NLP实战之textRNN中文文本分类
TextRNN论文:https://www.ijcai.org/Proceedings/16/Papers/408.pdf
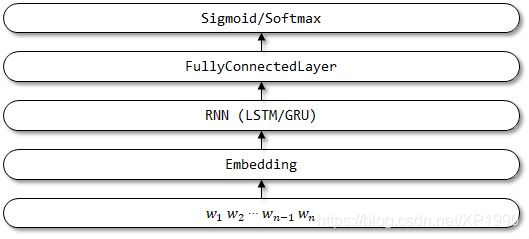
TextRNN网络结构:
环境:
windows 10、tensorflow版本为2.3.0
模型构建与训练
定义网络结构
定义TextRNN类
from tensorflow.keras import Input, Model
from tensorflow.keras.layers import Embedding, Dense, Dropout, LSTM
class TextRNN(object):
def __init__(self, maxlen, max_feature, embedding_dims, class_num=5, last_activation='softmax'):
self.maxlen = maxlen
self.max_feature = max_feature
self.embedding_dims = embedding_dims
self.class_num = class_num
self.last_activation = last_activation
def get_model(self):
input = Input((self.maxlen,))
embedding = Embedding(self.max_feature, self.embedding_dims, input_length=self.maxlen)(input)
x = LSTM(128)(embedding)
output = Dense(self.class_num, activation=self.last_activation)(x)
model = Model(inputs=input, outputs=output)
return model通用工具文件utils.py,内容如下:
# coding: utf-8
import sys
from collections import Counter
import numpy as np
import tensorflow.keras as kr
import os
if sys.version_info[0] > 2:
is_py3 = True
else:
reload(sys)
sys.setdefaultencoding('utf-8')
is_py3 = False
def open_file(filename, mode='r'):
'''
常用文件操作,可在python2和python3间切换
mode:'r' or 'w' for read or write
'''
if is_py3:
return open(filename, mode, encoding='utf-8', errors='ignore')
else:
return open(filename, mode)
def read_file(filename):
'''读取单个文件,文件中包含多个类别'''
contents = []
labels = []
with open_file(filename) as f:
for line in f:
try:
raw = line.strip().split('\t')
content = raw[1].split(' ')
if content:
contents.append(content)
labels.append(raw[0])
except:
pass
return contents, labels
def read_single_file(filename):
'''读取单个文件,文件为单一类型'''
contents = []
label = filename.split('\\')[-1].split('.')[0]
with open_file(filename) as f:
for line in f:
try:
content = line.strip().split(' ')
if content:
contents.append(content)
except:
pass
return contents, label
def read_files(dirname):
'''读取文件夹'''
contents = []
labels = []
files = [f for f in os.listdir(dirname) if f.endswith('.txt')]
for filename in files:
content, label = read_single_file(os.path.join(dirname, filename))
contents.extend(content)
labels.extend([label]*len(content))
return contents, labels
def build_vocab(train_dir, vocab_file, vocab_size=5000):
'''根据训练集构建词汇表,存储'''
data_train, _ = read_files(train_dir)
all_data = []
for content in data_train:
all_data.extend(content)
counter = Counter(all_data)
count_pairs = counter.most_common(vocab_size - 1)
words, _ = list(zip(*count_pairs))
#添加一个来将所有文本pad为同一个长度
words = [''] + list(words)
open_file(vocab_file, mode='w').write('\n'.join(words) + '\n')
def read_vocab(vocab_file):
'''读取词汇表'''
with open_file(vocab_file) as fp:
#如果是py2,则每个值都转化为unicode
words = [_.strip() for _ in fp.readlines()]
word_to_id = dict(zip(words, range(len(words))))
return words, word_to_id
def read_category():
'''读取分类,编码'''
categories = ['car', 'entertainment', 'military', 'sports', 'technology']
cat_to_id = dict(zip(categories, range(len(categories))))
return categories, cat_to_id
def encode_cate(content, words):
'''将id表示的内容转换为文字'''
return [(words[x] if x in words else 40000) for x in content]
def encode_sentences(contents, words):
'''将id表示的内容转换为文字'''
return [encode_cate(x, words) for x in contents]
def process_file(filename, word_to_id, cat_to_id, max_length=600):
