论文笔记:Spatio-Temporal Trajectory Similarity Measures: AComprehensive Survey and Quantitative Study
1 intro
1.1 背景
- 轨迹相似度测量在很多应用中都起着基础性的作用
- 不同的测量选择可能导致完全不同的结果和质量
- 以轨迹聚类为例,聚类旨在将相似的轨迹分组到集群中,其中相似度计算是聚类的基础任务
- DTW和EDR聚类的效果千差万别

- 不同的测量选择可能导致完全不同的结果和质量
1.1.1 轨迹相似度需要考量的四个轨迹特性
- 与孤立的空间点或一维时间序列不同(这些距离定义是直接了当的)定义连续二维轨迹之间的距离并非易事。还需要考虑以下四个轨迹特性
- 不同的数据源(自由空间与道路网络空间)
- 在后一种情况下,适当的轨迹测量应考虑道路拓扑结构,因为人和车辆不能像没有空间限制的船舶一样行驶
- 各种采样率和长度
- 与通常具有恒定和高采样率的时间序列不同,时空轨迹数据通常是通过不同的采样生成的,导致长度可变
- 噪声的影响
- 噪声点通常存在,尤其是由于城市中的强度衰减和干扰
- 复杂的形状
- 与通常由于隐私原则而无法访问的私家车轨迹相比,出租车轨迹在社区中得到了广泛的研究
- 然而,出租车轨迹展示了更多样化、复杂和灵活的几何形状,这是因为各种接送需求
- 不同的数据源(自由空间与道路网络空间)
——>为了解决上述时空特性,大量的研究工作设计了数十种时空轨迹相似度测量方法。
1.1.2 如何选择轨迹相似度测量方法?
- 面对大量的轨迹测量方法,研究人员往往感到太累而无法选择一个合适的。
- 一方面,有太多的轨迹测量方法,这些方法是在不同场景下提出的
- 基于学习或非基于学习(non-learning)
- 面向自由空间或面向道路网络
- 独立处理或分布式处理
- 另一方面,对各种轨迹测量方法的评估仍然没有很好地组织
- 有些测量方法只关注效率,而其他可能更注重有效性和鲁棒性
- 一方面,有太多的轨迹测量方法,这些方法是在不同场景下提出的
- ——>论文以分层的方式对1995年至2022年提出的现有代表性的时空轨迹测量方法进行分类,即非学习 vs 学习(第一层次),自由空间 vs 道路网络(第二层次),以及独立 vs 分布式(第三层次)

1.2 之前综述论文的不足 & 论文的研究架构
- 之前的综述主要关注非学习、自由空间或基于独立措施(不分布式)的轨迹相似性
- 大大缩小了研究的范围
- 论文以三维层次方式,对最常见和具有代表性的时空轨迹测量进行了回顾和评估
- learning VS non-learning
- 近些年许多研究尝试用基于学习的模型替代传统的手工轨迹测量
- free space VS road network
- 在早期阶段,大多数轨迹测量 是为在欧几里得空间中自由移动的物体设计的,例如鸟或船的轨迹
- 近年来,车辆导航系统和基于位置的服务(LBS)的普及使得在道路网络中大量收集车辆和人员轨迹成为可能。
- 在这种情况下,面向自由空间的轨迹测量不能反映在受限制的道路网络中移动物体之间的真实距离
- 基于单机的 VS 分布式的
- 由于单台机器的存储容量和处理能力已经无法支持大规模的轨迹数据,另一个流行的轨迹相似性研究方向是在分布式处理平台(例如,Spark)上设计高效和可扩展的框架,以进行大规模轨迹相似性分析
- learning VS non-learning
2 preliminary
2.1 轨迹
轨迹 T 是一个由 GPS 采样点组成的有序序列 ![]()
 表示id为i的轨迹,
表示id为i的轨迹,![]() 表示id为i的轨迹的第j个点
表示id为i的轨迹的第j个点
每个采样点pi是是二维或三维(即(纬度,经度)或(纬度,经度,时间戳))
2.2 道路网络
G=
vi表示路网中的一个交叉点
![]() 是一条有向边
是一条有向边
2.3 相似性测量
f(Ti,Tj),用于测量Ti和Tj的距离
2.4 度量测量
给定相似性测量f和三条轨迹Ti,Tj和Ta
- 如果f满足以下条件,那么称f为一个度量测量
- 唯一性
- 非负性
- 三角不等式
- 对称性
- 唯一性
表1 中 metric 那一列就是表示这种测量方法是不是度量测量(✔是 × 否 / 表示基于learning的方法不需要考量这个)
2.5 Top-K 相似性
和查询轨迹QT最相似的k条轨迹(不包括本身)
3 不基于learning的方法
3.1 自由空间的轨迹相似度
3.1.1 基于点的测量方法
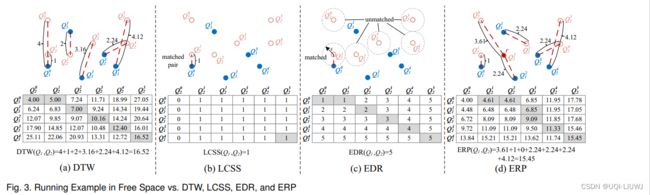

3.1.1.1 欧几里得距离
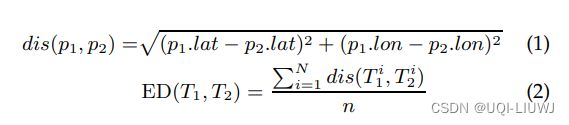

论文正文中说ED是parameter-free的,所以这边我觉得应该是图标错了
3.1.1.2 DTW
. Efficient retrieval of similar time sequences under time warping ICDE 1998


Head(T) 表示Tn不要了,之前的部分
3.1.1.3 LCSS
Discovering similar multidimensional trajectories 2002


