python自学-class23(down)-使用多线程进行数据处理的练习
练习
1. 读写所爬取的东方财富股票数据信息(csv文件)
2. 多线程统计文件行数
3. 多进程统计文件行数
4. 多线程检索数据
5. 多线程检索邮箱
6. 多线程保存文件
±+++++++++++++++++++++++++++++++++++++++
1.读写所爬取的东方财富股票数据信息(csv文件)
之前写过爬取并保存东方财富历年股票数据的小爬虫(传送门:爬取东方财富股票信息),保存格式为csv文件,因此学习如何使用python读写csv文件;
read:
import csv
path=r"D:\Python代码\class20\down\20201010\0600010.csv"
reader = csv.reader(open(path,"r")) #读取文件
for item in reader: #读取文件
print(item)
for data in item:
print(data)
write:
import csv
with open("1.csv","w",newline="") as datacsv:
csvw=csv.writer(datacsv,dialect=("excel")) #最常用格式excel格式
csvw.writerow(["1","2","3"])
csvw.writerow(["1","2","3"])
csvw.writerow(["1","2","3"])
2.多线程统计爬取的csv文件行数
import threading
import csv
import os
class MyThreadLine(threading.Thread):
def __init__(self,path):
threading.Thread.__init__(self)
self.path=path
self.line=-1
def run(self):
reader = csv.reader(open(self.path, "r")) # 读取文件
lines=0
for item in reader:
lines+=1
self.line=lines
print(self.getName(),self.line)
'''
#单线程执行
path="D:\\Python代码\\class20\\down\\20201010\\0600010.csv"
mythd=MyThreadLine(path)
mythd.start()
mythd.join()
print(mythd.line)
'''
#多线程并发执行
path="D:\\Python代码\\class20\\down\\20200201"
filelist=os.listdir(path) #存储所有文件名
threadlist=[] #线程列表
for filename in filelist:
newpath=path+"\\"+filename #代表完整路径
mythd=MyThreadLine(newpath) #创建线程类对象
mythd.start() #线程开始干活
threadlist.append(mythd) #增加线程到线程列表
for mythd in threadlist:#遍历每一个线程
mythd.join() #等待所有线程把活干完
linelist=[]
for mythd in threadlist:
linelist.append(mythd.line)
print(linelist)
运行效果:

3.多进程统计行数:
多进程与多线程在这里差别不大
import os
import multiprocessing
import time
import csv
def getline(path,mylist):
reader = csv.reader(open(path, "r")) # 读取文件
lines = 0
for item in reader:
lines += 1
print("self.pid",os.getpid(),"lines",lines)
mylist.append(lines)
#单进程
#getline(r"D:\Python代码\class20\down\20201010\0600010.csv")
if __name__=="__main__":
path="D:\\Python代码\\class20\\down\\20200201"
filelist=os.listdir(path) #存储所有文件名
processlist=[] #线程列表
mylist=multiprocessing.Manager().list() #共享list,共享内存
for filename in filelist:
newpath=path+"\\"+filename #代表完整路径
p=multiprocessing.Process(target=getline,args=(newpath,mylist))#开启进程
p.start()
processlist.append(p)#加入进程列表
for mythd in processlist:#遍历每一个线程
mythd.join() #等待所有线程把活干完
print(mylist)
print("done")
运行效果:

4.多线程检索数据(txt文件):
实现是将数据全部载入内存,缺点是如果数据量比较大,会耗费较多时间,优点是查询的时候速度会比较快;
import threading
import os
class Find(threading.Thread):
def __init__(self,datalist,istart,iend,searchstr):
threading.Thread.__init__(self)
self.datalist=datalist #数据内存地址
self.istart=istart #开始索引
self.iend=iend#结束索引
self.searchstr=searchstr #需要搜索的数据
def run(self):
for i in range(self.istart,self.iend):
line=self.datalist[i].decode("gbk","ignore")
if line.find(self.searchstr) !=-1:
print(self.getName(),line,end="")
path="D:\\Python代码\\class15\\图形化编程\\txm.txt" #路径
file = open(path,"rb")
datalist=file.readlines()#全部读入内存
lines=len(datalist)
searchstr=input("输入要查询的数据:")
N=10 #开启10个线程
threadlist=[]
for i in range(0,N-1):
