SpringBoot整合Lucene实现全文检索
记录一下Lucene的简单使用,首先我的boot是2.x版本的。Lucene依赖如下:
org.apache.lucene
lucene-core
7.6.0
org.apache.lucene
lucene-queryparser
7.6.0
org.apache.lucene
lucene-analyzers-common
7.6.0
org.apache.lucene
lucene-highlighter
7.6.0
com.janeluo
ikanalyzer
2012_u6
第一步直接处理一下jar包版本不兼容问题,应该是我的这个版本比较高了,因为我用公司的Lucene5.x版本就没有出现这个问题,问题主要是在分词器上面。报错如下:
org.springframework.web.util.NestedServletException: Handler dispatch failed; nested exception is java.lang.AbstractMethodError: org.apache.lucene.analysis.Analyzer.createComponents(Ljava/lang/String;)Lorg/apache/lucene/analysis/Analyzer$TokenStreamComponents;
解决地址:https://blog.csdn.net/weixin_43649997/article/details/106839446
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.Tokenizer;
public class MyIKAnalyzer extends Analyzer {
private boolean useSmart;
public boolean useSmart() {
return this.useSmart;
}
public void setUseSmart(boolean useSmart) {
this.useSmart = useSmart;
}
public MyIKAnalyzer() {
this(false);
}
@Override
protected TokenStreamComponents createComponents(String s) {
Tokenizer _MyIKTokenizer = new MyIKTokenizer(this.useSmart());
return new TokenStreamComponents(_MyIKTokenizer);
}
public MyIKAnalyzer(boolean useSmart) {
this.useSmart = useSmart;
}
}
import java.io.IOException;
import org.apache.lucene.analysis.Tokenizer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.analysis.tokenattributes.OffsetAttribute;
import org.apache.lucene.analysis.tokenattributes.TypeAttribute;
import org.wltea.analyzer.core.IKSegmenter;
import org.wltea.analyzer.core.Lexeme;
public class MyIKTokenizer extends Tokenizer {
private IKSegmenter _IKImplement;
private final CharTermAttribute termAtt = (CharTermAttribute)this.addAttribute(CharTermAttribute.class);
private final OffsetAttribute offsetAtt = (OffsetAttribute)this.addAttribute(OffsetAttribute.class);
private final TypeAttribute typeAtt = (TypeAttribute)this.addAttribute(TypeAttribute.class);
private int endPosition;
//useSmart:设置是否使用智能分词。默认为false,使用细粒度分词,这里如果更改为TRUE,那么搜索到的结果可能就少的很多
public MyIKTokenizer(boolean useSmart) {
this._IKImplement = new IKSegmenter(this.input, useSmart);
}
public boolean incrementToken() throws IOException {
this.clearAttributes();
Lexeme nextLexeme = this._IKImplement.next();
if (nextLexeme != null) {
this.termAtt.append(nextLexeme.getLexemeText());
this.termAtt.setLength(nextLexeme.getLength());
this.offsetAtt.setOffset(nextLexeme.getBeginPosition(), nextLexeme.getEndPosition());
this.endPosition = nextLexeme.getEndPosition();
this.typeAtt.setType(nextLexeme.getLexemeTypeString());
return true;
} else {
return false;
}
}
public void reset() throws IOException {
super.reset();
this._IKImplement.reset(this.input);
}
public final void end() {
int finalOffset = this.correctOffset(this.endPosition);
this.offsetAtt.setOffset(finalOffset, finalOffset);
}
}
实体类和页面
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Content {
@Id
private Integer id;
private String title;
private String price;
private String img;
private String descs;
}
xmlns:th="http://www.thymeleaf.org">
"utf-8">
"viewport" content="width=device-width, initial-scale=1.0">
"renderer" content="webkit">
hAdmin- 主页
"shortcut icon" href="favicon.ico">
th:each="list: ${list}" style="width: 200px;height: 200px;float: left;border: 1px solid red;margin-left: 20px;margin-top: 20px;">
title:th:utext="${list.title}">
111
descs:th:utext="${list.descs}">
222
回头使用分词器的时候直接用该分词器实现即可
第二步,创建索引
import java.io.File;
import java.io.IOException;
import java.nio.file.FileSystems;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.Collection;