3.1.1.4 EDR (编辑距离)
Robust and fast similarity search ¨ for moving object trajectories. SIGMOD 2005
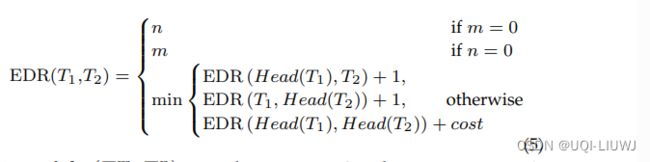
 前4个详细的可见:轨迹相似度整理_python 轨迹相似度_UQI-LIUWJ的博客-CSDN博客
前4个详细的可见:轨迹相似度整理_python 轨迹相似度_UQI-LIUWJ的博客-CSDN博客
3.1.1.5 ERP(实数惩罚编辑距离)
On the marriage of lp-norms and edit distance VLDB 2004
(
- 上述基于编辑距离的测量方法基本上都不是度量的
- ERP是一种可以用于索引和剪枝的度量测量方法
- 与 LCSS 和 EDR 等其他基于编辑距离的测量方法不同,ERP 不需要阈值参数,而是设置一个参考点r进行测量

3.1.1.6 豪斯多夫距离 TITS 2010
Clustering of vehicle trajectories
从一个轨迹中的某一点到另一个轨迹中最近点的所有距离值中的最大距离

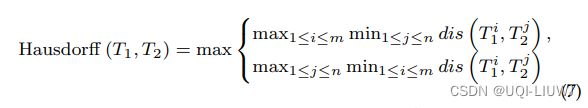

数学笔记/scipy 笔记:豪斯多夫距离(Hausdorff )_python 豪斯多夫距离_UQI-LIUWJ的博客-CSDN博客
3.1.1.7 Frechet 距离
Computing the fr´echet distance between two polygonal curves. Int. J. Comput. Geom. Appl. 1995
Frechet [2] 是通过走狗的例子来提出的。假设一个人用皮带遛狗。虽然这个人和他的狗可能有不同的轨迹,但他们移动的方向是相同的。两个轨迹(人和狗)之间的 Frechet 距离是所需皮带的最短长度

- 由于 Frechet 距离是非度量的,因此提出了许多变体来使其成为度量 。
- 最常见的一个是离散 Frechet 距离 [70],时间复杂度为 O(mn)
- 在本文的其余部分中使用“Frechet”距离来表示离散 Frechet 距离
- 最常见的一个是离散 Frechet 距离 [70],时间复杂度为 O(mn)

3.1.1.8 分布式设定
3.1.1.8.1 DITA

- DITA(Distributed In-memory Trajectory Analytics,分布式内存轨迹分析系统)使用了几种经典的基于点的测量方法,如DTW和Frechet。
- DITA选择了STR分区算法来对轨迹点进行分区。
- 使用R树作为局部索引,并设计了一个类似字典树(Trie)的索引作为全局索引。
- 相应地,在局部索引中也使用了类似字典树的分区算法,并开发了几种剪枝优化方法来提高分布式环境中相似度搜索和连接的效率。
3.1.1.8.2 REPOSE

- REPOSE是一个用于轨迹相似性搜索的分布式内存系统
- 支持多种距离测量方法,包括 Hausdorff、Frechet、DTW、LCSS、EDR 和 ERP。
- 将轨迹离散化为参考轨迹,并在参考轨迹的参考点上构建一个类似字典树(即 RP-Tree)的索引
- REPOSE 倾向于尽可能将相似的轨迹划分到不同的分区中,以实现负载均衡。
算法笔记:Frechet距离度量_UQI-LIUWJ的博客-CSDN博客
3.1.2 基于线段的方法
3.1.2.1 Edit Distance with Projections (EDwP)
Indexing and matching trajectories under inconsistent sampling rates ICDE 2015
- 采用无参数方法,并通过动态插值和投影来适应非均匀采样率。
- 将轨迹点转换为线段,并使用插入和替换操作来计算编辑距离

两个轨迹 T1 和 T2 之间的 EDwP 距离定义为:

- rep和ins分别表示替换和插入操作
- 这里和前面的EDR是有一点去别的(EDR替换之外的操作是删除,所以需要+1;这边替换之外的操作是插入,之后还要考虑的【只不过下一步考虑的时候,替换操作加的内容是0】,所以不用加什么数值)
-
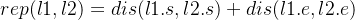
- 替换的两截轨迹起始点之间的距离+终止点之间的距离
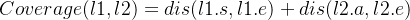
- 替换的成本:两截轨迹的长度之和
3.1.2.2 多线位置距离(Locality In-between Polylines,LIP)
Similarity search in trajectory databases TIME 2007
轨迹相似度整理_python 轨迹相似度_UQI-LIUWJ的博客-CSDN博客


LIP 进一步可以扩展到一个具有时空性(即,考虑时间因素)的距离,称为 STLIP
SPSTLIP :速度模式时空距离。
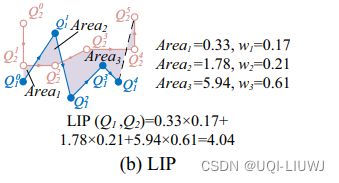
3.1.2.3 One-way Distance (OWD) 单向距离
Index-based most similar trajectory search ICDE 2007

- OWD 支持两种轨迹表示(即,线性表示和网格表示)
- 将基于点的轨迹数据转换为基于段的数据。
- 测量从一条轨迹中的每个点到另一条轨迹的平均最小距离

- 考虑到线性表示的高计算成本O(mn),OWD 被扩展到称为
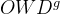 的网格表示
的网格表示
- 轨迹点根据其空间信息映射到网格单元中
- 只计算网格单元(而不是样本点)和基于网格的轨迹之间的距离
- 时间复杂度降低到 O(m′n′),其中 m′ 和 n′ 分别表示两条轨迹占用的网格单元数

