从流量打标到机器打标 - 达达全链路压测探索与实战
1. 背景
达达集团是 2014年在上海成立的本地即时配送平台, 过去7年中稳步前进; 2020年双11大促时, 日配送完成单量突破 1000万; 单量的增长需要稳定性的保障, 全链路压测在达达稳定性保障中扮演着重要角色,本文将阐述达达全链路压测的核心设计与落地。
2. 全链路压测核心设计
2.1 业界全链路压测
达达原压测方案是: 搭建一套跟线上 1:1 的压测环境, 在这套环境中进行压测, 此方案技术难度低, 实现简单, 但弊端也明显: 人力及机器成本随着生产环境规模的变大而变大; 于是我们调研了业界主流的 【流量打标】方案, 该方案原理是: 在请求的流量(HTTP,RPC,MQ)上打标, 所打的标示随着请求在各个服务之间流转, 从而使得压测流量与线上流量隔离; 在数据隔离这块:
DB 层: 使用 影子库/影子表 隔离数据。
Cache 层: 使用 影子缓存 隔离数据;。
MQ 层: 使用 影子队列 隔离数据。

图: 流量打标
但这个方案适用于中间件统一的场景;而达达内部使用了各种类型的中间件, 比如 ORM 就有 Mybatis, Hiberante, JPA, 版本也不一致; 并且存在大量异构程序, 有 Java 的, 有Python 的; 若要实现【流量打标】方案, 势必会有大量业务改造, 因此我们放弃此方案。
2.2 达达全链路压测
在分析达达自身架构特点后, 我们在 2019年一季度研发了基于【机器打标】的压测方案 (数据使用 影子DB&Redis&MQ 隔离)。
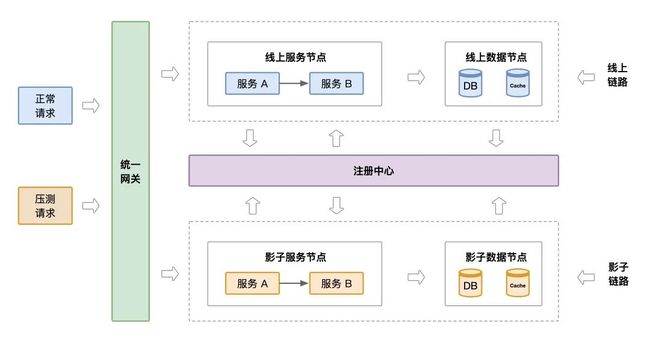
图: 机器打标
以下是实现此方案的流程:
机器抽象化: 所有 DB&Redis&ES 机器抽象成一个一个节点; 节点信息如下图。
机器信息注册到注册中心: 所有节点信息注册到注册中心。
服务接入链路治理SDK: 所有服务接入 "链路治理SDK", "链路治理SDK" 具有根据链路路由请求的能力。

图: 节点信息
节点信息说明:
cloud_name: 资源名称, 全局唯一, 一个资源可包含多个节点, 比如 mysql_cluster001 就可以包含一个主节点, 多个从节点。
node_name: 节点名称, 全局唯一, 通常使用 host+port。
host: host 信息。
port: 端口信息。
role: 角色, w: 写节点, r: 读节点。
dada_type: 资源类别, 有 mysql, redis, es 等。
data_link: 链路类别, 有 benchmark(压测), base(生产)。
方案中最重要的是 "链路治理SDK", 它的职责是: 根据链路类别路由请求流量; 如下图所示:

