go语言基本操作---三

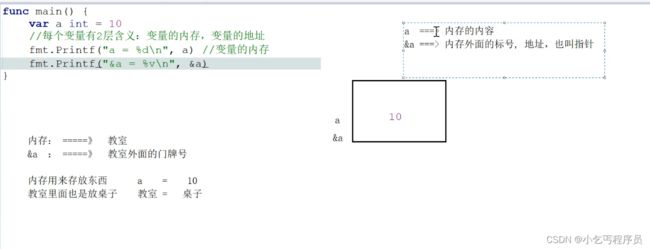
变量的内存和变量的地址
指针是一个代表着某个内存地址的值。这个内存地址往往是在内存中存储的另一个变量的值的起始位置。Go语言对指针的支持介于java语言和C/C+语言之间,它即没有想Java语言那样取消了代码对指针的直接操作的能力,也避免了C/C+语言中由于对指针的滥用而造成的安全和可靠性问题。
package main
import "fmt"
func main() {
var a int = 10
//每个变量有2层含义,变量的内存,变量的地址
fmt.Printf("a = %d\n", a) //变量的内存 10
fmt.Printf("&a = %p\n", &a) //变量的地址 0xc00000a0c8
}
指针变量的基本使用
//保存某个变量的地址,需要指针类型,*int保存int的地址 **int保存*int地址
var a int = 10
var p *int //定义只是特殊的声明
p = &a //指针变量指向谁,就把谁的地址赋值给指针变量
fmt.Printf("p = %p, &a = %p\n", p, &a) //p = 0xc00000a0c8, &a = 0xc00000a0c8
*p = 666 //*p操作的不是p的内存是所指向的内存a
fmt.Printf("*p = %d,a = %d\n", *p, a) //*p = 666,a = 666

不要操作没有合法的指向的内存
var p *int
p = nil
fmt.Println("p = ", p) //new函数的使用
表达式new(T)将创建一个T类型的匿名变量,所做的是T类型的新值分配并清零一块内存空间,然后将这块内存空间的地址作为结果返回,而这个结果就是指向这个新的T类型值的指针值,返回的指针类型为*T。
//a :=10 //整型变量a
var p *int
//指向一个合法内存
p = new(int) //p是*int,执行int类型 new为没有名字的内存
*p = 666
fmt.Println("*p = ", *p)
q :=new(int)
*q = 777
我们只需使用new函数,无需担心其内存的生命周期或怎样将其删除,因为go语言的内存管理系统会帮我们打理一切。
普通变量做函数参数(值传递)
package main
import "fmt"
func swap(a, b int) {
a, b = b, a
fmt.Printf("swap: a = %d, b = %d\n", a, b) // 20 10
}
func main() {
a, b := 10, 20
//通过一个函数交换a和b的内存
swap(a, b) //变量本身传递,值传递
fmt.Printf("main: a = %d, b = %d\n", a, b) //10 20
}
指针做函数参数(地址传递)
package main
import "fmt"
func swap(p1, p2 *int) {
*p1, *p2 = *p2, *p1
fmt.Printf("swap: *p1 = %d, *p2 = %d\n", *p1, *p2) // 20 10
}
func main() {
a, b := 10, 20
//通过一个函数交换a和b的内存
swap(&a, &b) //地址传递
fmt.Printf("main: a = %d, b = %d\n", a, b) //20 10
}
数组的基本操作
数组是指一系列同一类型数据的集合。数组中包含的每个数据被称为数组元素,一个数组包含的元素个数被称为数组长度。
package main
import "fmt"
func main() {
//定义一个数组[10]int和[5]int是不同类型
//[数组],这个数字作为数组元素个数
var a [10]int
var b [5]int
fmt.Printf("len(a) = %d, len(b) = %d\n", len(a), len(b))
// 注意:定义数组是,数组元素个数必须是常量
//n := 10
//var c [n]int //error non-constant array bound n
//操作数组元素,从0开始,到len()-1,不对称元素,这个数字,叫下标
//这是下标,可以是变量或常量
a[0] = 1
i := 1
a[i] = 2
//赋值,每个元素
for i := 0; i < len(a); i++ {
a[i] = i + 1
}
//打印 第一个返回下标,第二个返回元素
for i, data := range a {
fmt.Printf("a[%d] = %d\n", i, data)
}
}
数组初始化
//声明定义同时赋值,叫初始化
//1 全部初始化
var a [5]int = [5]int{1, 2, 3, 4, 5}
fmt.Println("a = ", a) //a = [1 2 3 4 5]
b := [5]int{1, 2, 3, 4, 5}
fmt.Println("b = ", b) //b = [1 2 3 4 5]
