hive中内部表、外部表、分区表、桶表、拉链表
hive查询的基本原理
- hive的设计思想是通过元数据解析描述将HDFS上的文件映射成表
- 基本的查询原理是当用户通过hql语句对hive中的表进行复杂数据处理和计算时候,默认将其准换为分布式计算mapReduce程序对hdfs中的数据进行读取处理的过程
hive是有多种表类型的,分四种,内部表、外部表、分区表、桶表
一、内部表
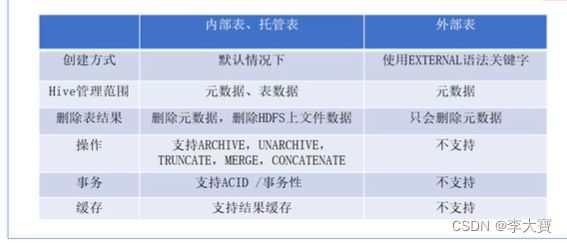
- 内部表也被称为hive拥有和管理的托管表
- 默认情况下创建的表,hive拥有该表的结构和文件
- 当删除内部表的时候,它会删除数据及表的元数据

二、外部表
- 外部表中的数据不是hive拥有或管理的,只是管理表元素的生命周期
- 要创建一个外部表,需要使用External语法关键字
- 删除外部表只会删除元数据,而不会删除实际数据,在hive外部依旧可以访问实际数据
- 实际场景下,外部表搭配location语法指定数据的路径,可以让数据更加安全
-
建立外部表,不使用LOCATION,会在默认在/hive/warehouse/数据库名称/表名,建立目录否用LOCATION方式建表,会影响在HDFS是否生成新目录(表名)。但是不影响外部表和内部表的功能。
2.1创建外部表命令

create external table external_table( key string ) location '/data/external'

2.2 导入数据使用load命令
load data local inpath '/data/soft/hivedata/external_table.data' into table external_table;

此时表目录存在/data/external,而表数据存在 /data/external/external_table.data
![]()
当删除表时候, drop table external_table;表数据依旧存在
2.3 外部表和内部表之间的转换
- 内部表转外部表: alter table t1 set tblproperties('EXTERNAL'='true');
- 外部表转内部表: alter table external_table set tblproperties('EXTERNAL'='false');

修改后: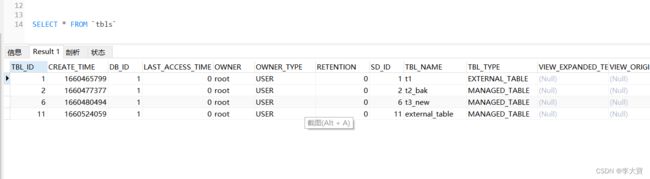
备注:EXTERNAL必须大写,小写不生效:
2.4 外部表和内部表之间的差异
三、分区表
分区可以理解为分类,通过分区把不同类型的数据放到不同目录。分区表的意义在于优化查询,查询时尽量利用分区字段,如果不使用分区字段,就会全表扫描,最典型的一个场景是把天作为分区字段,查询的时候指定天
hdfs会自动在表的目录下 ,为每个分区创建一个分区目录
3.1 创建一个分区
3.1.1 创建表的命令:
create table partition_1(
id int ,
name string
) partitioned by (dt string)
row format delimited
fields terminated by '\t'3.1.2 添加表分区数据
load data local inpath '/data/soft/hivedata/partition_1.data'
into table partition_1 partition(dt='2022-01-01');![]()
3.1.3 手动添加分区:
alter table partition_1 add partition(dt ='2022-01-02');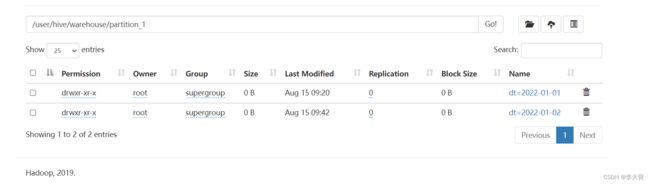
3.2 创建多个分区
3.2.1 创建表语句:
create table partition_2(
id int ,
name string
)partitioned by (year int ,school string)
row format delimited
fields terminated by '\t'
3.2.2 添加表分区数据
其中数据文件只要有id和name这两个字段就可以,具体year和school两个区分字段在加载分区的时候指定的
load data local inpath '/data/soft/hivedata/partition_2.data' into table partition_2 partition (year='20220101',school='li');
3.2.3 如果数据已经上传了,把表绑定数据
alter table ex_par add partition(year=20220103,school='bao')
location '/data/soft/hivedata/partition_2.data';![]()
3.3 动态分区
分区的值根据后续的查询结果,动态的确定,根据查询结果的值自动分区