import java.util.List;
import javax.servlet.http.HttpServletRequest;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.IndexableField;
import org.apache.lucene.index.MultiReader;
import org.apache.lucene.queryparser.classic.MultiFieldQueryParser;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.search.highlight.Fragmenter;
import org.apache.lucene.search.highlight.Highlighter;
import org.apache.lucene.search.highlight.InvalidTokenOffsetsException;
import org.apache.lucene.search.highlight.QueryScorer;
import org.apache.lucene.search.highlight.SimpleFragmenter;
import org.apache.lucene.search.highlight.SimpleHTMLFormatter;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
@ResponseBody
@RequestMapping("/createIndex")
public String createIndex() throws IOException{
List list1 = new ArrayList<>();
list1.add(new Content(null,"Java面向对象", "10", null, "Java面向对象从入门到精通,简单上手"));
list1.add(new Content(null,"Java面向对象java", "10", null, "Java面向对象从入门到精通,简单上手"));
list1.add(new Content(null,"Java面向编程", "15", null, "Java面向对象编程书籍"));
list1.add(new Content(null,"JavaScript入门", "18", null, "JavaScript入门编程书籍"));
list1.add(new Content(null,"深入理解Java编程", "13", null, "十三四天掌握Java基础"));
list1.add(new Content(null,"从入门到放弃_Java", "20", null, "一门从入门到放弃的书籍"));
list1.add(new Content(null,"Head First Java", "30", null, "《Head First Java》是一本完整地面向对象(object-oriented,OO)程序设计和Java的学习指导用书"));
list1.add(new Content(null,"Java 核心技术:卷1 基础知识", "22", null, "全书共14章,包括Java基本的程序结构、对象与类、继承、接口与内部类、图形程序设计、事件处理、Swing用户界面组件"));
list1.add(new Content(null,"Java 编程思想", "12", null, "本书赢得了全球程序员的广泛赞誉,即使是最晦涩的概念,在Bruce Eckel的文字亲和力和小而直接的编程示例面前也会化解于无形"));
list1.add(new Content(null,"Java开发实战经典", "51", null, "本书是一本综合讲解Java核心技术的书籍,在书中使用大量的代码及案例进行知识点的分析与运用"));
list1.add(new Content(null,"Effective Java", "10", null, "本书介绍了在Java编程中57条极具实用价值的经验规则,这些经验规则涵盖了大多数开发人员每天所面临的问题的解决方案"));
list1.add(new Content(null,"分布式 Java 应用:基础与实践", "14", null, "本书介绍了编写分布式Java应用涉及的众多知识点,分为了基于Java实现网络通信、RPC;基于SOA实现大型分布式Java应用"));
list1.add(new Content(null,"http权威指南", "11", null, "超文本传输协议(Hypertext Transfer Protocol,HTTP)是在万维网上进行通信时所使用的协议方案"));
list1.add(new Content(null,"Spring", "15", null, "这是啥,还需要学习吗?Java程序员必备书籍"));
list1.add(new Content(null,"深入理解 Java 虚拟机", "18", null, "作为一位Java程序员,你是否也曾经想深入理解Java虚拟机,但是却被它的复杂和深奥拒之门外"));
list1.add(new Content(null,"springboot实战", "11", null, "完成对于springboot的理解,是每个Java程序员必备的姿势"));
list1.add(new Content(null,"springmvc学习", "72", null, "springmvc学习指南"));
list1.add(new Content(null,"vue入门到放弃", "20", null, "vue入门到放弃书籍信息"));
list1.add(new Content(null,"vue入门到精通", "20", null, "vue入门到精通相关书籍信息"));
list1.add(new Content(null,"vue之旅", "20", null, "由浅入深地全面介绍vue技术,包含大量案例与代码"));
list1.add(new Content(null,"vue实战", "20", null, "以实战为导向,系统讲解如何使用 "));
list1.add(new Content(null,"vue入门与实践", "20", null, "现已得到苹果、微软、谷歌等主流厂商全面支持"));
list1.add(new Content(null,"Vue.js应用测试", "20", null, "Vue.js创始人尤雨溪鼎力推荐!Vue官方测试工具作者亲笔撰写,Vue.js应用测试完全学习指南"));
list1.add(new Content(null,"PHP和MySQL Web开发", "20", null, "本书是利用PHP和MySQL构建数据库驱动的Web应用程序的权威指南"));
list1.add(new Content(null,"Web高效编程与优化实践", "20", null, "从思想提升和内容修炼两个维度,围绕前端工程师必备的前端技术和编程基础"));
list1.add(new Content(null,"Vue.js 2.x实践指南", "20", null, "本书旨在让初学者能够快速上手vue技术栈,并能够利用所学知识独立动手进行项目开发"));
list1.add(new Content(null,"初始vue", "20", null, "解开vue的面纱"));
list1.add(new Content(null,"什么是vue", "20", null, "一步一步的了解vue相关信息"));
list1.add(new Content(null,"深入浅出vue", "20", null, "深入浅出vue,慢慢掌握"));
list1.add(new Content(null,"三天vue实战", "20", null, "三天掌握vue开发"));
