Redis-Cluster集群搭建
Redis-Cluster
redis集群的原理,redis分片是怎么实现的,你们公司redis用在了哪些环境?
笔者回答:reids集群原理:
其实它的原理不是三两句话能说明白的,redis 3.0版本之前是不支持集群的,官方推荐最大的节点数量为1000,至少需要3(Master)+3(Slave)才能建立集群,是无中心的分布式存储架构,可以在多个节点之间进行数据共享,解决了Redis高可用、可扩展等问题。集群可以将数据自动切分(split)到多个节点,当集群中的某一个节点故障时,redis还可以继续处理客户端的请求。
redis分片:
分片(partitioning)就是将你的数据拆分到多个 Redis 实例的过程,这样每个实例将只包含所有键的子集。当数据量大的时候,把数据分散存入多个数据库中,减少单节点的连接压力,实现海量数据存储。分片部署方式一般分为以下三种:
(1)在客户端做分片;这种方式在客户端确定要连接的redis实例,然后直接访问相应的redis实例;
(2)在代理中做分片;这种方式中,客户端并不直接访问redis实例,它也不知道自己要访问的具体是哪个redis实例,而是由代理转发请求和结果;其工作过程为:客户端先将请求发送给代理,代理通过分片算法确定要访问的是哪个redis实例,然后将请求发送给相应的redis实例,redis实例将结果返回给代理,代理最后将结果返回给客户端。
(3)在redis服务器端做分片;这种方式被称为“查询路由”,在这种方式中客户端随机选择一个redis实例发送请求,如果所请求的内容不再当前redis实例中它会负责将请求转交给正确的redis实例,也有的实现中,redis实例不会转发请求,而是将正确redis的信息发给客户端,由客户端再去向正确的redis实例发送请求。
redis用在了哪些环境:
java、php环境用到了redis,主要缓存有登录用户信息数据、设备详情数据、会员签到数据等
一、设计
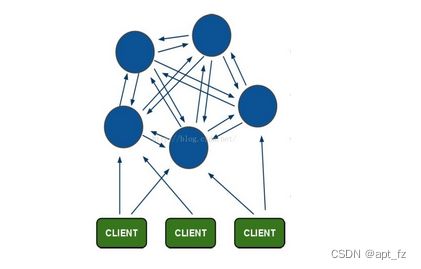
Redis集群搭建的方式有多种,例如使用zookeeper等,但从redis 3.0之后版本支持redis-cluster集群,Redis-Cluster采用无中心结构,每个节点保存数据和整个集群状态,每个节点都和其他所有节点连接。其redis-cluster架构图如下:
二、redis-cluster的优势
1、官方推荐
2、去中心化,集群最大可增加1000个节点,性能随节点增加而线性扩展。
3、管理方便,后续可自行增加或摘除节点,移动分槽等等。
4、简单,易上手。
redis cluster在设计的时候,就考虑到了去中心化,去中间件,也就是说,集群中的每个节点都是平等的关系,都是对等的,每个节点都保存各自的数据和整个集群的状态。每个节点都和其他所有节点连接,而且这些连接保持活跃,这样就保证了我们只需要连接集群中的任意一个节点,就可以获取到其他节点的数据。
Redis 集群没有并使用传统的一致性哈希来分配数据,而是采用另外一种叫做哈希槽 (hash slot)的方式来分配的。
同步原理:
redis cluster 默认分配了 16384 个slot,当我们set一个key 时,会用CRC16算法来取模得到所属的slot,然后将这个key 分到哈希槽区间的节点上,具体算法就是:CRC16(key) % 16384。所以我们在测试的时候看到set 和 get 的时候,直接跳转到了7000端口的节点。
Redis 集群会把数据存在一个 master 节点,然后在这个 master 和其对应的salve 之间进行数据同步。当读取数据时,也根据一致性哈希算法到对应的 master 节点获取数据。只有当一个master 挂掉之后,才会启动一个对应的 salve 节点,充当 master 。
三、redis-cluster架构
1、master 主节点、
2、slave 从节点
3、slot 槽,一共有16384数据分槽,分布在集群的所有主节点中。
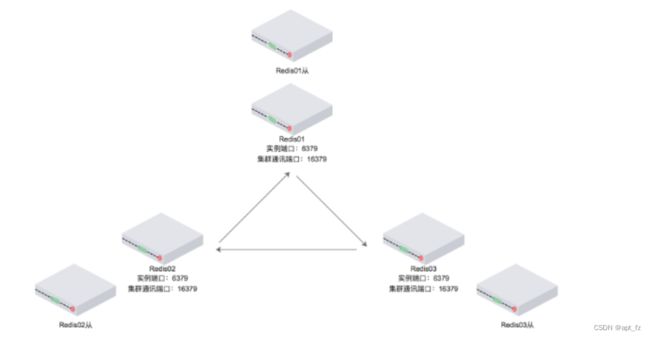
图中描述的是六个redis实例构成的集群
6379端口为客户端通讯端口
16379端口为集群总线端口
集群内部划分为16384个数据分槽,分布在三个主redis中。
从redis中没有分槽,不会参与集群投票,也不会帮忙加快读取数据,仅仅作为主机的备份。
三个主节点中平均分布着16384数据分槽的三分之一,每个节点中不会存有有重复数据,仅仅有自己的从机帮忙冗余。
架构细节:
(1)所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽.
