zookeeper
概要:
数据不一致场景
1、zk过半成功,剩余未commit的节点
2、leader未发送proposal宕机
3、leader发送proposal成功,发送commit前宕机
zk简介
Google下Chubby的一个开源的实现,是Hadoop的分布式协调服务。Chubby就是一个分布式文件系统,可解决分布式系统中的数据不一致问题。
特性:
1、最终一致性:为客户端展示统一视图,即所有客户端看到的数据都一致;
2、顺序性:所有server,同一消息发布顺序一致,通过每个提议都会生成唯一递增的zxid保证;
3、可靠性:如果消息被一台服务器接受,那么它将被所有服务器接受;
4、实时性:zk无法保证所有的客户端同时得到最新更新的数据,但可通过 sync api使当前被客户端连接的server被读取数据前与Leader同步一次数据;
5、独立性:各client互不干扰;
6、原子性:更新要么成功,要么失败,没有中间态,保证原子性操作。
zk角色
Leader:领导者,负责决议的发起和提交,接收follower转发的写操作;
follower:跟随者,选主时参与投票,接收客户端的读请求并返回数据,接收客户端的写请求并转发给Leader处理;
observer:为了横向拓展,提升系统读能力,不参与投票的特殊follower。同步Leader状态,并将写请求转发给Leader。

Observer与follower拓展规则
1、提升zk读请求能力,增加Observer,而非follower
当zk集群读压力很大时,可增加Observer,最好不要增加follower,原因是zk主从同步数据是基于过半机制+类似二阶段提交(参考下方的zk数据同步机制),leader最终才commit,若follower太多,会降低写操作效率,且在leader选举时会增大投票与统计选票的压力。
2、observer数量<=follower数量
observer数量一般与follower数量相同,当observer数量太多时,虽然不会增加事务操作压力,但其需要从leader同步数据,observer同步数据的时间<=follower同步数据的时间。当follower同步数据完成,leader的observer列表中的observer主机将结束同步。
完成同步的observer将会在另一个对外提供服务的列表,每同步数据的无法提供服务造成资源浪费。所以对于事务操作频繁的系统,不建议使用过多的observer。
Zab协议
Zookeeper Atomic Broacast,zk原子消息广播协议,专为zk涉及的一种支持崩溃恢复的原子广播协议,在zk中,主要依赖ZAB协议来实现分布式数据一致性。
ZAB协议时Paxos算法的一种工业实现算法,ZAB协议主要用于构建一个高可用的分布式数据主从系统,即Follower是Leader的从机,主机挂了,可以马上选举一个新的leader,但平时都对外提供服务。并且ZAB协议使用Chubby算法作为分布式锁的实现。
Paxos算法是为了解决一个分布式系统如何就某个值(提议/Proposal)达成一致,是一种基于消息传递模型的一致性算法。
为了保证事务的顺序一致性,集群采用ZAB原子广播协议,采用递增的事务id号(zxid)来标识事务。所有的提议(proposal)都在被提出时加上了Zxid。Zxid是一位64位的数字,高32位是epoch用来标识leader关系是否改变,每个leader被选举出,都会有一个新的epoch(leader周期纪元),标识当前属于哪个leader的统治周期。低32位是用户递增计数的。
ZAB模式
ZAB协议有三种模式:
恢复模式:当集群启动,或leader挂了,zk集群需进入恢复模式,包含两个阶段:leader选举与初始化同步;
广播模式:分为两类,初始化广播和更新广播;
同步模式:分为两类,初始化同步与更新同步。
1、恢复模式-leader选举
当服务启动或Leader宕机后,Zab进入恢复模式,当领导者被选举出来,且大多数server完成了和Leader状态同步后,恢复模式就结束了。状态同步保证了leader和server具有相同的系统状态。
过半机制(Paxos协议):集群中半数以上的机器存活,集群才可用。这也是zk建议配置奇数台机器上的原因。集群第一次启动时,假设当前有5台机器,myid配置为1~5,且都为最新启动没有历史数据的。
则逻辑会如下:
- 服务器1启动,因当前仅一台服务器,发出的请求没有响应,状态为LOOKING,且默认都将票投给自己;
- 服务器2启动,此时服务器1与2建立连接,并且myid服务器2大于1,所以服务器2成为leader的票数为2,但任没有达到过半机制,状态都还为LOOKING;
- 服务器3启动,此时服务器1、2与3建立连接,因服务器3的myid最大,leader投票都给3,达到过半机制(3台服务器,至少2票),所以服务器3成为Leader,服务器1、2成为follower;
- 服务器4启动,虽然此时myid最大,但集群中已存在leader,所以成为follower;
- 服务器5与服务器4逻辑一致。
相关概念
SID:服务器ID。用来唯一标识一台zk集群中的机器,不可重复,与myid一致;