3.1.2.4 Seg-Frechet and Seg-Hausdorff

- 受到 Fréchet 和 Hausdorff 距离的启发,Seg-Fréchet 和 Seg-Hausdorff 在计算 Fréchet 和 Hausdorff 距离时,将点改为线段进行计算
- 这种变化主要是为了更好地适应那些基于线段而非点的轨迹数据。
- 例如,在车辆或人员移动的场景中,通常更关心沿一定路径的移动,而这一路径可以用一系列线段来表示。
- 因此,通过将 Fréchet 和 Hausdorff 距离扩展到线段,可以更准确地描述这类轨迹之间的相似性或差异。
3.1.2.5 分布式框架
- 基于 Spark 开发了一个支持 Seg-Fréchet 和 Seg-Hausdorff 测量的分布式框架(即,DFT)
- DFT 使用 STR 分区算法来分区线段,同时构建一个双 R-树作为全局索引和一个通用 R-树作为局部索引。
- DFT 是第一个支持快速轨迹相似性计算的分布式方法。
Distri VLDB 2017buted trajectory similarity search
- 这种分布式框架主要是为了应对大规模轨迹数据的处理需求。
- 通过在 Spark 上实现这一框架,DFT 能够充分利用分布式计算资源,以实现更高的计算效率和可扩展性。
- STR 分区算法和 R-树索引进一步提高了查询效率,使得该框架能够快速地处理复杂的轨迹相似性查询。
- 这对于需要在大数据环境下进行轨迹分析的应用场景(如城市交通管理、社交网络分析等)来说,具有很高的实用价值。

3.2 路网的轨迹相似度
3.2.1 基于点的测量
3.2.1.1 NetERP、NetEDR、NetDTW 和 NetLCSS
- 从自由空间中的经典度量扩展而来的
- 首先将原始轨迹映射到由顶点或线段组成的路网路径上
- 然后基于经典的距离度量(如 ERP、EDR、DTW 和 LCSS)定义相似性度量
- 值得注意的是,这些度量采用图中两个路口之间的最短路径距离(而不是欧几里得距离)
- NetERP、NetEDR、NetDTW 和 NetLCSS 具有与相应的经典度量相同的特点

Road network inference from GPS traces using DTW algorithm ITSC 2014
Spatio-temporal trajectory similarity learning in road networks KDD 2022
Fast subtrajectory similarity search in road networks under weighted edit distance constraints VLDB 2020
.Fast subtrajectory similarity search in road networks under weighted edit distance constraints VLDB 2020
3.2.1.2 TP
Trajectory similarity join in spatial networks VLDB 2017

- 同时考虑时空相似度,记每个点为一个三维向量 v=(p,t)=((lat,lon),timestamp)
- 每个点到另一条轨迹的时空距离:
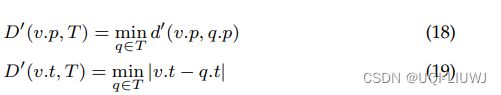
- 这里也是路径距离
- 两条轨迹的时 or 空相似度
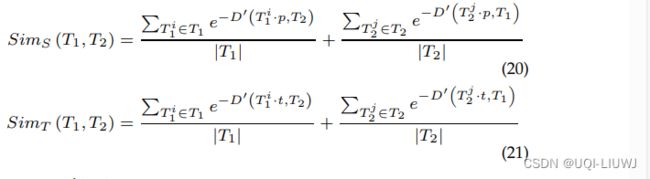
- 每一条轨迹 每一个点到另一条轨迹的平均时间/空间距离
- 两条轨迹的时空相似度
3.2.2 基于路段的测量
3.2.2.1 Longest Overlapping Road Segments (LORS)

Torch: A search engine for trajectory data SIGIR 2018
计算重叠边(路段)的长度

3.2.2.2 Longest Common Road Segments (LCRS)

路段版的LCSS
两条轨迹中的最长公共路段

Distributed in-memory trajectory similarity search and join on road network 2019 ICDE (yuan haitao)
3.2.2.3 分布式版本
- 将独立的 LCRS 扩展到一个名为 DISON 的分布式框架,该框架支持基于路网约束的相似性搜索和连接。
- DISON 首先使用 STR 分区算法对路段进行分区,然后构建一个两层索引,其中哈希映射用作全局索引,而倒排索引用作局部索引。
- 需要注意的是,DISON 是用于路网中相似性度量的唯一分布式框架。
Distributed in-memory trajectory similarity search and join on road network 2019 ICDE (yuan haitao)

4 基于learning的方法
- 非learning的方法一般复杂度都比较高
- learning的方法主要把高维输入数据重构为低维表征
- t2vec设计了一个轨迹深度学习框架
- 将一个轨迹映射到一个 d-维嵌入向量中。
- 需要注意的是,t2vec 不是一种相似性度量,而是一种将轨迹转换成向量的表示方法。

- 受到 t2vec 的启发,许多研究在自由空间和路网中采用不同的深度学习框架,以学习非学习度量的近似距离函数。
- 通常,如图 9 所示,它们首先选择锚轨迹(原始轨迹)的相似和不相似轨迹(即正轨迹和负轨迹)
- 然后,提取特征(就空间、时间、结构等方面而言),同时使用深度表示学习生成轨迹嵌入向量。
- 最后,当在嵌入向量上评估的轨迹相似性和不相似性接近ground-truth时,学习(图 9 中的虚线矩形)可以停止。
- 需要注意的是,向量间相似性学习的时间复杂性是线性的
4.1 基于自由空间的
4.1.1 NEUTRAJ
Computing trajectory similarity in linear time ICDE 2019 (Cong Gao)