'''将文件转换为id表示'''
contents, labels = read_file(filename)
data_id, label_id = [], []
for i in range(len(contents)):
data_id.append([word_to_id[x] for x in contents[i] if x in word_to_id])
label_id.append(cat_to_id[labels[i]])
#使用keras提供的pad_sequences来将文本pad为固定长度
x_pad = kr.preprocessing.sequence.pad_sequences(data_id, max_length)
y_pad = kr.utils.to_categorical(label_id, num_classes=len(cat_to_id)) #将标签转换为one-hot表示
return x_pad, y_pad
def batch_iter(x, y, batch_size=64):
'''生成批次数据'''
data_len = len(x)
num_batch = int((data_len-1) / batch_size) + 1
indices = np.random.permutation(np.arange(data_len))#随机无序排列
x_shuffle = x[indices]
y_shuffle = y[indices]
for i in range(num_batch):
start_id = i * batch_size
end_id = min((i+1) * batch_size, data_len)
yield x_shuffle[start_id:end_id], y_shuffle[start_id:end_id] 数据预处理与模型训练
from tensorflow.keras.preprocessing import sequence
import random
from sklearn.model_selection import train_test_split
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
from tensorflow.keras.utils import to_categorical
from model import TextRNN
from utils import *
import os
#路径等配置
data_dir = 'E:/personal/nlp/practice/processed_data'
vocab_file = 'E:/personal/nlp/practice/vocab/vocab.txt'
vocab_size = 40000
#神经网络配置
max_features = 40001
maxlen = 400
batch_size = 64
embedding_dims = 50
epochs = 10
print('数据预处理与加载数据。。。')
#如果不存在词汇表,重建
if not os.path.exists(vocab_file):
build_vocab(data_dir, vocab_file, vocab_size)
#获得词汇/类别与id映射字典
categories, cat_to_id = read_category()
words, word_to_id = read_vocab(vocab_file)
#全部数据
x, y = read_files(data_dir)
data = list(zip(x, y))
del x, y
#乱序
random.shuffle(data)
#切分训练集与测试集
train_data, test_data = train_test_split(data)
#对文本的词id和类别id进行编码
x_train = encode_sentences([content[0] for content in train_data], word_to_id)
y_train = to_categorical(encode_cate([content[1] for content in train_data], cat_to_id))
x_test = encode_sentences([content[0] for content in test_data], word_to_id)
y_test = to_categorical(encode_cate([content[1] for content in test_data], cat_to_id))
print('对序列做padding,保证是samples*timestep的维度')
x_train = sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = sequence.pad_sequences(x_test, maxlen=maxlen)
print('x_train shape:', x_train.shape)
print('x_test shape:', x_test.shape)
print('构建模型。。。。。')
model = TextRNN(maxlen, max_features, embedding_dims).get_model()
model.compile('adam', 'categorical_crossentropy', metrics=['accuracy'])
print('Train......')
early_stopping = EarlyStopping(monitor='val_accuracy', patience=2, mode='max')
modelcheckpoint = ModelCheckpoint('./rnn.model', verbose=1)
history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs,
callbacks=[early_stopping, modelcheckpoint],
validation_data=(x_test, y_test))
print('Test.........')
result = model.predict(x_test)
print(result)训练中信息输出、图片保存
import matplotlib.pyplot as plt
from pro_data import history
fig = plt.figure()
plt.plot(history.history['accuracy'], 'r', linewidth=3.0)
plt.plot(history.history['val_accuracy'], 'b', linewidth=3.0)
plt.legend(['Training Accuracy', 'Validation Accuracy'], fontsize=18)
plt.xlabel('Epochs', fontsize=16)
plt.ylabel('Accuracy', fontsize=16)
plt.title('Accuracy Curves: RNN', fontsize=16)
fig.savefig('accuracy_rnn.png')
plt.show()