Hive_UDF开发指南
最近在看 《Hive 编程指南》 其中提到了对Hive 自定义函数的几种扩展,
对于我们日常开发,这个功能还是非常有用的。
打算细致的研究一下,这里我们将研究结果整理成博客,方便大家理解 :
参考文章:
- Hive UDF教程(一)https://blog.csdn.net/u010376788/article/details/50532166
- Hive开发UDFhttps://blog.csdn.net/qq_33792843/article/details/74945718#commentBox
- hive UDF 测试样例开发 https://blog.csdn.net/zwjzqqb/article/details/79042636
- Hive- UDF&GenericUDF https://www.jianshu.com/p/ca9dce6b5c37
- [一起学Hive]之十八-Hive UDF开 https://www.cnblogs.com/1130136248wlxk/articles/5519276.html
- Hive+GenericUDF示例二 https://blog.csdn.net/wisgood/article/details/26169383
- Hive+GenericUDF示例一 https://blog.csdn.net/wisgood/article/details/26169313
- 将Hive统计分析结果导入到MySQL数据库表中(三)——使用Hive UDF或GenericUDF http://www.bubuko.com/infodetail-763295.html
本篇主要讲解 UDF , 对于 UDAF (用户自定义聚合函数) , UDTF ( 用户自定义表生成函数 )
对于 这两个请参考问的其他博文
UDAF (用户自定义聚合函数)
UDTF (用户自定义表生成函数)
本文大纲
1. UDF 实现的两种策略
2. UDF 中的注解
3. 简单的 UDF 实现
4. 更为复杂的 GenericUDF 实现
5. 打包,加入到集群中,进行测试。
1. UDF 实现的两种策略
Hive 的 UDF 主要分为2种类型的接口 UDF, GenericUDF
1) UDF 为一种比较简单的类,继承的基类为 org.apache.hadoop.hive.ql.exec.UDF;
2) GenericUDF 相对复杂一些,主要针对于类型检查等具有更好的控制,
继承的基类为 org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
2. UDF 中的注解
在对这接口进行讲解之前,我们先对基本的注解进行一下讲解。注解非常有利于我们程序的开发。
对于UDF 注解主要使用 @Description 注解
@Description 注解
主要的3个属性: name , value , extended
主要的宏 :_FUNC_
---------------------------------------------------------------------------------------
还有一些其他的注解
public @interface UDFType {
boolean deterministic() default true;
boolean stateful() default false;
boolean distinctLike() default false;
}
=============================
下面先对 @Description 注解 进行详细的讲解。
@Description 是可选的。该注解主要注明了关于函数的文档说明。
主要的3个属性: name , value , extended
name : 表明了该函数的名称。
value : 描述了该函数在 DESCRIBE FUNCTION ... 时 显示的提示。
extended : 主要用来编写示例,如 函数使用示例,DESCRIBE FUNCTION EXTENDED 显示的提示。
主要的宏 :_FUNC_
_FUN_ 会被替换为 这个函数定义的“临时”函数名称
下面是一些DESCRIBE FUNCTION / DESCRIBE FUNCTION EXTENDED 的例子:


下面是一个 @Description 注解使用的示例:
/**
* Created by szh on 2018/7/16.
*
* @author szh
* @date 2018/7/16
*/
@Description(
name = "zodiac",
value = "_FUNC_ (date) - " +
" from the input date string " +
" or separate month and day arguments, \n" +
" returns the sign of the Zodiac.",
extended = "Example :\n" +
"> SELECT _FUNC_ (date_string) FROM src;\n" +
"> SELECT _FUNC_ (month, day) FROM src;")
public class HiveTestZodiacUDF extends UDF {===============================
public @interface UDFType {
boolean deterministic() default true;
boolean stateful() default false;
boolean distinctLike() default false;
}
deterministic 定数性标注:
大多数函数都是定数性的,rand() 函数是个例外。如果rand() 是定数性的,那么结果只会在计算阶段计算一次。
如果一个UDF 是非定数性的,那么就不会包含在分区裁剪中。
因为包含rand() 是非定数性的,因此对于每一行数据,rand() 的值都会重新计算一次。
stateful 状态性标注:
几乎所有的UDF 默认都是有状态性的,rand() 函数是无状态性的,每次调用都会返回不同的值。
stateful 适用以下场景:
1) 有状态性的UDF 只能使用在SELECT 语句后面, 而不能使用到其他如 WHERE, ON, ORDER, GROUP 语句后面。
2)当一个查询语句中存在有状态性的UDF时,其隐含信息是,SELECT 将会和 TRANSFORM (例如,DISTRIBUTE,
CLUSTER, SORT 语句 ) 进行类似的处理,然会会在对应的Reducer 内部进行执行,以保证结果是预期的结果。
3)如果状态性标记 statefule 设置为 true, 那么这个UDF 同样作为非定数性的。
( 即使此时定数性标记 deterministic 的值是显式设置为 true 的 )。
distinctLike 唯一性标注:
有些函数,即使其输入的列的值是非排重值,其结果也是类似于使用了DISTINCT 进行了排重操作,这类场景可以定义为
具有唯一性。
例子有min, max ,即使实际数据中有重复值,其最终结果也是唯一排重值。
最新版本的 UDFType
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by Fernflower decompiler)
//
package org.apache.hadoop.hive.ql.udf;
import java.lang.annotation.ElementType;
import java.lang.annotation.Inherited;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
import org.apache.hadoop.hive.common.classification.InterfaceAudience.Public;
import org.apache.hadoop.hive.common.classification.InterfaceStability.Evolving;
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
@Public
@Evolving
public @interface UDFType {
boolean deterministic() default true;
boolean stateful() default false;
boolean distinctLike() default false;
boolean impliesOrder() default false;
}
对于 impliesOrder 属性的作用,目前我不是特别的明确,欢迎清楚的朋友在评论区补充。
3. 简单的 UDF 实现
UDF 主要需要实现evaluate() 函数。
并主要通过方法重载的方式实现对多种数据的支持。
需要注意的是:
在查询执行过程中,查询中对应的每个应用到该函数的地方都会对这个类进行实例化。
示例如下:
UDF 功能描述,该UDF 主要用于判断某一个日期属于哪一个星座。
package com.test.hive.udf;
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.hive.ql.udf.UDFType;
import org.joda.time.DateTime;
import java.util.Date;
/**
* Created by szh on 2018/7/16.
