Elasticsearch 8.X 可以按照数组下标取数据吗?
1、线上环境问题
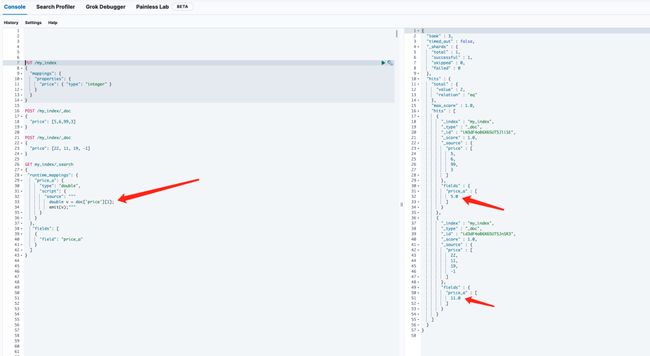
老师、同学们,有人遇到过这个问题么,索引中有一个 integer 数组字段,然后通过脚本获取数组下标为1的值作为运行时字段,发现返回的值是乱的,并不是下标为1的值, 具体如下:
DELETE my_index
PUT my_index
{
"mappings": {
"properties": {
"price": {
"type": "integer"
}
}
}
}
POST /my_index/_doc
{
"price": [
5,
6,
99,
3
]
}
POST /my_index/_doc
{
"price": [
22,
11,
19,
-1
]
}GET my_index/_search
{
"runtime_mappings": {
"price_a": {
"type": "double",
"script": {
"source": """
double v = doc['price'][1];
emit(v);
"""
}
}
},
"fields": [
{
"field": "price_a"
}
]
}是不是因为doc value存储的结果是乱序的?
结果为:
 ——问题来自技术交流群
——问题来自技术交流群
2、问题分析
2.1 Elasticsearch 数组是如何存取的?
在 Elasticsearch 中,数组并不是一种特殊的数据类型。
当你在JSON文档中有一个数组字段并将其索引到Elasticsearch时,Elasticsearch会将数组中的每个元素当作独立的值进行索引,但它不会存储数组的结构或顺序信息。
例如,假设你有以下文档:
{
"tags": ["A", "B", "C"]
}Elasticsearch会像你分别为文档添加了三个标签"A"、"B"和"C"一样对待它。
数组字段(和许多其他字段类型)在 Elasticsearch 中主要是通过Doc Values来存储的。
Doc Values 是一种优化的、磁盘上的、列式数据结构,它们使得对字段的排序和聚合变得非常快速和高效。
但是,列式存储并不保留原始数据的顺序,这就是为什么数组在 Elasticsearch中会丢失其原始顺序的原因。
2.2 访问数组数据
当你在脚本或查询中访问数组字段时,例如 doc['tags'],你实际上得到的是一个值列表。
即使原始数组只有一个值,你也会得到一个值列表。因此,通常需要检查其.size( )并通过.value或具体的索引来访问特定的值。
2.3 数组与嵌套文档类型 Nested
尽管数组不保留顺序,但 Elasticsearch 提供了一种 nested 数据类型,可以让你索引数组中的对象,并保持它们之间的关系。
这对于复杂的对象数组非常有用,但同时也带来了一些复杂性,如使用特定的 nested 查询和聚合。
3、如何获取指定下标的数据?
