mysql索引
文章目录
- 1. 概述
- 2. 索引结构
- 3. 索引分类
- 4. 索引语法
- 5. SQL性能分析
- 6. 索引使用
- 7.索引设计原则
1. 概述
索引(index)是帮助mysql高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据上实现高级查找算法,这种数据结构就是索引。
| 优势 | 劣势 |
|---|---|
| 提高数据检索的效率,降低数据库的IO成本 | 索引列也是需要占用空间的 |
| 通过索引列对数据进行排序,可以降低数据的排序成本,降低CPU的消耗 | 索引大大提高了查询效率,同时却降低更新表的速度,如对表进行Insert、Update、Delete时,效率降低 |
2. 索引结构
mysql的索引时在存储引擎层实现的,不同的存储引擎有不同的结构,主要包含以下几种:
| 索引结构 | 描述 |
|---|---|
| B+Tree索引 | 最常见的索引类型,大部分引擎都支持B+树索引 |
| Hash索引 | 底层数据结构是用hash表实现的,只有精确匹配索引列的查询才有效,不支持范围查询 |
| R-tree索引(空间索引) | 空间索引MyISAM引擎的一个特殊索引类型,主要用于地理和空间数据类型,通常使用较少 |
| Full-text(全文索引) | 是一种通过建立倒排索引,快速匹配文档的方式,类似于Lucene,Solr,ES |
| 索引 | innoDB | MyISAM | Memory |
|---|---|---|---|
| B+tree | 支持 | 支持 | 支持 |
| Hash索引 | 不支持 | 不支持 | 支持 |
| R-tree索引 | 不支持 | 支持 | 不支持 |
| Full-text | 5.6版本之后的支持 | 支持 | 不支持 |
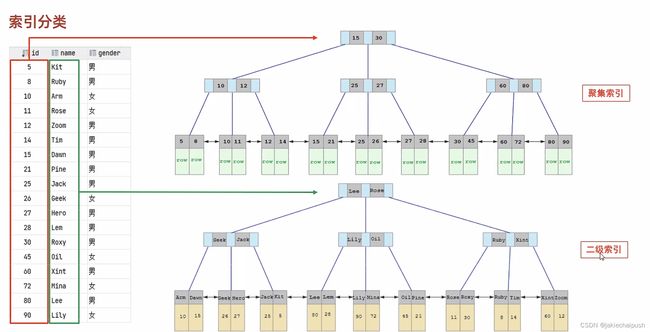
3. 索引分类
| 分类 | 含义 | 特点 | 关键字 |
|---|---|---|---|
| 主键索引 | 针对于表中主键创建的索引 | 默认自动创建,只能有一个 | PRIMARY |
| 唯一索引 | 避免同一个表中某数据列中的值重复 | 可以有多个 | UNIQUE |
| 常规索引 | 快速定位特定数据 | 可以有多个 | |
| 全文索引 | 全文索引查找的是文本中的关键词,而不是比较索引中的值 | 可以有多个 |
在InnoDB存储引擎中,根据索引的存储形式,又可以分为一下两种:
| 分类 | 含义 | 特点 |
|---|---|---|
| 聚集索引 | 将数据索引放到一块,索引结构的叶子结点保存了行数据 | 必须有,而且只有一个 |
| 二级索引 | 将数据与索引分开存储,索引结构的叶子结点关联的是对应的主键 | 可以存在多个 |
聚集索引选取规则:
- 如果存在主键,主键索引就是聚集索引
- 如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引
- 如果表没有主键,或没有合适的唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚集索引
4. 索引语法
- 创建索引
CREATE [UNIQUE|FULLTEXT] Index index_name On table_name (index_col_name.....)
- 查看索引
show index from table_name
- 删除索引
Drop index index_name on table_name
5. SQL性能分析
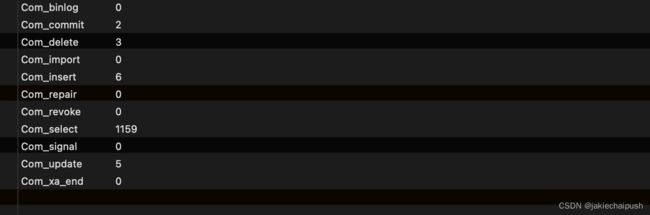
- SQL执行频率
MYSQL客户端连接成功后,通过show [session(当前会话)|global(全局)] status命令可以提供服务器状态信息。通过一下指令,可以查看当前数据库的Inser、Update、Delete、Select的访问频次:
