Prompt tuning
转载自:NLP新宠——浅谈Prompt的前世今生_zenRRan的博客-CSDN博客
0.NLP新宠——浅谈Prompt的前世今生
0.1 Prompt的产生和兴起
近几年来,有关预训练语言模型(PLM)的研究比比皆是,自然语言处理(NLP)也借着这股春风获得了长足发展。尤其是在2017-2019年间,研究者们的重心逐渐从传统task-specific的有监督模式转移到预训练上。基于预训练语言模型的研究思路通常是“pre-train, fine-tune”,即将PLM应用到下游任务上,在预训练阶段和微调阶段根据下游任务设计训练对象并对PLM本体进行调整。
随着PLM体量的不断增大,对其进行fine-tune的硬件要求、数据需求和实际代价也在不断上涨。除此之外,丰富多样的下游任务也使得预训练和微调阶段的设计变得繁琐复杂,因此研究者们希望探索出更小巧轻量、更普适高效的方法,Prompt就是一个沿着此方向的尝试。
融入了Prompt的新模式大致可以归纳成”pre-train, prompt, and predict“,在该模式中,下游任务被重新调整成类似预训练任务的形式。例如,通常的预训练任务有Masked Language Model, 在文本情感分类任务中,对于 "I love this movie." 这句输入,可以在后面加上prompt "The movie is ___" 这样的形式,然后让PLM用表示情感的答案填空如 "great"、"fantastic" 等等,最后再将该答案转化成情感分类的标签,这样以来,通过选取合适的prompt,我们可以控制模型预测输出,从而一个完全无监督训练的PLM可以被用来解决各种各样的下游任务。
因此,合适的prompt对于模型的效果至关重要。大量研究表明,prompt的微小差别,可能会造成效果的巨大差异。研究者们就如何设计prompt做出了各种各样的努力——自然语言背景知识的融合、自动生成prompt的搜索、不再拘泥于语言形式的prompt探索等等,笔者将会在第三节进行进一步讨论。
0.2 什么是Prompt
Prompt刚刚出现的时候,还没有被叫做Prompt,是研究者们为了下游任务设计出来的一种输入形式或模板,它能够帮助PLM“回忆”起自己在预训练时“学习”到的东西,因此后来慢慢地被叫做Prompt了。
对于输入的文本 ,有函数
,有函数![]() ,将转化成prompt的形式
,将转化成prompt的形式![]() ,即:
,即:
![]()
该函数通常会进行两步操作:
-
使用一个模板,模板通常为一段自然语言,并且包含有两个空位置:用于填输入
的位置![[X]](http://img.e-com-net.com/image/info8/c1efe1f72e8f417fa68d5813013c6452.png) 和用于生成答案文本
和用于生成答案文本 的位置
的位置![[Z]](http://img.e-com-net.com/image/info8/a834233f5f01456095edf9882b08b2c1.png) .
. -
把输入
填到的位置。
还用前文提到的例子。在文本情感分类的任务中,假设输入是
" I love this movie."
使用的模板是
" [X] Overall, it was a [Z] movie."
那么得到的![]() 就应该是 "I love this movie. Overall it was a [Z] movie."
就应该是 "I love this movie. Overall it was a [Z] movie."