- NEUTRAJ 首先将轨迹映射为网格轨迹(grid-trajectories)
- —》由 NEUTRAJ 生成的嵌入向量可以保留轨迹的空间信息
- 然后抽样轨迹作为种子,使用它们的成对相似性和不相似性作为指导。
- 最后,NEUTRAJ 使用LSTM来生成嵌入向量,以O(m+n) 的复杂性近似各种非学习相似性计算)。
4.1.1.1 TrajGAT
为了提高深度表示学习方法在长轨迹上的性能TrajGAT基于图注意力网络(GATs)、Transformer 和四叉树索引,以有效地嵌入轨迹
4.1.2 Traj2SimVec
Trajectory similarity learning with auxiliary supervision and optimal matching IJCAI 2020

- 与 NEUTRAJ 不同,Traj2SimVec 通过将训练轨迹简化为三元组训练样本(triplet training samples。
- 三元组通常包括一个"锚点"轨迹、一个与锚点相似的"正"轨迹,以及一个与锚点不相似的"负"轨迹。
- 通过这种方式,Traj2SimVec 能够将训练时间复杂度降低到 O(logn),其中 n 是训练轨迹的平均长度。
- 类似于 Traj2SimVec,还有基于注意力网络的方法,如 T3S 和 TMN。
- T3S 考虑到了不相似的轨迹
- TMN 主要关注轨迹之间的相互信息。
4.2 基于路网
4.2.1 GTS
A graph-based approach for trajectory similarity computation in spatial networks. KDD 2021

- GTS (Graph Trajectory Similarity) 是一个基于GNN的方法
- 与上述两种在自由空间中设计的方法不同,GTS 考虑到了道路网络的特殊性
- 为了反映道路网络上的信息,GTS 学习了空间网络中POI的表示以及轨迹之间、POI 之间,以及轨迹与 POI 之间的关系
- ——>更准确地量化在具有路网约束的环境中轨迹的相似性
4.2.2 ST2Vec
Spatio-temporal trajectory similarity learning in road networks KDD 2022