show global status like 'Com_______';
- 慢查询日志
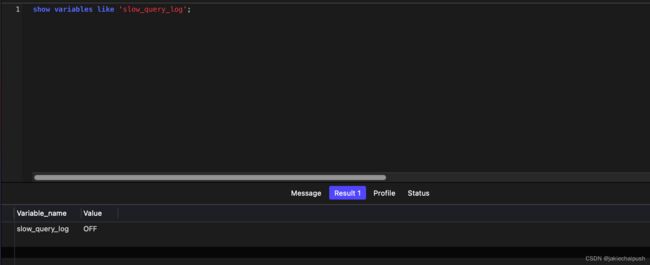
慢查询日志记录了所有执行时间超过指定参数(long_query_time,单位:秒,默认10s)的所有SQL的日志。Mysql的慢查询日志默认没有开启,需要在Mysql的配置文件(/etc/my.cnf)中配置如下信息:
-- 查看慢查询日志的开启情况
show variables like 'slow_query_log';
开启慢查询日志只需要在配置文件中加入以下命令:
#开启慢查询日志开关
slow_query_log=1;
#设置慢日志的时间为1s,sql执行时间超过两秒,就会被视为慢查询,记录慢查询日志
long_query_time=2
配置完成后重启msql服务器
- profie详情
show profile能够在SQL优化时帮助我们了解时间都耗费到哪里去了,通过have_profiling参数,能够看到当前mysql是否支持profile操作
查看是否支持profile操作:
select @@have_profiling;
默认profiling是关闭的,可以通过set语句在session/global级别开启profiling
set profiling=1;
查看指定query_id的sql语句各个阶段的耗时情况
show profile for query query_id;
查看指定query_id的sql语句的cpu的使用情况
show profile cpu for query query_id;
- explain执行计划
EXPLAIN或者DESC命令获取Mysql如何执行Select语句的信息,包括在Select语句执行过程中表如何连接和连接的顺序
#直接在select语句之前加上关键字explain/desc
Explain select 字段列表 From 表名 where 条件;
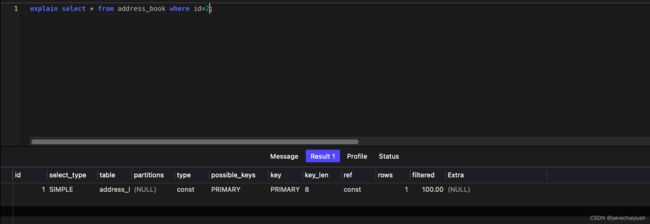
- id:select查询的序列号,表示查询中执行select子句或者是操作表的顺序(id相同,执行顺序从上到下;id不同,值越大,越先执行)
6. 索引使用
- 最左前缀法则
如果索引了多列(联合索引),要遵守最左前缀法则,最左前缀法则指的是查询从索引的最左列开始,并且不跳过索引中的列,如果跳跃某一列,索引将部分失效(后面的字段索引失效)
-- 创建表
-- 创建用户表
CREATE TABLE 用户表 (
用户ID INT PRIMARY KEY,
姓名 VARCHAR(50),
年龄 INT,
性别 VARCHAR(10),
电子邮件 VARCHAR(100),
手机号 VARCHAR(20),
地址 VARCHAR(200),
城市 VARCHAR(50),
省份 VARCHAR(50),
国家 VARCHAR(50),
注册日期 DATE,
最后登录日期 DATE,
用户类型 VARCHAR(20)
);
-- 插入17条随机数据
INSERT INTO 用户表 (用户ID, 姓名, 年龄, 性别, 电子邮件, 手机号, 地址, 城市, 省份, 国家, 注册日期, 最后登录日期, 用户类型)
VALUES
(1, '张三', 25, '男', '[email protected]', '1234567890', '北京市朝阳区', '北京', '北京', '中国', '2021-01-01', '2023-08-15', '普通用户'),
(2, '李四', 30, '女', '[email protected]', '9876543210', '上海市浦东新区', '上海', '上海', '中国', '2021-02-15', '2023-08-20', '高级用户'),
(3, '王五', 22, '男', '[email protected]', '1357924680', '广州市天河区', '广州', '广东', '中国', '2021-03-20', '2023-08-25', '普通用户'),
