面向深度神经网络的特定领域架构
随着AI对算力的需求不断增长,以TPU为代表的面向DNN的特定领域架构为DNN计算提供了几十倍的性能提升以及能效优化。本文基于谷歌真实业务场景数据,介绍了TPU相对CPU/GPU的实际性能、能效指标。原文: A Domain-Specific Architecture for Deep Neural Networks
摩尔定律的终结使人们意识到特定领域架构才是计算的未来。谷歌的张量处理单元(TPU)就是一个开创性的例子,自从2015年首次部署以来,已经为超过10亿人提供了服务。TPU运行深度神经网络(DNN)的速度比同时代CPU和GPU要快15到30倍,能效比同类技术的CPU和GPU高30到80倍。
所有指数定律都有终结的时候[26]。
1965年,Gordon Moore预测芯片的晶体管数量将每一两年翻一番。尽管Communications杂志2017年1月的封面报道认为:"关于摩尔定律死亡的报道被大大夸大了",但摩尔定律确实正在终结。2014年推出的DRAM芯片包含80亿个晶体管,而160亿个晶体管的DRAM芯片要到2019年才量产,但摩尔定律预测DRAM芯片的规模应该会扩大4倍。2010年的英特尔至强E5微处理器有23亿个晶体管,而2016年的至强E5有72亿个晶体管,与摩尔定律相差2.5倍。半导体技术仍然在继续演进,但比过去慢很多。
另一个没那么出名但同样重要的观察是Dennard Scaling。Robert Dennard在1974年发现,当晶体管变小时,功率密度是不变的。如果晶体管的线性尺寸缩小2倍,那就可以提供4倍的晶体管数量。如果电流和电压也都缩小2倍,那么功率就会下降4倍,从而在相同频率下得到相同的功率。Dennard Scaling在首次被观察到30年后就结束了,不是因为晶体管没有继续缩小,而是因为电流和电压无法在保证可靠的情况下不断下降。
计算机架构师们利用摩尔定律和Dennard Scaling通过增加资源、采用复杂的处理器设计和内存层次结构,提高指令的并行性,从而在程序员不知情的情况下提升了性能。不幸的是,架构师们最终耗尽了可以有效利用的指令级并行性。2004年,Dennard Scaling的结束和缺乏更多(有效的)指令级并行性,迫使业界从单核处理器芯片转向多核处理器。
重要见解
- 虽然TPU是特定应用集成电路,但通过支持基于TensorFlow框架编程的神经网络,用以驱动谷歌数据中心的许多重要应用,包括图像识别、语言翻译、搜索和游戏。
- 通过利用专门用于神经网络的芯片资源,TPU在全球超过10亿人日常使用的实际数据中心工作负载上比通用计算机提高了30-80倍的性能。
- 神经网络推理阶段通常需要服从严格的响应时间限制,这降低了通用计算机技术的有效性,这些计算机通常运行速度较快,但在某些情况下性能不佳。
Gene Amdahl在1967年提出的一个观点现在来看仍然正确,这一观点说明增加处理器数量带来的收益会逐渐递减。Amdahl定律说,并行化的理论速度提升受到任务顺序部分的限制,如果任务的1/8是串行的,即使其余部分很容易并行,而且架构师增加能够增加100个处理器,其速度提升最多是原来性能的8倍。
图1显示了过去40年里这三个定律对处理器性能的影响。按照目前的速度,标准处理器基准性能在2038年前不会翻倍。
 图1. 按照Hennessy和Patterson[17]的说法,我们绘制了过去40年32位和64位处理器内核每年最高SPECCPUint性能;面向吞吐量的SPECCPUint_rate也反映了类似的情况,并在几年后逐渐平稳。
图1. 按照Hennessy和Patterson[17]的说法,我们绘制了过去40年32位和64位处理器内核每年最高SPECCPUint性能;面向吞吐量的SPECCPUint_rate也反映了类似的情况,并在几年后逐渐平稳。
由于晶体管技术没有多大进步(反映了摩尔定律的终结),每平方毫米芯片面积的峰值功率在增加(由于Dennard Scaling的终结),但每芯片功率预算没有增加(由于电迁移和机械及热限制),而且芯片设计师已经转向多核(受Amdahl定律的限制),架构师们普遍认为在性能-成本-能耗方面进行重大改进的唯一途径是特定领域架构[17]。
云上大型数据集和为其提供动力的众多计算机之间的协作使机器学习取得了显著进步,特别是在DNN方面。与其他领域不同,DNN具有广泛的适用性。DNN的突破包括将语音识别的单词错误率相对传统方法降低了30%,这是20年来最大的进步[11]; 将2011年以来进行的图像识别比赛的错误率从26%降低到3.5%[16][22][34]; 在围棋中击败人类冠军[32]; 提高搜索排名; 等等。虽然DNN架构只能适用于某个较小的领域,但仍然有许多应用。
神经网络以类似大脑的功能为目标,基于简单的人工神经元: 基于非线性函数(例如 )及其输入的加权和(weighted sum of the inputs)。这些人工神经元按层组织,一个层的输出成为下一层的输入,DNN的"深度"部分就来自于多层的处理。因为云上大型数据集允许通过使用额外的更大的层来捕捉更高层次的模式或概念来建立更精确的模型,而GPU能够提供足够的算力来开发这些模型。
DNN的两个阶段被称为训练(或学习)和推理(或预测),类似于开发和生产。训练DNN一般需要几天时间,但训练好的DNN可以在几毫秒内完成推理或预测。开发者选择层数和DNN类型(见"深度神经网络的类型"),训练决定权重。几乎所有训练都是以浮点方式进行的,这也是GPU在训练中如此受欢迎的原因之一。
深度神经网络的类型
目前有三种DNN在谷歌数据中心很受欢迎:
- 多层感知器(MLP, Multi-layer perceptron) 。对于多层感知器,每个新层都是一组由先前所有输出(完全连接)的加权和组成的非线性函数;