*
* @author szh
* @date 2018/7/16
*/
@UDFType
@Description(
name = "zodiac",
value = "_FUNC_ (date) - " +
" from the input date string " +
" or separate month and day arguments, \n" +
" returns the sign of the Zodiac.",
extended = "Example :\n" +
"> SELECT _FUNC_ (date_string) FROM src;\n" +
"> SELECT _FUNC_ (month, day) FROM src;")
public class HiveTestZodiacUDF extends UDF {
private static final String ERROR_DATE_OF_MONTH = "invalid date of specify month";
private static final String ERROR_MONTH_ARGS = "invalid argument of month";
private static final String ERROR_DATE_STRING = "invalid date format";
public String evaluate(Date bday) {
return this.evaluate(bday.getMonth(), bday.getDay());
}
public String evaluate(String dateString) {
DateTime dateTime = null;
try {
dateTime = new DateTime(dateString);
} catch (Exception e) {
return ERROR_DATE_STRING;
}
return this.evaluate(dateTime.getMonthOfYear(), dateTime.getDayOfMonth());
}
public String evaluate(Integer month, Integer day) {
switch (month) {
//判断是几月
case 1:
//判断是当前月的哪一段时间;然后就可以得到星座了;下面代码都一样的
if (day > 0 && day < 20) {
return "魔蝎座";
} else if (day < 32) {
return "水瓶座";
} else {
return ERROR_DATE_OF_MONTH;
}
case 2:
if (day > 0 && day < 19) {
return "水瓶座";
} else if (day < 29) {
return "双鱼座";
} else {
return ERROR_DATE_OF_MONTH;
}
case 3:
if (day > 0 && day < 21) {
return "双鱼座";
} else if (day < 32) {
return "白羊座";
} else {
return ERROR_DATE_OF_MONTH;
}
case 4:
if (day > 0 && day < 20) {
return "白羊座";
} else if (day < 31) {
return "金牛座";
} else {
return ERROR_DATE_OF_MONTH;
}
case 5:
if (day > 0 && day < 21) {
return "金牛座";
} else if (day < 32) {
return "双子座";
} else {
return ERROR_DATE_OF_MONTH;
}
case 6:
if (day > 0 && day < 22) {
return "双子座";
} else if (day < 31) {
return "巨蟹座";
} else {
return ERROR_DATE_OF_MONTH;
}
case 7:
if (day > 0 && day < 23) {
return "巨蟹座";
} else if (day < 32) {
return "狮子座";
} else {
return ERROR_DATE_OF_MONTH;
}
case 8:
if (day > 0 && day < 23) {
return "狮子座";
} else if (day < 32) {
return "处女座";
} else {
return ERROR_DATE_OF_MONTH;
}
case 9:
if (day > 0 && day < 23) {
return "处女座";
} else if (day < 31) {
return "天平座";
} else {
return ERROR_DATE_OF_MONTH;
}
case 10:
if (day > 0 && day < 24) {
return "天平座";
} else if (day < 32) {
return "天蝎座";
} else {
return ERROR_DATE_OF_MONTH;
}
case 11:
if (day > 0 && day < 23) {
return "天蝎座";
} else if (day < 31) {
return "射手座";
} else {
return ERROR_DATE_OF_MONTH;
}
case 12:
if (day > 0 && day < 22) {
return "射手座";
} else if (day < 32) {
return "摩羯座";
} else {
return ERROR_DATE_OF_MONTH;
}
default:
return ERROR_MONTH_ARGS;
}
}
}
4. 更为复杂的 GenericUDF 实现
GenericUDF 是一个更为复杂的类,其主要对代码整理构建,使用了模板模式,规范了各个步奏应该完成的流程。
我们先来看下 GenricUDF 的源码:
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by Fernflower decompiler)
//
package org.apache.hadoop.hive.ql.udf.generic;
import java.io.Closeable;
import java.io.IOException;
import java.sql.Timestamp;
import java.text.ParseException;
import java.util.Date;
import org.apache.hadoop.hive.ql.exec.FunctionRegistry;
import org.apache.hadoop.hive.ql.exec.MapredContext;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.UDFType;
import org.apache.hadoop.hive.serde2.io.ByteWritable;
import org.apache.hadoop.hive.serde2.io.DateWritable;
import org.apache.hadoop.hive.serde2.io.DoubleWritable;
import org.apache.hadoop.hive.serde2.io.ShortWritable;
import org.apache.hadoop.hive.serde2.io.TimestampWritable;
import org.apache.hadoop.hive.serde2.objectinspector.ConstantObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorConverters;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorUtils;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector.Category;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorConverters.Converter;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector.PrimitiveCategory;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorUtils;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorUtils.PrimitiveGrouping;