//部分初始化,没有初始化的元素,自动赋值为0
c := [5]int{1, 2, 3}
fmt.Println("c = ", c) //c = [1 2 3 0 0]
//指定某个元素初始化
d := [5]int{2: 10, 4: 20}
fmt.Println("d = ", d) //d = [0 0 10 0 20]
二维数组的介绍
//有多个[]就是多少维
//有多少个[]就用多少个循环
var a [3][4]int
k := 0
for i := 0; i < 3; i++ {
for j := 0; j < 4; j++ {
k++
a[i][j] = k
fmt.Printf("a[%d][%d] = %d, ", i, j, a[i][j])
}
fmt.Printf("\n")
}
fmt.Println("a = ", a) //a = [[1 2 3 4] [5 6 7 8] [9 10 11 12]]
//有3个元素,每个元素又是一维数组[4]int
b := [3][4]int{
{1, 2, 3, 4},
{5, 6, 7, 8},
{9, 10, 11, 12},
}
fmt.Println("b = ", b) //b = [[1 2 3 4] [5 6 7 8] [9 10 11 12]]
//部分初始化没有初始化的值为0
c := [3][4]int{
{1, 2, 3},
{5, 6, 7, 8},
{9, 10},
}
fmt.Println("c = ", c) //c = [[1 2 3 0] [5 6 7 8] [9 10 0 0]]
//部分初始化没有初始化的值为0
d := [3][4]int{
{1, 2, 3},
{5, 6, 7, 8},
}
fmt.Println("d = ", d) //d = [[1 2 3 0] [5 6 7 8] [0 0 0 0]]
//部分初始化没有初始化的值为0
e := [3][4]int{0: {1, 2, 3, 4}, 1: {5, 6, 7, 8}}
fmt.Println("e = ", e) //e = [[0 0 0 0] [5 6 7 8] [0 0 0 0]]
数组比较和赋值
//支持比较,只支持==或!=,比较每一个元素都一样,2个数组比较,数组类型要一样
a := [5]int{1, 2, 3, 4, 5}
b := [5]int{1, 2, 3, 4, 5}
c := [5]int{1, 2, 3}
fmt.Println("a == b ", a == b) //true
fmt.Println("a == c ", a == c) //false
//同类型的数组可以赋值
var d [5]int
d = a
fmt.Println("d = ", d) //d = [1 2 3 4 5]
随机数的使用
package main
import (
"fmt"
"math/rand"
"time"
)
func main() {
//设置种子,只需要一次
//如果种子参数一样,每次运行程序产生的随机数都一样
//rand.Seed(666)
//for i := 0; i < 5; i++ {
// //产生随机数
// fmt.Println("rand = ", rand.Int())//随机数很大的范围
//}
//rand.Seed(time.Now().UnixNano()) //以当前系统时间作为种子参数
//for i := 0; i < 5; i++ {
// //产生随机数
// fmt.Println("rand = ", rand.Int()) //随机数很大的范围
//}
rand.Seed(time.Now().UnixNano()) //以当前系统时间作为种子参数
for i := 0; i < 5; i++ {
//产生随机数
fmt.Println("rand = ", rand.Intn(100)) //限制在100内的数
}
}
冒泡排序代码实现
rand.Seed(time.Now().UnixNano()) //以当前系统时间作为种子参数
var a [10]int
for i := 0; i < len(a); i++ {
a[i] = rand.Intn(100) //100以内的随机数
fmt.Printf("%d, ", a[i])
}
fmt.Printf("\n")
//冒泡排序 挨着的2个元素比较,升序(大于则交换)
for i := 0; i < len(a)-1; i++ {
for j := 0; j < len(a)-1-i; j++ {
if a[j] > a[j+1] {
a[j], a[j+1] = a[j+1], a[j]
}
}
}
fmt.Printf("\n排序后:\n")
for i := 0; i < len(a); i++ {
fmt.Printf("%d, ", a[i])
}
fmt.Printf("\n")
数组做函数参数是值拷贝
package main
import "fmt"
// 数组做函数参数,他是值传递
// 实参数组的每个元素给形参数组拷贝一份
// 形参数组是实参的复制品,数组越大,拷贝的效率越低
func modify(a [5]int) {