- 卷积神经网络(CNN, Convolutional neural network) 。在卷积神经网络中,后面的每个层是一组来自前一层输出的空间上邻近的子集的加权和的非线性函数,权重在空间上重复使用; 以及
- 循环神经网络(RNN), Recurrent neural network) 。对于RNN,每个后续层是前一层状态的加权和的非线性函数的集合。最流行的RNN是长短期记忆(LSTM, long short-term memory),LSTM的艺术在于决定要忘记什么,以及把什么作为状态传递到下一层。权重在不同步骤中被重复使用。
一个被称为"量化(quantization)"的步骤将浮点数转化为足以用于推理的窄整数(通常只有8位)。与IEEE 754的16位浮点乘法相比,8位整数乘法所需能耗和芯片面积可减少6倍,而整数加法的优势是能耗减少13倍,面积减少38倍[10]。
表1针对三种类型的DNN分别例举了两个例子,代表了2016年谷歌数据中心95%的DNN推理工作量,我们将其作为基准。这些DNN通常是用TensorFlow编写的[1],代码很短,只有100到1500行。这些例子代表了在主机服务器上运行的较大应用程序的小组件,这些应用程序可能是数千到数百万行的C++代码,通常是面向最终用户的,从而需要严格的响应时间限制。
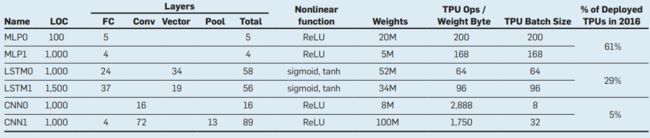 表1. 截至2016年7月,6个DNN应用(每种DNN类型2个应用)代表了TPU 95%的工作量。列是DNN名称; 代码行数; DNN类型和层数; FC是全连接; Conv是卷积; Vector是二进制运算; Pool是pooling,在TPU上做非线性裁剪; 非线性函数; 权重数; 运算强度; 批量大小; 以及截至2016年7月的TPU应用普及度。多层感知器(MLP)是RankBrain[9]; 长短时记忆(LSTM)是GNM Translate的一个子集[37]; 卷积神经网络(CNN)是Inception和DeepMind AlphaGo[19][32]。ReLU代表Rectified Linear Unit,是函数 。
表1. 截至2016年7月,6个DNN应用(每种DNN类型2个应用)代表了TPU 95%的工作量。列是DNN名称; 代码行数; DNN类型和层数; FC是全连接; Conv是卷积; Vector是二进制运算; Pool是pooling,在TPU上做非线性裁剪; 非线性函数; 权重数; 运算强度; 批量大小; 以及截至2016年7月的TPU应用普及度。多层感知器(MLP)是RankBrain[9]; 长短时记忆(LSTM)是GNM Translate的一个子集[37]; 卷积神经网络(CNN)是Inception和DeepMind AlphaGo[19][32]。ReLU代表Rectified Linear Unit,是函数 。
如表1所示,每个模型需要500万到1亿权重,需要消耗大量时间和资源来访问(参见"能耗比例")。为了分摊访问成本,推理或训练期间,通过在独立示例之间重用相同的权重从而提高性能。
能耗比例(Energy Proportionality)
热设计功率(TDP, Thermal design power)影响到电源供应成本,数据中心必须在硬件满功率运行时才能提供足够的电力和制冷。然而由于一天中的工作负荷并不相同,电力成本是基于平均消耗的。Barroso和Hölzle[4]发现服务器只有在不到10%的时间里是100%繁忙的,因此提出了能耗比例,认为服务器耗电量应与工作量成正比。图4中对能耗的估计基于谷歌数据中心TDP的一部分。由于工作负载利用率不同,我们测量了运行生产程序CNN0的三台服务器的性能和功率,然后基于服务器芯片数量将其归一化。
上图显示,TPU功率最低,每芯片40W,但能耗比例很差(谷歌TPU设计时间较短,无法纳入许多节能功能)。Haswell CPU在2016年有最好的能耗比例。在TPU-Haswell组合系统中,CPU的工作量减少了,因此CPU功率也减少了。因此,Haswell服务器加上四个低功耗TPU使用不到20%的额外功率,但因为有四个TPU和两个CPU,运行CNN0比单独的Haswell服务器快80倍。
TPU的起源、架构和实现
早在2006年开始,谷歌就考虑在其数据中心部署GPU、现场可编程门阵列(FPGA, , field programmable gate array)或特定应用集成电路(ASIC, application-specific integrated circuit)。结论是,少数可以在特殊硬件上运行的应用可以利用谷歌大型数据中心的过剩容量免费实现,而且很难在此基础上有所改进。这种情况在2013年发生了变化,当时有一个预测,即谷歌用户每天使用3分钟基于语音识别DNN的语音搜索,使谷歌数据中心的计算需求增加了一倍,因此使用传统CPU将会非常昂贵。于是谷歌启动了一个高优先级项目,快速生产用于推理的定制芯片,并购买现成的GPU用于训练,其目标是将性价比提高10倍。由于这一任务,只花了15个月的时间就完成了TPU的设计、验证、制造和部署。
为了降低延迟部署的风险,谷歌工程师将TPU设计成I/O总线上的协处理器,而没有与CPU紧密集成,使其能够像GPU一样插入现有服务器中。此外,为了简化硬件设计和调试,主机服务器向TPU发送指令供其执行,而不是自己获取。因此,TPU在概念上更接近浮点单元(FPU, floating-point unit)协处理器,而不是GPU。
