【笔记】社交媒体事件的Hawkes Process建模教程(1)
想对数据或者现象进行Hawkes Process进行建模以及应用的话,还需要对Hawkes Process的来龙去脉有更深刻的理解。所以,在参考A Tutorial on Hawkes Processes for Events in Social Media这篇文章的情况下,打算重新对Hawkes Process进行从理论到应用的梳理。
有需要的朋友也可以直接阅读这篇文章进行学习,它为大家提供了对于self-exciting point-processes的基本概念与方法的介绍,且会对Hawkes Process进行着重介绍。这篇文章包含了从poisson processes,hawkes processes的概念介绍,到使用hawkes process进行建模以及参数估计的全部内容。
由于文章很长,需要时间进行阅读,理解以及整理。所以这篇笔记主要整理前两个部分:Introduction和 Preliminary。
参考链接:
- https://arxiv.org/pdf/1708.06401.pdf
- 伯努利试验_百度百科 (baidu.com)
- 什么是泊松分布?什么是泊松过程?_像我这样迷茫的人的博客-CSDN博客
- Poisson(泊松)过程 - 知乎 (zhihu.com)
目录
1. Introduction: 点过程(Point process)与自激励过程(self-exciting processes)
1.1 点过程(Point process)
1.2 自激励过程(self-exciting processes )
2. Preliminary: Poisson processes (泊松过程)
2.1 泊松过程
2.2 非齐次泊松过程(non-homogeneous Poisson process)
1. Introduction: 点过程(Point process)与自激励过程(self-exciting processes)
1.1 点过程(Point process)
点过程(Point process):点过程是指在某个空间中(例如时间和位置)分布的随机点的集合。
- 这些过程为描述事件的时间和属性提供了统计语言框架。
- 点过程在各个领域中都有广泛的应用,用于解决各种问题。
- 在金融领域中,事件可以表示市场上的买入或卖出股票的交易,影响未来交易的价格和交易量。
- 在在线社交媒体分析中,事件可以是用户随时间发生的行为,每个行为都具有一系列属性,例如用户影响力、兴趣主题和周围网络的连通性。
点过程的定义:点过程是指在非负实线上(通常表示时间)发生事件的随机过程。点过程的实现通常为事件在事件时间![]() 里发生,并体现在实线上的不同位置上。
里发生,并体现在实线上的不同位置上。
- 值得注意的是,事件时间
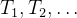 和相应的计数过程
和相应的计数过程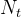 是底层点过程的等效表示。它们提供了不同的视角来观察事件的发生和计数,为我们深入了解过程的行为和特征提供了有益的信息。
是底层点过程的等效表示。它们提供了不同的视角来观察事件的发生和计数,为我们深入了解过程的行为和特征提供了有益的信息。
与点过程等价的计数过程(counting process):计数过程是定义在时间![]() 上的随机函数,取整数值,如1、2等等。计数过程的值表示到时间
上的随机函数,取整数值,如1、2等等。计数过程的值表示到时间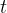 为止点过程中发生的事件数量。因此,由一系列非负随机变量
为止点过程中发生的事件数量。因此,由一系列非负随机变量 唯一确定,满足如果
唯一确定,满足如果![]() ,则
,则![]() 。
。
换句话说,计数过程记录了在时间之前发生的累积事件数量。
![]()
在上述公式中,![]() 是指示函数,当条件为真时取值为1,否则为0。计数过程从
是指示函数,当条件为真时取值为1,否则为0。计数过程从![]() 开始,表示时间0之前没有发生事件。计数过程是分段常数函数,在每个事件时间处跃升1个单位。(此处的指示函数结合概率统计的基础知识进行理解的话,就是将每个事件记为A,当事件发生则取1,未发生则取0)
开始,表示时间0之前没有发生事件。计数过程是分段常数函数,在每个事件时间处跃升1个单位。(此处的指示函数结合概率统计的基础知识进行理解的话,就是将每个事件记为A,当事件发生则取1,未发生则取0)
点过程实例:让我们来看一下图1.1给出的关于Youtube上游戏视频的Retweet Cascade点过程。在这种情况下,每个推文都是在连续时间的某一时刻发生的事件。图1.1中的三个事件使用空心标记表示,它们是前一个推文的转发,或者是一个用户重新分享其他用户内容的行为。
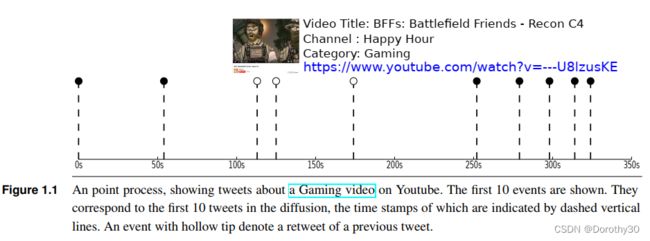
然而,仅仅从点过程出发的话,虽然我们可以明确地观察到通过转发而产生的信息传播,但这个“Retweet Cascade”中还存在其他不容易观察到的传播机制。为了对整体信息传播过程进行建模,一种方法是使用所谓的自激励过程(self-exciting processes ),该过程会由于受过去时间的影响而导致观察到新事件的概率增加。
1.2 自激励过程(self-exciting processes )
自激励过程有各种应用,包括:
- 解释底层过程的特性: 通过使用自激励过程,我们可以深入了解事件生成过程的动态和特征。这些模型使我们能够了解事件之间的相互影响,并对整个过程做出贡献。