a[0] = 666
fmt.Println("modify a = ", a)//modify a = [666 2 3 4 5]
}
func main() {
a := [5]int{1, 2, 3, 4, 5}
modify(a) //数组传递过去
fmt.Println("main: a = ", a) //main: a = [1 2 3 4 5]
}
数组指针做函数参数
package main
import "fmt"
// P指向实参数组a,他是数组指针
// *p代表指针所指向的内存,就是实参a
func modify(p *[5]int) {
(*p)[0] = 666
fmt.Println("modify a = ", *p)
}
func main() {
a := [5]int{1, 2, 3, 4, 5}
//modify a = [666 2 3 4 5]
//main: a = [666 2 3 4 5]
modify(&a) //地址传递
fmt.Println("main: a = ", a)
}
切片
切片并不是数组或数组指针,它通过内部指针和相关属性引用数组片段,以实现边长方案。
slice并不是真正意义上的动态数组,而是一个引用类型。slice总是指向一个底层array,slice的声明也可以像array一样,只是不需要长度

a := []int{1, 2, 3, 4, 5}
s := a[0:3:5] //左闭右开
fmt.Println("s = ", s) // s = [1,2,3]
fmt.Println("len(s) = ", len(s)) //长度 //3 3-0
fmt.Println("cap(s) = ", cap(s)) //容量 //5 5-0
s1 := a[1:4:5] //左闭右开
fmt.Println("s = ", s1) // 从下标1开始,取4-1=3个 s = [2 3 4]
fmt.Println("len(s) = ", len(s1)) //长度 //3 4-1
fmt.Println("cap(s) = ", cap(s1)) //容量 //4 5-1
切片和数组区别
//切片和数组的区别
//数组[]里面的长度是固定的一个常量,数组不能修改长度,len和cap永远都是5
a := [5]int{}
fmt.Printf("len = %d, cap = %d\n", len(a), cap(a)) //len = 5, cap = 5
//切片,[]里面为空,或者为....切片的长度或容易可以不固定
s := []int{}
fmt.Printf("1: len = %d, cap = %d\n", len(s), cap(s)) //1: len = 0, cap = 0
s = append(s, 11) //给切片末尾追加一个成员
fmt.Printf("append: len = %d, cap = %d\n", len(s), cap(s)) //append: len = 1, cap = 1
切片的创建
//自动推导类型 同时初始化
s1 := []int{1, 2, 3, 4}
fmt.Println("s1 = ", s1) //s1 = [1 2 3 4]
//借助make函数 格式make(切片类型,长度,容量)
s2 := make([]int, 5, 10)
fmt.Printf("len = %d, cap = %d\n", len(s2), cap(s2)) //len = 5, cap = 10
//没有指定容量,容量和长度一样
s3 := make([]int, 5)
fmt.Printf("len = %d, cap = %d\n", len(s3), cap(s3)) //len = 5, cap = 5
切片截取

array := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
//[low:high:max] 取下标从low开始的元素,len = high-low,cap=max-low
s1 := array[:] //[0:len(array):len(array)] 不指定容量和长度一样
fmt.Println("s1 = ", s1) //s1 = [0 1 2 3 4 5 6 7 8 9]
fmt.Printf("len = %d, cap = %d\n", len(s1), cap(s1)) //10 10
//操作某个元素和数组操作方式一样
data := array[0]
fmt.Println("data = ", data) //0
s2 := array[3:6:7] //a[3] a[4] a[5] len = 3 cap =4
fmt.Println("s2 = ", s2) //3 4 5
fmt.Printf("len = %d, cap = %d\n", len(s2), cap(s2)) //3 4
s3 := array[:6] //从0开始,取6个元素,容量是10 容量为数组长度
fmt.Println("s3 = ", s3) //[0 1 2 3 4 5]