在实际的研究中,prompts应该有空位置来填充答案,这个位置一般在句中或者句末。如果在句中,一般称这种prompt为cloze prompt;如果在句末,一般称这种prompt为prefix prompt。 [X] 和[Z] 的位置以及数量都可能对结果造成影响,因此可以根据需要灵活调整。
另外,上面的例子中prompts都是有意义的自然语言,但实际上其形式并不一定要拘泥于自然语言。现有相关研究使用虚拟单词甚至直接使用向量作为prompt,笔者将会在第三节讲到。
下一步会进行答案搜索,顾名思义就是LM寻找填在[Z] 处可以使得分数最高的文本![]() 。最后是答案映射。有时LM填充的文本并非任务需要的最终形式,因此要将此文本映射到最终的输出
。最后是答案映射。有时LM填充的文本并非任务需要的最终形式,因此要将此文本映射到最终的输出 。例如,在文本情感分类任务中,"excellent", "great", "wonderful" 等词都对应一个种类 "++",这时需要将词语映射到标签再输出。
。例如,在文本情感分类任务中,"excellent", "great", "wonderful" 等词都对应一个种类 "++",这时需要将词语映射到标签再输出。
0.3 Prompt的设计
Prompt大致可以从下面三个角度进行设计:
-
Prompt的形状
-
手工设计模板
-
自动学习模板
Prompt的形状
Prompt的形状主要指的是 [X] 和[Z] 的位置和数量。上文提到过cloze prompt和prefix prompt的区别,在实际应用过程中选择哪一种主要取决于任务的形式和模型的类别。cloze prompts和Masked Language Model的训练方式非常类似,因此对于使用MLM的任务来说cloze prompts更加合适;对于生成任务来说,或者使用自回归LM解决的任务,prefix prompts就会更加合适;Full text reconstruction models较为通用,因此两种prompt均适用。另外,对于文本对的分类,prompt模板通常要给输入预留两个空,![]() 和
和![]() 。
。
手工设计模板
Prompt最开始就是从手工设计模板开始的。手工设计一般基于人类的自然语言知识,力求得到语义流畅且高效的模板。例如,Petroni等人在著名的LAMA数据集中为知识探针任务手工设计了cloze templates;Brown等人为问答、翻译和探针等任务设计了prefix templates。手工设计模板的好处是较为直观,但缺点是需要很多实验、经验以及语言专业知识,代价较大。
自动学习模板
为了解决手工设计模板的缺点,许多研究开始探究如何自动学习到合适的模板。自动学习的模板又可以分为离散(Discrete Prompts)和连续(Continuous Prompts)两大类。离散的主要包括 Prompt Mining, Prompt Paraphrasing, Gradient-based Search, Prompt Generation 和 Prompt Scoring;连续的则主要包括Prefix Tuning, Tuning Initialized with Discrete Prompts 和 Hard-Soft Prompt Hybrid Tuning。
Prompt范式的第一个阶段,就是在输入上加Prompt文本,再对输出进行映射。但这种方式怎么想都不是很优雅,无法避免人工的介入。即使有方法可以批量挖掘,但也有些复杂(有这个功夫能标不少高质量语料),而且模型毕竟是黑盒,对离散文本输入的鲁棒性很差:

怎么办呢?离散的不行,那就连续的呗
用固定的token代替prompt,拼接上文本输入,当成特殊的embedding输入,这样在训练时也可以对prompt进行优化,就减小了prompt挖掘、选择的成本。