import org.apache.hadoop.io.BooleanWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hive.common.util.DateUtils;
@UDFType(
deterministic = true
)
public abstract class GenericUDF implements Closeable {
private static final String[] ORDINAL_SUFFIXES = new String[]{"th", "st", "nd", "rd", "th", "th", "th", "th", "th", "th"};
public GenericUDF() {
}
public abstract ObjectInspector initialize(ObjectInspector[] var1) throws UDFArgumentException;
public void configure(MapredContext context) {
}
public ObjectInspector initializeAndFoldConstants(ObjectInspector[] arguments) throws UDFArgumentException {
ObjectInspector oi = this.initialize(arguments);
if(this.getRequiredFiles() == null && this.getRequiredJars() == null) {
boolean allConstant = true;
for(int ii = 0; ii < arguments.length; ++ii) {
if(!ObjectInspectorUtils.isConstantObjectInspector(arguments[ii])) {
allConstant = false;
break;
}
}
if(allConstant && !ObjectInspectorUtils.isConstantObjectInspector((ObjectInspector)oi) && FunctionRegistry.isDeterministic(this) && !FunctionRegistry.isStateful(this) && ObjectInspectorUtils.supportsConstantObjectInspector((ObjectInspector)oi)) {
GenericUDF.DeferredObject[] argumentValues = new GenericUDF.DeferredJavaObject[arguments.length];
for(int ii = 0; ii < arguments.length; ++ii) {
argumentValues[ii] = new GenericUDF.DeferredJavaObject(((ConstantObjectInspector)arguments[ii]).getWritableConstantValue());
}
try {
Object constantValue = this.evaluate(argumentValues);
oi = ObjectInspectorUtils.getConstantObjectInspector((ObjectInspector)oi, constantValue);
} catch (HiveException var6) {
throw new UDFArgumentException(var6);
}
}
return (ObjectInspector)oi;
} else {
return (ObjectInspector)oi;
}
}
public String[] getRequiredJars() {
return null;
}
public String[] getRequiredFiles() {
return null;
}
public abstract Object evaluate(GenericUDF.DeferredObject[] var1) throws HiveException;
public abstract String getDisplayString(String[] var1);
public void close() throws IOException {
}
public GenericUDF flip() {
return this;
}
public GenericUDF negative() {
throw new UnsupportedOperationException("Negative function doesn't exist for " + this.getFuncName());
}
public String getUdfName() {
return this.getClass().getName();
}
public void copyToNewInstance(Object newInstance) throws UDFArgumentException {
if(this.getClass() != newInstance.getClass()) {
throw new UDFArgumentException("Invalid copy between " + this.getClass().getName() + " and " + newInstance.getClass().getName());
}
}
protected String getStandardDisplayString(String name, String[] children) {
return this.getStandardDisplayString(name, children, ", ");
}
protected String getStandardDisplayString(String name, String[] children, String delim) {
StringBuilder sb = new StringBuilder();
sb.append(name);
sb.append("(");
if(children.length > 0) {
sb.append(children[0]);
for(int i = 1; i < children.length; ++i) {
sb.append(delim);
sb.append(children[i]);
}
}
sb.append(")");
return sb.toString();
}
protected String getFuncName() {
return this.getClass().getSimpleName().substring(10).toLowerCase();
}
protected void checkArgsSize(ObjectInspector[] arguments, int min, int max) throws UDFArgumentLengthException {
if(arguments.length < min || arguments.length > max) {
StringBuilder sb = new StringBuilder();
sb.append(this.getFuncName());
sb.append(" requires ");
if(min == max) {
sb.append(min);
} else {
sb.append(min).append("..").append(max);
}
sb.append(" argument(s), got ");
sb.append(arguments.length);
throw new UDFArgumentLengthException(sb.toString());
}
}
protected void checkArgPrimitive(ObjectInspector[] arguments, int i) throws UDFArgumentTypeException {
Category oiCat = arguments[i].getCategory();
if(oiCat != Category.PRIMITIVE) {
throw new UDFArgumentTypeException(i, this.getFuncName() + " only takes primitive types as " + this.getArgOrder(i) + " argument, got " + oiCat);
