OpenMP共享内存多核并行计算
一、参考资料
openMP_demo
OpenMP入门
OpenMP 教程(一) 深入剖析 OpenMP reduction 子句
二、OpenMP相关介绍
1. OpenMP简介
OpenMP(Open Multi-Processing)是一种用于共享内存并行系统的多线程程序涉及方案,支持C/C++。OpenMP提供了对并行算法的高层抽象描述,能够在多个处理器核心中实现并行计算,提高程序的执行效率。编译器根据程序中添加的pragma指令,自动将程序并行处理,使用OpenMP降低了并行编程的难度和复杂度。当编译器不支持OpenMP时,程序会退化成普通(串行)程序,程序中已有的OpenMP指令不会影响程序的正常编译运行。
很多主流的编译环境都内置了OpenMP,在VisualStudio中,启动OpenMP很简单。在项目上右键->属性->配置属性->C/C+±>语言->OpenMP支持,选择“是”即可。
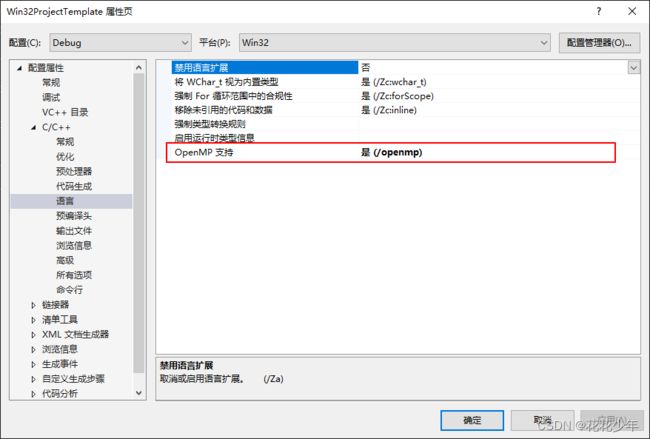
2. 共享内存模型
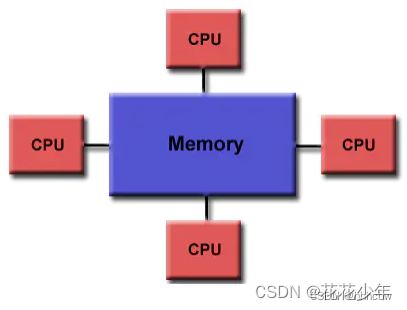
OpenMP是为多处理器和多核共享内存机器设计的。处理单元(CPU核心)的数量,决定了OpenMP的并行性。
3. 混合并行模型
OpenMP适用于单节点并行,MPI与OpenMP相结合实现分布式内存并行,这通常被称为混合并行模型。
- OpenMP用于每个节点(一台计算机)上的计算密集型工作;
- MPI用于实现节点之间的通信和数据共享。

4. Fork-Join模型
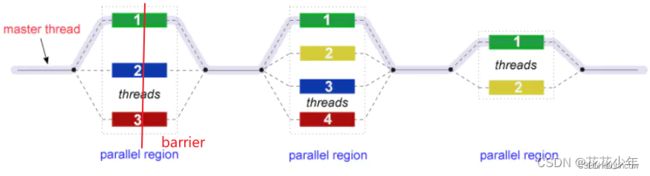
OpenMP使用并行执行的 Fork-Join 模型。
- Fork:主线程创建一组并行线程;
- Join:团队线程在并行区域分别进行计算,它们将进行同步与终止,只留下主线程。

上图中,parallel region 是并行域,在并行域内多线程并发,在并行域之间由主线程(master)线性执行。
5. barrier同步机制
barrier 用于并行域内代码的线程同步,线程执行到 barrier 时要停下等待,直到所有线程都执行到 barrier 时,才继续往下执行,从而实现线程的同步。
#include yoyo@yoyo:~/PATH/TO$ gcc -fopenmp demo.c -o demo
yoyo@yoyo:~/PATH/TO$ ./demo
Hello World from thread 10
Hello World from thread 3
Hello World from thread 2
Hello World from thread 6
Hello World from thread 4
Hello World from thread 7
Hello World from thread 0
Hello World from thread 5
Hello World from thread 11
Hello World from thread 8
Hello World from thread 1
Hello World from thread 9
There are 12 threads
三、常用操作
1. 常用指令
# 安装OpenMP
sudo apt-get install libomp-dev
# 使用gcc编译OpenMP程序
gcc -fopenmp demo.c -o demo
# 使用g++编译OpenMP程序
g++ -fopenmp demo.cpp -o demo
2. 重要操作
(1)并行区域:使用#pragma omp parallel指令来定义并行区域。
(2)线程编号:使用omp_get_thread_num()函数获取当前线程的编号。
(3)线程总数:使用omp_get_num_threads()函数获取总的线程数。
(4)数据共享:可以使用private和shared等关键字来声明变量的共享状态。
(5)同步机制:可以使用#pragma omp barrier指令来实现线程的同步。
3. 查看是否支持OpenMP
#include yoyo@yoyo:~/PATH/TO$ gcc -fopenmp demo.c -o demo
yoyo@yoyo:~/PATH/TO$ ./demo-1
support openmp
4. Hello World
#include yoyo@yoyo:~/PATH/TO$ gcc -fopenmp demo.c -o demo
yoyo@yoyo:~/PATH/TO$ ./demo
Hello, world.