ST2Vec 采用了具有 O(d) 时间复杂度的模型来捕获空间和时间特征。
它基于GNN和LSTM将这些特征融合,从而获得基于时空的嵌入向量。
5 评价标准
从四个性能方面研究每种度量的能力
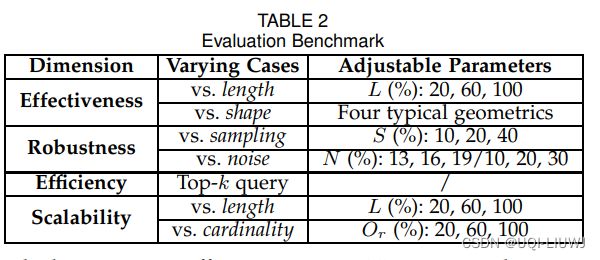
5.1 有效性与长度和形状
- 由于两个轨迹的相似性没有一个基准真值,我们无法确定由轨迹度量计算出的值是否正确
- 不同度量返回的距离值进行交叉比较也是没有意义的
- ——>我们采用定性的方式,将不同轨迹度量返回的相同查询轨迹的 Top-k 相似性查询结果进行可视化
- 当查询轨迹的长度或形状不同时,提供一种直观的分析,以展示每种度量的有效性
- 使用参数 L 来改变轨迹长度
- L=20 意味着从原始轨迹中选择前 20% 的点作为一个变形轨迹
- 这种以长度为导向的评估使我们能够看到每种距离度量在轨迹长度从短到长变化时的表现
- 这在涉及轨迹演化的在线设置中是有用的
- 在不同形状方面,我们选择了四种典型的几何形状
- 直线
- 无重叠的折线
- 有重叠的折线
- 圆形线
- 使用参数 L 来改变轨迹长度
- 当查询轨迹的长度或形状不同时,提供一种直观的分析,以展示每种度量的有效性
5.2 稳健性与采样和噪声
- 对于一个给定的查询轨迹,一个稳健的轨迹相似度度量应该能够为具有不同采样率和噪声比例的数据集检索相同的查询结果
- 使用参数 S 来表示每条轨迹中采样点的百分比
- S=20 表示我们从轨迹中采样20%的点作为一个变形轨迹
- 对于自由空间轨迹,采样转换是有意义和有用的,而对于经过地图匹配后的受路网约束的轨迹则是无意义和无用的
- 在自由空间轨迹中,每个点都是独立的,并且它们之间没有任何预定义的关系(除了可能的时间先后关系)
- 这样,采样转换(即从轨迹中随机或按照某种规则选择一定比例的点)通常不会改变轨迹的基本特性或形状
- 然而,在受路网约束的轨迹中,情况就有所不同。
- 这些轨迹通常是由一系列沿着特定路网图的顶点或边生成的。
- 在这种情况下,简单地从轨迹中随机抽取点可能会导致信息丢失(如路由信息)或误导,因为这些点通常是沿着特定的路线或路径捕获的。
- 采样可能会打破这些内在的路径依赖关系,从而导致不准确或无意义的相似度计算。
- 在自由空间轨迹中,每个点都是独立的,并且它们之间没有任何预定义的关系(除了可能的时间先后关系)
- N=10 表示从轨迹中抽样10%的点,然后为每个点添加一个异常值
- 使用高斯噪声
- 使用参数 S 来表示每条轨迹中采样点的百分比
5.3效率与 Top-k 查询
- 一个高效的轨迹相似度度量应该能够有效地计算任意一对轨迹之间的距离值,这对于在线轨迹应用尤为重要。
- 因此,直接使用 Top-k 相似性查询作为评估任务
5.4 可扩展性与长度和基数
- 无论轨迹数据集的平均轨迹长度或数据基数(即,移动对象的数量)如何变化,一个可扩展的度量应该显示稳定的轨迹间距离计算性能
- 使用 L(%) 来控制数据集中轨迹的平均长度
- 使用另一个参数 Or 来控制所有对象中移动对象的百分比,即要查询/处理的轨迹数量
6 实验
6.1 实验配置
6.1.1 数据集
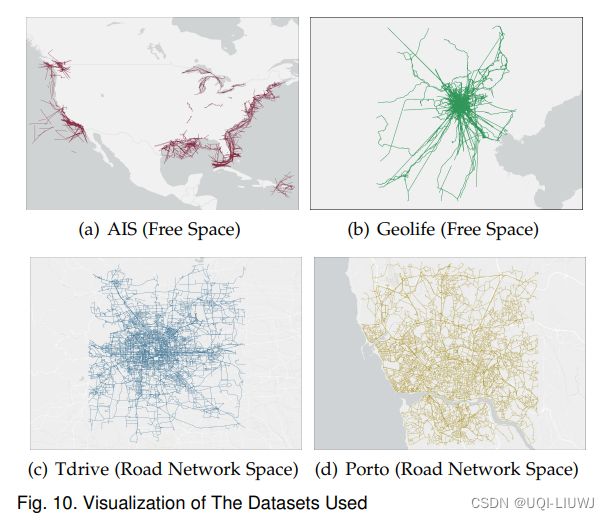
使用四个真实世界的轨迹数据集:
- AIS 记录了美国和国际水域内船只的位置。我们使用的数据范围是从2019年1月1日到12月1日。样本间隔在1到90秒之间不等。
- Geolife 包含了约2500万个GPS点,这些点是从2007年4月到2012年8月在北京的182名行人中收集的。样本间隔是2秒。Geolife 记录了用户不同的出行方式,因此,轨迹的速度差异很大。
- T-Drive 包括了由10357辆出租车在2008年2月2日至2月8日间在北京生成的150万个GPS点。样本间隔在1到177秒之间不等。
- Porto 包含了由442辆出租车在2011年8月到2012年4月间在葡萄牙波尔图生成的170万个GPS点。样本间隔是15秒。
- 四个数据集的可视化展示在图10中。
- 与Geolife收集的GPS点相比,AIS收集的GPS点具有更广泛的空间覆盖范围,并且分布更不均匀。
- 由于船只和行人在自由空间中移动,而出租车沿着道路网络移动,我们使用AIS和Geolife来评估面向自由空间的轨迹度量,使用T-Drive和Porto来评估受道路网络约束的轨迹度量。
- 移除了包含少于5个GPS点的轨迹,并使用地图匹配将所有在T-Drive和Porto上的轨迹与从OpenStreetMap 中提取的相应道路网络进行匹配。
- 在分布式设置中,随机选择了50,000条轨迹进行评估。
- AIS、Geolife、T-Drive和Porto的平均长度分别是512、343、150和58。
- 由于相似性计算的高复杂性和单一机器的局限性,从总共50,000条轨迹中随机选择了10,000条轨迹进行单机处理模式下的评估。
6.1.1 实验设计
- 非基于学习的度量
- 评估了17个独立的度量:DTW、LCSS、EDR、EDwP、ERP、Hausdorff、Frechet、LIP、OWD、Seg-Frechet、LORS、TP、NetERP、NetEDR、NetDTW、NetLCSS 和 LCRS,考虑其有效性、鲁棒性、效率和可扩展性
- 只在效率和可扩展性方面评估了四个分布式度量:DFT、DITA、REPOSE 和 DISON
- 因为分布式实现仅通过如并行化和分区等技术来提高时间性能,而没有修改度量本身
- 基于学习的度量
- 所有基于学习的度量,即 NEUTRAJ 、Traj2SimVec 、GTS 和 ST2Vec 都是基于单机的
- 在有效性、鲁棒性、效率和可扩展性方面对它们进行了评估
- 需要注意的是,基于学习的模型的目标是近似由非学习度量计算的轨迹间相似性,而所有现有的基于学习的度量只能支持基于点的相似性学习
- 因此,对于每一种基于学习的度量,我证了其在自由空间中近似基于点的轨迹相似性度量(包括 DTW、LCSS、EDR、EDwP、ERP、Hausdorff 和 Frechet)以及在道路网络中(包括 NetDTW、NetLCSS、NetERP 和 TP)的能力
- 所有基于学习的度量,即 NEUTRAJ 、Traj2SimVec 、GTS 和 ST2Vec 都是基于单机的
6.2 有效性
6.2.1 非基于学习的测量
6.2.1.1 长度的影响
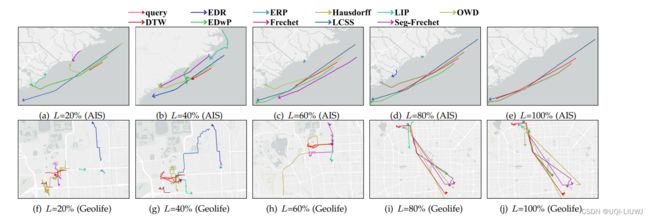
- 给定查询轨迹 QT(用红线表示)的 Top-1 查询结果,其中 QT 的长度与其整体长度的比例从 20% 变化到 100%。
- 只评估 AIS 和 Geolife 上的自由空间导向度量。
- 通过可视化查询轨迹和相应的 Top-1 查询结果之间的相似性越高,效果越好。、
- 对于 AIS,当L=100% 时
- 由 LCSS 和 Hausdorff 计算的结果几乎相同
- 而对于 DTW、Frechet、OWD 和 Seg-Frechet,则几乎相同。
- 对于 Geolife
- DTW、EDwP、OWD、Hausdorff、Frechet 和 Seg-Frechet 与 QT 的相同交通模式共享相似的结果
- 而只有 Hausdorff 返回与之相反方向的结果。
- 这是因为 Hausdorff 是一个对称度量,不考虑轨迹的方向。
- 当 QT 的长度变化时
- DTW、EDwP、Hausdorff 和 OWD 在两个数据集上始终返回相同的结果
- 这表明它们可以灵活地适应于识别与具有不同长度的查询轨迹 QT 相关的相似轨迹
- 当 QT 的长度较小时
- EDR 的性能比其他度量差,即 EDR 所识别的结果与 QT 非常不同
- 原因是 EDR 计算中不同编辑操作的成本相同,使其对轨迹长度(即轨迹点的数量)敏感
- 具体来说,EDR 总是找到与查询轨迹 QT 长度相似的查询结果,即使该结果与 QT 在空间上相距遥远
- EDR 的性能比其他度量差,即 EDR 所识别的结果与 QT 非常不同
- 由 LIP 计算的结果随着 QT 的长度而显著变化
- 这是因为结果在很大程度上依赖于 QT 和待检查轨迹的交点形成的多边形的形状,而这些形状显然受到 QT 长度的影响
- 在 AIS 上由所有度量识别的结果通常比在 Geolife 上的要好(即,与 QT 更相似)
- 这是因为 Geolife 中的每一条轨迹通常包含多种交通模式,并倾向于展示各种各样的特征
6.2.1.2 形状的影响