}
}
protected void checkArgGroups(ObjectInspector[] arguments, int i, PrimitiveCategory[] inputTypes, PrimitiveGrouping... grps) throws UDFArgumentTypeException {
PrimitiveCategory inputType = ((PrimitiveObjectInspector)arguments[i]).getPrimitiveCategory();
PrimitiveGrouping[] var6 = grps;
int j = grps.length;
for(int var8 = 0; var8 < j; ++var8) {
PrimitiveGrouping grp = var6[var8];
if(PrimitiveObjectInspectorUtils.getPrimitiveGrouping(inputType) == grp) {
inputTypes[i] = inputType;
return;
}
}
StringBuilder sb = new StringBuilder();
sb.append(this.getFuncName());
sb.append(" only takes ");
sb.append(grps[0]);
for(j = 1; j < grps.length; ++j) {
sb.append(", ");
sb.append(grps[j]);
}
sb.append(" types as ");
sb.append(this.getArgOrder(i));
sb.append(" argument, got ");
sb.append(inputType);
throw new UDFArgumentTypeException(i, sb.toString());
}
protected void obtainStringConverter(ObjectInspector[] arguments, int i, PrimitiveCategory[] inputTypes, Converter[] converters) throws UDFArgumentTypeException {
PrimitiveObjectInspector inOi = (PrimitiveObjectInspector)arguments[i];
PrimitiveCategory inputType = inOi.getPrimitiveCategory();
Converter converter = ObjectInspectorConverters.getConverter(arguments[i], PrimitiveObjectInspectorFactory.writableStringObjectInspector);
converters[i] = converter;
inputTypes[i] = inputType;
}
protected void obtainIntConverter(ObjectInspector[] arguments, int i, PrimitiveCategory[] inputTypes, Converter[] converters) throws UDFArgumentTypeException {
PrimitiveObjectInspector inOi = (PrimitiveObjectInspector)arguments[i];
PrimitiveCategory inputType = inOi.getPrimitiveCategory();
switch(null.$SwitchMap$org$apache$hadoop$hive$serde2$objectinspector$PrimitiveObjectInspector$PrimitiveCategory[inputType.ordinal()]) {
case 1:
case 2:
case 3:
case 4:
Converter converter = ObjectInspectorConverters.getConverter(arguments[i], PrimitiveObjectInspectorFactory.writableIntObjectInspector);
converters[i] = converter;
inputTypes[i] = inputType;
return;
default:
throw new UDFArgumentTypeException(i, this.getFuncName() + " only takes INT/SHORT/BYTE types as " + this.getArgOrder(i) + " argument, got " + inputType);
}
}
protected void obtainLongConverter(ObjectInspector[] arguments, int i, PrimitiveCategory[] inputTypes, Converter[] converters) throws UDFArgumentTypeException {
PrimitiveObjectInspector inOi = (PrimitiveObjectInspector)arguments[i];
PrimitiveCategory inputType = inOi.getPrimitiveCategory();
switch(null.$SwitchMap$org$apache$hadoop$hive$serde2$objectinspector$PrimitiveObjectInspector$PrimitiveCategory[inputType.ordinal()]) {
case 1:
case 2:
case 3:
case 5:
Converter converter = ObjectInspectorConverters.getConverter(arguments[i], PrimitiveObjectInspectorFactory.writableIntObjectInspector);
converters[i] = converter;
inputTypes[i] = inputType;
return;
case 4:
default:
throw new UDFArgumentTypeException(i, this.getFuncName() + " only takes LONG/INT/SHORT/BYTE types as " + this.getArgOrder(i) + " argument, got " + inputType);
}
}
protected void obtainDoubleConverter(ObjectInspector[] arguments, int i, PrimitiveCategory[] inputTypes, Converter[] converters) throws UDFArgumentTypeException {
PrimitiveObjectInspector inOi = (PrimitiveObjectInspector)arguments[i];
PrimitiveCategory inputType = inOi.getPrimitiveCategory();
Converter converter = ObjectInspectorConverters.getConverter(arguments[i], PrimitiveObjectInspectorFactory.writableDoubleObjectInspector);
converters[i] = converter;
inputTypes[i] = inputType;
}
protected void obtainDateConverter(ObjectInspector[] arguments, int i, PrimitiveCategory[] inputTypes, Converter[] converters) throws UDFArgumentTypeException {
PrimitiveObjectInspector inOi = (PrimitiveObjectInspector)arguments[i];
PrimitiveCategory inputType = inOi.getPrimitiveCategory();
Object outOi;
switch(null.$SwitchMap$org$apache$hadoop$hive$serde2$objectinspector$PrimitiveObjectInspector$PrimitiveCategory[inputType.ordinal()]) {