list1.add(new Content(null,"不知火舞", "20", null, "不知名的vue"));
list1.add(new Content(null,"娜可露露", "20", null, "一招秒人"));
list1.add(new Content(null,"宫本武藏", "20", null, "我就是一个超级兵"));
list1.add(new Content(null,"vue宫本vue", "20", null, "我就是一个超级兵"));
// 创建文档的集合
Collection docs = new ArrayList<>();
for(int i=0;isize();i++){
//contentMapper.insertSelective(list1.get(i));
// 创建文档对象
Document document1 = new Document();
//StringField会创建索引,但是不会被分词,TextField,即创建索引又会被分词。
document1.add(new StringField("id", (i+1)+"", Field.Store.YES));
document1.add(new TextField("title", list1.get(i).getTitle(), Field.Store.YES));
document1.add(new TextField("price", list1.get(i).getPrice(), Field.Store.YES));
document1.add(new TextField("descs", list1.get(i).getDescs(), Field.Store.YES));
docs.add(document1);
}
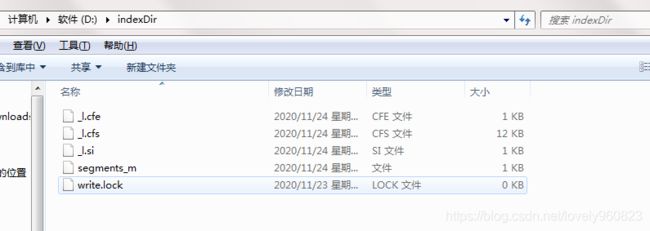
// 索引目录类,指定索引在硬盘中的位置,我的设置为D盘的indexDir文件夹
Directory directory = FSDirectory.open(FileSystems.getDefault().getPath("d:\\indexDir"));
// 引入IK分词器
Analyzer analyzer = new MyIKAnalyzer();
// 索引写出工具的配置对象,这个地方就是最上面报错的问题解决方案
IndexWriterConfig conf = new IndexWriterConfig(analyzer);
// 设置打开方式:OpenMode.APPEND 会在索引库的基础上追加新索引。OpenMode.CREATE会先清空原来数据,再提交新的索引
conf.setOpenMode(IndexWriterConfig.OpenMode.CREATE);
// 创建索引的写出工具类。参数:索引的目录和配置信息
IndexWriter indexWriter = new IndexWriter(directory, conf);
// 把文档集合交给IndexWriter
indexWriter.addDocuments(docs);
// 提交
indexWriter.commit();
// 关闭
indexWriter.close();
return"success";
}
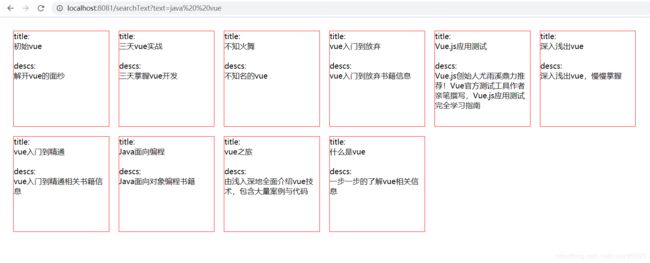
第三步,查询数据 根据descs字段查询
@RequestMapping("/searchText")
public String searchText(String text,HttpServletRequest request) throws IOException,ParseException{
Directory directory = FSDirectory.open(FileSystems.getDefault().getPath("d:\\indexDir"));
// 索引读取工具
IndexReader reader = DirectoryReader.open(directory);
// 索引搜索工具
IndexSearcher searcher = new IndexSearcher(reader);
// 创建查询解析器,两个参数:默认要查询的字段的名称,分词器
QueryParser parser = new QueryParser("descs", new MyIKAnalyzer());
// 创建查询对象
Query query = parser.parse(text);
// 获取前十条记录
TopDocs topDocs = searcher.search(query, 10);
// 获取总条数
System.out.println("本次搜索共找到" + topDocs.totalHits + "条数据");
// 获取得分文档对象(ScoreDoc)数组.SocreDoc中包含:文档的编号、文档的得分
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
List list = new ArrayList<>();
for (ScoreDoc scoreDoc : scoreDocs) {
// 取出文档编号
int docID = scoreDoc.doc;
// 根据编号去找文档
Document doc = reader.document(docID);
Content content = contentMapper.selectByPrimaryKey(doc.get("id"));
list.add(content);
}
request.setAttribute("list", list);
return "index";
}
测试结果,想根据title字段查询 自行修改即可
第四步,根据多字段查询 和上面的类似
private String[] str={"title","descs"};
@RequestMapping("/searchText1")
public String searchText1(String text,HttpServletRequest request) throws IOException,ParseException{
Directory directory = FSDirectory.open(FileSystems.getDefault().getPath("d:\\indexDir"));
// 索引读取工具
IndexReader reader = DirectoryReader.open(directory);
// 索引搜索工具
IndexSearcher searcher = new IndexSearcher(reader);
// 创建查询解析器,两个参数:默认要查询的字段的名称,分词器
MultiFieldQueryParser parser = new MultiFieldQueryParser(str, new MyIKAnalyzer());
// 创建查询对象
Query query = parser.parse(text);
// 获取前十条记录
TopDocs topDocs = searcher.search(query, 100);
// 获取总条数
System.out.println("本次搜索共找到" + topDocs.totalHits + "条数据");
// 获取得分文档对象(ScoreDoc)数组.SocreDoc中包含:文档的编号、文档的得分
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
List list = new ArrayList<>();
for (ScoreDoc scoreDoc : scoreDocs) {
// 取出文档编号
int docID = scoreDoc.doc;
// 根据编号去找文档
Document doc = reader.document(docID);
Content content = contentMapper.selectByPrimaryKey(doc.get("id"));