(2)节点的fail是通过集群中超过半数的节点检测失效时才生效.
(3)客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
(4)redis-cluster把所有的物理节点映射到[0-16383]slot上,cluster 负责维护node<->slot<->value
redis-cluster选举:容错
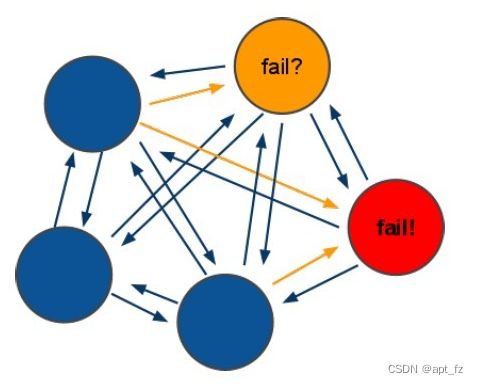
(1) 选举过程是集群中所有master参与,如果半数以上master节点与master节点通信超过(cluster- node-timeout),认为当前master节点挂掉.
(2 )什么时候整个集群不可用(cluster_state:fail),当集群不可用时,所有对集群的操作做都不可用,收到 ((error) CLUSTERDOWN The cluster is down)错误
a:如果集群任意master挂掉,且当前master没有slave.集群进入fail状态,也可以理解成进群的slot映射 [0-16383]不完成时进入fail状态.
b:如果进群超过半数以上master挂掉,无论是否有slave集群进入fail状态.
四、集群部署
搭建redis集群,建议至少需要准备3台服务器,共搭建6个节点,3个master,3个slave,并且要求3个master节点不能全部跑到同一台服务器上,保证节点安全,3台服务器的配置相同,对应的端口是7000/7001/7002端口
环境为三台服务器:centos7.6
集群分配如下,每个节点运行两个端口。第一列做主库,第二列做备库
记得选出控制节点
redis1=192.168.222.130:7000 192.168.222.130:7001 同时也是集群的控制节点
redis2=192.168.222.131:7002 192.168.222.131:7003
redis3=====192.168.222.132:7004 192.168.222.132:7005
1.在安装集群之前,需要在服务器上安装ruby环境,(三台机器相同操作)
因为使用centos的相关的yum源安装ruby安装的版本太低,本次搭建集群所使用的redis版本是6.2.7为官方发布的最新版本,过低版本的ruby不支持该版本的redis节点的安装。
vim /etc/hosts
199.232.28.133 raw.githubusercontent.com #添加信息
curl -sSL https://github.com/rvm/rvm/tarball/stable -o rvm-stable.tar.gz
#本地存在安装包的话以上两步可以不需要,直接上传安装包到相关的安装目录下。
tar -xzvf rvm-stable.tar.gz
mv rvm-stable-xxx rvm
cd rvm
./install --auto-dotfiles
source /usr/local/rvm/scripts/rvm
# 查看rvm可安装版本
rvm list known
# 这里安装3.1.0
rvm install 3.1.0
# 设置默认版本
rvm use 3.1.0 --default
#查看ruby的安装版本
ruby -v
#安装redis接口
gem install redis
2.安装redis (三台机器相同操作)
wget https://download.redis.io/releases/redis-6.2.7.tar.gz
tar -xzf redis-6.2.7.tar.gz
cd redis-6.2.7/src
make install PREFIX=/usr/local/redis
cp redis-6.2.7/redis.conf /usr/local/redis/ #拷贝redis配置文件存放路径
mkdir /usr/local/redis/data #创建存放数据的目录
3.创建节点目录 (三台及其相同操作,注意端口号的不一样)
cd /usr/local/redis/
mkdir redis_cluster
cd redis_cluster #创建集群目录
mkdir 700{0..2} #创建不同端口的redis配置文件的存放目录
cp /usr/local/redis/redis.conf /usr/local/redis/redis_cluster/7000
cp /usr/local/redis/redis.conf /usr/local/redis/redis_cluster/7001
