Pandas常用指令
astype
astype的作用是转换数据类型,astype是没办法直接在原df上进行修改的,只能通过赋值的形式将原有的df进行覆盖,即df = df.astype(dtype)
astype的基本语法
DataFrame.astype(dtype, copy=True, errors='raise')dtype参数指定将数据类型转换为的目标类型,如str,float,int等等。
copy参数表示是否创建数据的副本,默认为 `True`。
errors参数定义如何处理转换过程中的错误,默认为 `'raise'`,表示遇到错误时引发异常。
常用的形式就是直接
DataFrame.astype(dtype)下面介绍常用的几个操作
数据集
data = {
'col1': [10, 20, 30],
'col2': [0.1, 0.2, 0.3],
'col3': ['A', 'B', 'C'],
'col4': [True, False, True]
}
df = pd.DataFrame(data) 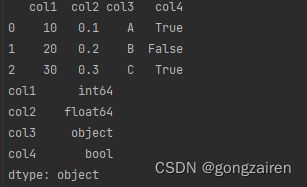
将整个df转变数据类型
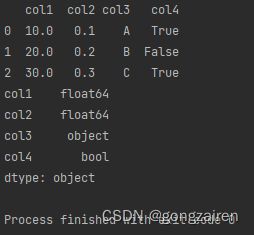
df = df.astype(str)
将整个df转为字符串的类型,object 是泛指的对象数据类型,它可以包括字符串、Python 对象和其他不可变对象
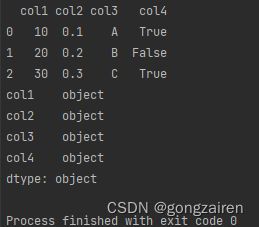
将df某一列转变数据类型
df['col1'] = df['col1'].astype(float)
能够将【col1】这列原本的int数据类型,转为float类型
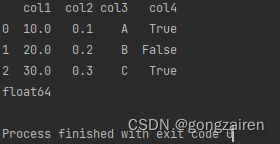
将df某多列转变数据类型
df[['col1','col2']] = df[['col1','col2']].astype(float)
concat
concat的作用是将多个dataframe对象进行水平或垂直合并
concat的基本语法
pd.concat(objs, axis=0, join='outer', ignore_index=False) objs: 必需参数,表示要拼接的对象(例如,DataFrame,Series 或 Panel)的序列、映射或 DataFrames 列表。
axis: 可选参数,默认为 0。指定拼接的轴方向,0 表示按行拼接,1 表示按列拼接。
join: 可选参数,默认为 'outer'。指定如何处理拼接后的索引。
'outer':保留所有的索引。
'inner':只保留共有的索引。
ignore_index: 可选参数,默认为 False。指定是否重置索引。
True:重置拼接后的轴上的索引。
False:保留原始索引。
常用的形式就是直接
pd.concat(objs)数据集
df1 = pd.DataFrame({'A': [1, 2, 3],
'B': [4, 5, 6]})
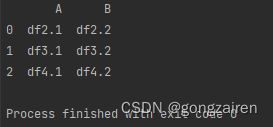
df2 = pd.DataFrame({'A': ["df2.1", "df3.1", "df4.1"],
'B': ["df2.2", "df3.2", "df4.2"]}) 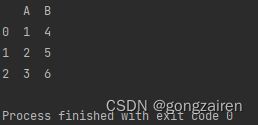
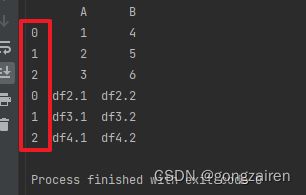
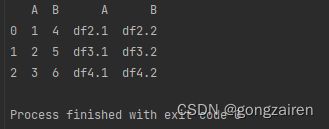
axis(默认为0)
result = pd.concat([df1, df2])
result = pd.concat([df1, df2],axis=1)
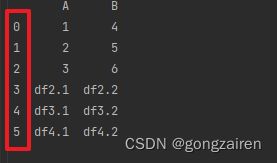
ignore_index(默认为False)
result = pd.concat([df1, df2])
result = pd.concat([df1, df2],ignore_index=True)
to_datetime
to_datetime的作用是将字符串的时间格式转为对应的时间对象,to_datetime是没办法直接在原df上进行修改的,只能通过赋值的形式将原有的df进行覆盖,即df = df.to_datetime(arg)
to_datetime的基本语法
pd.to_datetime(arg, format=None, errors='raise', dayfirst=False, yearfirst=False, utc=None, box=True, exact=True, unit=None, infer_datetime_format=False, origin='unix', cache=True)
arg:必需参数,指定要转换的日期或时间对象。可以是字符串、整数、浮点数、列表、Series、DataFrame 等对象。
format:可选参数,用于指定输入日期或时间字符串的格式。如果未提供,则尝试自动推断格式。常见的格式代码如 %Y(4 位年份)、%m(月份)等。详细的格式代码列表可以在官方文档中找到。
errors:可选参数,指定如何处理转换错误。
'raise':默认值,遇到转换错误时抛出异常。
'ignore':忽略转换错误,不会抛出异常,返回原始对象。
'coerce':将转换错误的值设为 NaT(不可用时间)。
其他参数:dayfirst、yearfirst、utc、box、exact、unit、infer_datetime_format、origin、cache 等可以进一步调整转换行为和性能,根据需要进行设置。
常用的形式就是直接
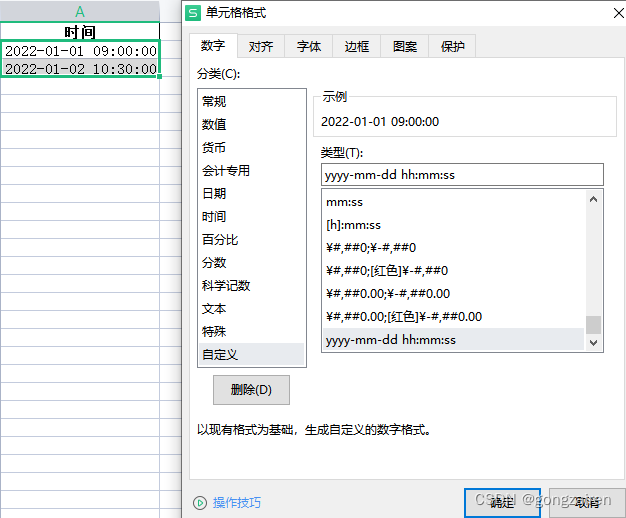
pd.to_datetime(df['时间'])数据集
df = pd.DataFrame({'时间': ['2022-01-01 09:00:00', '2022-01-02 10:30:00']})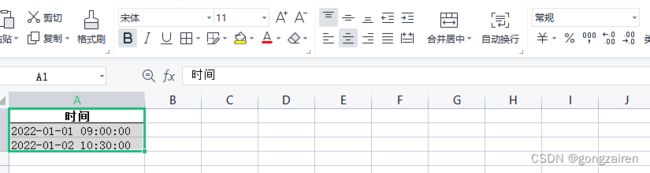
格式转换
pd.to_datetime(df['时间'], format='%Y-%m-%d %H:%M:%S')
df['时间'] = pd.to_datetime(df['时间'], format='%Y-%m-%d %H:%M:%S')
df.to_excel('output.xlsx', index=False)