case 4:
case 9:
case 10:
outOi = PrimitiveObjectInspectorFactory.writableDateObjectInspector;
break;
case 5:
default:
throw new UDFArgumentTypeException(i, this.getFuncName() + " only takes STRING_GROUP or DATE_GROUP types as " + this.getArgOrder(i) + " argument, got " + inputType);
case 6:
case 7:
case 8:
outOi = PrimitiveObjectInspectorFactory.writableStringObjectInspector;
}
converters[i] = ObjectInspectorConverters.getConverter(inOi, (ObjectInspector)outOi);
inputTypes[i] = inputType;
}
protected void obtainTimestampConverter(ObjectInspector[] arguments, int i, PrimitiveCategory[] inputTypes, Converter[] converters) throws UDFArgumentTypeException {
PrimitiveObjectInspector inOi = (PrimitiveObjectInspector)arguments[i];
PrimitiveCategory inputType = inOi.getPrimitiveCategory();
switch(null.$SwitchMap$org$apache$hadoop$hive$serde2$objectinspector$PrimitiveObjectInspector$PrimitiveCategory[inputType.ordinal()]) {
case 6:
case 7:
case 8:
case 9:
case 10:
ObjectInspector outOi = PrimitiveObjectInspectorFactory.writableTimestampObjectInspector;
converters[i] = ObjectInspectorConverters.getConverter(inOi, outOi);
inputTypes[i] = inputType;
return;
default:
throw new UDFArgumentTypeException(i, this.getFuncName() + " only takes STRING_GROUP or DATE_GROUP types as " + this.getArgOrder(i) + " argument, got " + inputType);
}
}
protected String getStringValue(GenericUDF.DeferredObject[] arguments, int i, Converter[] converters) throws HiveException {
Object obj;
return (obj = arguments[i].get()) == null?null:converters[i].convert(obj).toString();
}
protected Integer getIntValue(GenericUDF.DeferredObject[] arguments, int i, Converter[] converters) throws HiveException {
Object obj;
if((obj = arguments[i].get()) == null) {
return null;
} else {
Object writableValue = converters[i].convert(obj);
int v = ((IntWritable)writableValue).get();
return Integer.valueOf(v);
}
}
protected Long getLongValue(GenericUDF.DeferredObject[] arguments, int i, Converter[] converters) throws HiveException {
Object obj;
if((obj = arguments[i].get()) == null) {
return null;
} else {
Object writableValue = converters[i].convert(obj);
long v = ((LongWritable)writableValue).get();
return Long.valueOf(v);
}
}
protected Double getDoubleValue(GenericUDF.DeferredObject[] arguments, int i, Converter[] converters) throws HiveException {
Object obj;
if((obj = arguments[i].get()) == null) {
return null;
} else {
Object writableValue = converters[i].convert(obj);
double v = ((DoubleWritable)writableValue).get();
return Double.valueOf(v);
}
}
protected Date getDateValue(GenericUDF.DeferredObject[] arguments, int i, PrimitiveCategory[] inputTypes, Converter[] converters) throws HiveException {
Object obj;
if((obj = arguments[i].get()) == null) {
return null;
} else {
Object date;
switch(null.$SwitchMap$org$apache$hadoop$hive$serde2$objectinspector$PrimitiveObjectInspector$PrimitiveCategory[inputTypes[i].ordinal()]) {
case 6:
case 7:
case 8:
String dateStr = converters[i].convert(obj).toString();
try {
date = DateUtils.getDateFormat().parse(dateStr);
break;
} catch (ParseException var9) {
return null;
}
case 9:
case 10:
Object writableValue = converters[i].convert(obj);
date = ((DateWritable)writableValue).get();
break;
default:
throw new UDFArgumentTypeException(0, this.getFuncName() + " only takes STRING_GROUP and DATE_GROUP types, got " + inputTypes[i]);
}
return (Date)date;
}
}
protected Timestamp getTimestampValue(GenericUDF.DeferredObject[] arguments, int i, Converter[] converters) throws HiveException {
Object obj;
if((obj = arguments[i].get()) == null) {
return null;
} else {
Object writableValue = converters[i].convert(obj);
if(writableValue == null) {
return null;
} else {
Timestamp ts = ((TimestampWritable)writableValue).getTimestamp();
return ts;
}
}
}
protected String getConstantStringValue(ObjectInspector[] arguments, int i) {
