-Watson插值也是成立的。当然还有其它形式的函数满足要求,甚至不需要满足 K ( x t − x i ) = 0 , t ≠ i K(x_t-x_i)=0,t\neq i K(xt−xi)=0,t=i这个要求,就可以作为Nadaraya-Watson插值中的 K K K函数。比如采用高斯展开 K ( x − x i ) = 1 2 π exp ( − ( x − x i ) 2 2 ) K(x-x_i)=\frac{1}{\sqrt{2\pi}}\exp(-\frac{(x-x_i)^2}{2}) K(x−xi)=2π1exp(−2(x−xi)2)就不满足上述两点要求。
我们可以看出,对于Nadaraya-Watson插值展开,不论任何的 x x x,都会有 ∑ i l ( x , x i ) = 1 \sum_{i}l(x,x_i)=1 ∑il(x,xi)=1。主要是为了使匹配度权重服从概率分布的定义。从形式上是为了遵从变量的均值的定义方式:
E ( x ) = ∑ x p ( x ) × x , ∑ x p ( x ) = 1 E(x)=\sum_x p(x)\times x,\sum_{x}p(x)=1 E(x)=x∑p(x)×x,x∑p(x)=1
相比原始的拉格朗日插值这个Nadaraya-Watson插值有什么别的意义吗?比如说减小方差,维持均值?这怎么证明呢?
原始的拉格朗日:
f ( x ) = ∑ i l i ( x ) y i = ∑ i l ( x , x i ) y i = ∑ i ( x − x 1 ) ( x − x 2 ) ⋯ ( x − x i − 1 ) ( x − x i + 1 ) ⋯ ( x − x n ) ( x i − x 1 ) ( x i − x 2 ) ⋯ ( x i − x i − 1 ) ( x i − x i + 1 ) ⋯ ( x i − x n ) y i \begin{split} f(x)=&\sum_{i}l_i(x)y_i \\=&\sum_{i}l(x,x_i)y_i \\=&\sum_{i}\frac{(x-x_1)(x-x_2)\cdots(x-x_{i-1})(x-x_{i+1})\cdots(x-x_n)}{(x_i-x_1)(x_i-x_2)\cdots(x_i-x_{i-1})(x_i-x_{i+1})\cdots(x_i-x_n)}y_i \end{split} f(x)===i∑li(x)yii∑l(x,xi)yii∑(xi−x1)(xi−x2)⋯(xi−xi−1)(xi−xi+1)⋯(xi−xn)(x−x1)(x−x2)⋯(x−xi−1)(x−xi+1)⋯(x−xn)yi
在给定的 x i x_i xi上,函数取值会是 y i y_i yi,但是在 x x x取非给定的数据 x i x_i xi时候,函数中的匹配度权重之和不为1。可以分析一下相关的均值与方差。
假设 x x x取遍了某个范围内的数 [ a , b ] [a,b] [a,b],会有对应的 [ y a , y b ] [y_a,y_b] [ya,yb],通过分析这个 y y y集合的松散度,可以看出这个函数的平滑性。
假设 x x x服从均匀分布,那么 x ∼ 1 b − a x\sim \frac{1}{b-a} x∼b−a1,对应的 y y y值也服从均匀分布,假设无重复。求 E ( y ) , D ( y ) E(y),D(y) E(y),D(y)。就相当于已知一个随机变量的概率分布,求随机变量函数的数字特征。
E y ∼ p ( y ) ( y ) = E x ∼ p ( x ) ( f ( x ) ) = E x ∼ p ( x ) ( ∑ i ( x − x 1 ) ( x − x 2 ) ⋯ ( x − x i − 1 ) ( x − x i + 1 ) ⋯ ( x − x n ) ( x i − x 1 ) ( x i − x 2 ) ⋯ ( x i − x i − 1 ) ( x i − x i + 1 ) ⋯ ( x i − x n ) y i ) \begin{split} E_{y\sim p(y)}(y)=&E_{x\sim p(x)}(f(x)) \\=&E_{x\sim p(x)}(\sum_{i}\frac{(x-x_1)(x-x_2)\cdots(x-x_{i-1})(x-x_{i+1})\cdots(x-x_n)}{(x_i-x_1)(x_i-x_2)\cdots(x_i-x_{i-1})(x_i-x_{i+1})\cdots(x_i-x_n)}y_i) \end{split} Ey∼p(y)(y)==Ex∼p(x)(f(x))Ex∼p(x)(i∑(xi−x1)(xi−x2)⋯(xi−xi−1)(xi−xi+1)⋯(xi−xn)(x−x1)(x−x2)⋯(x−xi−1)(x−xi+1)⋯(x−xn)yi)