- 图 12 展示了四种不同查询轨迹(用红线表示)的 Top-1 查询结果,每一种都具有典型的空间形状
- 直线(表示为 QTs)
- 无重叠的折线(表示为 QTo1)
- 有重叠的折线(表示为 QTo2)
- 圆形(表示为 QTr)
- 仅评估 T-drive 和 Porto 上的受路网约束的相似性度量,因为由于路网的约束,车辆轨迹通常比自由空间轨迹具有更复杂的几何形状
- 直线【12(a) 和 (e)】
- 给定一个 QTs,只有 NetEDR 和 NetLCSS 返回包含与 QT 匹配对数量较多的往返轨迹,而所有其他度量都返回直线轨迹
- 原因是 NetEDR 和 NetLCSS 不考虑轨迹的方向,而是考虑匹配对的数量。具体而言,匹配对越多,相似性越高
- 给定一个 QTs,只有 NetEDR 和 NetLCSS 返回包含与 QT 匹配对数量较多的往返轨迹,而所有其他度量都返回直线轨迹
- 折线【图 12(b)、(c)、(f) 和 (g)】
- 除 NetEDR 外,所有度量都返回与其相似的结果
- NetEDR 不考虑两点之间的空间距离
- 相反,它通过比较它们的长度来识别相似的轨迹,即相似的长度导致更高的相似性
- 除 NetEDR 外,所有度量都返回与其相似的结果
- 圆形【图 12(d) 和 (h)】
- 只有 LORS、LCRS 和 TP 返回带有圆形子轨迹的结果,其中 LORS 表现最好
- 因为 LORS 能够识别重叠的道路段,这使得它能够有效地匹配具有圆形形状的轨迹
- 只有 LORS、LCRS 和 TP 返回带有圆形子轨迹的结果,其中 LORS 表现最好
6.2.2 非基于学习的度量

- 通过学习型度量近似非学习型度量的能力来评估其有效性,非学习型度量是它们的目标。
- 给定一个查询轨迹 QT 和一个非学习型度量,使用该非学习型度量计算出的 Top-50 查询结果作为ground truth
- 实现一个学习型度量的模型以近似该非学习型度量,并应用所学度量来计算与 QT 相关的 Top-50 查询结果
- 使用 HR@50 来衡量由学习型度量返回的 Top-50 相似性查询结果与ground truth之间的重叠程度
- HR@50 越高,有效性越高
- 在自由空间设置中
- Traj2SimVec 的性能优于 NEUTRAJ
- Traj2SimVec 将轨迹简化为三元组(锚点、相似、不相似),增强了轨迹之间的相似性学习
- Traj2SimVec 在不同的相似性度量和不同的数据集之间的性能不稳定
- (i) LCSS、EDR 和 ERP 是基于字符串的,其信息无法在嵌入中保留
- (ii) AIS 的数据分布不均匀,而由于各种交通方式,Geolife 上的时空特征很复杂
- Traj2SimVec 的性能优于 NEUTRAJ
- GTS 和 ST2Vec 在路网设置中的 HR@50 都很稳定,且 ST2Vec 的性能优于 GTS
- ST2Vec 利用的空间信息(即路网)比 GTS(即 POI)更全面,而且 ST2Vec 能够有效地提取这些信息
- 在路网设置中,基于学习的度量更有效
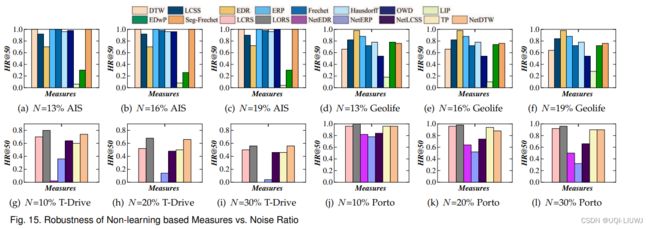
6.3 鲁棒性
- 首先,我们通过一个相似性度量计算 QT 的 Top-50 相似轨迹,并将结果设置为ground-truth
- 其次,根据S和N(采样率,噪声比例),我们对原始数据集执行下采样或加噪操作,从而得到一组转换后的轨迹数据集
- 第三,我们对每个转换后的数据集中相同的查询轨迹 QT 执行 Top-50 相似性查询
- 最后,我们使用 HR@50 来衡量转换后的数据集上的 Top-50 相似性查询结果与ground-truth之间的重叠程度
- HR@50 越高,鲁棒性越强
6.3.1 基于非学习的度量
6.3.1.1 采样率

