clickhouse三分片一副本集群部署
1、创建文件夹 /opt/module/clickhouse,将安装包放入文件夹

2.、安装和创建路径并修改用户组和用户名
#数据文件路径:
mkdir -p /data/clickhouse/
#日志文件路径:
mkdir -p /data/log/clickhouse-server/
#给创建的路径修改用户组和用户名
chown -R clickhouse:clickhouse /data/clickhouse/
chown -R clickhouse:clickhouse /data/log/clickhouse-server/
#如果/data/lib和/data/log/属于bigdata用户,则添加这两个路径other用户的的权限,使clickhouse用户可以访问/data/log和/data/clickhouse的子目录
chmod o+rx /data/log/
chmod o+rx /data/clickhouse/
sudo rpm -ivh *.rpm
3、安装过程中,不用设置登陆密码,直接按enter键
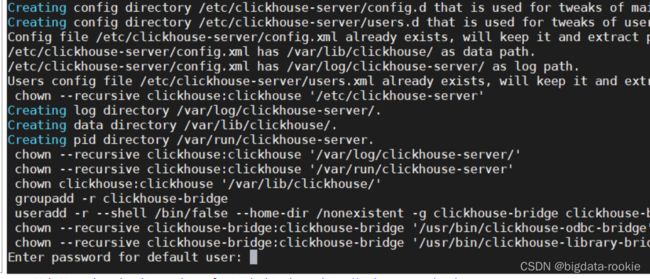
4、修改配置文件/etc/clickhouse-server/config.xml
删除掉
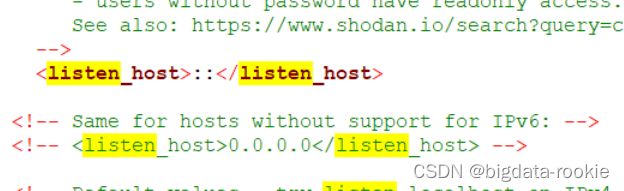
修改tcp端口为9123,默认9000端口已被其他程序占用。

修改默认路径
1.数据文件路径:
<path>/data/clickhouse/</path>
2.日志文件路径:
<log>/data/log/clickhouse-server/clickhouse-server.log</log>
3.临时文件路径
<tmp_path>/data/clickhouse/tmp/</tmp_path>
4.配置metrika.xml副配置文件
在config.xml文件中声明metrika.xml文件路径及相关配置

vi /etc/clickhouse-server/metrika.xml
<yandex>
<clickhouse_remote_servers>
<perftest_3shards_1replicas>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>node1</host>
<port>9123</port>
</replica>
</shard>
<shard>
<replica>
<internal_replication>true</internal_replication>
<host>node2</host>
<port>9123</port>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>node3</host>
<port>9123</port>
</replica>
</shard>
</perftest_3shards_1replicas>
</clickhouse_remote_servers>
<!--zookeeper相关配置-->
<zookeeper-servers>
<node index="1">
<host>node1</host>
<port>2182</port>
</node>
<node index="2">
<host>node2</host>
<port>2182</port>
</node>
<node index="3">
<host>node3</host>
<port>2182</port>
</node>
</zookeeper-servers>
<macros>
<replica>node1</replica>
</macros>
<networks>
<ip>::/0</ip>
</networks>
<clickhouse_compression>
<case>
<min_part_size>10000000000</min_part_size>
<min_part_size_ratio>0.01</min_part_size_ratio>
<method>lz4</method>
</case>
</clickhouse_compression>
</yandex>
5.配置用户名密码
vi /etc/clickhouse-server/users.xml
找到users标签,新建一个

5、将配置文件/etc/clickhouse-server/config.xml分发到其他主机上

按服务器修改
6、验证
启动所有节点
systemctl start clickhouse-server
登录clickhouse客户端
clickhouse-client --host localhost --user clickhouse --password 123456 --port 9123
SQL查询
select * from system.clusters
可以看到集群信息,则集群搭建好了。
7、测试
在各个节点建库、本地表
create database testdb ;
create table person_local (ID Int8, Name String, BirthDate Date) ENGINE = MergeTree(BirthDate, (Name, BirthDate), 8192);
在各个节点建分布表
create table person_all as person_local ENGINE = Distributed(perftest_3shards_1replicas, testdb, person_local, rand());
分布表(Distributed)本身不存储数据,相当于路由,需要指定集群名、数据库名、数据表名、分片KEY.
这里分片用rand()函数,表示随机分片。
查询分布表,会根据集群配置信息,路由到具体的数据表,再把结果进行合并。
- person_local 为本地表,数据只是在本地
- person_all 为分布式表,查询这个表,引擎自动把整个集群数据计算后返回
插入数据
insert into person_all (*) valuses ('1','a','2021-10-01');
insert into person_all (*) valuses ('2','b','2021-10-01');
insert into person_all (*) valuses ('3','c','2021-10-01');
insert into person_all (*) valuses ('4','d','2021-10-01');
insert into person_all (*) valuses ('5','e','2021-10-01');
insert into person_all (*) valuses ('6','f','2021-10-01');
insert into person_all (*) valuses ('7','g','2021-10-01');
insert into person_all (*) valuses ('8','h','2021-10-01');
insert into person_all (*) valuses ('9','i','2021-10-01');
insert into person_all (*) valuses ('10','j','2021-10-01');
insert into person_all (*) valuses ('11','k','2021-10-01');
insert into person_all (*) valuses ('12','l','2021-10-01');
再查看分布式表和本地表的数据
select * from person_all;
select * from person_local;
可以发现数据分片到了三台机器的本地表。