对于上面的Nadaraya-Watson插值,我们选择插值函数 K ( x − x i ) = ( x − x 1 ) ( x − x 2 ) ⋯ ( x − x i − 1 ) ( x − x i + 1 ) ⋯ ( x − x n ) ( x i − x 1 ) ( x i − x 2 ) ⋯ ( x i − x i − 1 ) ( x i − x i + 1 ) ⋯ ( x i − x n ) K(x-x_i)=\frac{(x-x_1)(x-x_2)\cdots(x-x_{i-1})(x-x_{i+1})\cdots(x-x_n)}{(x_i-x_1)(x_i-x_2)\cdots(x_i-x_{i-1})(x_i-x_{i+1})\cdots(x_i-x_n)} K(x−xi)=(xi−x1)(xi−x2)⋯(xi−xi−1)(xi−xi+1)⋯(xi−xn)(x−x1)(x−x2)⋯(x−xi−1)(x−xi+1)⋯(x−xn)以跟标准拉格朗日插值形成对比。
E y ∼ p ( y ) ( y ) = E x ∼ p ( x ) ( f ( x ) ) = E x ∼ p ( x ) ( ∑ i ( x − x 1 ) ( x − x 2 ) ⋯ ( x − x i − 1 ) ( x − x i + 1 ) ⋯ ( x − x n ) ( x i − x 1 ) ( x i − x 2 ) ⋯ ( x i − x i − 1 ) ( x i − x i + 1 ) ⋯ ( x i − x n ) ∑ j = 1 n ( x − x 1 ) ( x − x 2 ) ⋯ ( x − x j − 1 ) ( x − x j + 1 ) ⋯ ( x − x n ) ( x j − x 1 ) ( x j − x 2 ) ⋯ ( x j − x j − 1 ) ( x j − x j + 1 ) ⋯ ( x j − x n ) y i ) \begin{split} E_{y\sim p(y)}(y)=&E_{x\sim p(x)}(f(x)) \\=&E_{x\sim p(x)}(\sum_{i}\frac{\frac{(x-x_1)(x-x_2)\cdots(x-x_{i-1})(x-x_{i+1})\cdots(x-x_n)}{(x_i-x_1)(x_i-x_2)\cdots(x_i-x_{i-1})(x_i-x_{i+1})\cdots(x_i-x_n)}}{\sum_{j=1}^{n}\frac{(x-x_1)(x-x_2)\cdots(x-x_{j-1})(x-x_{j+1})\cdots(x-x_n)}{(x_j-x_1)(x_j-x_2)\cdots(x_j-x_{j-1})(x_j-x_{j+1})\cdots(x_j-x_n)}}y_i) \end{split} Ey∼p(y)(y)==Ex∼p(x)(f(x))Ex∼p(x)(i∑∑j=1n(xj−x1)(xj−x2)⋯(xj−xj−1)(xj−xj+1)⋯(xj−xn)(x−x1)(x−x2)⋯(x−xj−1)(x−xj+1)⋯(x−xn)(xi−x1)(xi−x2)⋯(xi−xi−1)(xi−xi+1)⋯(xi−xn)(x−x1)(x−x2)⋯(x−xi−1)(x−xi+1)⋯(x−xn)yi)
然后求出对应的均值和方差进行比较。
==以后可能经常性的会求出随机变量的均值与方差进行比较以说明理论背后的逻辑。所以有必要学习一下scipy的用法使得自定义概率分布成为可能。==可参考下方CSDN链接。
经验:没必要求概率分布,直接积分就行了,那个概率分布函数功能还不是很完善,不如积分。