fmt.Printf("len = %d, cap = %d\n", len(s3), cap(s3)) // 6 10
s4 := array[3:] //从下标为3开始,到结尾
fmt.Println("s4 = ", s4) //[3 4 5 6 7 8 9]
fmt.Printf("len = %d, cap = %d\n", len(s4), cap(s4)) //len = 7, cap = 7
切片和底层数组关系

a := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
s1 := a[2:5] //从a[2]开始取三个元素
fmt.Println("s1 =", s1) //[2 3 4]
s1[1] = 666
fmt.Println("s1 =", s1) //s1 = [2 666 4]
fmt.Println("a = ", a) //a = [0 1 2 666 4 5 6 7 8 9]
s2 := s1[1:7]
fmt.Println("s2 = ", s2) //s2 = [666,4 5 6 7 8]
s2[2] = 777
fmt.Println("s2 = ", s2) //s2 = [666 4 777 6 7 8]
fmt.Println("a = ", a) //a = [0 1 2 666 4 777 6 7 8 9]
内建函数------append
append函数向切片尾部添加数据,返回新的切片对象,容量不够,会自动扩容
s1 := []int{}
fmt.Printf("len = %d ,cap = %d\n", len(s1), cap(s1)) // 0 0
fmt.Println("s1 = ", s1) //[]
//在原切片的末尾添加元素
s1 = append(s1, 1)
s1 = append(s1, 2)
s1 = append(s1, 3)
fmt.Printf("len = %d ,cap = %d\n", len(s1), cap(s1)) // 3 4 容量以两倍的速度增加的
fmt.Println("s1 = ", s1) // 1 2 3
s2 := []int{1, 2, 3}
fmt.Println("s2 = ", s2) //1 2 3
s2 = append(s2, 5)
s2 = append(s2, 5)
s2 = append(s2, 5)
fmt.Println("s2 = ", s2) //s2 = [1 2 3 5 5 5]
append扩容特点
一旦超过原底层数组容量,通常以2倍容量重新分配底层数组,并复制原来的数据
//如果超过原来的容量,通常以2倍容量扩容
s := make([]int, 0, 1) //cap 1 len 0
oldCap := cap(s)
for i := 0; i < 8; i++ {
s = append(s, i)
if newCap := cap(s); oldCap < newCap {
fmt.Printf("cap: %d ====>%d\n", oldCap, newCap) //cap: 1 ====>2 cap: 2 ====>4 cap: 4 ====>8
oldCap = newCap
}
}
内建函数copy
srcSlice := []int{1, 2}
dstSlice := []int{6, 6, 6, 6, 6}
copy(dstSlice, srcSlice)
fmt.Println("dst", dstSlice) //dst [1 2 6 6 6]
切片做函数参数
切片为引用传递
package main
import (
"fmt"
"math/rand"
"time"
)
func InitData(s []int) {
rand.Seed(time.Now().UnixNano()) //设置种子
for i := 0; i < len(s); i++ {
s[i] = rand.Intn(100) //100以内的随机数
}
}
func BubbleSort(s []int) {
n := len(s)
for i := 0; i < n-1; i++ {
for j := 0; j < n-1-i; j++ {
if s[j] > s[j+1] {
s[j], s[j+1] = s[j+1], s[j]
}
}
}
}
func main() {
var n int = 10
//创建一个切片,len为n
s := make([]int, n)
InitData(s)
fmt.Println("排序前 s = ", s)
BubbleSort(s) //冒泡排序
fmt.Println("排序后 s = ", s)
}
猜数字游戏
package main
import (
"fmt"
"math/rand"
"time"
)
// 创建一个数字
func CreatNum(p *int) {
rand.Seed(time.Now().UnixNano())
var num int
for {
num = rand.Intn(10000)
if num >= 1000 {
break
}
}
//fmt.Println("num = ", num)