谷歌工程师从系统角度优化了设计。为了减少与主机CPU的互动,TPU运行整个推理模型,但不止支持2013年的DNN,还提供了匹配2015年及以后的DNN的灵活性。
图2是TPU的框图。TPU指令通过PCIe Gen3 x16总线从主机发送至指令缓冲区,内部块通常由256字节宽的路径连接在一起。从右上角开始,矩阵乘法单元是TPU的核心,有256×256个MAC,可以对有符号或无符号整数进行8位乘法和加法。16位的乘积被收集在矩阵单元下面的4M字节32位累加器中,4M代表4,096个256元素的32位累加器。矩阵单元每周期产生一个256元素的部分和。
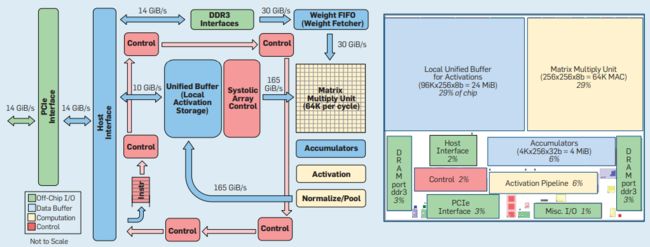 图2. TPU框图和平面布置图。主要计算部分是黄色的矩阵乘法单元,它的输入是蓝色的带权重FIFO和蓝色的统一缓冲器,输出是蓝色的累加器。黄色的激活单元执行非线性功能。右边的TPU芯片平面图显示蓝色存储器占35%,黄色计算单元占35%,绿色I/O占10%,红色控制只占芯片的2%。在CPU或GPU中,控制部分要大得多(而且更难设计)。
图2. TPU框图和平面布置图。主要计算部分是黄色的矩阵乘法单元,它的输入是蓝色的带权重FIFO和蓝色的统一缓冲器,输出是蓝色的累加器。黄色的激活单元执行非线性功能。右边的TPU芯片平面图显示蓝色存储器占35%,黄色计算单元占35%,绿色I/O占10%,红色控制只占芯片的2%。在CPU或GPU中,控制部分要大得多(而且更难设计)。
矩阵单元权重通过片上"权重FIFO"分阶段进行,该FIFO从我们称之为"权重存储器"的片外8GB字节DRAM读取。对于推理,权重是只读的,8GB字节支持许多同时活跃的模型。权重FIFO的深度为4层,中间结果被保存在24M字节的片上"统一缓冲区"中,可以作为矩阵单元的输入。可编程DMA控制器将数据传入或传出CPU主机存储器和统一缓冲区。为了能够在大规模可靠部署,内外部存储器内置了硬件错误检测和纠正功能。
TPU微架构背后的理念是让矩阵单元保持忙碌。为了达到这个目的,读取权重的指令遵循解耦访问/执行的理念[33],因此可以在发送地址后以及从权重存储器获取权重前完成。如果没有活跃输入或权重数据没有准备好,矩阵单元将暂停执行。
由于读取大型静态随机存取存储器(SRAM, static random-access memory)比计算的能耗更大,矩阵单元通过"收缩执行(systolic execution)",即通过减少统一缓冲区的读写来节省能耗[23],因此依赖不同来源的数据以固定时间间隔到达阵列单元,并将其合并。体现为给定65,536个元素的向量矩阵乘法操作以对角线波阵的形式在矩阵中移动。权重被预先加载,并随着新区块的第一个数据的推进波生效。控制和数据是流水线式的,这给程序员一种错觉,即256个输入被一次性读取,并立即更新256个累加器中的一个位置。从正确性的角度来看,软件不知道矩阵单元的收缩性,但为了性能,必须考虑单元的延迟。
TPU软件堆栈必须与那些为CPU和GPU开发的软件兼容,以便应用程序可以快速移植到TPU上。在TPU上运行的那部分应用程序通常是用TensorFlow编写的,并被编译成可以在GPU或TPU上运行的API[24]。
CPU, GPU, TPU平台
大多数架构研究论文都基于模拟运行小型、容易移植的基准测试,预测可能的性能。本文不是这样,而是对2015年以来在数据中心运行的真实大型生产工作负载的机器进行回顾性评估,其中一些机器由超过10亿人常规使用。如表1所示,这6个应用代表了2016年TPU数据中心95%的使用量。
由于我们要测量的是生产工作负载,所以比较的基准平台也必须可以部署在谷歌数据中心,和生产工作负载运行环境一致。谷歌数据中心的大量服务器和大规模应用的可靠性要求意味着机器必须至少能对内存错误做出检查。由于Nvidia Maxwell GPU和最近的Pascal P40 GPU不检查内部内存错误,因此没法满足谷歌大规模部署的严格可靠性要求。
表2显示了部署在谷歌数据中心的服务器,用于与TPU进行比较。传统CPU服务器的代表是英特尔的18核双插槽Haswell处理器,这个平台也是GPU或TPU的主机服务器,谷歌工程师在服务器中使用四个TPU芯片。
 表2. 基准服务器采用Haswell CPU、K80 GPU和TPU。Haswell有18个核心,K80有13个处理器,GPU和TPU使用Haswell服务器作为主机。芯片工艺单位是nm。TDP代表热设计功率; TOPS/s是 次操作/秒; 内存带宽是GB/s。TPU芯片的大小不到Haswell芯片的一半。
表2. 基准服务器采用Haswell CPU、K80 GPU和TPU。Haswell有18个核心,K80有13个处理器,GPU和TPU使用Haswell服务器作为主机。芯片工艺单位是nm。TDP代表热设计功率; TOPS/s是 次操作/秒; 内存带宽是GB/s。TPU芯片的大小不到Haswell芯片的一半。  表3. 2015年至2017年,Nvidia GPU发布与云计算部署之间的差距[5][6]。GPU的世代是Kepler、Maxwell、Pascal和Volta。
表3. 2015年至2017年,Nvidia GPU发布与云计算部署之间的差距[5][6]。GPU的世代是Kepler、Maxwell、Pascal和Volta。
一些计算机架构师对于从公布产品直到芯片、板卡和软件都准备好并能可靠服务于数据中心客户所需要的时间没有概念。表3指出,从2014年到2017年,商业云公司部署GPU的时间差是5到25个月。因此,与2015年的TPU相比,对应的GPU显然是Nvidia K80,它采用相同的半导体工艺,并在TPU部署前六个月发布。