代码如下:
import numpy as np #导入numpy
from matplotlib import pyplot as plt #导入绘图对象plt
import sympy as sp #用于比较符号函数
import scipy as sci #用于计算函数数值
x_i=np.array([1.1,1.5,2.0,3.1,4.2,4.3,4.6,5.1,7.1,8.3]) # 生成训练数据
y_i=np.array([2.4,3,1.1,4.5,3.6,2.2,1.0,5.6,3.7,0.2])
start=1.0 # 确定反映拟合函数的图形范围
end=4.1
test=np.linspace(start,end,1000)
def lfun(x,i,x_i): # 定义插值函数l(x,x_i)
temp=1.0
for j in range(np.size(x_i)):
if j!=i:
temp=temp*(x-x_i[j])/(x_i[i]-x_i[j])
return temp
def lang(x): # 定义拉格朗日函数
x_i=np.array([1.1,1.5,2.0,3.1,4.2,4.3,4.6,5.1,7.1,8.3])
y_i=np.array([2.4,3,1.1,4.5,3.6,2.2,1.0,5.6,3.7,0.2])
msum=0.0
for i in range(np.size(x_i)):
k_x_x_i=lfun(x,i,x_i)
msum=msum+k_x_x_i*y_i[i]
return msum
def lang1(x): # 稍后用于求方差
return lang(x)*lang(x)
def nawa(x): # 定义Nadaraya-Watson插值函数
x_i=np.array([1.1,1.5,2.0,3.1,4.2,4.3,4.6,5.1,7.1,8.3])
y_i=np.array([2.4,3,1.1,4.5,3.6,2.2,1.0,5.6,3.7,0.2])
msum=0.0
for i in range(np.size(x_i)):
temp=0.0
for j in range(np.size(x_i)):
temp=temp+lfun(x,j,x_i)
msum=msum+lfun(x,i,x_i)/temp*y_i[i]
return msum
def nawa1(x): # 稍后用于求na-wa展开方差
return nawa(x)*nawa(x)
x=sp.symbols('x') # 比较生成函数本身
print(lang(x))
print(nawa(x))
test_lang=lang(test) # 比较拟合的函数图形
test_nawa=nawa(test)
plt.plot(test,test_lang,test,test_nawa,x_i,y_i)
plt.show()
print(test_nawa-test_lang)
print(sum(test_nawa==test_lang))
v_lang,error_lang=sci.integrate.quad(lang,start,end) # 比较均值和方差
print(v_lang/(end-start),error_lang/(end-start))
v_nawa,error_nawa=sci.integrate.quad(nawa,start,end)
print(v_nawa/(end-start),error_nawa/(end-start))
v_lang1,error_lang1=sci.integrate.quad(lang1,start,end)
v_nawa1,error_nawa1=sci.integrate.quad(nawa1,start,end)
print(v_lang1/(end-start)-(v_lang/(end-start))**2,(v_nawa1/(end-start)-(v_nawa/(end-start))**2))
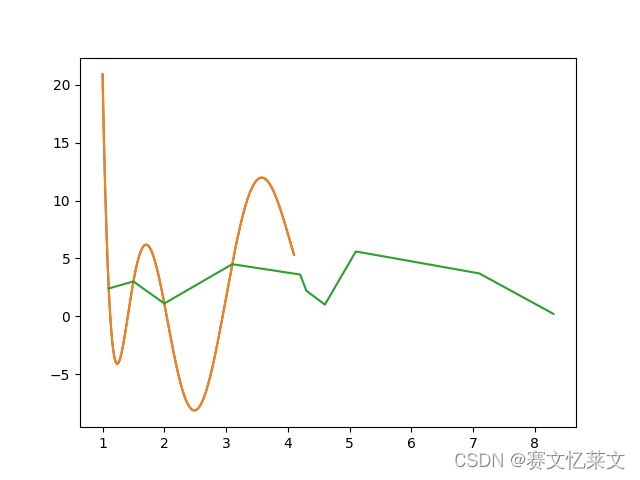