list.add(content);
}
request.setAttribute("list", list);
return "index";
}
测试结果 很明显比刚才查出来的结果多了许多

第五步,高亮显示
@RequestMapping("/searchText2")
public String searchText2(String text,HttpServletRequest request) throws IOException,ParseException, InvalidTokenOffsetsException{
Directory directory = FSDirectory.open(FileSystems.getDefault().getPath("d:\\indexDir"));
// 索引读取工具
IndexReader reader = DirectoryReader.open(directory);
// 索引搜索工具
IndexSearcher searcher = new IndexSearcher(reader);
// 创建查询解析器,两个参数:默认要查询的字段的名称,分词器
MultiFieldQueryParser parser = new MultiFieldQueryParser(str, new MyIKAnalyzer());
// 创建查询对象
Query query = parser.parse(text);
// 获取前十条记录
TopDocs topDocs = searcher.search(query, 100);
// 获取总条数
System.out.println("本次搜索共找到" + topDocs.totalHits + "条数据");
//高亮显示
SimpleHTMLFormatter simpleHTMLFormatter = new SimpleHTMLFormatter("", "");
Highlighter highlighter = new Highlighter(simpleHTMLFormatter, new QueryScorer(query));
Fragmenter fragmenter = new SimpleFragmenter(100); //高亮后的段落范围在100字内
highlighter.setTextFragmenter(fragmenter);
// 获取得分文档对象(ScoreDoc)数组.SocreDoc中包含:文档的编号、文档的得分
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
List list = new ArrayList<>();
for (ScoreDoc scoreDoc : scoreDocs) {
// 取出文档编号
int docID = scoreDoc.doc;
// 根据编号去找文档
Document doc = reader.document(docID);
Content content = contentMapper.selectByPrimaryKey(doc.get("id"));
//处理高亮字段显示
String title = highlighter.getBestFragment(new MyIKAnalyzer(), "title",doc.get("title"));
if(title==null){
title=content.getTitle();
}
String descs = highlighter.getBestFragment(new MyIKAnalyzer(), "descs",doc.get("descs"));
if(descs==null){
descs=content.getDescs();
}
content.setDescs(descs);
content.setTitle(title);
list.add(content);
}
request.setAttribute("list",list);
return "index";
}
测试结果

第六步 索引更新
先看一下更新前数据
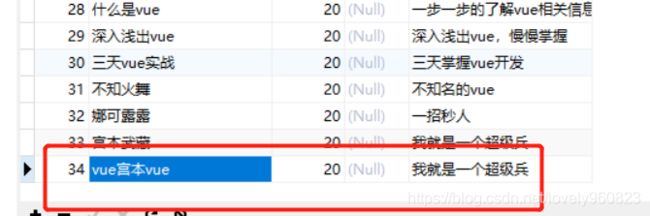
查询结果和数据库的也是一致的

我们现在来更新这条数据
//更新指定id的数据
@RequestMapping("/updateIndex")
@ResponseBody
public String update(String age) throws IOException{
// 创建目录对象
Directory directory = FSDirectory.open(FileSystems.getDefault().getPath("d:\\indexDir"));
// 创建配置对象
IndexWriterConfig conf = new IndexWriterConfig(new MyIKAnalyzer());
// 创建索引写出工具
IndexWriter writer = new IndexWriter(directory, conf);
// 创建新的文档数据
Document doc = new Document();
doc.add(new StringField("id","34",Store.YES));
Content content = contentMapper.selectByPrimaryKey("34");
content.setTitle("宫本武藏超级兵");
contentMapper.updateByPrimaryKeySelective(content);
doc.add(new TextField("title", content.getTitle(), Field.Store.YES));
doc.add(new TextField("price", content.getPrice(), Field.Store.YES));
doc.add(new TextField("descs", content.getDescs(), Field.Store.YES));
writer.updateDocument(new Term("id","34"), doc);
// 提交
writer.commit();
// 关闭
writer.close();
return "success";
}
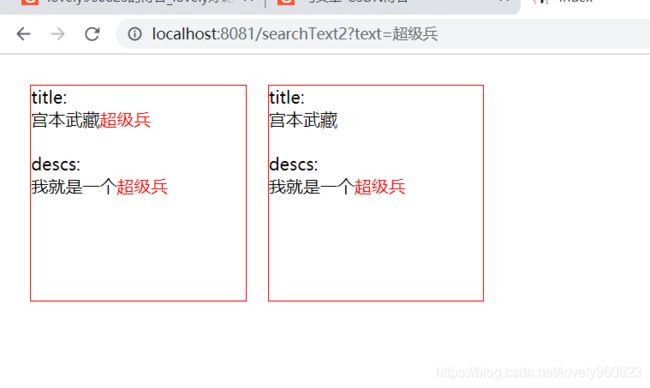
更新测试

重新查询结果如下,果然发生了变化
第七步 删除指定索引 到这了你们自己测这个
@RequestMapping("/deleteIndex")
@ResponseBody
public String deleteIndex() throws IOException{
// 创建目录对象
Directory directory = FSDirectory.open(FileSystems.getDefault().getPath("d:\\indexDir"));
// 创建配置对象
IndexWriterConfig conf = new IndexWriterConfig(new IKAnalyzer());
// 创建索引写出工具
IndexWriter writer = new IndexWriter(directory, conf);
// 根据词条进行删除
writer.deleteDocuments(new Term("id", "34"));
// 提交
writer.commit();
// 关闭
writer.close();
return "success";
}
第八步 分页,分页的话自己手动处理
private String[] str={"title","descs"};
@RequestMapping("/searchText3")
public String searchText3(String text,HttpServletRequest request) throws IOException,ParseException, InvalidTokenOffsetsException{