3.1 方案一、微小改动。
#### 删除索引
DELETE my_index
#### 创建索引
PUT my_index
{
"mappings": {
"properties": {
"price": {
"type": "integer"
}
}
}
}
#### 导入数据
POST /my_index/_doc
{
"price": [
5,
6,
99,
3
]
}
POST /my_index/_doc
{
"price": [
22,
11,
19,
-1
]
}#### 创建预处理管道
PUT _ingest/pipeline/split_array_pipeline
{
"description": "Splits the price array into individual fields",
"processors": [
{
"script": {
"source": """
if (ctx.containsKey('price') && ctx.price instanceof List && ctx.price.size() > 0) {
for (int i = 0; i < ctx.price.size(); i++) {
ctx['price_' + i] = ctx.price[i];
}
}
"""
}
}
]
}split_array_pipeline 预处理管道的含义:
description:
描述该管道的目的。在这个案例中,我们说明这个管道的目的是将price数组分解为单独的字段。
processors:
是一个处理器数组,每个处理器都完成一个特定的任务。在这里,我们只有一个script处理器。
在 script 处理器中,我们编写了一个小脚本,检查是否存在一个名为 price 的字段,该字段是否是一个数组,以及数组是否至少有一个元素。如果所有这些条件都满足,脚本会遍历数组并为数组中的每个元素创建一个新字段。新字段的名称将是 price_0、price_1等,其中的数字是数组的索引。
这种预处理管道非常有用,特别是当原始数据格式不适合直接索引到 Elasticsearch 时。通过使用预处理管道,我们可以在索引数据之前对其进行所需的转换或清理。
POST my_index/_update_by_query?pipeline=split_array_pipeline
{
"query": {
"match_all": {}
}
}
GET my_index/_search
{
"runtime_mappings": {
"price_a": {
"type": "double",
"script": {
"source": """
if (doc['price_0'].size() > 0) {
double v = doc['price_0'].value;
emit(v);
}
"""
}
}
},
"fields": [
{
"field": "price_a"
}
]
}运行时字段(Runtime Fields)。运行时字段是 7.12 版本后引入的功能,允许你定义临时字段,这些字段的值是在查询时通过脚本计算的,而不是在索引时预先存储的。
如上代码中:
我们定义了一个名为 price_a 的新运行时字段。字段类型为 double。
我们提供了一个Painless 脚本,用于计算此字段的值。
脚本解读:
if (doc['price_0'].size() > 0):
这检查price_0字段是否存在并且有值。在Elasticsearch的脚本中,doc['field_name']表示获取该字段的值,.size()方法用于检查该字段是否有值(在某些文档中,该字段可能不存在或为空)。
double v = doc['price_0'].value;:
如果上面的条件为真,这行代码会从price_0字段中取出值,并将其转换为double类型。
emit(v);:
这是Painless脚本的关键指令。它将指定的值输出为运行时字段price_a的值。
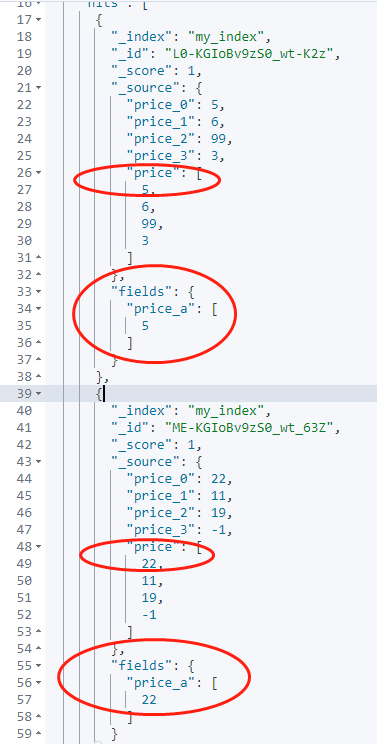