4.修改集群配置文件。(主要是端口和ip,三台机器相同操作)
bind 192.168.3.41 #本机ip,使得三台服务器可相互访问
daemonize yes #redis后台运行
pidfile /var/run/redis_7000.pid # pid文件,**运行多个实例时,需要指定不同的pid文件
port 7000 # 监听端口,**运行多个实例时,需要指定不同的端口
tcp-backlog 511
tcp-keepalive 0
loglevel notice # 日志等级
logfile /var/log/redis_7000.log # 日志文件位置 **运行多实例时,需要修改不同的端口
databases 16 # 可用数据库数
dir /data/application/redis/data #存放数据的目录
#以下可根据实际需要开启和修改相关配置
appendonly yes #redis会把所接收到的每一次写操作请求都追加到appendonly.aof文件中,当redis重新启动时,会从该文件恢复出之前的状态。
appendfilename "appendonly.aof" #AOF文件名称
appendfsync everysec # 表示对写操作进行累积,每秒同步一次
no-appendfsync-on-rewrite yes # AOF 自动重写
auto-aof-rewrite-percentage 80-100 #重写百分比
auto-aof-rewrite-min-size 64mb
#如下为集群配置
cluster-enabled yes #启用集群
cluster-config-file nodes-7000.conf #集群配置文件,由redis自动更新,不需要手动配置,**运行多实例时请注修改为对应端口**
cluster-node-timeout 5000 #集群节点超时时间,即集群中主从节点断开连接时间阈值,超过该值则认为主节点不可以,从节点将有可能转为master
cluster-slave-validity-factor 10 #在进行故障转移的时候全部slave都会请求申请为master,但是有些slave可能与master断开连接一段时间了导致数据过于陈旧,不应该被提升为master。该参数就是用来判断slave节点与master断线的时间是否过长
(计算方法为:cluster-node-timeout * cluster-slave-validity-factor,此处为:5000 * 10 毫秒)
\#cluster-migration-barrier 1
cluster-require-full-coverage yes #集群中的所有slot(16384个)全部覆盖,才能提供服务
可以在一台服务器上面修改好了scp到每台服务器对应的目录下面,然后修改ip和端口还有pid号日志存放文件和配置文件中的cluster-config-file nodes-7000.conf对应不同的端口!**
5.拷贝配置文件 (控制节点操作,拷贝只被控制节点并对应端口目录)
可以在主服务器上面修改好了scp到每台服务器对应的目录下面,然后修改ip和端口还有pid号日志存放文件和配置文件中的cluster-config-file nodes-7000.conf对应不同的端口!**
scp /usr/local/redis/redis_cluster/7000/[email protected]:/usr/local/redis/redis_cluster/7002/
scp /usr/local/redis/redis_cluster/7000/[email protected]:/usr/local/redis/redis_cluster/7003/
scp /usr/local/redis/redis_cluster/7000/[email protected]:/usr/local/redis/redis_cluster/7004/
scp /usr/local/redis/redis_cluster/7000/[email protected]:/usr/local/redis/redis_cluster/7005/
6.启动三台机器上面的每个节点(三台机器相同操作)
控制节点:
cd /usr/local/redis/bin
./redis-server ../redis_cluster/7000/redis.conf
./redis-server ../redis_cluster/7001/redis.conf