ZXID:事务ID。用来标识一次服务器状态的变更,某一时刻,因zk服务器与客户端更新请求的处理逻辑,每台机器的ZXID值不一定完全一致,比如写请求过半follower响应并commit,还有剩余的机器未commit。
逻辑时钟:Logicalclock,是一个整型数,该概念在选举时称为logicalclock,而在选举结束后称为 epoch。即epoch与logicalclock是同一个值,在不同情况下的不同名称。Epoch也是每个Leader任期的代号,该值伴随每次的投票都会增加。
选举Leader规则
1、Epoch最大;
2、Epoch相同,则ZXID(事务id)最大;
3、事务id相同,则myid最大。
zk中各服务器可能存在的状态
LOOKING:寻找leader状态,在初次启动、leader宕机重选时;
FOLLOWING:跟随者状态,当集群中存在leader后其他与leader通讯正常的服务器状态;
LEADING:领导者状态;
OBSERVING:观察者状态,表示当前服务器为观察者。
2、恢复模式-初始化同步
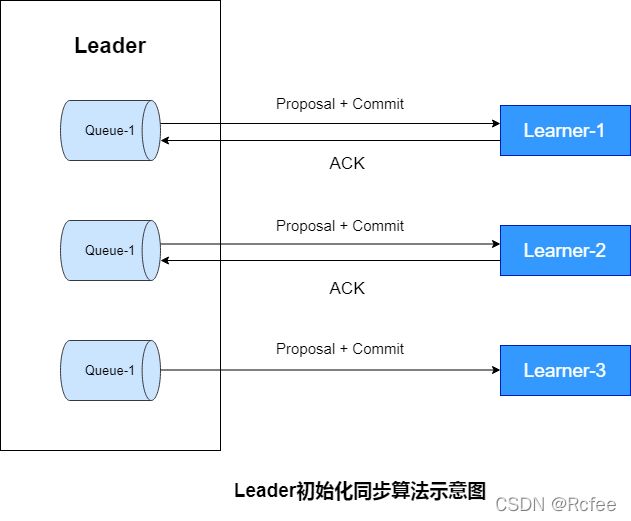
zk在经过leader选举后,leader需与Learner同步后,才能成为真正的Leader,步骤如下:
- 为了保证leader与learner发送的提议有序,leader会为每一个learner服务器准备一个队列;
- leader将未被同步的事务封装为Proposal(提议);
- leader将Proposal逐条发送给各个learner,并在每个Proposal后紧跟一个commit,标识该事务已提交,learner可直接接收并执行;
- learner接收来自leader的Proposal,并更新至本地;
- 当Learner更新成功后,向leader发送ACK消息;
- leader收到来自learner的ACK后会将learner加入真正可用的Follower列表或Observer列表。没有反馈ACK,或反馈了但leader没有收到的learner,leader不会将其加入到相应的列表。
3、广播模式-更新广播
当集群的learner完成初始化状态同步,整个集群进入正常工作模式。
如果集群中的learner节点收到客户端的事务请求,则这些请求会转发给leader服务器。然后执行以下过程:
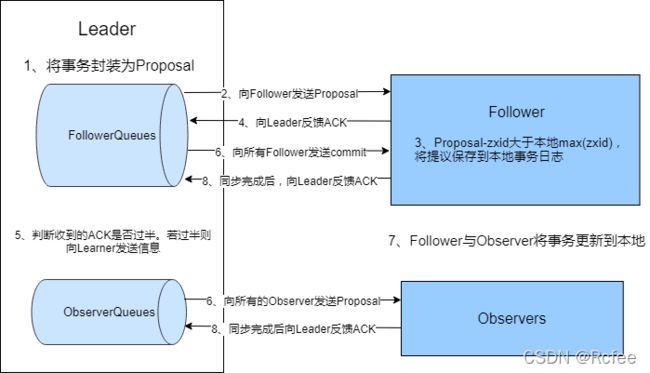
1、leader接收更新请求,为事务赋予一个全局唯一的64位自增id,即Zxid,通过zxid的大小比较即可实现事务的有序管理,然后将事务封装成一个proposal;
2、leader根据follower列表获取所有的follower,然后将proposal通过这些follower的队列将提议发送给各个follower;
3、当follower接收到提议后,会先将提议中的zxid与本地记录的事务日志中的最大zxid比较,若当前提议zxid大于最大zxid,则将当前提议记录到本地事务日志中,并向leader返回一个ACK;
4、当leader收到集群中过半的ACK后,leader会向所有的follower发送commit消息,向所有的observer队列发送proposal;
5、当follower接收到acommit消息后,就会将事务正式更新到本地。当observer收到proposal后,会直接将事务更新到本地;
6、无论是follower还是observer,在同步完成后都需要向leader发送成功的ACK。
zk数据不一致场景
1、zk过半成功,剩余未commit的节点
场景:比如5个节点,有三个返回写入成功,则如果有读请求到另两个节点,则会数据不一致。
解决方案:sync API
原理:sync是使client当前连接的Zookeeper服务器,和zk的Leader节点同步(sync)一下数据。
1)客户端掉用zk.sync()方法,生成一个ZooDefs.OpCode.sync类型的请求;
2)当follower收到sync请求时,将进行以下步骤:
- 添加至ConcurrentLinkedQueue
pendingSyncs中,ConcurrentLinkedQueue通过volatile和CAS保证线程安全; - 将request packet发送至Leader;
- Leader收到sync请求,需执行完当前待commit的决议后发送Leader.SYNC消息给follower,如果没有则立即发送一个Leader.SYNC消息给follower,。
当follower与Leader之前的通信时按顺序(TCP保证)发送的,因此follower会同步所有Leader之前(Lewader接收到sync之前)commit的所有决议。
添加到pendingSyncs队列中的类:FollowerRequestProcessor.java
public void run() {
try {
while (!finished) {
Request request = queuedRequests.take();
if (LOG.isTraceEnabled()) {
ZooTrace.logRequest(LOG, ZooTrace.CLIENT_REQUEST_TRACE_MASK,