Hello, world.
Hello, world.
Hello, world.
Hello, world.
Hello, world.
Hello, world.
Hello, world.
Hello, world.
Hello, world.
Hello, world.
Hello, world.
由于没有指定线程数,默认数量为CPU核心数。
#include 5. #pragma omp parallel for
omp_get_thread_num:获取当前线程id;
#include yoyo@yoyo:~/PATH/TO$ gcc -fopenmp demo.c -o demo
yoyo@yoyo:~/PATH/TO$ ./demo
OpenMP Test, th_id: 8
OpenMP Test, th_id: 3
OpenMP Test, th_id: 1
OpenMP Test, th_id: 9
OpenMP Test, th_id: 5
OpenMP Test, th_id: 0
OpenMP Test, th_id: 6
OpenMP Test, th_id: 11
OpenMP Test, th_id: 2
OpenMP Test, th_id: 7
OpenMP Test, th_id: 4
OpenMP Test, th_id: 10
6. reduction规约操作
6.1 引言
#include yoyo@yoyo:~/PATH/TO$ gcc -fopenmp demo.c -o demo
yoyo@yoyo:~/PATH/TO$ ./demo
1173yoyo@yoyo:~/PATH/TO$ ./demo
2521yoyo@yoyo:~/PATH/TO$ ./demo
3529yoyo@yoyo:~/PATH/TO$ ./demo
2174yoyo@yoyo:~/PATH/TO$ ./demo
1332yoyo@yoyo:~/PATH/TO$ ./demo
1673yoyo@yoyo:~/PATH/TO$ ./demo
1183yoyo@yoyo:~/PATH/TO$
执行多次,每次结果都不一样,原因是线程对同一个资源产生了竞争。对于 sum += i; 这一行,可以改写为 sum = sum + i,多线程并行对 sum 同时写,产生冲突。为了解决这个问题,可以使用 reduction。
6.2 reduction简介
reduction(操作符:变量)
先以 sum 求和函数为例:
#include yoyo@yoyo:~/PATH/TO$ gcc -fopenmp demo.c -o demo
yoyo@yoyo:~/PATH/TO$ ./demo
5050yoyo@yoyo:~/PATH/TO$ ./demo
5050yoyo@yoyo:~/PATH/TO$ ./demo
5050yoyo@yoyo:~/PATH/TO$ ./demo
5050yoyo@yoyo:~/PATH/TO$ ./demo
5050yoyo@yoyo:~/PATH/TO$ ./demo
5050yoyo@yoyo:~/PATH/TO$
上述代码中,reduction(+:sum) 表示在每个线程对变量sum进行拷贝,然后在线程中使用这个拷贝的变量,这样就不存在数据竞争的问题,因为对于每个线程,使用的 sum 数据都不一样。在 reduction 中还有一个加号 + ,这个加号表示如何进行规约操作。所谓规约操作,简单来说就是多个数据逐步进行操作,最终得到一个不能够在进行规约的数据。
例如,在上面的程序中,规约操作为 +,因此需要将线程1和线程2的数据进行 + 操作,即线程1的sum值加上线程2的sum值,然后将得到的结果赋值给全局变量sum,其他线程以此类推,最终得到的全局变量sum即为正确结果。
如果有4个线程,那么就有4个线程本地的 sum,每个线程拷贝一份 sum。那么规约(reduction)操作的结果等于:
( ( ( s u m 1 + s u m 2 ) + s u m 3 ) + s u m 4 ) (((sum_1 + sum2) + sum_3) + sum_4) (((sum1+sum2)+sum3)+sum4)
其中,sum_i 表示第i个线程得到的sum。