4.正则提取html中的img标签的src内容
我们以百度贴吧的1吧举例

目录
1 把网页搞下来
2 收集url
3 处理url
4 空的src
5 容错
6 不使用数字作为文件名
7 并不是所有的图片都用img标签表示
8 img标签中src请求下来不一定正确
9 分页
1 把网页搞下来

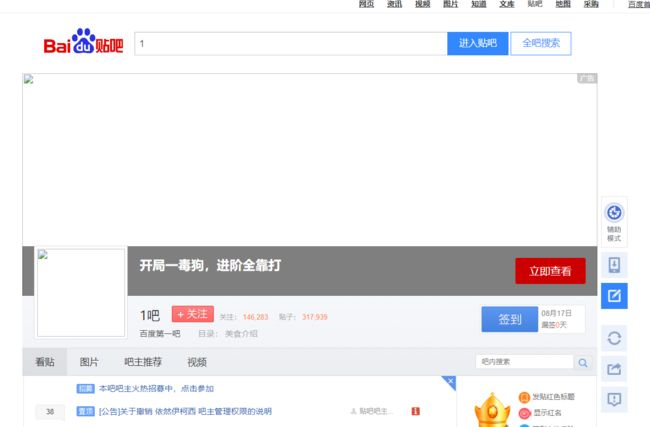
搞下来之后,双击打开是这样的
2 收集url
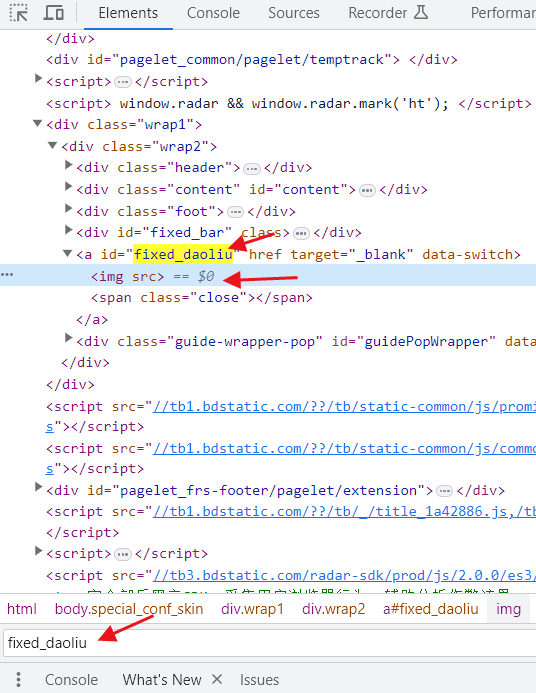
我们实际拿的就是 img标签中src的内容,比如这个
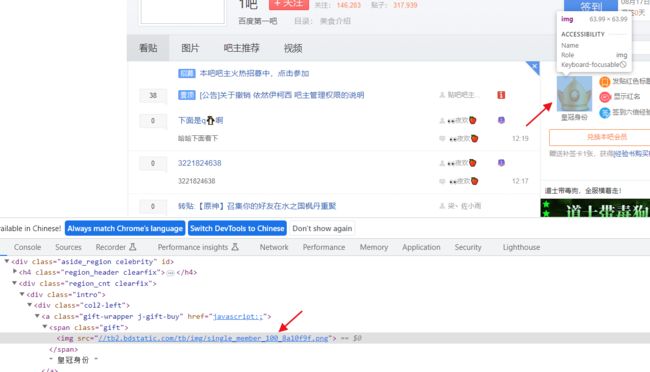
我们通过正则获取一下
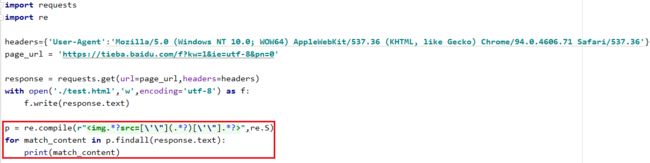
我们得到了这些结果
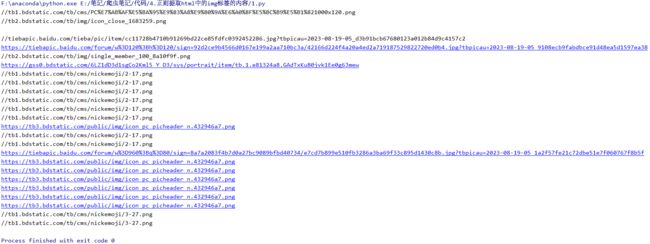
3 处理url
我们发现上面好多url都没有协议,那么我们需要给协议加上,然后发起请求,保存。我们用数字作为保存图像的名称
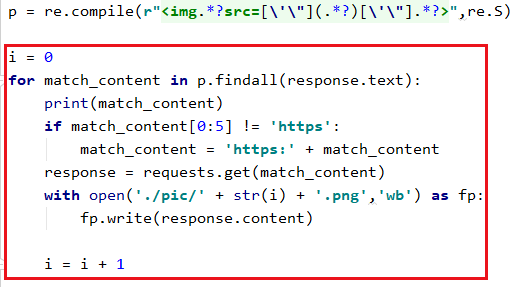
运行后发现报错了
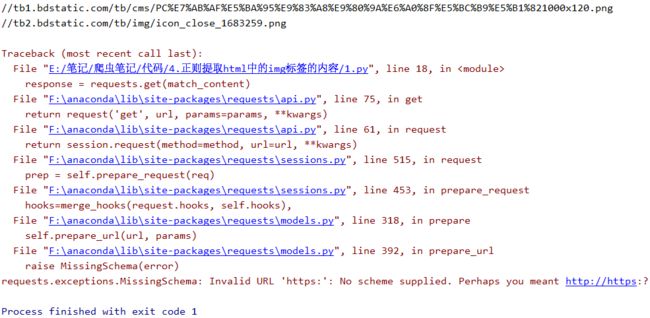
4 空的src
错误的原因是我们获取的结果,第三条是空的
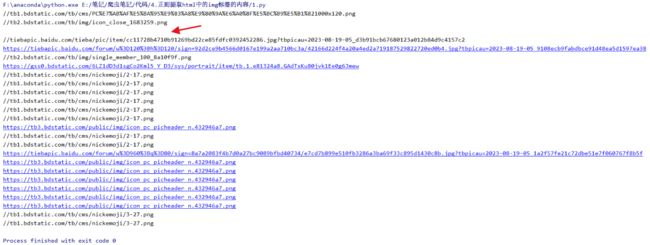
这种就是前端用来占位的,我们在保存的html中可以看到确实是没东西