每块K80卡包含两个芯片,并在内部存储器和DRAM上内置了错误检测和纠正功能。每台服务器最多可以安装8个K80芯片,这就是我们的基准配置。CPU和GPU都使用大型芯片封装,大约为600 ,是Core i7的三倍。
性能: Roofline模型, 响应时间, 吞吐量
为了说明上述6个应用在3类处理器上的性能,我们采用了高性能计算(HPC, high-performance computing)中的Roofline性能模型[36]。虽然不是完美的视觉模型,但可以洞察到性能瓶颈的原因。该模型背后的假设是,应用不适合在片上缓存,所以要么计算受限,要么内存带宽受限。对于HPC来说,Y轴是每秒浮点运算的性能,因此峰值计算率构成了屋顶的平坦部分。X轴是计算强度(operational intensity),以每个浮点操作访问的DRAM字节来衡量。由于(FLOPS/s)/(FLOPS/Byte)=Bytes/s,因此内存带宽的单位是字节/秒,从而构成屋顶的斜面部分。如果没有足够的计算强度,程序就会受到内存带宽的限制,停留在屋顶的斜面部分。
应用实际的每秒操作数与其上限之间的差距显示了在不触及计算强度的情况下进一步调整性能的潜在好处,增加计算强度的优化(如缓存模块化)可能会实现更好的性能。
为了将Roofline模型应用于TPU,当DNN应用被量化时,首先用整数运算取代浮点运算。由于权重通常不适用于DNN应用的片上存储器,第二个变化是重新定义计算强度为每字节读取权重的整数乘积操作,如表1所示。
图3显示了TPU、CPU和GPU在对数尺度上的单芯片Roofline模型。TPU的屋顶有很长的倾斜部分,计算强度意味着性能受限于内存带宽,而不是峰值计算量。6个应用中有5个无法触及上线,MLP和LSTM受内存限制,而CNN受计算限制。
 图3. TPU、CPU和GPU的Roofline合并成一个对数图。星形代表TPU,三角形代表K80,圆形代表Haswell。所有TPU的星星都处于或高于其他两个Roofline。
图3. TPU、CPU和GPU的Roofline合并成一个对数图。星形代表TPU,三角形代表K80,圆形代表Haswell。所有TPU的星星都处于或高于其他两个Roofline。
与图3的TPU相比,6个DNN应用普遍低于其在Haswell和K80的上限,原因是由于响应时间。这些DNN应用中有许多是面向终端用户服务的,研究人员已经证明,即使是响应时间的小幅增加也会导致客户减少使用服务。虽然训练可能没有严格的响应时间限制,但推理通常会有,或者说推理更倾向于延迟而不是吞吐量[28]。
例如,按照应用开发者的要求,MLP0的P99响应时间限制为7ms。(每秒的推理和7ms的延迟包含服务器主机和加速器的执行时间)。如果放宽响应时间限制,Haswell和K80的运行速度分别只有MLP0可实现的最高吞吐量的42%和37%。这些限制也影响到了TPU,但在80%的情况下,其运行速度更接近TPU的最大MLP0吞吐量。与CPU和GPU相比,单线程TPU没有任何复杂的微架构特性,这些特性消耗晶体管和能量来改善平均情况,但不是99%的情况。也就是说,没有缓存、分支预测、失序执行、多处理、投机预取、地址凝聚、多线程、上下文切换等等。极简主义是特定领域处理器的一大美德。
表4显示了每个芯片的相对推理性能的底线,包括两个加速器与CPU的主机服务器开销,显示了6个DNN应用的相对性能加权平均值,表明K80芯片的速度是Haswell芯片的1.9倍,而TPU芯片的速度是其29.2倍,因此TPU芯片的速度是GPU芯片的15.3倍。
 表4. K80 GPU芯片和TPU芯片相对于CPU的DNN工作负载性能。加权平均值基于表1中6个应用的实际组合。
表4. K80 GPU芯片和TPU芯片相对于CPU的DNN工作负载性能。加权平均值基于表1中6个应用的实际组合。
性能开销(Cost-Performance), TCO, 每瓦性能(Performance/Watt)
当购买大量计算机时,性能开销胜过性能。数据中心的最佳成本指标是总拥有成本(TCO, total cost of ownership)。如谷歌这样的组织为成千上万的芯片支付的实际价格取决于相关公司之间的谈判,由于商业机密的原因,我们无法公布这类价格信息或可能用于推导这类信息的数据。然而,功率与总拥有成本相关,而且我们可以公布每台服务器的功率,所以我们在这里使用每瓦性能(performance/Watt)作为性能/TCO的代表。我们在本节中比较了整个服务器,而不是单个芯片。
图4显示了K80 GPU和TPU相对于Haswell CPU的平均每瓦性能。我们提出了两种不同的每瓦性能计算方法。第一种"总量",在计算GPU和TPU的每瓦性能时包含主机CPU服务器消耗的功率。第二种"增量",从GPU和TPU中减去主机CPU服务器的功率。
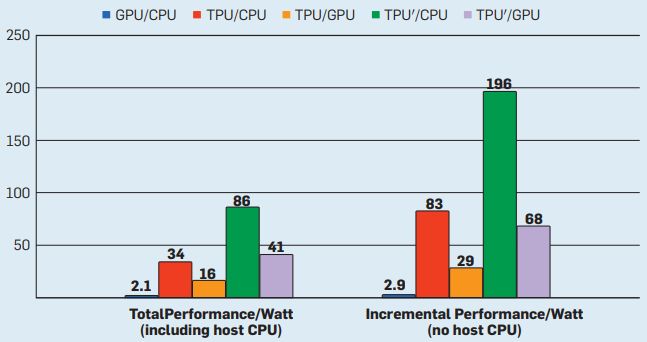 图4. GPU(蓝色)、TPU(红色)与CPU的相对每瓦性能,以及TPU与GPU(橙色)的相对每瓦性能(TDP)。TPU′是使用K80的GDDR5内存的改进型TPU。绿色条显示了改进后的TPU与CPU的每瓦性能比率,淡紫色条显示了与GPU的比率。总量包含主机服务器功率,增量不包含主机功率。
图4. GPU(蓝色)、TPU(红色)与CPU的相对每瓦性能,以及TPU与GPU(橙色)的相对每瓦性能(TDP)。TPU′是使用K80的GDDR5内存的改进型TPU。绿色条显示了改进后的TPU与CPU的每瓦性能比率,淡紫色条显示了与GPU的比率。总量包含主机服务器功率,增量不包含主机功率。