原始数据点连成的线段如图中所示,使用Nadaraya-Watson插值拟合的和采用拉格朗日拟合曲线比较接近,在图中为连续光滑的曲线。通过比较两条曲线的均值与方差,发现差别不大。从结果上来看,Nadaraya-Watson插值拟合的方差比较小一点。
【2】采用Nadaraya-Watson函数高斯展开
采用高斯函数来替代模型中的匹配度函数会导致一个问题,就是在已有的数据点上也不能实现完全拟合。
注意力机制表达式
回忆一下之前总结的注意力函数的形式:
y = ∑ i = 1 n l i ( x ) y i = ∑ i = 1 n l ( x , x i ) y i y=\sum_{i=1}^{n}l_i(x)y_i=\sum_{i=1}^{n}l(x,x_i)y_i y=i=1∑nli(x)yi=i=1∑nl(x,xi)yi
我们可以把形式变换一下:
y = ∑ i = 1 n l i ( x ) y i = ∑ i = 1 n l ( x , x i ) y i = ∑ i = 1 n l ( q , k i ) v i \begin{split} y&=\sum_{i=1}^{n}l_i(x)y_i=\sum_{i=1}^{n}l(x,x_i)y_i \\&=\sum_{i=1}^{n}l(q,k_i)v_i \end{split} y=i=1∑nli(x)yi=i=1∑nl(x,xi)yi=i=1∑nl(q,ki)vi
这就是注意力机制中的查询,键值对的定义。所以键值对是已有的数据,查询是未知的数据。
注意力-掩蔽函数
就是对于输入与人为补充的数据进行运算所得到的注意力权重加上一层掩码。如下所示:
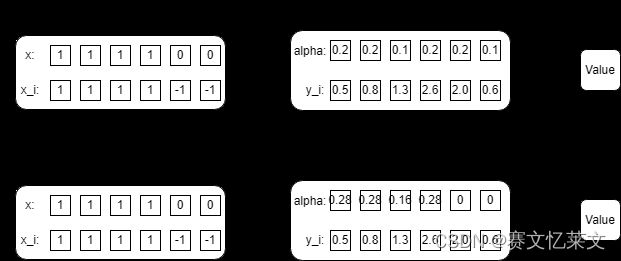
对于没有人为补充的,就不加掩码,而对于人为补全的数据,需要排除人为地影响,就可以通过加掩码来实现。上图中 x i x_i xi里面的 − 1 -1 −1就是人为补全的数据。所以对于人为补全的数据所对应的 y i y_i yi,让他的注意力权重为 0 0 0。
加性注意力
对于输入 x x x和已有样本数据 x i x_i xi,如果他们的长度不一样,一种办法就是对 x i x_i xi进行补全对齐,这就是上面的掩码技术;另一种办法通过矩阵把他们转化为一样的长度。
| Equation | Dimension |
|---|---|
| W q × q W_q\times q Wq×q | h × q ∗ q × 1 = h × 1 h\times q*q\times 1=h\times 1 h×q∗q×1=h×1 |
| W k × k W_k\times k Wk×k | h × k ∗ k × 1 = h × 1 h\times k*k\times 1=h\times 1 h×k∗k×1=h×1 |
| W v T × l ( q , k ) W_v^T\times l(q,k) WvT×l(q,k) | v × h ∗ h × 1 = v × 1 v\times h*h\times 1=v\times 1 v×h∗h×1=v×1 |
| v × α ( q , k ) v\times \alpha(q,k) v×α(q,k) | 1 × v ∗ v × 1 = 1 × 1 1\times v*v\times 1=1\times 1 1×v∗v×1=1×1 |
对于多个 q : q 1 , q 2 , ⋯ , q n q:{q_1,q_2,\cdots,q_n} q:q1,q2,⋯,qn,基于已有的 ( k , v ) : ( k 1 , v 1 ) , ( k 2 , v 2 ) , ⋯ , ( k m , v m ) (k,v):{(k_1,v_1),(k_2,v_2),\cdots,(k_m,v_m)} (k,v):(k1,v1),(k2,v2),⋯,(km,vm),得到的注意力结果为:
| q q q | ( k , v ) : ( k 1 , v 1 ) , ( k 2 , v 2 ) , ⋯ , ( k m , v m ) (k,v):{(k_1,v_1),(k_2,v_2),\cdots,(k_m,v_m)} (k,v):(k1,v1),(k2,v2),⋯,(km,vm) |
|---|---|