(4, '赵六', 28, '女', '[email protected]', '2468135790', '深圳市南山区', '深圳', '广东', '中国', '2021-04-10', '2023-08-30', '高级用户'),
(5, '陈七', 29, '男', '[email protected]', '1122334455', '成都市武侯区', '成都', '四川', '中国', '2021-05-05', '2023-09-01', '普通用户'),
(6, '刘八', 31, '女', '[email protected]', '9988776655', '杭州市西湖区', '杭州', '浙江', '中国', '2021-06-15', '2023-09-05', '高级用户'),
(7, '黄九', 26, '男', '[email protected]', '5566778899', '南京市玄武区', '南京', '江苏', '中国', '2021-07-20', '2023-09-10', '普通用户'),
(8, '徐十', 27, '女', '[email protected]', '7788990011', '武汉市江汉区', '武汉', '湖北', '中国', '2021-08-10', '2023-09-15', '高级用户'),
(9, '孙十一', 24, '男', '[email protected]', '0011223344', '重庆市渝中区', '重庆', '重庆', '中国', '2021-09-05', '2023-09-20', '普通用户'),
(10, '杨十二', 32, '女', '[email protected]', '3344556677', '天津市和平区', '天津', '天津', '中国', '2021-10-15', '2023-09-25', '高级用户'),
(11, '周十三', 23, '男', '[email protected]', '1122334455', '青岛市市南区', '青岛', '山东', '中国', '2021-11-20', '2023-09-30', '普通用户'),
(12, '吴十四', 33, '女', '[email protected]', '9988776655', '苏州市姑苏区', '苏州', '江苏', '中国', '2021-12-01', '2023-10-05', '高级用户'),
(13, '郑十五', 27, '男', '[email protected]', '5566778899', '西安市雁塔区', '西安', '陕西', '中国', '2022-01-10', '2023-10-10', '普通用户'),
(14, '马十六', 29, '女', '[email protected]', '7788990011', '成都市锦江区', '成都', '四川', '中国', '2022-02-15', '2023-10-15', '高级用户'),
(15, '朱十七', 26, '男', '[email protected]', '0011223344', '南京市鼓楼区', '南京', '江苏', '中国', '2022-03-20', '2023-10-20', '普通用户'),
(16, '刘十八', 28, '女', '[email protected]', '3344556677', '武汉市洪山区', '武汉', '湖北', '中国', '2022-04-05', '2023-10-25', '高级用户'),
(17, '李十九', 25, '男', '[email protected]', '1122334455', '重庆市江北区', '重庆', '重庆', '中国', '2022-05-10', '2023-10-30', '普通用户')
创建索引
CREATE Index idx_uer_na_age_ema On 用户表 (姓名,年龄,电子邮件)
查看索引
show index from 用户表