就每瓦总性能而言,K80服务器是Haswell的2.1倍。就每瓦增量性能而言,如果忽略Haswell服务器的功率,K80服务器是Haswell的2.9倍。TPU服务器的每瓦总性能比Haswell高34倍,使得TPU服务器的每瓦性能是K80服务器的16倍。TPU的相对每瓦增量性能(谷歌定制ASIC的理由)是83倍,从而使TPU的每瓦性能达到GPU的29倍。
另一种TPU替代方案的评估
与FPU一样,TPU协处理器也比较容易评估,所以我们为6个应用建立了性能模型,模型结果与硬件性能计数器之间的差异平均不到10%。
如果我们有超过15个月的时间,就可以用同样的工艺技术来设计一款新芯片TPU',我们用性能模型来评估这款理论上的芯片。更积极的逻辑合成和模块设计仍然可以将时钟频率提高50%。就像K80那样为GDDR5内存设计一个接口电路,可以将加权内存带宽提高5倍以上,将其roofline最高点从1350降到250。
将时钟速度提高到1050MHz,但不改善内存,这样影响不会太大。而如果我们将时钟速度保持在700MHz,但使用GDDR5(双数据率5型同步图形随机存取存储器)作为加权存储器,加权平均值就会跳到3.9。做到这两点并不改变平均值,所以理论上的TPU'只是拥有更快的内存。
仅仅用K80一样的GDDR5内存替换DDR3加权内存,需要将内存通道的数量增加一倍,达到四个,这一改进将使芯片尺寸扩大约10%。因为每台服务器有四个TPU,GDDR5还将使TPU系统的功率预算从861W增加到大约900W。
图4报告了TPU的每芯片的每瓦相对总性能,比Haswell跃升86倍,比K80跃升41倍。增量指标相对Haswell达到惊人的196倍,相对K80高达68倍。
讨论
本节遵循Hennessy和Patterson的谬误-易犯错误-反驳(fallacy-and-pitfall-with-rebuttal)模式[17]:
谬误(Fallacy)。数据中心的DNN推理应用重视吞吐量和响应时间。 我们感到惊讶的是,由于有人在2014年提出,批量大小足以使得TPU达到峰值性能(或者对延迟要求不那么严格),因此谷歌TPU开发人员对响应时间有着强烈的要求。其中一个驱动应用是离线图像处理,谷歌开发人员的直觉是,如果交互业务也想要TPU,大多数人只会积累更大的批处理。即使到2014年某个关心响应时间的应用(LSTM1)的谷歌开发人员也说,限制是10ms,但在实际移植到TPU时缩减到了7ms。许多这样的服务对TPU的意外需求,加上对快速响应时间的影响和偏好,改变了平衡,应用开发者往往选择减少延迟,而不是等待积累更大的批次。幸运的是,TPU有一个简单、可重复的执行模型,以帮助满足交互业务的响应时间目标,以及高峰值吞吐量,即使是相对较小的批次规模,也能带来比当代CPU和GPU更高的性能。
谬误(Fallacy)。K80 GPU架构非常适合DNN推理。 我们看到5个具体原因,即TPU在性能、能耗和成本方面都比K80 GPU更有优势。首先,TPU只有一个处理器,而K80有13个,用单线程更容易达到严格的延迟目标。其次,TPU有非常大的二维乘法单元,而GPU有13个较小的一维乘法单元。DNN的矩阵乘法强度适合排列在二维阵列中的算术逻辑单元。第三,二维数组还能实现系统化,通过避免寄存器访问来提高能源效率。第四,TPU的量化应用使用K80上不支持的8位整数,而不是GPU的32位浮点数。较小的数据不仅提高了计算的能源效率,而且使加权FIFO的有效容量和加权存储器的有效带宽翻了两番。(这些应用经过训练,尽管只使用8位,却能提供与浮点数相同的精度)。第五,TPU省略了GPU需要但DNN不使用的功能,因此缩小了芯片面积,节省了能源,并为其他升级留出了空间。TPU芯片的尺寸几乎是K80的一半,通常以三分之一的功率运行,但包含3.5倍内存。这五个因素解释了TPU在能源和性能方面30倍的优势。
易犯错误(Pitfall)。在设计特定领域架构时,忽视架构历史。 那些在通用计算中没有成功的想法可能是特定领域架构的理想选择。对于TPU来说,有三个重要的架构特征可以追溯到20世纪80年代初: 收缩阵列(systolic arrays)[23]、解耦访问/执行[33]和复杂指令集[29]。第一个特征减少了大型矩阵乘法单元的面积和功率; 第二个特征在矩阵乘法单元的操作中同时获取权重; 第三个特征更好利用了PCIe总线的有限带宽来传递指令。因此,具有历史意识、特定领域的架构师可以拥有竞争优势。
谬误(Fallacy)。如果谷歌更有效的使用CPU,那么CPU的结果将与TPU相当。 我们最初在CPU上只有一个DNN的8位结果,这是因为需要做大量工作来有效使用高级向量扩展(AVX2)的整数支持,这样做大约能获得3.5倍好处。以浮点方式呈现所有的CPU结果,而不是让一个例外情况有自己的顶线,这样比较不容易混淆(而且需要更少的空间)。如果所有DNN都有类似的加速,每瓦性能将从41-83倍下降到12-24倍。
谬误(Fallacy)。如果谷歌能使用适当的较新版本,GPU的结果将与TPU相匹配。 表3显示了GPU的发布和可以在云端被客户使用之间的时间差异。较新的TPU可以与较新GPU公平比较,而且,只要增加10W,我们就可以通过使用K80的GDDR5内存将28纳米、0.7GHz、40W的TPU的性能提高两倍。将TPU转移到16纳米工艺将进一步提高其每瓦性能。16纳米的Nvidia Pascal P40 GPU的峰值性能是原来TPU的一半,但250W的功率却比原来多出许多倍[15]。如前所述,缺乏错误检查意味着谷歌无法在其数据中心部署P40,因此无法在其上运行生产工作负载以确定其实际相对性能。
相关工作
两篇调查文章证实定制DNN ASIC至少可以追溯到20世纪90年代初[3][18]。正如2016年Communications杂志所介绍的,支持四种DNN体系架构的DianNao家族通过对DNN应用中的内存访问模式提供高效的体系架构支持,最大限度的减少了片上和外部DRAM的内存访问[7][21]。原生DianNao使用64个16位整数乘法累加单元。