- 模拟未来事件: 自激励过程使我们能够基于历史数据中观察到的模式和依赖关系来模拟未来事件。通过捕捉自激励效应,我们可以生成真实场景,并研究潜在结果。
- 预测未来事件的概率和数量: 借助自激励过程所获得的知识,我们可以预测未来事件的概率和数量。这些信息在各个领域中都非常有价值,例如预测股市活动、估计社交媒体平台上的用户参与度以及预测传染病的传播情况。
总之,点过程提供了一种描述事件时间和属性的统计语言。通过利用自激励过程,我们可以更深入地理解事件生成过程,模拟未来事件,并预测未来事件的概率和数量。这些技术在不同领域具有广泛的应用,并在分析受事件动态影响的复杂系统中起着关键作用。
2. Preliminary: Poisson processes (泊松过程)
在介绍更加复杂的point process(Hawkes Process)之前,本文先从最简单的point process,即Poisson processes(泊松过程)开始介绍。
不同于原文直接对Poisson processes进行展开,在这篇笔记中,我会从n重伯努利实验,二项分布,以及泊松分布讲起。从我们熟悉的概率统计知识出发,也许会对泊松过程有更好的理解(至少我梳理起来的时候,是把这些基础知识又顺了一遍>_<,因为泊松过程与泊松分布有关,泊松分布是二项分布的极限情况,二项分布又追溯到伯努利事件….)。
-
n重伯努利试验: 伯努利试验(Bernoulli experiment)是在同样的条件下重复地、相互独立地进行的一种随机试验
 ,其特点是该随机试验只有两种可能结果:发生或者不发生(通常表示为1或0)。我们假设该项试验独立重复地进行了n次,那么就称这一系列重复独立的随机试验为n重伯努利试验。
,其特点是该随机试验只有两种可能结果:发生或者不发生(通常表示为1或0)。我们假设该项试验独立重复地进行了n次,那么就称这一系列重复独立的随机试验为n重伯努利试验。 -
二项分布X~B:假设一次伯努利实验用随机变量
表示,用随机变量 来表示在n重伯努利试验中A事件发生的次数,其概率函数为:
来表示在n重伯努利试验中A事件发生的次数,其概率函数为: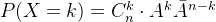
-
泊松分布 (Poisson Distribution):泊松分布是用来描述在一个比较长的时间段(时空)里面,一个很小概率事件发生的次数。
泊松分布可以理解为二项分布的试验次数
 趋向于无穷大时,事件A发生的次数及概率的分布。在理论上,泊松分布是二项分布的极限分布,其概率函数为:
趋向于无穷大时,事件A发生的次数及概率的分布。在理论上,泊松分布是二项分布的极限分布,其概率函数为: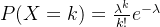
请注意,在泊松分布中,我们关注的重点主要是在事件发生的次数上。参数
 是一段时间内事件A发生的平均次数(期望次数)。
是一段时间内事件A发生的平均次数(期望次数)。
2.1 泊松过程
首先从直观上来说,在一段较长时间 内,若进行无数次伯努利实验的结果服从泊松分布,那么这个实验的过程就是泊松过程。相当于,泊松过程把离散的伯努利实验放在连续的时间轴上进行,使得事件的发生变得连续化了。相对于泊松分布描述在给定时间段内事件发生的次数,泊松过程关注的是事件发生的时间间隔,即,经过多长时间发生一次事件。
内,若进行无数次伯努利实验的结果服从泊松分布,那么这个实验的过程就是泊松过程。相当于,泊松过程把离散的伯努利实验放在连续的时间轴上进行,使得事件的发生变得连续化了。相对于泊松分布描述在给定时间段内事件发生的次数,泊松过程关注的是事件发生的时间间隔,即,经过多长时间发生一次事件。
还是以Figure 1.1的retweet cascade为例,如图所示,在350s前有10条关于视频的tweet被发布,即发生事件的次数为10(k=10),泊松过程描述的就是在陆续观察到有10条相关推特发布的过程,在这个过程中我们关注的重点是,过多长时间会有一条新的tweet被发布(过多少时间间隔会有一个新事件发生)。
泊松分布与泊松过程的关系:实际上,泊松分布可以看作是泊松过程的一个特例,它描述了在一个特定时间段内事件发生的次数。当我们观察泊松过程的时间间隔,并记录在给定时间段内事件的数量时,这些事件的数量就可以用泊松分布进行建模。
下面将继续结合上文的例子对泊松过程进行介绍,以及对泊松过程的数学特征进行推导。
-
到达(Arrival):在泊松过程中,我们把进行了发了一条关于gaming video的tweet的事件叫做到达。
-
到达时间间隔:到达时间间隔
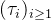 表示,每个
表示,每个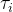 是相互独立的,事件到达的时间间隔序列则可以使用组成的序列表示。例如,第一个事件在
是相互独立的,事件到达的时间间隔序列则可以使用组成的序列表示。例如,第一个事件在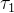 发生,第二个事件在
发生,第二个事件在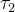 发生。
发生。 -
到达次数与计数过程(Arrival times and counting process):在第n次事件到达的时间点用
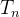 表示。因此每次事件到达的时间点