'F', request, "");
}
if (request == Request.requestOfDeath) {
break;
}
// We want to queue the request to be processed before we submit
// the request to the leader so that we are ready to receive
// the response
nextProcessor.processRequest(request);
// We now ship the request to the leader. As with all
// other quorum operations, sync also follows this code
// path, but different from others, we need to keep track
// of the sync operations this follower has pending, so we
// add it to pendingSyncs.
switch (request.type) {
case OpCode.sync:
zks.pendingSyncs.add(request);
zks.getFollower().request(request);
break;
... ...将request发送至Leader的类:Learner.java
/**
* send a request packet to the leader
* @param request:the request from the client
* @throws IOException
*/
void request(Request request) throws IOException {
ByteArrayOutputStream baos = new ByteArrayOutputStream();
DataOutputStream oa = new DataOutputStream(baos);
oa.writeLong(request.sessionId);
oa.writeInt(request.cxid);
oa.writeInt(request.type);
if (request.request != null) {
request.request.rewind();
int len = request.request.remaining();
byte b[] = new byte[len];
request.request.get(b);
request.request.rewind();
oa.write(b);
}
oa.close();
QuorumPacket qp = new QuorumPacket(Leader.REQUEST, -1, baos
.toByteArray(), request.authInfo);
writePacket(qp, true);
}Leader commit后移除pendingSyncs的类:Learner.java的tryToCommit()方法中
/**
* @return True if committed, otherwise false.
**/
synchronized public boolean tryToCommit(Proposal p, long zxid, SocketAddress followerAddr) {
... ...
zk.commitProcessor.commit(p.request);
if(pendingSyncs.containsKey(zxid)){
for(LearnerSyncRequest r: pendingSyncs.remove(zxid)) {
sendSync(r);
}
}
return true;
}2、leader未发送proposal宕机
这也就是数据同步说过的问题。
leader与follower之间同步数据的步骤如下,类似二阶段提交:
- leader接收写请求,发起一个proposal提议,并生成一个全局性的唯一递增ID(zxid),并放入一个FIFO队列;
- follower收到proposal提议后,以事务日志的形式写入本地磁盘,并返回ACK给leader;
- leader收到过半follower的ACK之后,发起commit给follower提交proposal,当过半提交成功后leader就会commit。
leader刚生成一个proposal,还没有来得及发送出去,此时leader宕机,重新选举之后作为follower,但是新的leader没有这个proposal。
这种场景下的日志将会被丢弃,也就是该条消息丢失。
3、leader发送proposal成功,发送commit前宕机
如果发送proposal成功了,但是在将要发送commit命令前宕机了,如果重新进行选举,还是会选择zxid最大的节点作为leader,因此,这个日志并不会被丢弃,会在选举出leader之后重新同步到其他节点当中。