 谷歌去年5月推出的TPU 3.0,比2.0强大8倍,性能高达100 petaflops。
谷歌去年5月推出的TPU 3.0,比2.0强大8倍,性能高达100 petaflops。
DNN的特定领域架构仍然是计算机架构师的热门话题,其中一个主要焦点在于稀疏矩阵架构,出现于2015年首次部署TPU之后。高效推理引擎基于第一道程序,通过独立步骤过滤掉非常小的值,将权重数量减少大约10[13]倍,然后使用Huffman编码进一步缩小数据,以提高推理性能[14]。Cnvlutin[1]通过避免激活输入为零时的乘法(大概有44%的乘法是这种类型,其原因可能部分由于调整线性单元、ReLU、非线性函数,将负值转化为零),平均提高1.4倍性能。Eyeriss是新型低功耗数据流架构,通过运行长度编码数据利用零值,以减少内存占用,并通过避免输入为零时的计算来节省能源[8]。Minerva是一个跨越算法、架构和电路学科的代码设计系统,通过部分修剪具有小值的激活数据和部分量化数据实现8倍功率的降低。2017提出的SCNN[27]是一个用于稀疏和压缩卷积神经网络(CNN)的加速器。权重和激活函数都被压缩在DRAM和内部缓冲区中,从而减少数据传输所需的时间和能耗,并允许芯片存储更大的模型。
2016年以来的另一个趋势是用于训练的特定领域架构。例如,ScaleDeep[35]是针对DNN训练和推理而设计的高性能服务器,包含成千上万的处理器。每个芯片包含重度计算模块和重度存储模块,比例为3:1,性能比GPU高出6倍到28倍,以16位或32位浮点运算进行计算。芯片通过高性能互连拓扑结构连接,与DNN的通信模式类似。像SCNN一样,这种拓扑结构完全是在CNN上评估的。2016年,CNN在谷歌数据中心的TPU工作负荷中仅占5%。计算机架构师们期待着在其他类型的DNN上评估ScaleDeep,并期待出现硬件实现。
DNN似乎是FPGA作为数据中心计算平台的一个很好的用例,一个实际倍部署的例子是Catapult[30]。虽然Catapult在2014年公开发布,但它和最新的TPU产品是同一代的,2015年微软在数据中心部署了28nm Stratix V FPGA。Catapult运行CNN的速度比服务器快2.3倍。也许Catapult和TPU之间最重要的区别是,为了达到最佳性能,用户必须用低级硬设计语言Verilog编写长程序,而不是用高级的TensorFlow框架编写短程序。也就是说,TPU软件相对FPGA固件提供了更好的"可编程性"。
结论
尽管I/O总线和相对有限的内存带宽限制了TPU的利用率(6个DNN应用中有4个是内存受限的),但正如Roofline性能模型所证明的那样,某些计算的能力提升相对还是比较大的,比如每周期可以完成65,536次乘法。这一结果表明Amdahl定律的一个推论: 大量廉价资源的低利用率仍然可以提供高性价比的性能。
我们知道推理应用往往是面向终端用户的应用的一部分,因此对响应时间有很高的要求,所以DNN架构需要在99%的情况下表现出良好的延迟特性。
TPU芯片利用其在MAC和片上存储器方面的优势,运行面向特定领域的TensorFlow框架编写的短程序的速度比K80 GPU芯片快15倍,从而使每瓦性能优势提升29倍,从而优化了性能/总拥有成本。与Haswell CPU芯片相比,相应提升了29和83倍。
五个架构因素可以解释这种能效差距:
单一处理器。 TPU只有一个处理器,而K80有13个,CPU有18个。单线程使系统更容易保证固定的延迟限制。
大型二维乘法单元。 TPU有一个非常大的二维乘法单元,而CPU和GPU分别有18和13个较小的一维乘法单元,二维乘法硬件单元更适合于计算矩阵乘法。
压缩数组。 对二维组织进行阵列收缩,以减少寄存器访问和能量消耗。
8位整数。 TPU应用使用8位整数运算而不是32位浮点运算,以提高计算和内存的效率。
放弃额外功能。 TPU放弃了CPU和GPU需要而DNN不需要的功能,使TPU成本更低,同时节省能源,并允许晶体管被重新用于特定领域的片上存储器。
虽然CPU和GPU在未来肯定会以更快的速度运行推理,但重新设计的TPU通过使用2015年左右的GPU内存将性能提升了三倍,并将每瓦性能优势提升到K80的70倍以及Haswell的200倍。
至少在过去十年里,计算机架构研究人员一直在发表基于模拟的创新成果,使用有限基准,并声称基于通用处理器的改进幅度不超过10%,而我们现在可以说,部署在真实硬件中的特定领域架构的改进幅度超过了10倍[17]。
商业产品之间的数量级差异在计算机架构中比较罕见,甚至可能导致TPU成为该领域未来工作的原型。我们预计,今后很多人都会构建类似的架构,并将标准提得更高。
致谢
感谢TPU团队所有成员在项目中的贡献[20]。设计、验证和实现类似TPU这样的系统硬件和软件,并制造、部署和大规模应用,需要很多人共同努力,正如我们在谷歌看到的那样。
参考文献
- Abadi, M. et al. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv preprint, 2016; https://arxiv.org/abs/1603.04467
- Albericio, J., Judd, P., Hetherington, T., Aamodt, T., Jerger, N.E., and Moshovos, A. 2016 Cnvlutin: Ineffectual-neuron-free deep neural network computing. In Proceedings of the 43rd ACM/IEEE International Symposium on Computer Architecture (Seoul, Korea), IEEE Press, 2016.