int page=1;
int pageSize=10;
Directory directory = FSDirectory.open(FileSystems.getDefault().getPath("d:\\indexDir"));
// 索引读取工具
IndexReader reader = DirectoryReader.open(directory);
// 索引搜索工具
IndexSearcher searcher = new IndexSearcher(reader);
// 创建查询解析器,两个参数:默认要查询的字段的名称,分词器
MultiFieldQueryParser parser = new MultiFieldQueryParser(str, new MyIKAnalyzer());
// 创建查询对象
Query query = parser.parse(text);
// 获取前十条记录
//TopDocs topDocs = searcher.search(query, 100);
TopDocs topDocs = searchByPage(page,pageSize,searcher,query);
// 获取总条数
System.out.println("本次搜索共找到" + topDocs.totalHits + "条数据");
//高亮显示
SimpleHTMLFormatter simpleHTMLFormatter = new SimpleHTMLFormatter("", "");
Highlighter highlighter = new Highlighter(simpleHTMLFormatter, new QueryScorer(query));
Fragmenter fragmenter = new SimpleFragmenter(100); //高亮后的段落范围在100字内
highlighter.setTextFragmenter(fragmenter);
// 获取得分文档对象(ScoreDoc)数组.SocreDoc中包含:文档的编号、文档的得分
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
List list = new ArrayList<>();
for (ScoreDoc scoreDoc : scoreDocs) {
// 取出文档编号
int docID = scoreDoc.doc;
// 根据编号去找文档
Document doc = reader.document(docID);
Content content = contentMapper.selectByPrimaryKey(doc.get("id"));
//处理高亮字段显示
String title = highlighter.getBestFragment(new MyIKAnalyzer(), "title",doc.get("title"));
if(title==null){
title=content.getTitle();
}
String descs = highlighter.getBestFragment(new MyIKAnalyzer(), "descs",doc.get("descs"));
if(descs==null){
descs=content.getDescs();
}
content.setDescs(descs);
content.setTitle(title);
list.add(content);
}
System.err.println("list的长度:"+list.size());
request.setAttribute("page", page);
request.setAttribute("pageSize", pageSize);
request.setAttribute("list",list);
return "index";
}
private TopDocs searchByPage(int page,int perPage, IndexSearcher searcher, Query query) throws IOException {
TopDocs result = null;
if(query == null){
System.out.println(" Query is null return null ");
return null;
}
ScoreDoc before = null;
if(page != 1){
TopDocs docsBefore = searcher.search(query, (page-1)*perPage);
ScoreDoc[] scoreDocs = docsBefore.scoreDocs;
if(scoreDocs.length > 0){
before = scoreDocs[scoreDocs.length - 1];
}
}
result = searcher.searchAfter(before, query, perPage);
return result;
}
第九步,多个索引同时查询,我建立两个索引文件,因为我数据已经存入数据库,所以直接查询出来即可,这两个索引的区别就是索引目录不同,title值不同 我在第二个索引的title值上面+1了
@RequestMapping("/createIndex")
@ResponseBody
public Result createIndex(){
List list1 = contentMapper.selectAll();
// 创建文档的集合
Collection docs = new ArrayList<>();
for(int i=0;isize();i++) {
// 创建文档对象
Document document = new Document();
//StringField会创建索引,但是不会被分词,TextField,即创建索引又会被分词。
document.add(new StringField("id",list1.get(i).getId().toString() , Field.Store.YES));
//我把需要检索的内容都存一个字段里面了,回头检索的时候方便使用
document.add(new TextField("title", list1.get(i).getTitle(), Field.Store.YES));
document.add(new TextField("price", list1.get(i).getPrice(), Field.Store.YES));
document.add(new TextField("descs", list1.get(i).getDescs(), Field.Store.YES));
docs.add(document);
}
try {
//先删除原来的
File f = new File("d:\\indexDir\\index1");
if(f.exists()){
f.delete();
}
// 索引目录类,指定索引在硬盘中的位置,我的设置为D盘的indexDir文件夹
Directory directory = FSDirectory.open(FileSystems.getDefault().getPath("d:\\indexDir\\index1"));
// 引入IK分词器
Analyzer analyzer = new MyIKAnalyzer();
// 索引写出工具的配置对象,这个地方就是最上面报错的问题解决方案
IndexWriterConfig conf = new IndexWriterConfig(analyzer);
// 设置打开方式:OpenMode.APPEND 会在索引库的基础上追加新索引。OpenMode.CREATE会先清空原来数据,再提交新的索引
conf.setOpenMode(IndexWriterConfig.OpenMode.CREATE);