mythd=Find(datalist,i*(lines//(N-1)),(i+1)*(lines//(N-1)),searchstr)
mythd.start()
threadlist.append(mythd)
mylastthd=Find(datalist,lines-lines//(N-1)*(N-1),lines,searchstr)
mylastthd.start()
threadlist.append(mylastthd)
for thd in threadlist:
thd.join()
print("done")
'''
#单线程
path="D:\\Python代码\\class15\\图形化编程\\txm.txt" #路径
file = open(path,"rb")
datalist=file.readlines()#全部读入内存
searchstr=input("输入要查询的数据:")
for line in datalist:
line=line.decode("gbk","ignore")
if line.find(searchstr)!=-1:
print(line)
'''
运行效果:
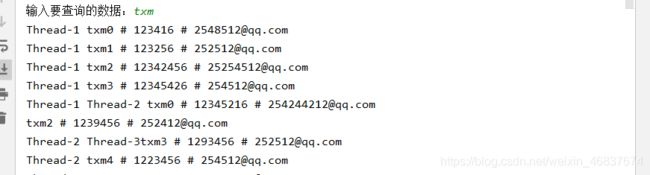
5.多线程检索邮箱
多线程检索与多线程检索数据是类似的,只不过这里是找到即通知其他线程退出
import threading
import os
class Find(threading.Thread):
def __init__(self,datalist,istart,iend,searchstr):
threading.Thread.__init__(self)
self.datalist=datalist #数据内存地址
self.istart=istart #开始索引
self.iend=iend#结束索引
self.searchstr=searchstr #需要搜索的数据
def run(self):
print(self.getName(),"start")
for i in range(self.istart,self.iend):
global isfind
if isfind:
break
line=self.datalist[i].decode("gbk","ignore")
if line.find(self.searchstr) !=-1:
print(self.getName(),line,end="")
isfind=True
break
print(self.getName(),"end")
isfind=False
path="D:\\Python代码\\class15\\图形化编程\\txm.txt" #路径
file = open(path,"rb")
datalist=file.readlines()#全部读入内存
lines=len(datalist)
searchstr=input("输入要查询的数据:")
N=10 #开启10个线程
threadlist=[]
for i in range(0,N-1):
mythd=Find(datalist,i*(lines//(N-1)),(i+1)*(lines//(N-1)),searchstr)
mythd.start()
threadlist.append(mythd)
mylastthd=Find(datalist,lines-lines//(N-1)*(N-1),lines,searchstr)
mylastthd.start()
threadlist.append(mylastthd)
for thd in threadlist:
thd.join()
print("done")
运行效果:
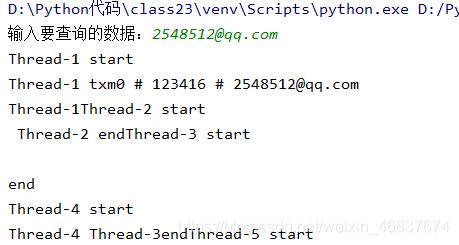
6.多线程检索保存文件
相比查询再增加写入并保存的功能
import threading
import os
class Find(threading.Thread):
def __init__(self,datalist,istart,iend,searchstr,savefile):
threading.Thread.__init__(self)
self.datalist=datalist #数据内存地址
self.istart=istart #开始索引
self.iend=iend#结束索引
self.searchstr=searchstr #需要搜索的数据
self.savefile=savefile #保存
def run(self):
self.findlist=[]
for i in range(self.istart,self.iend):
line=self.datalist[i].decode("gbk","ignore")
if line.find(self.searchstr) !=-1:
print(self.getName(),line,end="")
self.findlist.append(line) #找到加入空列表
global mutex
with mutex: #写入
for line in self.findlist:
self.savefile.write(line.encode("utf-8")) #写入
mutex=threading.Lock() #创建一个锁
savefile=open("tmy.txt","wb")
path="D:\\Python代码\\class15\\图形化编程\\txm.txt" #路径
file = open(path,"rb")
datalist=file.readlines()#全部读入内存
lines=len(datalist)
searchstr=input("输入要查询的数据:")
N=10 #开启10个线程
threadlist=[]
for i in range(0,N-1):
mythd=Find(datalist,i*(lines//(N-1)),(i+1)*(lines//(N-1)),searchstr,savefile)
mythd.start()
threadlist.append(mythd)
mylastthd=Find(datalist,lines-lines//(N-1)*(N-1),lines,searchstr,savefile)
mylastthd.start()
threadlist.append(mylastthd)
for thd in threadlist:
thd.join()
print("done")
savefile.close()
运行效果:
保存到当前目录下txt文件
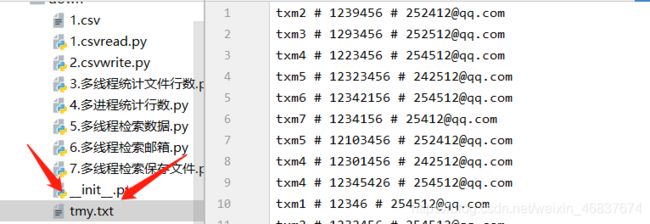
总结
通过练习,算是对这几天线程的学习的一点点小小总结回顾,虽然还不能熟练应用,但还是比之前刚接触要好上许多