Object constValue = ((ConstantObjectInspector)arguments[i]).getWritableConstantValue();
String str = constValue == null?null:constValue.toString();
return str;
}
protected Boolean getConstantBooleanValue(ObjectInspector[] arguments, int i) throws UDFArgumentTypeException {
Object constValue = ((ConstantObjectInspector)arguments[i]).getWritableConstantValue();
if(constValue == null) {
return Boolean.valueOf(false);
} else if(constValue instanceof BooleanWritable) {
return Boolean.valueOf(((BooleanWritable)constValue).get());
} else {
throw new UDFArgumentTypeException(i, this.getFuncName() + " only takes BOOLEAN types as " + this.getArgOrder(i) + " argument, got " + constValue.getClass());
}
}
protected Integer getConstantIntValue(ObjectInspector[] arguments, int i) throws UDFArgumentTypeException {
Object constValue = ((ConstantObjectInspector)arguments[i]).getWritableConstantValue();
if(constValue == null) {
return null;
} else {
int v;
if(constValue instanceof IntWritable) {
v = ((IntWritable)constValue).get();
} else if(constValue instanceof ShortWritable) {
v = ((ShortWritable)constValue).get();
} else {
if(!(constValue instanceof ByteWritable)) {
throw new UDFArgumentTypeException(i, this.getFuncName() + " only takes INT/SHORT/BYTE types as " + this.getArgOrder(i) + " argument, got " + constValue.getClass());
}
v = ((ByteWritable)constValue).get();
}
return Integer.valueOf(v);
}
}
protected String getArgOrder(int i) {
++i;
switch(i % 100) {
case 11:
case 12:
case 13:
return i + "th";
default:
return i + ORDINAL_SUFFIXES[i % 10];
}
}
public static class DeferredJavaObject implements GenericUDF.DeferredObject {
private final Object value;
public DeferredJavaObject(Object value) {
this.value = value;
}
public void prepare(int version) throws HiveException {
}
public Object get() throws HiveException {
return this.value;
}
}
public interface DeferredObject {
void prepare(int var1) throws HiveException;
Object get() throws HiveException;
}
}可以看到对于GenericUDF 类,我们使用了 deterministic 定数性标注,
deterministic 定数性标注:
大多数函数都是定数性的,rand() 函数是个例外。如果rand() 是定数性的,那么结果只会在计算阶段计算一次。
如果一个UDF 是非定数性的,那么就不会包含在分区裁剪中。
因为包含rand() 是非定数性的,因此对于每一行数据,rand() 的值都会重新计算一次。
我们继承一下 GenricUDF 类,看需要实现那几个方法
/**
* Created by szh on 2018/7/17.
*
* @author szh
* @date 2018-07-17
*/
public class HiveTestGenericUDF extends GenericUDF {
@Override
public ObjectInspector initialize(ObjectInspector[] objectInspectors) throws UDFArgumentException {
return null;
}
@Override
public Object evaluate(DeferredObject[] deferredObjects) throws HiveException {
return null;
}
@Override
public String getDisplayString(String[] strings) {
return null;
}
}需要注意的几个方法:
public void configure(MapredContext context) { }
//可选,该方法中可以通过context.getJobConf()获取job执行时候的Configuration;
//可以通过Configuration传递参数值
public ObjectInspector initialize(ObjectInspector[] arguments) { }
//必选,该方法用于函数初始化操作,并定义函数的返回值类型;
//比如,在该方法中可以初始化对象实例,初始化数据库链接,初始化读取文件等;
public Object evaluate(DeferredObject[] args){ }
//必选,函数处理的核心方法,用途和UDF中的evaluate一样;
public String getDisplayString(String[] children) { }
//必选,显示函数的提示信息(当出现异常导致终止的时候)
public void close(){ }
//可选,map完成后,执行关闭操作
一些开发注意事项:
注意:在Hive-1.0.1估计之后的版本也是,evaluate()方法中从Object Inspectors取出的值,需要先保存为Lazy包中的数据类型(org.apache.hadoop.hive.serde2.lazy),然后才能转换成Java的数据类型进行处理。否则会报错,解决方案可以参考Hive报错集锦中的第5个。
该提议经实际测试并未发生,目前不知道具体的原因 ,请知道原因的小伙伴踊跃留言 !!!!
private GenericUDFUtils.ReturnObjectInspectorResolver returnObjectInspectorResolver;
returnObjectInspectorResolver 是一个内置的类,其通过获取非null 的值的变量并使用这个数据类型来确定返回值类型。
示例:
该函数功能与上面的UDF 函数功能一致。即计算某一个日期的星座。
package com.test.hive.udf;
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.UDFType;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDFUtils;
import org.apache.hadoop.hive.serde2.lazy.LazyDate;
import org.apache.hadoop.hive.serde2.lazy.LazyInteger;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.*;
import org.joda.time.DateTime;
import java.util.Date;
/**
* Created by szh on 2018/7/17.