// 创建索引的写出工具类。参数:索引的目录和配置信息
IndexWriter indexWriter = new IndexWriter(directory, conf);
// 把文档集合交给IndexWriter
indexWriter.addDocuments(docs);
// 提交
indexWriter.commit();
// 关闭
indexWriter.close();
} catch (Exception e) {
return Result.error("创建索引失败");
}
return Result.ok("创建索引成功");
}
@RequestMapping("/createIndex1")
@ResponseBody
public Result createIndex1(){
List list1 = contentMapper.selectAll();
// 创建文档的集合
Collection docs = new ArrayList<>();
for(int i=0;isize();i++) {
// 创建文档对象
Document document = new Document();
//StringField会创建索引,但是不会被分词,TextField,即创建索引又会被分词。
document.add(new StringField("id",list1.get(i).getId().toString() , Field.Store.YES));
//我把需要检索的内容都存一个字段里面了,回头检索的时候方便使用
document.add(new TextField("title", list1.get(i).getTitle()+"1", Field.Store.YES));
document.add(new TextField("price", list1.get(i).getPrice(), Field.Store.YES));
document.add(new TextField("descs", list1.get(i).getDescs(), Field.Store.YES));
docs.add(document);
}
try {
//先删除原来的
File f = new File("d:\\indexDir\\index2");
if(f.exists()){
f.delete();
}
// 索引目录类,指定索引在硬盘中的位置,我的设置为D盘的indexDir文件夹
Directory directory = FSDirectory.open(FileSystems.getDefault().getPath("d:\\indexDir\\index2"));
// 引入IK分词器
Analyzer analyzer = new MyIKAnalyzer();
// 索引写出工具的配置对象,这个地方就是最上面报错的问题解决方案
IndexWriterConfig conf = new IndexWriterConfig(analyzer);
// 设置打开方式:OpenMode.APPEND 会在索引库的基础上追加新索引。OpenMode.CREATE会先清空原来数据,再提交新的索引
conf.setOpenMode(IndexWriterConfig.OpenMode.CREATE);
// 创建索引的写出工具类。参数:索引的目录和配置信息
IndexWriter indexWriter = new IndexWriter(directory, conf);
// 把文档集合交给IndexWriter
indexWriter.addDocuments(docs);
// 提交
indexWriter.commit();
// 关闭
indexWriter.close();
} catch (Exception e) {
return Result.error("创建索引失败");
}
return Result.ok("创建索引成功");
}
创建成功
查询测试
@RequestMapping("/searchText4")
public String searchText4(String text,HttpServletRequest request) throws IOException,ParseException, InvalidTokenOffsetsException{
int page=1;
int pageSize=100;
IndexSearcher searcher = getMoreSearch("d:\\indexDir");
// 创建查询解析器,两个参数:默认要查询的字段的名称,分词器
MultiFieldQueryParser parser = new MultiFieldQueryParser(str, new MyIKAnalyzer());
// 创建查询对象
Query query = parser.parse(text);
TopDocs topDocs = searchByPage(page,pageSize,searcher,query);
// 获取总条数
System.out.println("本次搜索共找到" + topDocs.totalHits + "条数据");
//高亮显示
SimpleHTMLFormatter simpleHTMLFormatter = new SimpleHTMLFormatter("", "");
Highlighter highlighter = new Highlighter(simpleHTMLFormatter, new QueryScorer(query));
Fragmenter fragmenter = new SimpleFragmenter(100); //高亮后的段落范围在100字内
highlighter.setTextFragmenter(fragmenter);
// 获取得分文档对象(ScoreDoc)数组.SocreDoc中包含:文档的编号、文档的得分
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
List list = new ArrayList<>();
for (ScoreDoc scoreDoc : scoreDocs) {
// 取出文档编号
int docID = scoreDoc.doc;
// 根据编号去找文档
//Document doc = reader.document(docID);
Document doc = searcher.doc(docID);//多索引找文档要用searcher找了,reader容易报错
Content content = contentMapper.selectByPrimaryKey(doc.get("id"));
//处理高亮字段显示
String title = highlighter.getBestFragment(new MyIKAnalyzer(), "title",doc.get("title"));
if(title==null){
title=content.getTitle();
}
String descs = highlighter.getBestFragment(new MyIKAnalyzer(), "descs",doc.get("descs"));
if(descs==null){
descs=content.getDescs();
}
content.setDescs(descs);
content.setTitle(title);
list.add(content);
}
System.err.println("list的长度:"+list.size());
request.setAttribute("page", page);
request.setAttribute("pageSize", pageSize);
request.setAttribute("list",list);
return "index";
}
private IndexSearcher getMoreSearch(String string) {