图: 链路治理SDK
它的启动流程如下:
注册服务节点信息。
根据本机的链路类别, 获取对应链路的存储节点信息。
根据存储节点信息, 建立起 DB,Redis, MQ 连接。
最终线上环境, 在机器维度形成两条链路, 处理生产流量的生产链路和处理压测流量的压测链路。
方案比较
下图是对【流量打标】【机器打标】的比较, 两种方案都有优缺点, 达达从安全及系统改造成本出发, 最终选择了【机器打标】方案。
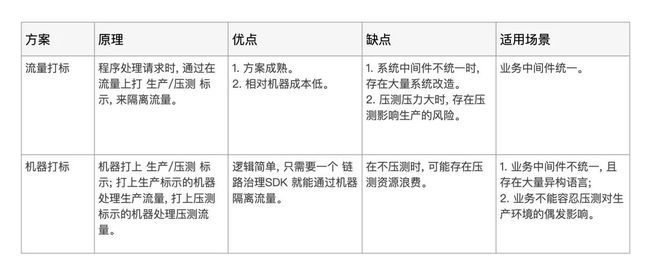
图: 方案比较
2.3 压测平台
原压测方案使用 jmeter 进行压测, jmeter 属于老牌压测工具, 稳定性高且支持分布式; 但在压测场景复杂时,使用不够灵活; 达达的压测多数为复杂场景压测, 所以我们放弃原方案, 转而基于 jmeter 内核开发自己的压测平台; 以下是压测平台的整体架构:
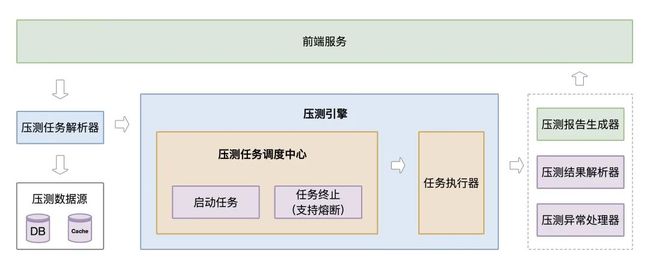
图: 压测平台架构
主要由以下几个核心模块构成:
前端服务: 提供 压测任务填写, 压测任务启动/停止, 压测结果展示等功能。
压测任务解析器: 主要负责压测任务的解析, 存储。
压测引擎: 负责将压测任务调度到执行器上执行 (定时执行 & 立即执行)。
压测结果处理器: 负责对压测接口返回值解析, 统计, 异常处理, 并生成报表。
新压测平台的优势在于: 具有可视化的操作界面, 压测结果实时动态产出; 研发人员在压测平台配置 "发压性能参数", "造数据脚本" 就能直接执行。
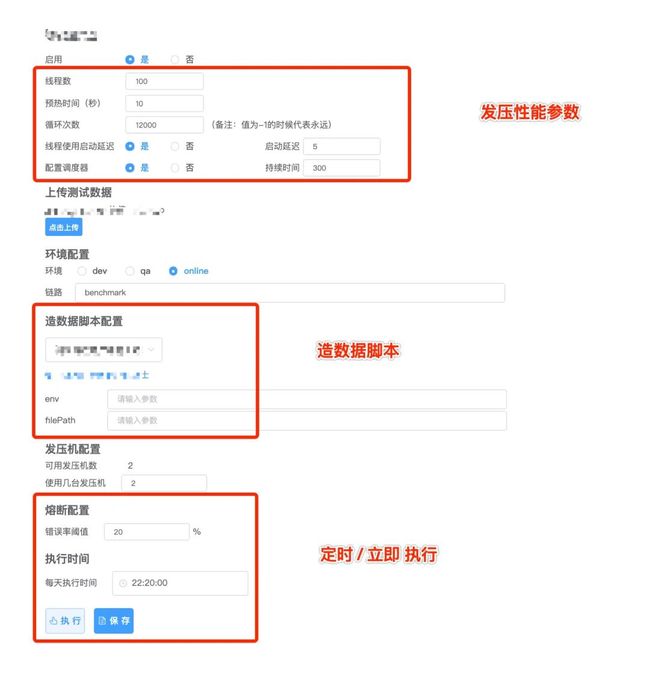
图: 压测平台操作界面
压测引擎在施压时, 对应压测结果 (TPS&响应&错误率) 会实时展示到前端界面。

图: 压测平台结果输出
3. 全链路压测落地
整个全链路压测的落地分成: 压测前, 压测中, 压测后:

图: 压测落地方案
其中 压测前 有三个关键点: 压测链路梳理, 优化预案设定, 精细化压测模型。
3.1 链路梳理
链路的梳理非常重要, 它决定着压测链路需要部署哪些服务, 压测时哪些服务需要被关注。
以前达达通过人肉的方式梳理链路, 但是这种方案效率低, 不准确, 工作量大, 且当生产环境链路变更时, 我们不能即时感知到; 后面引入 APM(PinPoint), APM 有梳理链路的功能。
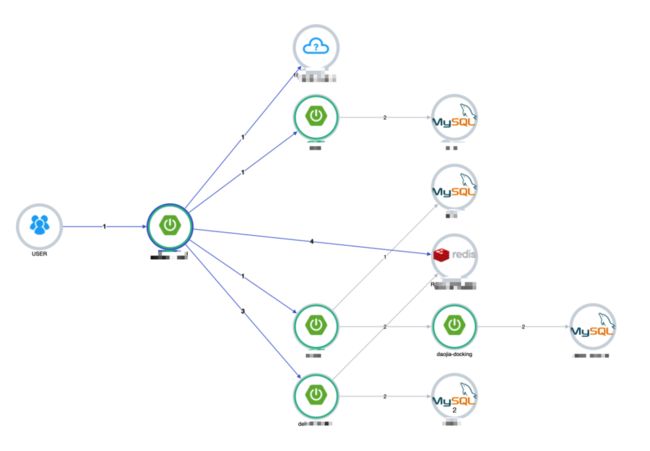
图: 链路梳理
但此方案还是没解决: "实时感知链路变更" 的问题; 为此我们在开发环境拉了条链路, 定时发请求以检测是否链路通畅; 若链路依赖有变化, 我们就能立刻知道。
3.2 优化预案设定
俗话说: 不打无准备之战, 压测就是为了提前发现高负载时系统可能出现的性能隐患, 那如何解决性能隐患呢? 通常在压测之前我们会准备一些性能优化预案, 常用预案如下:
线程池/连接池 打满: 扩容线程池大小(服务CPU未超过阈值时) / 扩容业务服务。
Mysql 主从延迟: Mysql BinLog 调优 -> 升级机器配置 -> 垂直拆库 -> 水平拆库。
Redis 带宽打满: 带宽自动扩容。
MQ 消息堆积: 扩容消费消息的服务方。
因过去几年的业务的发展, 导致生产环境数据库单表单库的数据量一直在增长, 达达物流系统多次碰到 Mysql 主从延迟 ; 目前最常用的优化方案是 "Mysql BinLog 调优", 此方案主要调优以下两个参数:
binlog_group_commit_sync_delay: 表示事务提交后, 等待多少时间, binlog 再同步到磁盘, 默认0, 表示不等待(单位微秒)。
binlog_group_commit_sync_no_delay_count: 表示等待多少事务提交后, binlog 再同步到磁盘。
但此调优方案也有弊端: 参数调优后, 接口响应会有一定提升(如下图); 所以调优时需考虑业务能否容忍接口响应的上升。
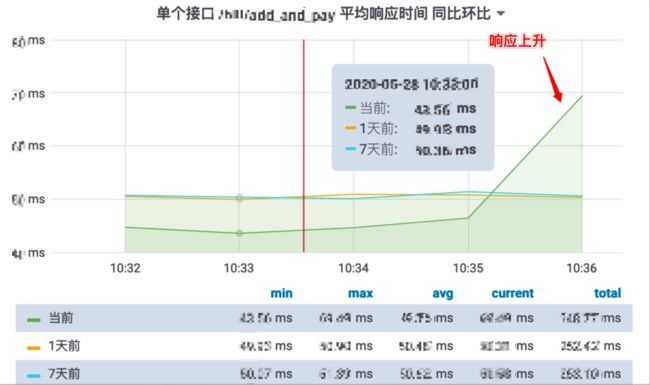
图: 接口响应上升
3.3 精细化压测模型构建
随着业务的发展, 压测模型也在不断演进迭代中; 从一开始 "使用虚拟骑士, 单一按照接口TPS目标值压测" 到现在 "模拟生产活跃骑士, 引入时间&空间因素 构建压测模型", 模型越发精准。模型分成两类:
数据模型: 骑士数据, 商户数据, 订单数据。
流量模型: 订单下发, 配送履约。
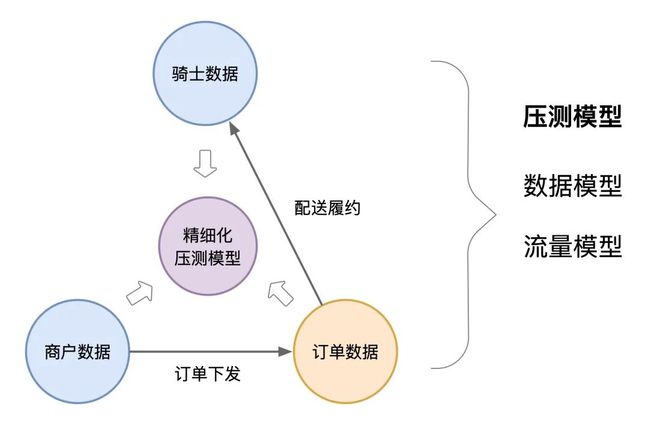
图: 压测模型
数据模型:
把生产上活跃骑士&商户&订单导入影子库, 对这批数据进行清洗, 去除敏感信息(手机号, 地址信息等), 用这些数据进行压测; 此方案简单且能最真实的还原生产环境。
流量模型:
业界常用 【流量回放】方案, 将大促时生产环境的流量存储下来, 然后在压测环境进行回放。
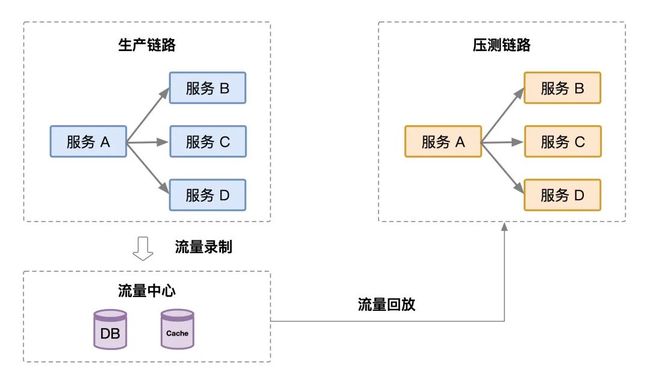
图: 流量回放
此方案适用于读接口的压测, 但是达达的业务场景复杂, 主流程接口多写少读; 所以直接使用此方案肯定不行。