执行结果如下,结果已经达到预期。
3.2 方案二:Nested 实现
Nested 嵌套数据类型,咱们之前文章多次讲过,不明白的同学可以翻看一下历史文章。
### 定义索引
PUT /my_nested_index
{
"mappings": {
"properties": {
"prices": {
"type": "nested",
"properties": {
"value": {
"type": "integer"
}
}
}
}
}
}
### 导入数据
POST /my_nested_index/_doc
{
"prices": [
{"value": 5},
{"value": 6},
{"value": 99},
{"value": 3}
]
}
POST /my_nested_index/_doc
{
"prices": [
{"value": 22},
{"value": 11},
{"value": 19},
{"value": -1}
]
}#### 执行检索
GET my_nested_index/_search
{
"query": {
"bool": {
"must": [
{
"nested": {
"path": "prices",
"query": {
"exists": {
"field": "prices.value"
}
},
"inner_hits": {
"size": 1
}
}
}
]
}
}
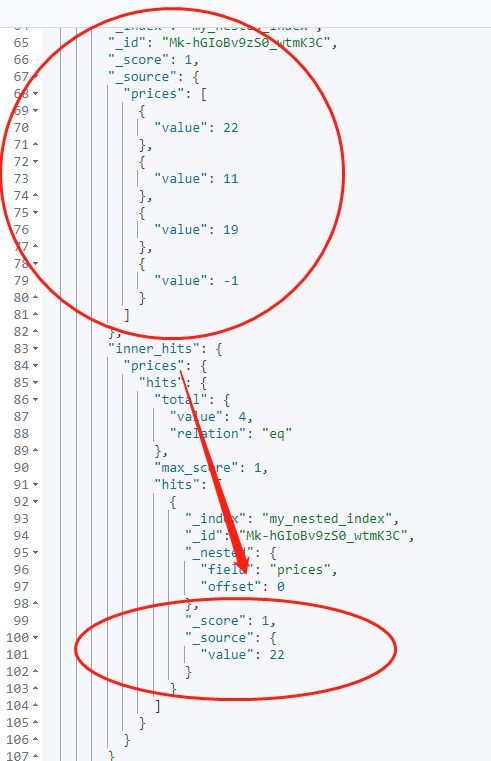
}如果你想只返回 inner_hits 下的第一个数据结果,你可以使用size参数。通过设置size为 1,你可以限制inner_hits返回的结果数量。
返回结果:
4、小结
当我们使用 Elasticsearch 处理数组数据时,很容易误解其实际行为。本文详细探讨了Elasticsearch如何处理和存储数组,并提供了几种获取数组中特定位置元素的方法。
首先,我们必须理解 Elasticsearch 不是以传统的方式存储数组,而是将每个元素视为独立的值。因此,我们不能简单地通过下标直接访问数组中的某个特定元素。
有几种方法可以解决这个问题:
使用预处理管道:通过创建一个预处理管道来分解数组并为每个元素生成一个新字段。这种方法非常直观,允许我们轻松访问任何特定位置的元素。
使用 Nested 数据类型:对于需要保留其元素间关系的复杂数组,Nested数据类型是一个非常有效的选择。这使我们能够对数组中的每个对象执行更复杂的查询,并且能够保留它们之间的关系。
这两种方法都有其优点和缺点。选择哪一种方法取决于你的具体需求和数据结构。预处理管道方案适用于那些希望保持数据的简单性并能够直接访问数组元素的场景。而 Nested 数据类型则适用于那些需要在数组对象之间维护关系的更复杂的场景。
在任何情况下,理解你的数据结构和 Elasticsearch 如何处理它是至关重要的。希望通过这篇文章,你对Elasticsearch的数组处理有了更深入的理解,并能够更有效地解决与数组相关的问题。
最后,不管你选择哪种方法,都要确保经常测试和验证数据的完整性和准确性。这样,你就可以确保在生产环境中得到预期的结果,避免因为数据结构的误解而产生的潜在问题。
推荐阅读
全网首发!从 0 到 1 Elasticsearch 8.X 通关视频
重磅 | 死磕 Elasticsearch 8.X 方法论认知清单
如何系统的学习 Elasticsearch ?
2023,做点事
干货 | Elasticsearch Nested类型深入详解
Elasticsearch Nested 选型,先看这一篇!
干货 | Elasticsearch Nested 数组大小求解,一网打尽!
Elasticsearch 有没有数组类型?有哪些坑?
干货 | 拆解一个 Elasticsearch Nested 类型复杂查询问题

更短时间更快习得更多干货!
和全球 近2000+ Elastic 爱好者一起精进!

一个人可以走得很快,但一群人走得更远!