*
* @author szh
* @date 2018-07-17
*/
@UDFType
@Description(
name = "zodiac",
value = "_FUNC_ (date) - " +
" from the input date string " +
" or separate month and day arguments, \n" +
" returns the sign of the Zodiac.",
extended = "Example :\n" +
"> SELECT _FUNC_ (date_string) FROM src;\n" +
"> SELECT _FUNC_ (month, day) FROM src;")
public class HiveTestZodiacGenericUDF extends GenericUDF {
private static final Integer ONE_ARG = 1;
private static final Integer TWO_ARG = 2;
private StringObjectInspector dateString = null;
private DateObjectInspector dateObject = null;
private IntObjectInspector monthInt = null;
private IntObjectInspector dayInt = null;
private static final String ERROR_DATE_OF_MONTH = "invalid date of specify month";
private static final String ERROR_MONTH_ARGS = "invalid argument of month";
private static final String ERROR_DATE_STRING = "invalid date format";
private GenericUDFUtils.ReturnObjectInspectorResolver returnObjectInspectorResolver;
@Override
//必选,该方法用于函数初始化操作,并定义函数的返回值类型;
//比如,在该方法中可以初始化对象实例,初始化数据库链接,初始化读取文件等;
public ObjectInspector initialize(ObjectInspector[] objectInspectors) throws UDFArgumentException {
Integer len = objectInspectors.length;
if (!len.equals(ONE_ARG) && !len.equals(TWO_ARG)) {
throw new UDFArgumentException("Not Invalid num of arguments");
}
if (len.equals(ONE_ARG)) {
ObjectInspector tmpDate = objectInspectors[0];
if (tmpDate instanceof DateObjectInspector) {
this.dateObject = (DateObjectInspector) tmpDate;
} else if (tmpDate instanceof StringObjectInspector) {
this.dateString = (StringObjectInspector) tmpDate;
} else {
throw new UDFArgumentException("Not Invalid type of date (string or date)");
}
}
if (len.equals(TWO_ARG)) {
ObjectInspector tmpMonthInt = objectInspectors[0];
ObjectInspector tmpDayInt = objectInspectors[1];
if (!(tmpDayInt instanceof IntObjectInspector) || !(tmpMonthInt instanceof IntObjectInspector)) {
throw new UDFArgumentException("Not Invalid type of month or day , please use int type");
}
this.monthInt = (IntObjectInspector) tmpMonthInt;
this.dayInt = (IntObjectInspector) tmpDayInt;
}
//确定返回值类型
return PrimitiveObjectInspectorFactory.javaStringObjectInspector;
}
@Override
public Object evaluate(DeferredObject[] deferredObjects) throws HiveException {
Integer length = deferredObjects.length;
Integer month = null;
Integer day = null;
if (length.equals(ONE_ARG)) {
if (this.dateObject != null) {
// LazyDate dateObjTmp = (LazyDate) ((deferredObjects[0].get()));
// Date date = (this.dateObject).getPrimitiveJavaObject(dateObjTmp);
Date date = (this.dateObject).getPrimitiveJavaObject(deferredObjects[0].get());
DateTime dateTime = new DateTime(date);
month = dateTime.getMonthOfYear();
day = dateTime.getDayOfMonth();
} else if (this.dateString != null) {
// LazyDate dateStringTmp = (LazyDate) (deferredObjects[0].get());
// String dateString = (this.dateString).getPrimitiveJavaObject(dateStringTmp);
String dateString = (this.dateString).getPrimitiveJavaObject(deferredObjects[0].get());
DateTime dateTime = new DateTime(dateString);
month = dateTime.getMonthOfYear();
day = dateTime.getDayOfMonth();
}
}
if (length.equals(TWO_ARG)) {
// LazyInteger monthIntTmp = (LazyInteger) (deferredObjects[0].get());
// LazyInteger dayIntTmp = (LazyInteger) ((deferredObjects[1].get()));
// month = (this.monthInt).get(monthIntTmp);
// day = (this.dayInt).get(dayIntTmp);
month = this.monthInt.get(deferredObjects[0].get());
day = this.dayInt.get(deferredObjects[1].get());
}
switch (month) {
//判断是几月
case 1:
//判断是当前月的哪一段时间;然后就可以得到星座了;下面代码都一样的
if (day > 0 && day < 20) {
return "魔蝎座";
} else if (day < 32) {
return "水瓶座";
} else {
