远程RPC+插桩巧解瑞数5,人人都能懂的瑞数(附源码)
前言:
众所周知,rpc对于一些复杂的加密有奇效,我们只需要找到加密函数所在的位置即可通过RPC远程调用,从而省去了扣代码补环境等掉头发过程。本篇以维普期刊为例,一探瑞数的奥秘。
1、抓包分析请求接口
通过抓包分析可知,我们要找的url是SearchList?xxxx,对比可知该接口对字符串参数和cookie进行了加密操作。由此确定了我们这次要解的参数一共有两个G5tA5iQ4和GW1gelwM5yZuT。

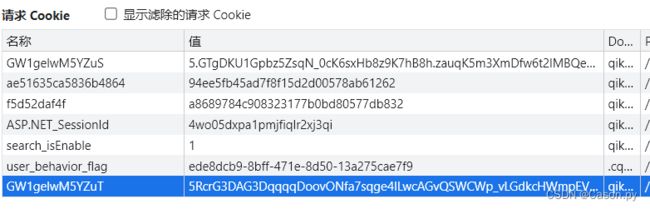
2.解密G5tA5iQ4参数
首先全局搜索G5tA5iQ4参数,发现无结果。进行跟栈send,打断点分析如下。
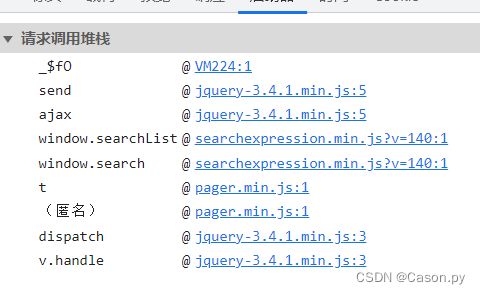

通过分析可知在u.open函数中对url进行了加密操作,继续跟进u.open函数找到加密函数_$BZ,传递的参数是"/Search/SearchList"。 导出_$BZ函数到全局保存。
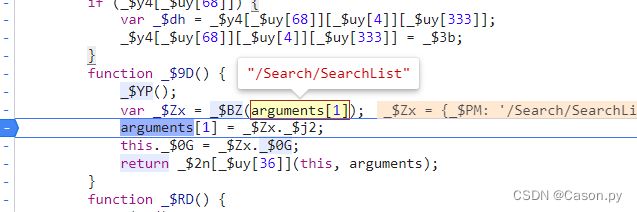
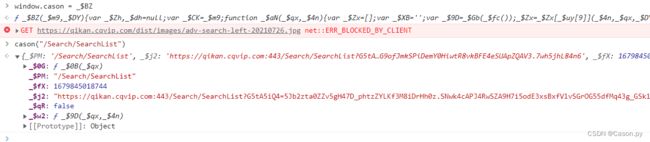
3.解密cookie加密参数GW1gelwM5yZuT
由于cookie通常保存在document中,因此我们对document.cookie进行hook定位。
window.cason_cookie = document.cookie;
Object.defineProperty(document, 'cookie', {
get:()=>{
return window.cason_cookie;
},
set:(x)=>{
debugger; window.cason_cookie = x;
}
})定位到cookie,跟堆栈向前查找。
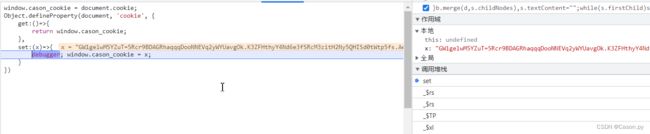
找到参数所在位置的变量名,添加断点。
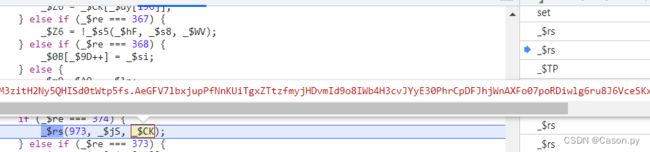
找到_$re的定义位置,添加日志断点,再次刷新还原打印函数的调用流程。