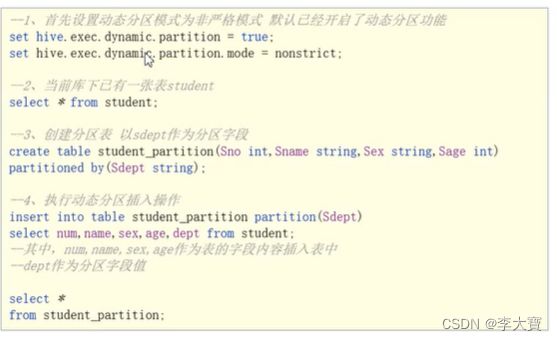
3.3.1 报错
![]()
语法问题:Column repeated in partitioning columns 这里的意思是 一个字段不能既做普通列又不能做分区字段,语法错误
异常时候sql为:

修改后sql为:

四、桶表
桶表是对数据进行哈希取值,然后放到不同文件中存储,物理上,每个桶就是表(或分区)里的一个文件
分区表示把数据划分到不同目录进行存储,分桶表把数据划分到不同文件下进行存储
创建桶:
create table bucket_tb(id int) clustered by (id) into 4 buckets;创建表并导入数据
create table b_source(id int);
load data local inpath '/data/soft/hivedata/b_source.data' into table b_source ;往桶里导入数据
insert into table bucket_tb select id from b_source where id is not null; 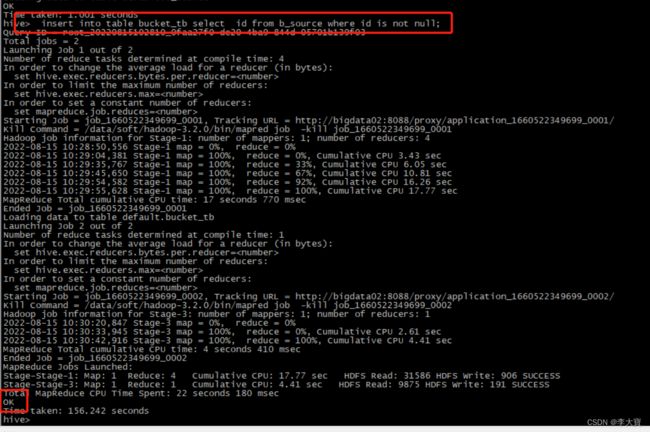
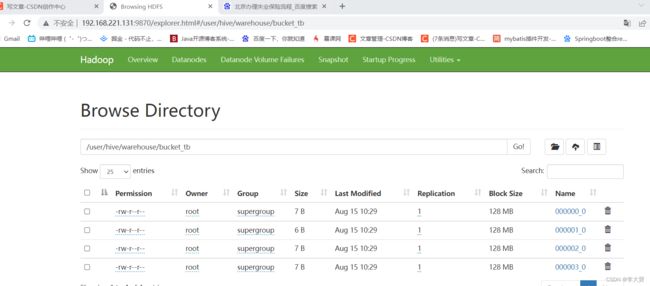
五、拉链表
拉链表专门为了解决在数据仓库中数据变化如何实现数据存储问题,顾名思义,所谓 拉链,就是记录历史。记录 一个事物从开始,一直到当前状态的所有历史变化的信息。
实现步骤:1、采集增量数据到增量表中
2、将增量表和历史拉链表数据合并,结果写到临时表中
3、将临时表数据覆盖到拉链表中