MultiReader reader = null;
//设置
try {
File[] files = new File(string).listFiles();
IndexReader[] readers = new IndexReader[files.length];
for (int i = 0 ; i < files.length ; i ++) {
readers[i] = DirectoryReader.open(FSDirectory.open(Paths.get(files[i].getPath(), new String[0])));
}
reader = new MultiReader(readers);
} catch (IOException e) {
e.printStackTrace();
}
return new IndexSearcher(reader);
//如果索引文件过多,可以这样加快效率
/**
ExecutorService service = Executors.newCachedThreadPool();
return new IndexSearcher(reader,service);
*/
}
根据结果来看的话,确实查出来不同索引下的数据了

20210401 今天愚人节,呵呵,
补充一下多条件查询,查询符合条件,并且价格为20的
private String[] str={"title","descs"};
@GetMapping("/search")
public ModelAndView searchText2(String text,HttpServletRequest request) throws IOException,ParseException, InvalidTokenOffsetsException{
Directory directory = FSDirectory.open(FileSystems.getDefault().getPath("d:\\indexDir"));
// 索引读取工具
IndexReader reader = DirectoryReader.open(directory);
// 索引搜索工具
IndexSearcher searcher = new IndexSearcher(reader);
//多条件查询构造
BooleanQuery.Builder builder = new BooleanQuery.Builder();
// 条件一
MultiFieldQueryParser parser = new MultiFieldQueryParser(str, new MyIKAnalyzer());
// 创建查询对象
Query query = parser.parse(text);
builder.add(query, Occur.MUST);
//条件二
Query termQuery = new TermQuery(new Term("price", "20"));
builder.add(termQuery, Occur.MUST);
// 获取前十条记录
TopDocs topDocs = searcher.search(builder.build(), 100);
// 获取总条数
System.err.println("本次搜索共找到" + topDocs.totalHits + "条数据");
//高亮显示
SimpleHTMLFormatter simpleHTMLFormatter = new SimpleHTMLFormatter("", "");
Highlighter highlighter = new Highlighter(simpleHTMLFormatter, new QueryScorer(query));
Fragmenter fragmenter = new SimpleFragmenter(100); //高亮后的段落范围在100字内
highlighter.setTextFragmenter(fragmenter);
// 获取得分文档对象(ScoreDoc)数组.SocreDoc中包含:文档的编号、文档的得分
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
List list = new ArrayList<>();
for (ScoreDoc scoreDoc : scoreDocs) {
// 取出文档编号
int docID = scoreDoc.doc;
// 根据编号去找文档
Document doc = reader.document(docID);
Content content = contentMapper.selectByPrimaryKey(doc.get("id"));
//处理高亮字段显示
String title = highlighter.getBestFragment(new MyIKAnalyzer(), "title",doc.get("title"));
if(title==null){
title=content.getTitle();
}
String descs = highlighter.getBestFragment(new MyIKAnalyzer(), "descs",doc.get("descs"));
if(descs==null){
descs=content.getDescs();
}
content.setDescs(descs);
content.setTitle(title);
list.add(content);
}
request.setAttribute("list",list);
return new ModelAndView("index");
}
查询结果
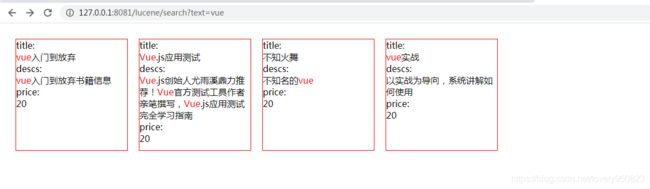
2021/4/6,附上实战代码
@Override
public List searchData(SearchParam searchParam) throws Exception {
String indexPath = uploadPath+"index/"+searchParam.getIndex();
//文件夹不存在
File ff = new File(indexPath);
if(!ff.exists()) {
return new ArrayList<>();
}
//空文件夹,也就是没有索引文件内容
File[] listFiles = ff.listFiles();
if(listFiles.length <= 0){
return new ArrayList<>();
}
Directory directory = FSDirectory.open(FileSystems.getDefault().getPath(indexPath));
// 索引读取工具
IndexReader reader = DirectoryReader.open(directory);
// 索引搜索工具
IndexSearcher searcher = new IndexSearcher(reader);
// 创建查询解析器,两个参数:默认要查询的字段的名称,分词器
MultiFieldQueryParser parser = new MultiFieldQueryParser(STR, new MyIKAnalyzer());
//多条件查询构造
BooleanQuery.Builder builder = new BooleanQuery.Builder();
// 创建查询对象
Query query = parser.parse(searchParam.getKeyWords());
builder.add(query, Occur.MUST);
//过滤postId不等于的
if(searchParam.getPerms().size()>0) {
List perms = searchParam.getPerms();
perms.forEach(each->{