观察发现断点执行前的_$re值分别为275,276,457。定义window.casonIoo=[]继续添加条件断点打印验证。


逐步调试到_$re == 374,分析加密过程,找到加密位置与之前断点位置重合,证明分析流程正确。继续修改条件断点,打印出_$CK值的变化。


由此可知加密过程发生在_$re值为457--276之间,修改条件断点使其定位到加密之前457。

找到加密函数跟栈分析


确定加密函数为_$rs,导出保存到全局。成功拿到加密值

4.RPC本地调用取值
我们成功通过导出全局的方式拿到了需要加密的两个参数
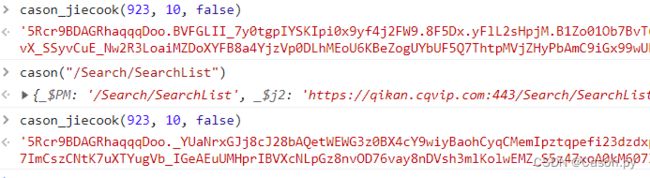
之后我们可以通过RPC在本地部署调用请求,RPC操作详情参考python通过RPC远程调用获取请求参数实例
成功后截图如下


总结:
本文通过hook,插桩,跟栈,RPC等一系列操作成功破解瑞数5加密,由于没有实现本地运行属于取巧的一种方法,对于爬取一些需求量不大但加密繁琐的网站还是十分合适。解密思路来源于B站up主陈不不and挽风的逆向的一期视频js逆向瑞数5解密讲解与插桩讲解,感兴趣的可以观看原视频。如果本篇文章对您有帮助还请给个免费的赞支持一下哦~
附源码:
# coding:utf-8
import requests
from lxml import etree
def get_url_cookie():
rpc_url = 'http://127.0.0.1:9420/cbb?type=S&webId=1001&data=12'
res = requests.get(rpc_url)
wp_url = 'http://qikan.cqvip.com:80/Search/SearchList?' + \
res.text.split('http://qikan.cqvip.com:80/Search/SearchList?')[1].split('"')[0]
wp_cookie = 'GW1gelwM5YZuS=5.GTgDKU1Gpbz5ZsqN_0cK6sxHb8z9K7hB8h.zauqK5m3XmDfw6t2lMBQerygmlEioWgsndYhhKNP5A2bFIe7na; ae51635ca5836b4864=94ee5fb45ad7f8f15d2d00578ab61262; f5d52daf4f=a8689784c908323177b0bd80577db832; ASP.NET_SessionId=4wo05dxpa1pmjfiqlr2xj3qi; search_isEnable=1; GW1gelwM5YZuT=' + \
res.text.split('false},"')[1].split('"]')[0]
return wp_url, wp_cookie
def get_content():
for i in range(1, 11):
wp_url, wp_cookie = get_url_cookie()
headers = {
'Cookie': wp_cookie,
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Origin': 'http://qikan.cqvip.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'
}
data = {
'searchParamModel': '{"ObjectType":1,"SearchKeyList":[],"SearchExpression":null,"BeginYear":null,"EndYear":null,"UpdateTimeType":null,"JournalRange":null,"DomainRange":null,"ClusterFilter":"","ClusterLimit":0,"ClusterUseType":"Article","UrlParam":"U=人工智能","Sort":"0","SortField":null,"UserID":"0","PageNum":%s,"PageSize":20,"SType":null,"StrIds":null,"IsRefOrBy":0,"ShowRules":" 任意字段=人工智能 ","IsNoteHistory":0,"AdvShowTitle":null,"ObjectId":null,"ObjectSearchType":0,"ChineseEnglishExtend":0,"SynonymExtend":0,"ShowTotalCount":143588,"AdvTabGuid":""}' % i
}
res = requests.post(wp_url, data=data, headers=headers)
html = etree.HTML(res.text)
title_list = html.xpath('//*[@id="remark"]/dl/dt/a')
t = ''
for title in title_list:
for x in title.xpath('.//text()'):
t += x
print(t)
t = ''
def main():
get_content()
if __name__ == '__main__':
main()