图: 业务主流程
鉴于不能直接使用【流量回放】, 达达选择了【人工构造流量】。影响构造流量真实性主要有两大因素: 时间, 空间。
时间:
在时间上, 达达一天有三个高峰期: 早&午&晚高峰, 每个高峰期 各个接口处于不同状态:
早高峰: 发单, 接单, 订单详情 的请求量处于高峰, 其他接口请求量一般。
午&晚高峰: 订单详情, 取货, 完成 的请求量处于高峰, 其他接口请求量一般。

图: 主流程接口请求量分布
所以压测时, 达达根据业务接口三个高峰期的特点, 设计两个压测场景(午高峰与晚高峰接口状态类似, 合并成一个压测场景), 进行压测。
空间:
在空间上, 订单与骑士不均匀的分布在各地, 有些区域人多单少, 有些区域人少单多, 而对系统影响最大的是人多单多的热点区域。

图: 订单热力分布
达达有个 查看周围X公里订单 的接口, 这个接口的性能跟 热点区域的个数, 每个热点区域内的单量, 每个热点区域内的运力 关系比较大; 为了搞清这几点, 我们分析大促时生产的流量, 根据 geohash 把全国划分成一个个正方形区域, 统计每个正方形区域内的订单及运力; 最后再在压测环境还原并放大。
然后就是 压测中, 主要有这几块: 接口验证, 压测预热, 压测实施, 性能指标观察, 性能问题记录。其中压测预热非常重要, 它决定了压测结果的准确性。
3.4 压测预热
早期每次压测得到的接口响应都比生产环境慢一点, 后面发现: 生产环境的部分数据是热数据, 而压测环境全是冷数据, 这导致压测刚开始进行时, 接口响应偏高, 等过了一分钟后, 响应逐渐降低并趋于平稳; 后面引入压测预热, 使得压测环境的数据, 部分是热数据, 部分是冷数据, 以达到跟生产环境数据一致的效果。
最后就是 压测后; 压测后主要是: 压测报告的生成, 性能隐患定位与优化, 系统容量预估, 压测复盘。下面说一下压测复盘。
3.5 压测复盘
每次的大促复盘, 都能找到下次压测优化的方向; 复盘中最重要的是: 比较 生产与压测环境的 接口TPS&响应,中间件核心指标; 通过这些数据的比较来验证并优化 压测模型。
4. 总结与收益
全链路压测从 2019年一季度立项, 已经历了 4次大促压测考验, 并且完成了目标; 而在全链路压测实施的过程中, 我们认为有三大关键:
流量的隔离: 基于【流量打标】, 达达研发出【机器打标】的隔离方案, 使得压测流量与生产流量完全隔离。
数据的隔离: 基于安全考虑, 达达选择 影子库, 影子缓存, 影子队列, 从而实现生产与压测数据的彻底隔离; 得益于这一点, 压测的实施在白天/晚上随时可进行。
精细化压测模型构建: 压测模型是否跟生产环境相近, 直接影响了压测结果的准确性; 我们参考生产环境大促高峰期的流量, 从时间&空间维度分析, 制作出与大促时相近的压测流量, 从而保证数据模型的真实性。
整个项目的收益也非常明显, 具体从以下两方面分别来看:
稳定性: 目前连续两年大促, 全链路压测每次都能挖掘出10 多项性能隐患, 从而保障了大促的平稳度过。
效率: 相比原先搭建一套独立压测环境的方案, 现在的方案在机器成本上降低 40%, 人效上提升 65%。
当然此方案还有待提升的点, 比如 成本问题; 目前从安全角度出发, 达达通过影子库/缓存实现数据的隔离, 但影子库相比影子表方案机器成本高, 那如何在 安全与成本之间找到平衡, 是压测优化的方向; 另外, 除了挖掘系统隐患点, 全链路压测能否给 "智能运力调度" "运力的合理配置" 提出更多建议, 这也是我们思考的。
作者简介
徐建康: 达达集团高级工程师, 2018年加入达达集团, 负责 达达 2019年&2020年 4次大促压测, 目前投入到 达达智配 项目中, 致力于为即时配送行业提供优质的软件。
顾宝碗: 达达集团架构师, 2019年加入达达集团, 负责 微服务治理,数据源高可用等模块。
张鹏: 达达集团高级测试工程师, 2018年加入达达集团, 负责达达即时配送的测试。
加入我们
达达集团目前还处于高速成长期, 欢迎对技术有追求的同学加入, 可发送简历至: [email protected], 邮件标题: 姓名-上海物流-Java高级开发工程师/资深测试工程师
参考阅读
盘点2021主流架构创新实践 | GIAC
混部之殇-论云原生资源隔离技术之CPU隔离
如何评估Serverless服务能力,这份报告给出了40条标准
性能分析场景下,一种实时分位数计算的系统及方法
爱奇艺全链路压测探索与实践
京东全链路压测军演系统(ForceBot)架构解密
原创及架构实践文章,欢迎通过公众号菜单「联系我们」进行投稿。

2021年GIAC将于6月25-26日在深圳举行,点击阅读原文了解更多详情。