6.3.1.2 噪声
6.3.2 基于learning的方法

 6.4 efficiency
6.4 efficiency
执行top50 查询的时间
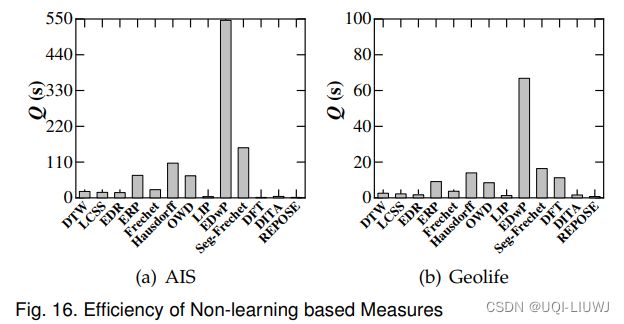
6.4.1 非学习的方法
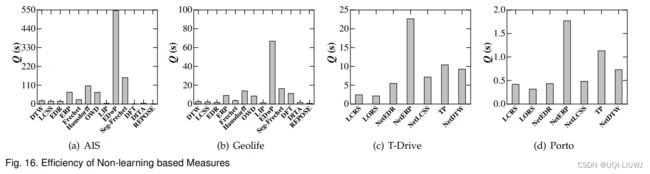
- (a)(b)
- LIP 时间复杂度为O((m+n)log(m+n)) 所以所需时间最短
- 其余大部分是O(mn)
- EdwP 在计算相似性的时候需要维护四个动态规划,所以最慢
- (c)(d)
- LCRS和LORS 及计算重叠的路段数量,不需要计算路段之间的距离,所以执行的最快
- TP 还需要计算时间维度的距离,所以会慢一些
- 所有分布式的会执行的快一些
6.4.2 学习的方法
分别统计了训练时间(Ttra)和查询时间Q

- 基于学习的方法的平均查询时间比基于非学习的度量低 1-2 个数量级
- 在路网中,ST2Vec 的训练时间比 GTS 长,而它们的查询时间相似。
- 这是因为 ST2Vec 考虑了时间信息,这需要在模型训练期间进行计算
6.5 scalability
- 不同长度和不同查询轨迹数量下
- 分布式方法建立index的时间Tidx
- 基于学习的方法的训练时间Ttra
- 所有方法的Top-50查询时间Q
6.5.1 非学习的方法
6.5.1.1 单机方法
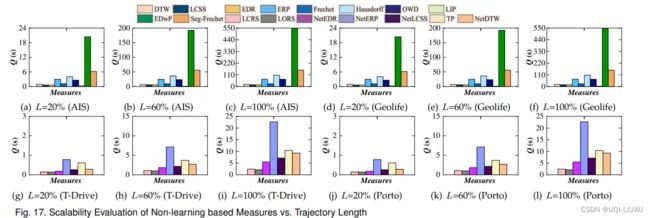
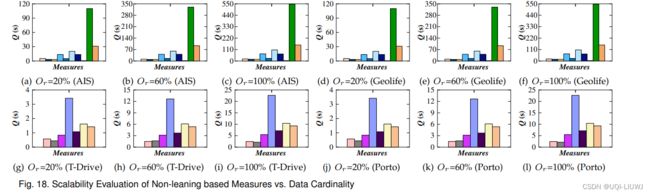
- 大多数单机度量(除了 LIP、LCRS 和 LORS)的查询时间随着轨迹长度或数据基数的增长而显著增加,可扩展性差
- LIP 的查询时间随着数据基数的增长而略有增加
- LCRS 和 LORS 的查询时间在数据基数从 60% 增加到 100% 时保持稳定。
- 这是因为 LCRS 和 LORS 通过计算一对轨迹的重叠路段数量来计算相似性,而不是计算它们的点或路顶点之间的成对距离。
- 这使得 LCRS 和 LORS 能够处理大型数据集
6.5.1.2 分布式方法
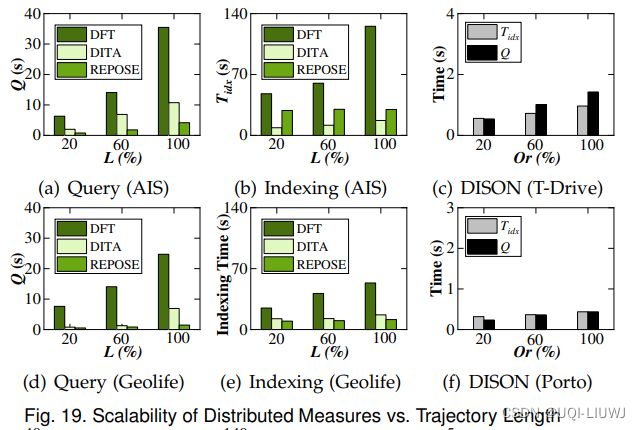
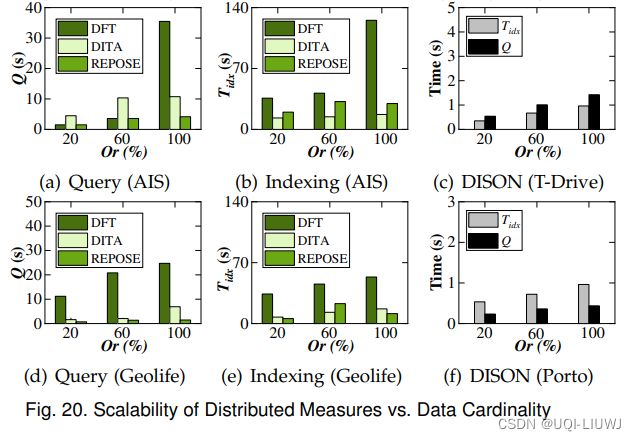
- 与图 17 和图 18 相比,当在两个数据集上变化轨迹长度和数据基数时,分布式度量实现了比单机度量更高的查询效率
- DITA、REPOSE 和 DISON 的查询时间和索引构建时间在两个数据集的轨迹长度和基数上都变化得很温和;而 DFT 的这些时间随着轨迹长度和基数的增长而迅速增加
- 当在 AIS 和 Geolife 上变化轨迹长度和数据基数时,REPOSE 和 DITA 的查询时间总是优于 DFT。
- 这意味着分布式技术能够提高路网中相似性计算的可扩展性。
6.5.2 学习的方法