return ERROR_DATE_OF_MONTH;
}
case 2:
if (day > 0 && day < 19) {
return "水瓶座";
} else if (day < 29) {
return "双鱼座";
} else {
return ERROR_DATE_OF_MONTH;
}
case 3:
if (day > 0 && day < 21) {
return "双鱼座";
} else if (day < 32) {
return "白羊座";
} else {
return ERROR_DATE_OF_MONTH;
}
case 4:
if (day > 0 && day < 20) {
return "白羊座";
} else if (day < 31) {
return "金牛座";
} else {
return ERROR_DATE_OF_MONTH;
}
case 5:
if (day > 0 && day < 21) {
return "金牛座";
} else if (day < 32) {
return "双子座";
} else {
return ERROR_DATE_OF_MONTH;
}
case 6:
if (day > 0 && day < 22) {
return "双子座";
} else if (day < 31) {
return "巨蟹座";
} else {
return ERROR_DATE_OF_MONTH;
}
case 7:
if (day > 0 && day < 23) {
return "巨蟹座";
} else if (day < 32) {
return "狮子座";
} else {
return ERROR_DATE_OF_MONTH;
}
case 8:
if (day > 0 && day < 23) {
return "狮子座";
} else if (day < 32) {
return "处女座";
} else {
return ERROR_DATE_OF_MONTH;
}
case 9:
if (day > 0 && day < 23) {
return "处女座";
} else if (day < 31) {
return "天平座";
} else {
return ERROR_DATE_OF_MONTH;
}
case 10:
if (day > 0 && day < 24) {
return "天平座";
} else if (day < 32) {
return "天蝎座";
} else {
return ERROR_DATE_OF_MONTH;
}
case 11:
if (day > 0 && day < 23) {
return "天蝎座";
} else if (day < 31) {
return "射手座";
} else {
return ERROR_DATE_OF_MONTH;
}
case 12:
if (day > 0 && day < 22) {
return "射手座";
} else if (day < 32) {
return "摩羯座";
} else {
return ERROR_DATE_OF_MONTH;
}
default:
return ERROR_MONTH_ARGS;
}
}
@Override
public String getDisplayString(String[] strings) {
return "Please check your code, unknown Exception!!!";
}
}
5. 打包,加入到集群中,进行测试。
为了方便大家确保环境一致,这里我贴出我编程环境的pom.xml
4.0.0
hive
hive-udf-test
1.0-SNAPSHOT
3.0.0
2.3.2
org.apache.hive
hive-exec
${hive.version}
org.apache.hadoop
hadoop-common
3.0.0
junit
junit
4.10
test
org.apache.maven.plugins
maven-compiler-plugin
2.3.2
1.8
1.8
UTF-8
下面演示下如何打包,这里我使用的是IDEA , IDEA 中集成较好,

打完包如图所示:

我们将这个包拷贝到 hive 目录下,另创建一个 my-jar 目录

执行 hive 客户端进行测试,
beeline -u jdbc:hive2://master:10000/test -n root

将打好的jar 载入hive 客户端:
(注意,载入的jar 只在此连接生效,并不会跨客户端,也就是说另一个客户端需要重新 add jar)
Hive 不仅将这个JAR文件加入到classpath 下,同时还将其加入到了分布式缓存中。
add jar /usr/local/hive/my-jar/hive-udf-test-1.0-SNAPSHOT.jar;

查看已经载入的jar
list jars;
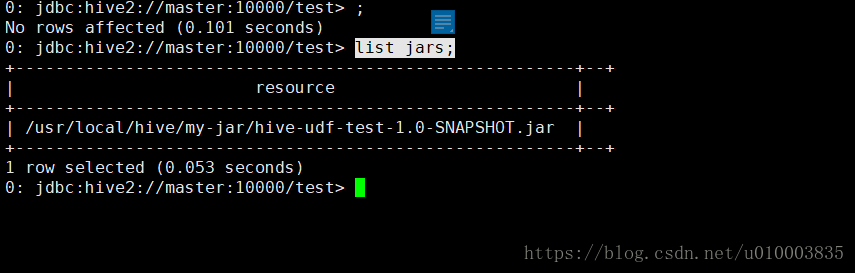
注册函数:
create temporary function zodiac as 'com.test.hive.udf.HiveTestZodiacUDF';
create temporary function zodiacx as 'com.test.hive.udf.HiveTestZodiacGenericUDF';

查看函数帮助文档:
describe function zodiac;
describe function zodiacx;
describe function extended zodiac;
describe function extended zodiacx;


构造测试用例:
先测试下函数功能:
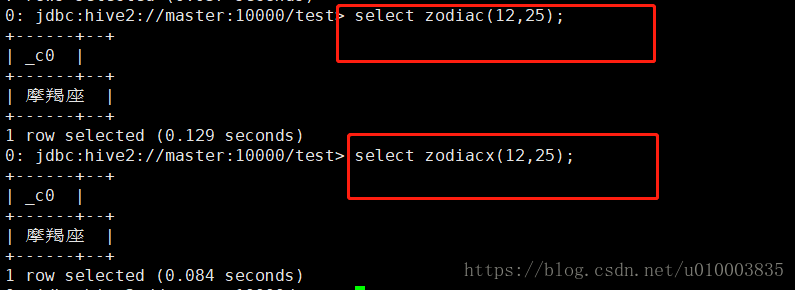
创建表 :
create table date_one(day string);
构建正确的样例:
insert into date_one values ('1992-12-25'),('2018-01-20'),('2018-07-20');
查询:
select zodiac(day) from date_one;

select zodiacx(day) from date_one;
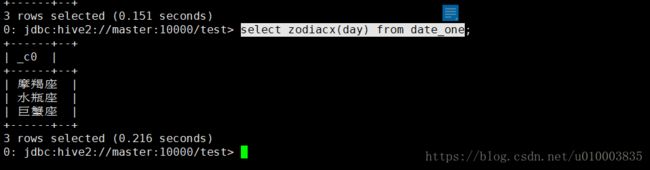
插入错误的数据:
insert into date_one values ('2222-32'),('2018-04-20'),('2018-17-20');

查询数据:
select zodiac(day) from date_one;
0: jdbc:hive2://master:10000/test> select zodiac(day) from date_one;
+----------------------+--+
| _c0 |
+----------------------+--+
| 摩羯座 |
| 水瓶座 |
| 巨蟹座 |
| invalid date format |
| 金牛座 |
| invalid date format |
+----------------------+--+
6 rows selected (0.185 seconds)
=========================================
select zodiacx(day) from date_one;
0: jdbc:hive2://master:10000/test> select zodiacx(day) from date_one;
Error: java.io.IOException: org.apache.hadoop.hive.ql.metadata.HiveException: Error evaluating Please check your code, unknown Exception!!! (state=,code=0)
0: jdbc:hive2://master:10000/test>
Please check your code, unknown Exception!!! 就是之前在 getDisplayString 中定义的返回值!!