| q 1 q_1 q1 | V ( q 1 , k 1 , v 1 ) + ⋯ + V ( q 1 , k m , v m ) V(q_1,k_1,v_1)+\cdots+V(q_1,k_m,v_m) V(q1,k1,v1)+⋯+V(q1,km,vm) |
| q 2 q_2 q2 | V ( q 2 , k 1 , v 1 ) + ⋯ + V ( q 2 , k m , v m ) V(q_2,k_1,v_1)+\cdots+V(q_2,k_m,v_m) V(q2,k1,v1)+⋯+V(q2,km,vm) |
| ⋮ \vdots ⋮ | ⋮ \vdots ⋮ |
| q n q_n qn | V ( q n , k 1 , v 1 ) + ⋯ + V ( q n , k m , v m ) V(q_n,k_1,v_1)+\cdots+V(q_n,k_m,v_m) V(qn,k1,v1)+⋯+V(qn,km,vm) |
缩放点积注意力
在缩放点积注意力的表达式中对于注意力的计算是:
l ( x , x i ) = x T × x i / d l(x,x_i)=x^T\times x_i/\sqrt{d} l(x,xi)=xT×xi/d
不是用的欧氏距离去衡量两向量之间的距离,而是使用两向量之间的夹角来衡量两向量之间的距离。
在书中,我们假设查询 x x x和键 x i x_i xi长度都为 d d d,并且查询和键的每个元素都是相互独立的,所以有: E ( x ) = [ 0 ] d × 1 , E ( x i ) = [ 0 ] d × 1 E(x)=[0]_{d\times 1},E(x_i)=[0]_{d\times 1} E(x)=[0]d×1,E(xi)=[0]d×1。
此时 x x x的大小为:
∣ x ∣ = x T × x = x 1 2 + x 2 2 + ⋯ + x d 2 \begin{split} \left| x\right|=&\sqrt{x^T\times x} \\=&\sqrt{x_1^2+x_2^2+\cdots+x_d^2} \end{split} ∣x∣==xT×xx12+x22+⋯+xd2
E ( ∣ x ∣ 2 ) = E ( x T × x ) = d \begin{split} E({\left| x\right|}^2)=&E(x^T\times x) \\=&d \end{split} E(∣x∣2)==E(xT×x)d
但是并不能说此时 x x x的大小均值为 d \sqrt{d} d。举个例子:
x ∼ U ( 1 , 3 ) E ( x ) = 2 E ( x ) = 3 3 − 1 3 E ( x 2 ) = 13 3 ≠ 4 \begin{split} x\sim& U(1,3)\\ E(x)=&2\\ E(\sqrt{x})=&\frac{3\sqrt{3}-1}{3}\\ E(x^2)=&\frac{13}{3}\neq 4 \end{split} x∼E(x)=E(x)=E(x2)=U(1,3)2333−1313=4
Bahdanau注意力机制
从表达式中看,查询使用了解码器的输出,键值都是编码器的输出,也就是:
x = D e c o d e r ( h t − 1 ) x i = h t y i = h t h t = E n c o d e r ( S o u r c e ) \begin{split} x=&Decoder(h_{t-1}) \\x_i=&h_t \\y_i=&h_t \\h_t=&Encoder(Source) \end{split} x=xi=yi=ht=Decoder(ht−1)hthtEncoder(Source)
对比一下机器翻译模型,也就是用上一时刻的机器翻译输出的字符作为查询,从编码器生成的中间待选 ( x i , y i ) (x_i,y_i) (xi,yi)中选择出最接近的字符作为当前时刻的翻译字符输出。
从直觉上可以感觉出这样生成的翻译结果会更加的连贯。
写不下去了,单独看这个Bahdanau注意力真看不懂,看原论文去了~
参考:
- 博客园:拉格朗日(Lagrange)插值多项式的基函数构造法(详细推导)
- CSDN:概率统计Python计算:自定义连续型分布
- D2L:动手学深度学习