*p = num
}
// 取出每一位
func GetNum(s []int, num int) {
s[0] = num / 1000 //取千位
s[1] = num % 1000 / 100 //取百位
s[2] = num % 100 / 10 //取十位
s[3] = num % 10 //取个位
}
// 猜数字逻辑
func OnGame(randSlice []int) {
var num int
keySlice := make([]int, 4)
for {
for {
fmt.Printf("请输入一个4位数")
fmt.Scan(&num)
if 999 < num && num < 10000 {
break
}
fmt.Println("请输入的数不符合要求")
}
//fmt.Println("num = ", num)
GetNum(keySlice, num)
//fmt.Println("keySlice = ", keySlice)
n := 0
for i := 0; i < 4; i++ {
if randSlice[i] < keySlice[i] {
fmt.Printf("第%d位大了一点\n", i+1)
} else if keySlice[i] < randSlice[i] {
fmt.Printf("第%d位小了一点\n", i+1)
} else {
fmt.Printf("第%d位猜对了\n", i+1)
n++
}
}
if n == 4 { //4位都猜对了
fmt.Println("全部猜对")
return
}
}
}
func main() {
var randNum int //产生随机的数
//产生一个4位的随机数
CreatNum(&randNum)
//fmt.Println("randNum: ", randNum)
//切片
randSlice := make([]int, 4)
//保存这个4位数的每一位
GetNum(randSlice, randNum)
//fmt.Println("randSlice = ", randSlice)
//n1 := 1234 / 1000 //取商
//n2 := (1234 % 1000)/100 //取余 结果为234
//fmt.Println("n1 = ", n1)
//fmt.Println("n2 = ", n2)
OnGame(randSlice) //游戏
}
map介绍
Go语言中的map(映射,字典)是一种内置的数据结构,他是一个无序的key-value对的集合。
在一个map里所有的键都是唯一的,而且必须是支持==和!=操作符的类型,切片。函数以及包含切片的结构类型这些类型由于具有引用语句,不能作为映射的键,使用这些类型会造成便于错误
![]()

map值可以是任意类型,没有限制。map里所有键的数据类型必须是相同的,值也必须如何,但键值的数据类型可以不相同。
注意:map是无序的,我们无法决定它的返回顺序,所以,每次打印结果的顺序有可能不同。
map的基本操作
//map创建
//定义一个变量,类型为map[int]string
var m1 map[int]string
fmt.Println("m1 = ", m1) //m1 = map[]
//对于map只有len,没有cap
fmt.Println("len = ", len(m1)) //0
//可以通过make创建
m2 := make(map[int]string)
fmt.Println("m2 = ", m2) //m2 = map[]
fmt.Println("len = ", len(m2)) //0
//可以通过make创建,可以指定长度,只是指定了容量,但是里面却是一个数据也没有
m3 := make(map[int]string, 10)
m3[1] = "mike"
m3[3] = "c++"
m3[2] = "go"
fmt.Println("m3 = ", m3) //m3 = map[1:mike 2:go 3:c++]
fmt.Println("len = ", len(m3)) //3
//键值是唯一的
m4 := map[int]string{
1: "make",
2: "go",
3: "c++",
//4:"xxxx",
}
fmt.Println("m4 = ", m4) //m4 = map[1:make 2:go 3:c++]
map赋值
//键值是唯一的
m1 := map[int]string{
1: "make",
2: "go",
3: "c++",
//4:"xxxx",
}
//赋值,如果已经存在的key值就是修改内容
fmt.Println("m1 = ", m1) //m1 = map[1:make 2:go 3:c++]
m1[1] = "python"
fmt.Println("m1 = ", m1) //m1 = map[1:python 2:go 3:c++]
m1[4] = "java" //追加,nap底层自动扩容,和append类似
fmt.Println("m1 = ", m1) //m1 = map[1:python 2:go 3:c++ 4:java]