这时候如果不确定的话,可以用浏览器访问,然后搜一下,发现在浏览器中它也是空的
5 容错
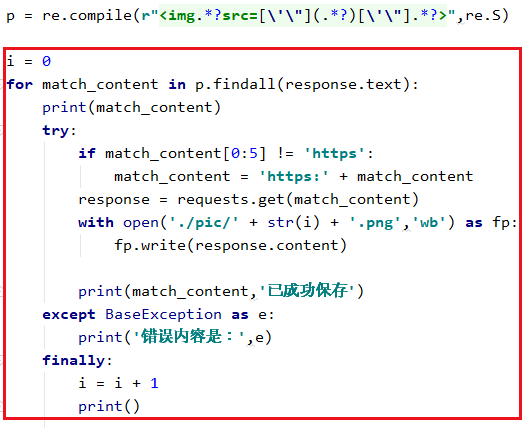
除了空的src,之后还可能会有很多问题,比起通过if来判断是否为空,在调试阶段中,我更倾向用try还except来捕获错误
这一次我们保存了很多的图片
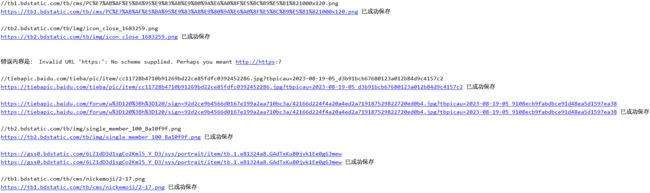
但我们发现重复的图像太多了