查询一条sql数据
select * from 用户表 where 姓名='张三' and 年龄=25 and 电子邮件='[email protected]'
查看执行计划
-- 没有跳过任何一个索引列,符合最左前缀法则
explain select * from 用户表 where 姓名='张三' and 年龄=25 and 电子邮件='[email protected]'

-- 跳过了第一个索引列,根据最左前缀法则,后面索引列全部失效
explain select * from 用户表 where 年龄=25 and 电子邮件='[email protected]'

- 范围查询
联合索引中,出现范围查询(>,<),范围查询右侧的列索引失效
-- >右侧的索引会失效,而>=不会让右侧的索引失效
explain select * from 用户表 where 姓名='张三' and 年龄>24 and 电子邮件='[email protected]'

- 索引列运算操作
不要在索引列上进行运算操作,否则索引将失效
创建一个单列索引
create index idx_phone on 用户表 (手机号)
根据电话号码查询
explain select * from 用户表 where 手机号='1234567890'

我们在查询中加入运算操作
explain select * from 用户表 where substring(手机号,9,2)='90'

- 字符串不加引号
字符串类型的字段使用时,不加引号,索引将失效
explain select * from 用户表 where 手机号=123456

- 模糊查询
如果仅仅是尾部模糊匹配,索引不会失效,如果是头部模糊匹配索引将失效
explain select * from 用户表 where 手机号 like '1234*'

explain select * from 用户表 where 手机号='*567890'

- or连接条件
用or分割开的条件,如果or前的条件中的列有索引,而后面的列中没有索引,那么涉及的索引将会失效
-- 手机号有索引,地址没有。索引失效
explain select * from 用户表 where 手机号='1234567890' or 地址='北京市朝阳区'

- 数据分布影响
如果Mysql评估使用索引比全表扫描更慢,则不使用索引
explain select * from 用户表 where 手机号 >'1234567890'

- SQL提示
是优化数据库的一个重要手段,简单来说,就是在SQL语句中加入一些人为的提示来达到优化的目的
--姓名字段前面创建了聚集索引,所以这里会使用索引进行查询
explain select * from 用户表 where 姓名 = '张三'

再给姓名字段创建一个单列索引
CREATE index idx_name on 用户表(姓名)
再次执行上面查询,判断会使用两个索引中的哪一个

使用sql提示
use index(使用某个索引-只是建议)
explain select * from 用户表 use index (idx_name) where 姓名 = '张三'
ignore index(不用哪个索引)
explain select * from 用户表 ignore index (idx_name) where 姓名 = '张三'
force index(必须使用哪个索引)
explain select * from 用户表 force index (idx_name) where 姓名 = '张三'

- 覆盖索引
尽量使用覆盖索引(查询使用了索引,并且需要返回的列,在改索引中已经全部都能找到),减少select *。
explain select * from 用户表 where 姓名='张三' and 年龄=25 and 电子邮件='[email protected]';

explain select 姓名,年龄,电子邮件 from 用户表 where 姓名='张三' and 年龄=25 and 电子邮件='[email protected]';

对比
extra信息,发现两个查询的分析不同,前者为null表示使用了索引,但是需要回表查询数据,using index查找了索引,但是需要的数据已经在索引列中找到了,所以不需要回表查询数据
- 前缀索引
当字段类型为字符串(varchar,text等)时,有时候需要索引很长的字符串,这会让索引变得很大,查询时,浪费大量的磁盘I/O,影响查询效率,此时只将字符串的一部分前缀,建立索引,这样可以大大节约索引空间,从而提高索引效率。
--提取column字段的前n个字符作为前缀索引
create index idx_xxxx on table_name(column(n));
前缀长度的选取可以根据索引的选择性来决定,而选择性是指不重复的索引值(基数)和数据表的记录总数的比值,索引的选择性越高则查询效率就越高,唯一的索引的选择性为1,这是最好的索引选择性,性能也是最好的,下面给个案例如何判断选择性:
--获取总条数
select count(电子邮件) from 用户表

--获取不重复数
select count(distinct 电子邮件) from 用户表

所以电子邮件的选择性为17/17=1
- 单列索引和联合索引的选择性问题
在业务场景中,如果存在多个查询条件,考虑针对于查询字段建立索引时,建议建立联合索引,而非单列索引
7.索引设计原则
- 针对数据量较大(超过100多万条以上),且查询比较频繁的表建立索引
- 针对于常作为查询条件(where)、排序(Order by)、分组(Group By)操作的字段建立索引
- 尽量使用区分度高的列建立索引,尽量建立唯一索引,区分度越高,使用索引效率越高
- 如果时字符串类型的字段,字段的长度很长,可以针对于字段的特点建立前缀索引
- 尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率
- 要控制索引的数量,索引并不是越多越好,索引越多,维护索引结构的代价也是越大,会影响增删改的效率
- 如果索引列不能为NULL,请在创建表的使用使用NOT NULL约束它。当优化器知道没列是否含有NULL值时,它可以更好地确定哪个索引有效地用于查询