map遍历
//键值是唯一的
m1 := map[int]string{
1: "make",
2: "go",
3: "c++",
//4:"xxxx",
}
//1=========>make
//2=========>go
//3=========>c++
//第一个返回值为key,第二个返回值为value,遍历结果是无序的
for key, value := range m1 {
fmt.Printf("%d=========>%s\n", key, value)
}
//如何判断一个key值是否存在
//第一个返回值为key所对应的value,第二个返回值为key是否存在的条件,存在ok为true
value, ok := m1[1]
if ok == true {
fmt.Println("m[1]= ", value) //m[1] make
} else {
fmt.Println("key不存在")
}
map删除
//键值是唯一的
m1 := map[int]string{
1: "make",
2: "go",
3: "c++",
//4:"xxxx",
}
fmt.Println("m1 = ", m1) //m1 = map[1:make 2:go 3:c++]
delete(m1, 1) //删除key为1的内容
fmt.Println("m1 = ", m1) //m1 = map[2:go 3:c++]
map做函数参数
引用传递
package main
import "fmt"
func test1(m map[int]string) {
delete(m, 1)
}
func main() {
//键值是唯一的
m1 := map[int]string{
1: "make",
2: "go",
3: "c++",
//4:"xxxx",
}
fmt.Println("m1 = ", m1) //m1 = map[1:make 2:go 3:c++]
test1(m1)
fmt.Println("m1 = ", m1) //m1 = map[2:go 3:c++]
}
结构体普通变量初始化
结构体类型:
有时我们需要将不同的类型的数据组合成一个有机的整体,如:一个学生有学号/姓名/性别等属性,显然单独定义以上变量比较繁琐,数据不便于管理。
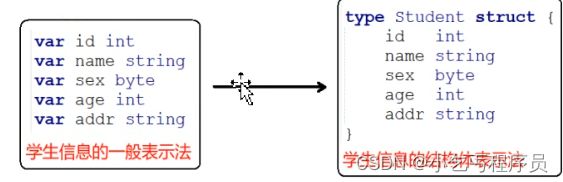
结构体是一种聚合的数据类型,它是由一系列具有相同类型或不同类型的数据构成的数据集合。每个数据称为结构体的成员。
结构体初始化
package main
import "fmt"
//定义一个结构体类型
type Student struct {
id int
name string
sex byte //字符类型
age int
addr string
}
func main() {
//顺序初始化,每个陈冠必须初始化
var s1 Student = Student{1, "mike", 'm', 18, "bj"} //s1 = {1 mike 109 18 bj}
fmt.Println("s1 = ", s1)
//指定成员初始化,没有初始化的成员自动赋值为零
s2 := Student{name: "mike", addr: "bj"}
fmt.Println("s2 = ", s2) //s2 = {0 mike 0 0 bj}
}
结构体指针变量初始化
package main
import "fmt"
//定义一个结构体类型
type Student struct {
id int
name string
sex byte //字符类型
age int
addr string
}
func main() {
//顺序初始化,每个陈冠必须初始化 别忘了&
var p1 *Student = &Student{1, "mike", 'm', 18, "bj"}
fmt.Println("*p1 = ", *p1) //*p1 = {1 mike 109 18 bj}
fmt.Println("p1 = ", p1) //p1 = &{1 mike 109 18 bj}
//指定成员初始化,没有初始化的成员自动赋值为零
p2 := &Student{name: "mike", addr: "bj"}
fmt.Println("*p2 = ", *p2) //*p2 = {0 mike 0 0 bj}
fmt.Println("p2 = ", p2) //p2 = &{0 mike 0 0 bj}
fmt.Printf("p2 type is %T\n ", p2) //p2 type is *main.Student
}
结构体成员的使用:普通变量
package main
import "fmt"
//定义一个结构体类型
type Student struct {
id int
name string
sex byte //字符类型
age int
addr string
}
func main() {
//定义一个结构体普通变量
var s Student
//操作成员需要使用.运算符
s.id = 1
s.name = "mike"
s.sex = 'm' //字符