表示。因此每次事件到达的时间点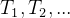 便可以在非负的时间轴上表示为一个个点。到达次数可以由下式得到
便可以在非负的时间轴上表示为一个个点。到达次数可以由下式得到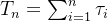
相对应的,计数过程
记录的是区间[0, t]的事件发生次数,会随着每个逐一递增,并可以表示为如下的形式
-
事件强度
(Event intensity): 是指单位时间内平均事件发生的次数。前面提到的每个到达时间间隔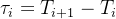 都服从参数为 的指数分布,该概率密度函数
都服从参数为 的指数分布,该概率密度函数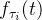 表示为:
表示为:
-
时间间隔服从指数分布的原因:对于一个特定的时间间隔(时间长度)
,时间在该时间间隔内发生的概率为,即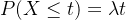 ,
, 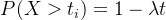 。当我们观察到连续的事件时间间隔时,每个时间间隔是否大于t是相互独立的,因此我们可以将这些事件的概率相乘,得到最终的概率为
。当我们观察到连续的事件时间间隔时,每个时间间隔是否大于t是相互独立的,因此我们可以将这些事件的概率相乘,得到最终的概率为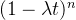 ,其中n是观察到的时间间隔的个数。当观察时间间隔趋近于无穷大时(即n趋近于无穷大),根据极限的性质,趋近于指数函数
,其中n是观察到的时间间隔的个数。当观察时间间隔趋近于无穷大时(即n趋近于无穷大),根据极限的性质,趋近于指数函数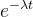 。
。因此,
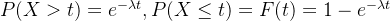 ,服从指数分布。
,服从指数分布。 -
相对应的,时间间隔的期望值(均值)为
 , 计算过程如下
, 计算过程如下![E_\tau[t]=\int_0^\infty tf_\tau(t) dt=\int_0^\infty t\lambda e^{-\lambda t}dt=\lambda\int_0^\infty t e^{-\lambda t}dt](http://img.e-com-net.com/image/info8/4389cec0e39b4d0e8da15226260d1da1.png)
-
![]()
![]()
![]()
-
一般来说,事件强度不需要是恒定的,而是时间的函数,写成
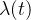 。这种一般情况被称为非齐次泊松过程
。这种一般情况被称为非齐次泊松过程 -
泊松过程的无记忆性:无记忆指的是未来的时间间隔的分布仅取决于当前时间的相关信息,而与过去的信息无关。泊松过程也具有这种性质。
根据前面计算得到的间隔时间
 大于的概率可得,在时间
大于的概率可得,在时间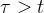 时观察到新事件到达的概率为
时观察到新事件到达的概率为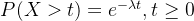 。
。假设我们正在等一个新事件的到来(比如一个推特的发布),由于推特发布的间隔时间服从参数为
的指数分布,假设已经过了 个时间单位还是没有事件到达,即在时间间隔
个时间单位还是没有事件到达,即在时间间隔![[0,m]](http://img.e-com-net.com/image/info8/520375a52f2447189696a9408cbe540a.png) 期间没有事件。我们再等待个时间单位后时间发生的概率为
期间没有事件。我们再等待个时间单位后时间发生的概率为通过推导可以发现,在已经等待了
个时间单位之后再等待个时间单位,这与在时间0开始时必须等待个时间单位的结果相同。
2.2 非齐次泊松过程(non-homogeneous Poisson process)
在泊松过程中,事件以恒定强度随机到达。 这个初始模型足以描述简单的过程。 然而,我们需要能够随时间改变事件强度,以描述更复杂的过程,例如模拟高峰时段和非高峰时段的汽车到达。在非齐次泊松过程中,事件的到达是时间的函数,即![]()
一个点过程 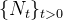 可以被条件强度函数完整的刻画,如下所示
可以被条件强度函数完整的刻画,如下所示
![]()
![]() 是截止的历史过程(history process),由一系列的事件的发生时间
是截止的历史过程(history process),由一系列的事件的发生时间![]() 组成。后文会直接用简写来表示
组成。后文会直接用简写来表示![]() 。
。
事件强度![]() 决定了事件发生时间的分布,进而决定了计数过程。更为正式地说,
决定了事件发生时间的分布,进而决定了计数过程。更为正式地说,![]() 和可以通过在一个很短的时间段h的事件发生概率来进行关联:
和可以通过在一个很短的时间段h的事件发生概率来进行关联:
![]()
![]()
![]()
在时间间隔为到![]() 且
且![]() 时,观察到一个事件的概率为
时,观察到一个事件的概率为![]() ,在相同时间间隔里观察到两个以上时间的概率微乎其微。
,在相同时间间隔里观察到两个以上时间的概率微乎其微。
以上就是我关于论文第一二部分的理解与展开,如果有不对的地方欢迎提出并指正!!