来自:《Prompt Tuning 近期研究进展 - 知乎 (zhihu.com)》
1.更为普适的Prompt tuning
《P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks》
摘要: Prompt tuning,冻结预训练的语言模型只微调连续的提示部分,大大减少了训练时每个任务的存储和内存使用。然而,在 NLU 的背景下,先前的工作和结果表明,现有的即时调整方法对于正常大小的预训练模型和困难任务表现不佳,表明缺乏通用性。作者提出了一个新的经验发现,即适当优化的即时调整可以在广泛的模型规模和 NLU 任务中普遍有效,它与微调的性能相匹配,而只有 0.1%-3% 的调整参数。作者提出的 P-Tuning v2 不是一种新方法,而是针对 NLU 优化和改编的前缀调整版本。鉴于 P-Tuning v2 的通用性和简单性,作者相信它可以作为微调的替代方案和未来研究的强大基线。
主要研究问题:Prompt tuning 在中小型预训练模型上(参数小于等于10B)以及困难任务上如(抽取式QA和序列标注)表现不佳,需要一个更为通用的微调方法。
在介绍这篇文章的方法之前,首先简单介绍一下P-tuning v1:
《GPT Understands, Too》
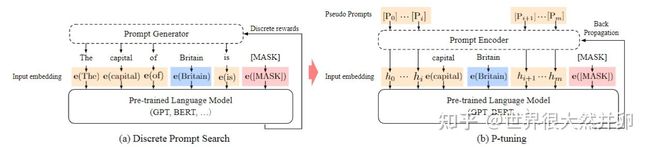
这篇文章其实就是在之前手工设计离散prompt的基础上,将离散的token设计为连续的可学习的参数,只保留一些关键的信息,如capital这种词汇。这里的prompt的参数只在embedding层,并且位置比较随意。
本文模型:
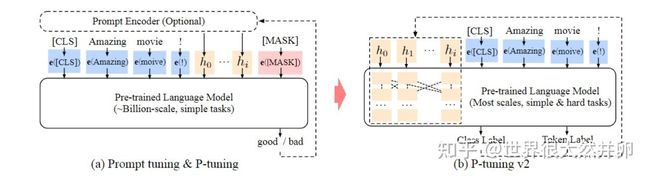
这篇文章就是P-tuning的改进版本。首先借鉴了Prefix-tuning的思路,将prompt信息作为前缀加入;其次是一个深层的前缀,即在模型的每一层前面都添加上前缀,以尽可能挖掘信息并且额外添加的参数并不会很大。
另外,作者去除了之前的重参数化方法;并且引入了多任务学习,比如说,在 NER 中,可以同时训练多个数据集,不同数据集使用不同的顶层 classifer,但是 prefix continuous prompt 是共享的;最后就是删除了之前的verbalizer。因为并不是每一个任务都需要有意义的标签,因此作者为了更为通用的框架,回归到最初的CLS+MLP头的范式。
2.Prompt tuning用于迁移学习
《SPoT: Better Frozen Model Adaptation through Soft Prompt Transfer》
摘要:随着预训练的语言模型越来越大,人们对将这些模型应用于下游任务的参数高效方法的兴趣也越来越大。 在之前P-tuning方法的基础上,作者提出了一种基于提示的迁移学习方法,称为SPOT:软提示转移。SPOT首先学习一个或多个源任务的提示,然后用它来初始化目标任务的提示。 作者表明,SPOT显著地提高了PROMPT-TUNING在许多任务中的性能。 更重要的是,SPOT与模型fine-tuning效果可比,甚至优于fine-tuning,而参数效率更高(最多可减少27,000倍的特定任务参数)。 作者进一步对26个NLP任务和160个源-目标任务的组合进行了大规模的任务转移性研究,并证明了任务往往可以通过及时转移而相互受益。最后,作者提出了一个简单而高效的检索方法,该方法将任务提示作为任务嵌入来识别任务之间的相似性,并预测一个给定的新目标任务的最可转移的源任务。
研究问题:作者上面已经提到了主要的思路,就是通过上游任务学习到的prompt来初始化下游的任务prompt。因此这里产生了两个问题:
- 对于一个给定的目标任务,什么时候应该将学习到的prompt用于目标任务