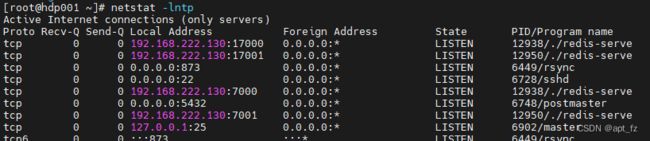
被控制节点;
cd /usr/local/redis/bin
./redis-server ../redis_cluster/7002/redis.conf
./redis-server ../redis_cluster/7003/redis.conf
./redis-server ../redis_cluster/7004/redis.conf
./redis-server ../redis_cluster/7005/redis.conf


7.创建集群(在控制节点上面操作即可,剩余机器不用操作)
注意:由于redis.conf文件使用的都是相对路径,并且生成的一些文件,如aof文件是不能覆盖重复的,因此标准的开启redis-server的操作是,进入到7000/7001/7002等目录中执行,…/redis-server redis.conf,这样各个实例生成的文件就在各自的目录下,互不干扰;当然如果修改redis.conf的配置文件目录,则可以实现在不同的目录下执行redis-server,这个可以灵活掌握和运用
redis节点搭建起来后,需要完成redis cluster集群搭建,搭建集群过程中,需要保证6个redis实例都是运行状态。
Redis是根据IP和Port的顺序,确定master和slave的,所以要排好序,再执行。
输出如下:
cd redis-6.2.7/src
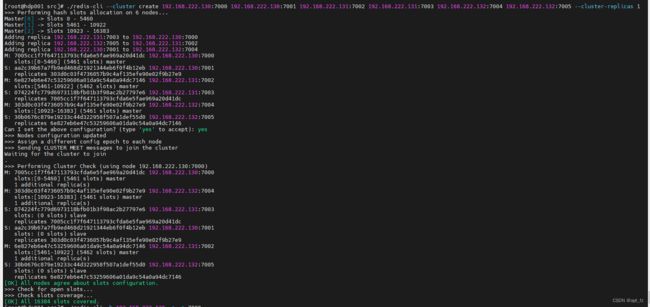
./redis-trib.rb create --replicas 1 192.168.222.130:7000 192.168.222.130:7001 192.168.222.131:7002 192.168.222.131:7003 192.168.222.132:7004 192.168.222.132:7005
#以上步骤为低版本redis集群启动命令,本次我们使用的6.2.7版本搭建的需使用以下新的集群启动命令
cd /usr/local/redis/bin
./redis-cli --cluster create 192.168.222.130:7000 192.168.222.130:7001 192.168.222.131:7002 192.168.222.131:7003 192.168.222.132:7004 192.168.222.132:7005 --cluster-replicas 1
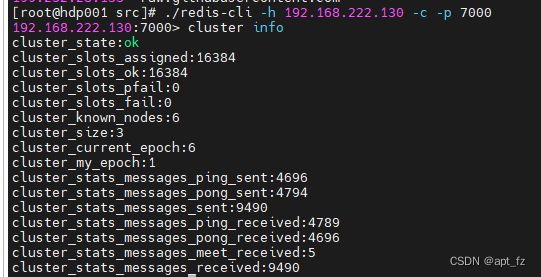
8.查看集群状态可连接集群中的任一节点,此处连接了集群中的节点192.168.222.130:7000
登录集群客户端,-c标识以集群方式登录 cluster info
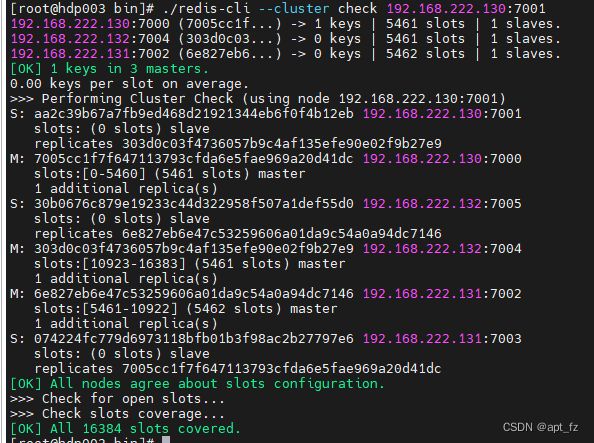
检查集群状态:任意服务器都可以检查
./redis-cli --cluster check 192.168.222.130:7001
测试连接数据库查询数据:
连接集群中的节点 ./redis-cli -h 192.168.222.130 -c -p 7000 输入 set redis cluster
连接集群的其他一个节点 ./redis-cli -h 192.168.222.131 -c -p 7003 输入 get redis
192.168.222.130:7000> set redis cluster
OK
192.168.222.130:7000>
192.168.222.131:7003> get redis
-> Redirected to slot [1151] located at 192.168.222.130:7000
"cluster"
192.168.222.130:7000>
9.设置集群开机启动
入 get redis
192.168.222.130:7000> set redis cluster
OK
192.168.222.130:7000>
192.168.222.131:7003> get redis
-> Redirected to slot [1151] located at 192.168.222.130:7000
"cluster"
192.168.222.130:7000>
9.设置集群开机启动
集群开机启动没有统一化的命令,需根据实际情况编写shell脚本,根据设计的redis端口进行统一的启停。