6 不使用数字作为文件名
现在有很多方法来进行数据去重,比如使用hash库,我们这里使用文件名的方式去重,如果html中引入的文件相同,那他们的文件名也应该相同
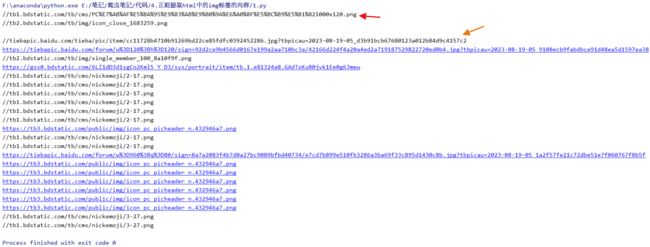
我们发现有两种格式的url,一种是红色箭头的url以文件格式结尾,另一种是不以文件格式做结尾。但他们都有一个共同点,文件名都在最后一个斜杠的后面
那么我们可以这样写
- 这样写有个缺点,对于查询字符串的url直接给了数字与png做名字
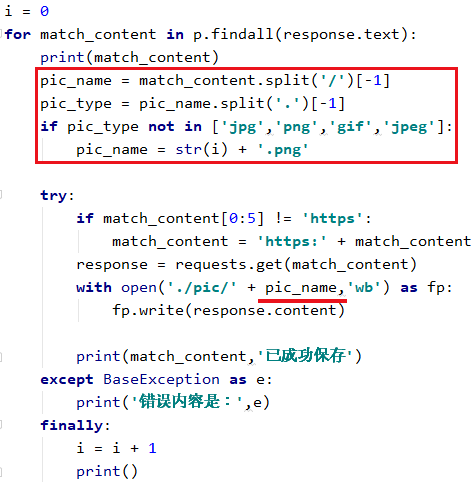
至此img的src内容已经全搞下来了
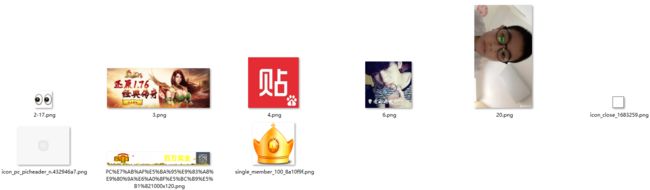
7 并不是所有的图片都用img标签表示
比如这张图
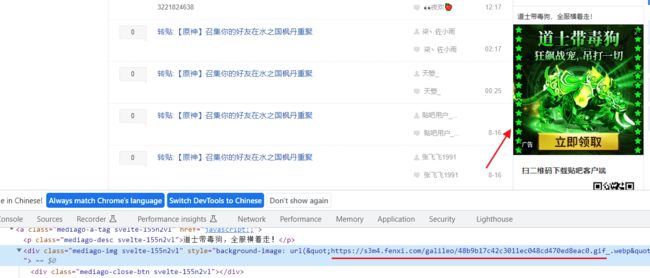
还有这张图
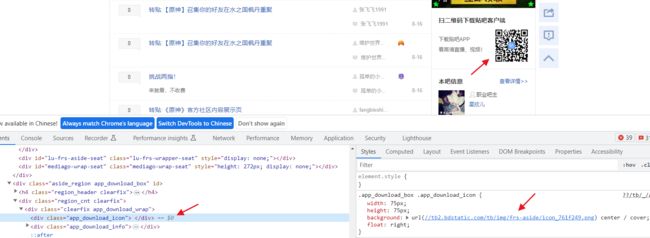
8 img标签中src请求下来不一定正确
比如这里,我保存的网页是这样的
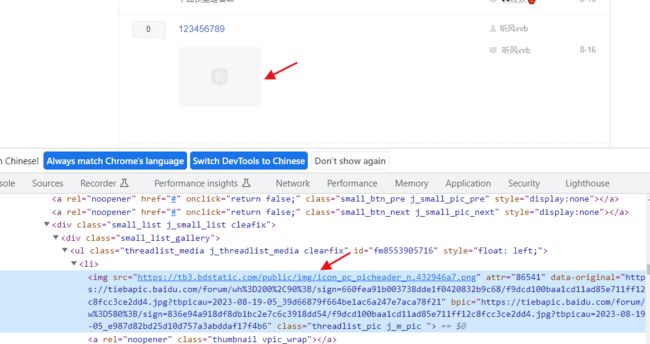
但实际是这样的

我们这个时候就要关注img标签的其他属性,比如这里的 data-original与bpic,用浏览器访问data-original的地址,会得到缩略图

用浏览器访问bpic的地址会得到这张大图
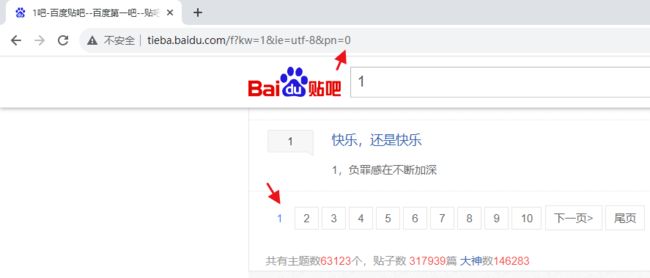
9 分页
像这种分页一般由于url挂钩,第一页pn是0
第二页pn是50
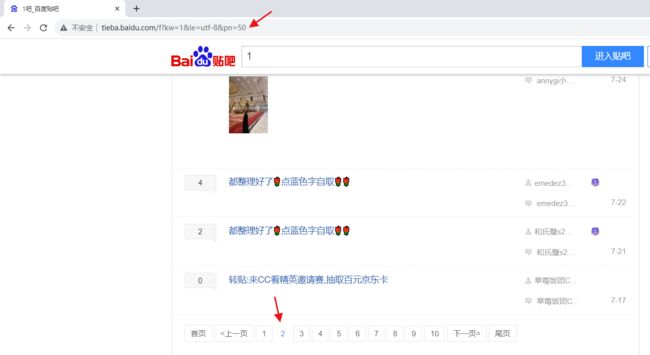
之后的pn就会是100,150,200这种,我们可以利用这个特性爬取多页
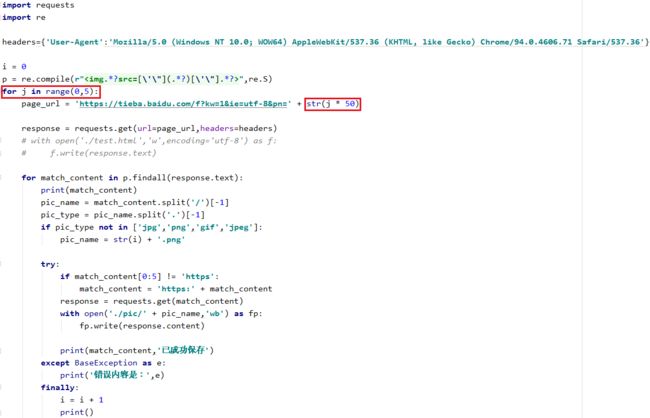
发现可以成功爬取一些图片