- 能否通过学到的prompt,更为准确的为目标任务选择最合适的源任务
3.一个「PPT」框架,让超大模型调参变简单:清华刘知远、黄民烈团队力作
近年来,微调预训练语言模型(PLM)取得了很大进展。通过微调 PLM 的全部参数,从大规模无标签语料库中获得的多方面知识可以用于处理各种 NLP 任务,并优于从头学习模型的方法。为简单起见,此处将这种全模型调整(full-model tuning)称为 FT。
如下图 1 (b) 和 (c)所示,主流的 FT 方法共有两种。第一种是任务导向的微调,在 PLM 上添加一个 task-specific 的头(head),然后通过优化 task-specific 训练数据上的 task-specific 学习目标,来微调整个模型。

第二种是以 prompt 为导向的微调,其灵感来自最近的一些研究,这些研究利用语言 prompt 来激发 PLM 的知识。在以 prompt 为导向的微调中,数据样本被转换为包含 prompt token 的线性序列,所有的下游任务都被转化为语言建模问题。
如图 1 (c) 所示,通过在句子中添加 prompt(It was [X]),我们可以根据 PLM 在掩码位置给出的预测结果(great 或 terrible)来确定这个句子到底是积极还是消极。
如图 1 所示,与以任务为导向的微调相比,在目标方面(掩码语言建模),以 prompt 为导向的微调更类似于预训练,因此有助于更好地利用 PLM 中的知识,通常也能取得更好的结果。
尽管上述 FT 方法已经显示出很好的结果,但随着模型规模的迅速扩张,为每个下游任务微调一个完整的大模型正变得越来越昂贵。为了应对这一挑战,来自谷歌的 Brian Lester 等人在《 The Power of Scale for Parameter-Efficient Prompt Tuning 》中提出了 prompt tuning(PT),以降低为下游任务微调大模型的成本,如图 1 (d)所示。
具体来说,PT 采用包含连续嵌入的 soft prompt 代替 hard prompt(离散语言短语)。这些连续 prompt 嵌入通常是随机初始化和端到端学习的。为了避免为每个下游任务存储整个模型,PT 冻结了 PLM 的所有参数,只调整 soft prompt,无需添加任何中间层和 task-specific 组件。尽管 PT 具有很少的可调参数和简单的设计,但它仍然可以媲美 FT,如图 2(a)所示。
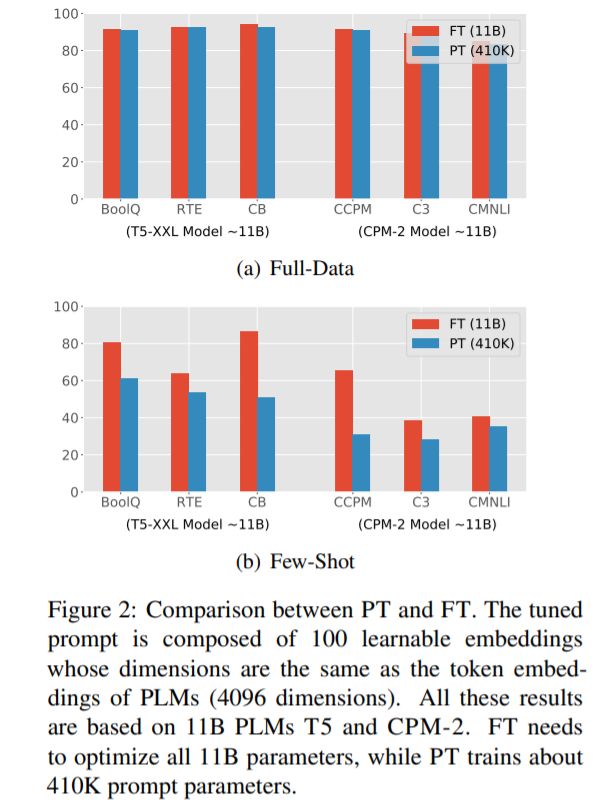
PT 有两个非常有前景的优势:1)与 hard prompt 相比,soft prompt 可以端到端学习;2)PT 是大规模 PLM 实际应用的一种高效、有效的范式。然而,如图 2 (b)所示,在 few-shot 场景下,PT 的表现比 FT 差很多,这可能会阻碍 PT 在各种低资源场景下的应用。
因此,在这篇论文中,来自清华大学的 Yuxian Gu、Xu Han、刘知远、黄民烈四位研究者广泛探索了如何通过 PT 以高效和有效的方式使用 PLM 进行 few-shot 学习。
具体来说,在论文的第二部分,他们进行了试点实验,分析了 PT 在大规模 PLM 中用于 few-shot 学习的有效性,这是现在很多研究所忽略的问题。他们发现:1)verbalizer 的选择对于性能有很大的影响;2)简单地用具体的词嵌入初始化 soft prompt 并不能提高性能;3)将 soft 和 hard prompt 结合起来很有帮助;4)所有这些方法都不能很好地处理 few-shot prompt 调优问题。上述观察结果表明,为大规模 PLM 找到合适的 prompt 并非易事,而精心设计的 soft prompt token 初始化至关重要。