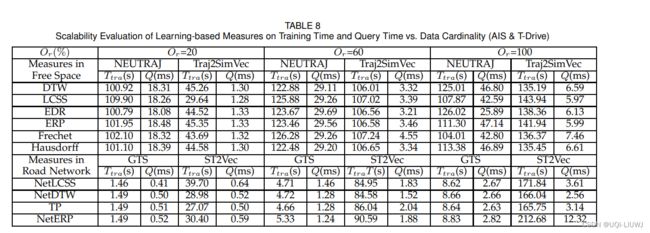
- 仅在 AIS 和 T-Drive 上评估基于学习的方法的可扩展性
- 由于空间限制以及它们比 Geolife 和 Porto 的尺寸更大
- 所有度量的查询时间随着轨迹长度和数据基数的增长而略有增加
- 训练时间则显著增加。
- 这是因为当轨迹长度或数据基数增加时,基于学习的方法需要更多的时间来捕获用于模型训练的采样点的信息
- 然后它们只需应用训练好的模型,以恒定的时间获得 Top-50 结果
- 基于学习的度量的查询时间远低于非基于学习的度量。
- 这表明基于学习的度量能够加速相似性计算
6.6 三角不等式和索引的影响

- 三角不等式和索引可以分别用于过滤不合格的结果和加速度量相似性度量的相似性计算,因此可以显著影响它们的性能。
- 评估基于三角不等式剪枝和不同索引结构对三种度量度量(ERP、Frechet 和 Hausdorff)性能的影响(非metric的无法比较)
- 具体来说,给定一个查询轨迹 QT,我们应用这三种度量来执行 Top-50 查询,并研究它们在分别使用LEASA、MVP-Tree和PM-Tree这三种索引结构时的索引构建时间(Tidx)、查询时间(Q)和剪枝率( Prune Rate)

- TrajNumpruned:是被过滤轨迹的数量
- TrajNumall 是轨迹的总数量
- PruneRate 越高,剪枝性能越好
- HF 方法用于选择支点轨迹,其中支点数设置为 5
- 索引有助于减少所有度量度量的查询时间
- 查询时间低
- PruneRate 高
- 应用索引结构时,三种度量之间的搜索时间排名发生变化
- 如图 16(a) 所示,在 Frechet、ERP 和 Hausdorff 之间,当没有应用索引结构时,Frechet 在 AIS 上达到最高效率
- 如图 21(b) 所示,当使用 LEASA 和 MVPT 时,Hausdorff 在 AIS 上比 ERP 更高效
- 如图 21(a) 和 21(c) 所示,具有相同索引结构的不同度量的索引构建时间和剪枝性能是不同的
- Frechet 在构建索引上花费的时间较少,并且比 ERP 和 Hausdorff 具有更稳定和更高的 PruneRate
总体而言,在评估度量相似性度量的性能之前,有必要构建索引并探索基于三角不等式的剪枝,因为这些辅助技术可能会大大提高度量相似性度量的有效性。
6.7 ★★★★实验总结★★★★
-
大多数轨迹相似性度量的效果受到数据集分布和特性的极大影响。具体来说,Frechet、Hausdorff、LCRS 和 LORS 在不同的数据集中始终表现良好和稳定;而 ERP 表现最差。
-
大多数度量仅计算轨迹的空间距离来衡量相似性;然而,当直接扩展到时间距离时(即使时间成本很高),它们在时空场景中也表现得非常有效。
-
基于点的度量在自由空间中表现更好;而基于段的度量在道路网络中更有效。此外,一些度量(例如,DTW 和 LCSS)在自由空间中可以直接扩展到道路网络,并保持良好的性能;而其他一些(例如,EDR 和 ERP)不适合调整到道路网络,这会影响其鲁棒性。
-
对于度量相似性度量,构建索引和探索基于三角不等式的剪枝可能有助于显著提高其效率。
-
在大多数情况下,基于学习的度量在不同规模的数据集上具有更高的时间消耗鲁棒性。基于单机的度量具有明显较低的效率和可扩展性,但具有更高的有效性。总体而言,基于分布式的度量能够在确保基于单机度量的高有效性的同时,提高时间性能,这在轨迹相似性度量的研究中具有前景。
7 未来研究方向
7.1 时效性(Temporality)
轨迹数据包括空间和时间信息。然而,现有的大多数轨迹相似性度量仅考虑空间信息,而只有TP 考虑了空间和时间信息。此外,TP的时间复杂度很高,因此无法有效地应用于需要捕捉时间依赖特性的下游任务(例如,交通流预测)。因此,设计考虑空间和时间信息的高效轨迹相似性度量是一个有趣的研究方向。
7.2 及时性(Timeliness)
随着位置服务和定位技术的广泛应用,大量的GPS轨迹数据作为流数据持续地被收集,这使得轨迹相似性计算更具挑战性。然而,现有的度量非常耗时,无法满足下游任务(例如,拼车)的实时需求。因此,实时或在线轨迹相似性计算也是一个潜在的研究方向。
7.3 隐私(Privacy)
由于私人位置信息的敏感性,在处理轨迹时需要保护隐私。现有的轨迹相似性度量没有考虑数据隐私,而且直接应用现有的度量以实现高查询效率/质量同时实现隐私保护是低效的。因此,在保护隐私的同时实现有效和高效的相似性计算也是一个值得关注的方向。
7.4 有效性(Effectiveness)
轨迹相似性计算的目标是为了促进下游的轨迹分析。由于存在各种相似性度量,如何为不同的分析任务选择合适的度量是非常重要的。例如,大多数现有的相似性度量(如DTW,NetERP等)是为轨迹检索和聚类设计的,但对于异常检测等任务则效果不佳。因此,将相似性度量的选择与下游任务相结合以提高轨迹分析的效果是一个有前途的方向。