- Asanovic´, K. Programmable neurocomputing. In The Handbook of Brain Theory and Neural Networks, Second Edition, M.A. Arbib, Ed. MIT Press, Cambridge, MA, Nov. 2002; https://people.eecs.berkeley.edu/~krste/papers/neurocomputing.pdf
- Barroso, L.A. and Hölzle, U. The case for energyproportional computing. IEEE Computer 40, 12 (Dec. 2007), 33–37.
- Barr, J. New G2 Instance Type for Amazon EC2: Up to 16 GPUs. Amazon blog, Sept. 29, 2016; https://aws.amazon.com/about-aws/whats-new/2015/04/introducing-a-new-g2-instance-size-the-g28xlarge/
- Barr, J. New Next-Generation GPU-Powered EC2 Instances (G3). Amazon blog, July 13, 2017; https://aws.amazon.com/blogs/aws/new-next-generationgpu-powered-ec2-instances-g3/
- Chen, Y., Chen, T., Xu, Z., Sun, N., and Teman, O. DianNao Family: Energy-efficient hardware accelerators for machine learning. Commun. ACM 59, 11 (Nov. 2016), 105–112.
- Chen, Y.H., Emer, J., and Sze, V. Eyeriss: A spatial architecture for energy-efficient dataflow for convolutional neural networks. In Proceedings of the 43rd ACM/IEEE International Symposium on Computer Architecture (Seoul, Korea), IEEE Press, 2016.
- Clark, J. Google turning its lucrative Web search over to AI machines. Bloomberg Technology (Oct. 26, 2015).
- Dally, W. High-performance hardware for machine learning. Invited talk at Cadence ENN Summit (Santa Clara, CA, Feb. 9, 2016); https://ip.cadence.com/uploads/presentations/1000AM_Dally_Cadence_ENN.pdf
- Dean, J. Large-Scale Deep Learning with TensorFlow for Building Intelligent Systems. ACM webinar, July 7, 2016; https://www.youtube.com/watch?v=vzoe2G5g-w4
- Hammerstrom, D. A VLSI architecture for high-performance, low-cost, on-chip learning. In Proceedings of the International Joint Conference on Neural Networks (San Diego, CA, June 17–21). IEEE Press, 1990.
- Han, S., Pool, J., Tran, J., and Dally, W. Learning both weights and connections for efficient neural networks. In Proceedings of Advances in Neural Information Processing Systems (Montreal Canada, Dec.) MIT Press, Cambridge, MA, 2015.
- Han, S., Liu, X., Mao, H., Pu, J., Pedram, A., Horowitz, M.A., and Dally, W.J. EIE: Efficient Inference Engine on compressed deep neural network. In Proceedings of the 43rd ACM/IEEE International Symposium on Computer Architecture (Seoul, Korea). IEEE Press, 2016.