Query termQuery = new TermQuery(new Term("postId", each.toString()));
builder.add(termQuery, Occur.MUST_NOT);
});
}
// 分页获取数据
TopDocs topDocs = searchByPage(searchParam.getPageNum(),searchParam.getPageSize(),searcher,builder.build());
// 获取总条数
System.out.println("本次搜索共找到" + topDocs.totalHits + "条数据");
//高亮显示
SimpleHTMLFormatter simpleHTMLFormatter = new SimpleHTMLFormatter("", "");
Highlighter highlighter = new Highlighter(simpleHTMLFormatter, new QueryScorer(builder.build()));
Fragmenter fragmenter = new SimpleFragmenter(100); //高亮后的段落范围在100字内
highlighter.setTextFragmenter(fragmenter);
// 获取得分文档对象(ScoreDoc)数组.SocreDoc中包含:文档的编号、文档的得分
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
List list = new ArrayList<>();
for (ScoreDoc scoreDoc : scoreDocs) {
SearchResultData searchResultData = new SearchResultData();
// 取出文档编号
int docID = scoreDoc.doc;
// 根据编号去找文档
Document doc = reader.document(docID);
searchResultData.setId(Integer.parseInt(doc.get("id")));
searchResultData.setArchiveType(searchParam.getIndex());
String dh = highlighter.getBestFragment(new MyIKAnalyzer(), "dh",doc.get("dh"))==null?doc.get("dh"):highlighter.getBestFragment(new MyIKAnalyzer(), "dh",doc.get("dh"));
searchResultData.setDh(dh);
String author = highlighter.getBestFragment(new MyIKAnalyzer(), "author",doc.get("author"))==null?doc.get("author"):highlighter.getBestFragment(new MyIKAnalyzer(), "author",doc.get("author"));
searchResultData.setAuthor(author);
String gdnd = highlighter.getBestFragment(new MyIKAnalyzer(), "gdnd",doc.get("gdnd"))==null?doc.get("gdnd"):highlighter.getBestFragment(new MyIKAnalyzer(), "gdnd",doc.get("gdnd"));
searchResultData.setGdnd(gdnd);
String name = highlighter.getBestFragment(new MyIKAnalyzer(), "name",doc.get("name"))==null?doc.get("name"):highlighter.getBestFragment(new MyIKAnalyzer(), "name",doc.get("name"));
searchResultData.setName(name);
String tm = highlighter.getBestFragment(new MyIKAnalyzer(), "tm",doc.get("tm"))==null?doc.get("tm"):highlighter.getBestFragment(new MyIKAnalyzer(), "tm",doc.get("tm"));
searchResultData.setTm(tm);
list.add(searchResultData);
}
return list;
}
private TopDocs searchByPage(Integer pageNum, Integer pageSize, IndexSearcher searcher, Query query) throws IOException {
TopDocs result = null;
ScoreDoc before = null;
if(pageNum > 1){
TopDocs docsBefore = searcher.search(query, (pageNum-1)*pageSize);
ScoreDoc[] scoreDocs = docsBefore.scoreDocs;
if(scoreDocs.length > 0){
before = scoreDocs[scoreDocs.length - 1];
}
}
result = searcher.searchAfter(before, query, pageSize);
return result;
}
2021/8/3 解决需求问题,出现特殊字符报错,以及查询的时候不分词,按照用户输入的匹配解决
public static String escapeQueryChars(String s) {
if (StringUtils.isBlank(s)) {
return s;
}
StringBuilder sb = new StringBuilder();
//查询字符串一般不会太长,挨个遍历也花费不了多少时间
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
// These characters are part of the query syntax and must be escaped
if (c == '\\' || c == '+' || c == '-' || c == '!' || c == '(' || c == ')'
|| c == ':' || c == '^' || c == '[' || c == ']' || c == '\"'
|| c == '{' || c == '}' || c == '~' || c == '*' || c == '?'
|| c == '|' || c == '&' || c == ';' || c == '/' || c == '.'
|| c == '$' || Character.isWhitespace(c)) {
sb.append('\\');
}
sb.append(c);
}
return sb.toString();
}
完事了,以上这些基本够用了。
2022-4-25新增扩展词
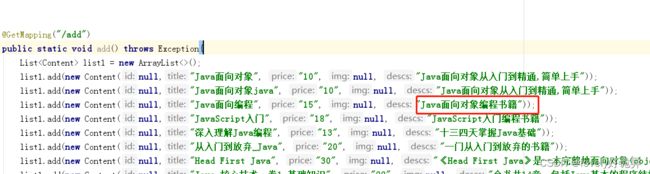
我的数据中有这样一条数据,我想根据"象编"来查询,这个时候是查不到的
增加扩展词之后
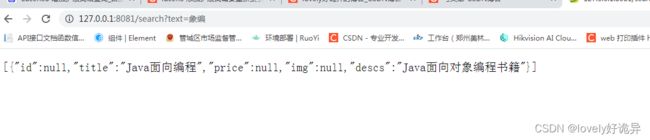
如何增加了 添加几个文件就好了。
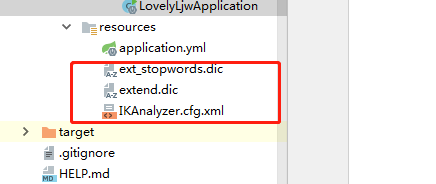
IKAnalyzer.cfg.xml
IKAnalyzer扩展配置
extend.dic
stopword.dic
扩展文件中自己添加词语

这些弄完之后要重新建索引,然后就会有提示了。