s.age = 18
s.addr = "wh"
fmt.Println("s = ", s) //s = {1 mike 109 18 wh}
}
结构体成员的使用:指针变量
package main
import "fmt"
//定义一个结构体类型
type Student struct {
id int
name string
sex byte //字符类型
age int
addr string
}
func main() {
//1 指针有合法指向后,才操作成员
// 先定义一个普通结构体变量
var s Student
//在定义一个指针变量,保存s的地址
var p1 *Student
p1 = &s
//通过指针操作成员p1.id (*p1).id完全等价,只能使用.运算符
p1.id = 1
(*p1).name = "mike"
p1.sex = 'm'
p1.age = 18
p1.addr = "bj"
fmt.Println("p1 = ", p1) //p1 = &{1 mike 109 18 bj}
fmt.Println("*p1 = ", *p1) // *p1 = {1 mike 109 18 bj}
//2 通过new生气一个结构体
p2 := new(Student)
p2.id = 1
(*p2).name = "mike"
p2.sex = 'm'
p2.age = 18
p2.addr = "bj"
fmt.Println("p2 = ", p2) //p2 = &{1 mike 109 18 bj}
fmt.Println("*p2 = ", *p2) // *p2 = {1 mike 109 18 bj}
}
结构体比较和赋值
如果结构体的全部成员都是可以比较的,那么结构体也是可以可以比较的,那样的话两个结构体将可以使用==或!=运算符进行比较,但不支持>或<
package main
import "fmt"
//定义一个结构体类型
type Student struct {
id int
name string
sex byte //字符类型
age int
addr string
}
func main() {
s1 := Student{1, "mike", 'm', 18, "bj"}
s2 := Student{1, "mike", 'm', 18, "bj"}
s3 := Student{2, "mike", 'm', 18, "bj"}
fmt.Println("s1 == s3", s1 == s3) //false
fmt.Println("s1 == s2", s1 == s2) //true
//同类型的2个结构体变量可以相互赋值
var tmp Student
tmp = s3
fmt.Println("tmp = ", tmp) //tmp = {2 mike 109 18 bj}
}
结构体做函数参数:值传递
package main
import "fmt"
//定义一个结构体类型
type Student struct {
id int
name string
sex byte //字符类型
age int
addr string
}
func test01(student Student) {
student.id = 2
fmt.Println("test01 student = ", student) //test01 student = {2 mike 109 18 bj}
}
func main() {
s := Student{1, "mike", 'm', 18, "bj"}
test01(s) //值传递,形参无法改实参
fmt.Println("main student = ", s) //main student = {1 mike 109 18 bj}
}
结构体做函数参数:地址传递
package main
import "fmt"
//定义一个结构体类型
type Student struct {
id int
name string
sex byte //字符类型
age int
addr string
}
func test01(student *Student) {
student.id = 2
fmt.Println("test01 student = ", *student) //test01 student = {2 mike 109 18 bj}
}
func main() {
s := Student{1, "mike", 'm', 18, "bj"}
test01(&s) //地址传递(引用传递),形参可以改实参
fmt.Println("main student = ", s) //main student = {2 mike 109 18 bj}
}
go语言可见性规则验证
Go语言对关键字的增加非常吝啬,其中没有private,protected,public这样的关键字.
要使某个符号对其他包(package)可见(即可以访问),需要将符号定义为以大写字母开头.
1):如果使用别的包的函数,结构体类型,结构体成员,函数名,类型名,结构体成员变量名,首字母必须大写,可见。
2):如果首字母是小写,只能在同一个包里面使用。