- Huang, J. AI Drives the Rise of Accelerated Computing in Data Centers. Nvidia blog, Apr. 2017; https://blogs.nvidia.com/blog/2017/04/10/ai-drives-riseaccelerated-computing-datacenter/
- He, K., Zhang, X., Ren, S., and Sun, J. Identity mappings in deep residual networks. arXiv preprint, Mar. 16, 2016; https://arxiv.org/abs/1603.05027
- Hennessy, J.L. and Patterson, D.A. Computer Architecture: A Quantitative Approach, Sixth Edition. Elsevier, New York, 2018.
- Ienne, P., Cornu, T., and Kuhn, G. Special-purpose digital hardware for neural networks: An architectural survey. Journal of VLSI Signal Processing Systems for Signal, Image and Video Technology 13, 1 (1996), 5–25.
- Jouppi, N. Google Supercharges Machine Learning Tasks with TPU Custom Chip. Google platform blog, May 18, 2016; https://cloudplatform.googleblog.com/2016/05/Google-supercharges-machinelearning-tasks-with-custom-chip.html
- Jouppi, N. et al, In-datacenter performance of a tensor processing unit. In Proceedings of the 44th International Symposium on Computer Architecture (Toronto, Canada, June 24–28). ACM Press, New York, 2017, 1–12.
- Keutzer, K. If I could only design one circuit ... Commun. ACM 59, 11 (Nov. 2016), 104.
- Krizhevsky, A., Sutskever, I., and Hinton, G. Imagenet classification with deep convolutional neural networks. In Proceedings of Advances in Neural Information Processing Systems (Lake Tahoe, NV). MIT Press, Cambridge, MA, 2012.
- Kung, H.T. and Leiserson, C.E. Algorithms for VLSI processor arrays. Chapter in Introduction to VLSI systems by C. Mead and L. Conway. Addison-Wesley, Reading, MA, 1980, 271–292.
- Lange, K.D. Identifying shades of green: The SPECpower benchmarks. IEEE Computer 42, 3 (Mar. 2009), 95–97.
- Larabel, M. Google Looks to Open Up StreamExecutor to Make GPGPU Programming Easier. Phoronix, Mar. 10, 2016; https://www.phoronix.com/scan.php?page=news_item&px=Google-StreamExec-Parallel
- Metz, C. Microsoft bets its future on a reprogrammable computer chip. Wired (Sept. 25, 2016); https://www.wired.com/2016/09/microsoftbets-future-chip-reprogram-fly/
- Moore, G.E. No exponential is forever: But ‘forever’ can be delayed! In Proceedings of the International SolidState Circuits Conference (San Francisco, CA, Feb. 13). IEEE Press, 2003.
- Parashar, A., Rhu, M., Mukkara, A., Puglielli, A., Venkatesan, R., Khailany, B., Emer, J., Keckler, S.W., and Dally, W.J. SCNN: An accelerator for compressedsparse convolutional neural networks. In Proceedings of the 44th Annual International Symposium on Computer Architecture (Toronto, ON, Canada, June 24–28). IEEE Press, 2017, 27–40.
- Patterson, D.A. Latency lags bandwidth. Commun. ACM 47, 10 (Oct. 2004), 71–75.
- Patterson, D.A. and Ditzel, D.R. The case for the reduced instruction set computer. SIGARCH Computer Architecture News 8, 6 (Sept. 1980), 25–33.
- Putnam, A. et al. A reconfigurable fabric for accelerating large-scale datacenter services. Commun. ACM 59, 11 (Nov. 2016), 114–122.
- Reagen, B., Whatmough, P., Adolf, R., Rama, S., Lee, H., Lee, S.K., Hernández-Lobato, J.M., Wei, G.Y., and Brooks, D. Minerva: Enabling low-power, highly accurate deep neural network accelerators. In Proceedings of the 43rd ACM/IEEE International Symposium on Computer Architecture (Seoul, Korea), IEEE Press 2016.
- Silver, D. et al. Mastering the game of Go with deep neural networks and tree search. Nature 529, 7587 (Sept. 20, 2016).
- Smith, J.E. Decoupled access/execute computer architectures. In Proceedings of the 11th Annual International Symposium on Computer Architecture (Austin, TX, Apr. 26–29). IEEE Computer Society Press, 1982.
- Szegedy, C. et al. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (Boston, MA, June 7–12). IEEE Computer Society Press, 2015.
- Venkataramani, S. et al. ScaleDeep: A scalable compute architecture for learning and evaluating deep networks. In Proceedings of the 44th Annual International Symposium on Computer Architecture (Toronto, ON, Canada, June 24–28). ACM Press, New York, 2017, 13–26.
- Williams, S., Waterman, A., and Patterson, D. Roofline: An insightful visual performance model for multi-core architectures. Commun. ACM 52, 4 (Apr. 2009), 65–76.
- Wu, Y. et al. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv preprint, Sept. 26, 2016; arXiv:1609.08144
作者
Norman P. Jouppi ([email protected]) 谷歌杰出硬件工程师
Cliff Young ([email protected]) 谷歌大脑团队成员
Nishant Patil ([email protected]) 谷歌技术主管
David Patterson ([email protected]) 加州大学伯克利分校电子工程与计算机科学学院Pardee荣誉教授,谷歌杰出工程师
你好,我是俞凡,在Motorola做过研发,现在在Mavenir做技术工作,对通信、网络、后端架构、云原生、DevOps、CICD、区块链、AI等技术始终保持着浓厚的兴趣,平时喜欢阅读、思考,相信持续学习、终身成长,欢迎一起交流学习。
微信公众号:DeepNoMind
本文由 mdnice 多平台发布