Python批处理(一)提取txt中数据存入excel
Python批处理(一)提取txt中数据存入excel
问题描述
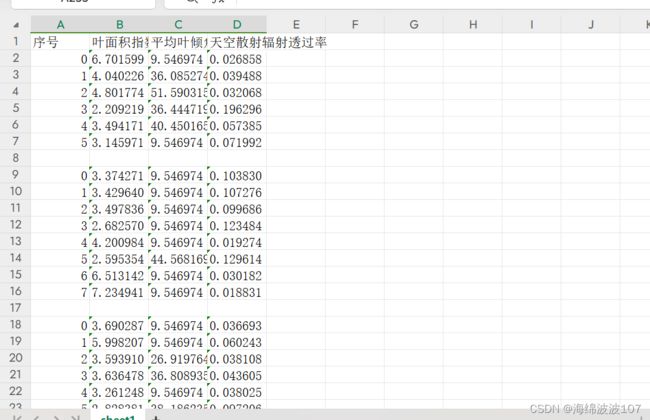
现从冠层分析软件中保存了叶面积指数分析的结果,然而软件保存格式为txt,且在不同的文件夹中,每个文件夹的txt文件数量不固定,但是txt文件格式固定。现需要批量处理这些txt文件,获取头三行的数据,并存入excel中。
源代码
def openreadtxt(file_name):
data = []
file = open(file_name, 'r') # 打开文件
file_data = file.readlines() # 读取所有行
for row in file_data:
tmp_list = row.split(' ') # 按‘,’切分每行的数据
# tmp_list[-1] = tmp_list[-1].replace('\n',',') #去掉换行符
data.append(tmp_list) # 将每行数据插入data中
return data
import os
import xlrd
# -*- coding: utf-8 -*-
import xlsxwriter as xw
def xw_toExcel(data, fileName): # xlsxwriter库储存数据到excel
workbook = xw.Workbook(fileName) # 创建工作簿
worksheet1 = workbook.add_worksheet("sheet1") # 创建子表
worksheet1.activate() # 激活表
title = ['序号', '叶面积指数', '平均叶倾角','天空散射辐射透过率'] # 设置表头
worksheet1.write_row('A1', title) # 从A1单元格开始写入表头
i = 2 # 从第二行开始写入数据
for j in range(len(data)):
insertData = [data[j]["id"], data[j]["lai"], data[j]["angle"],data[j]["sky"]]
row = 'A' + str(i)
worksheet1.write_row(row, insertData)
i += 1
workbook.close() # 关闭表
# "-------------数据用例-------------"
if __name__ == "__main__":
DATA=[]
list=['A1','A2','A3','A5','A8','A9','AA1','AA2','AA3','AA4','AA5','AA6','AA7','AA8','G1','L1','Q1','R1','R2','RR1','RR2','RR3','RR4','X2','X4','X5','XX1']
for i in list:
count = 0
for root, dirs, files in os.walk("D:/Learn_Python/数据分析项目/08_叶面积指数批处理/fly/"+str(i)+'/'):
for file in files:
ext = os.path.splitext(file)[-1].lower()
if ext == '.txt':
count = count + 1
print(i,count)
n=0
while(n<count):
print("正在读取"+i+"下第"+str(n)+"个文件")
data = openreadtxt('D:/Learn_Python/数据分析项目/08_叶面积指数批处理/fly/'+i+'/20230905_00'+str(n)+'.txt')
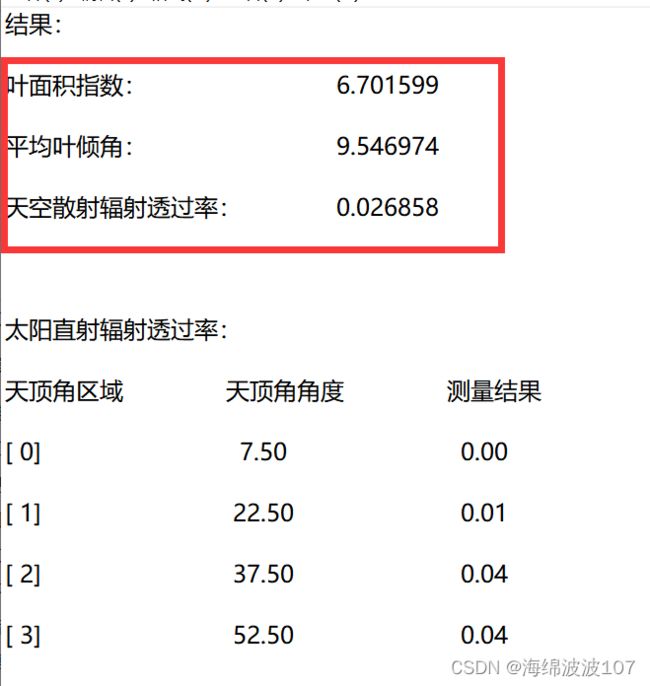
newdata={"id":n,"lai":data[2][4],"angle":data[4][4],"sky":data[6][10]}
DATA.append(newdata)
n=n+1
DATA.append({"id":1,"lai":1,"angle":1,"sky":1})
print(DATA)
xw_toExcel(DATA, 'D:/Learn_Python/数据分析项目/08_叶面积指数批处理/output.xlsx')
代码注释
1、file = open(file_name, ‘r’)。使用open()函数打开名为"filename.txt"的文件,并以只读模式(“r”)打开。然后使用read()方法将文件内容读取并赋值给变量file。
2、file_data = file.readlines(),它会从文件中逐行读取数据,并将每一行存储为一个列表中的元素。这样就可以逐行处理文件中的内容了。
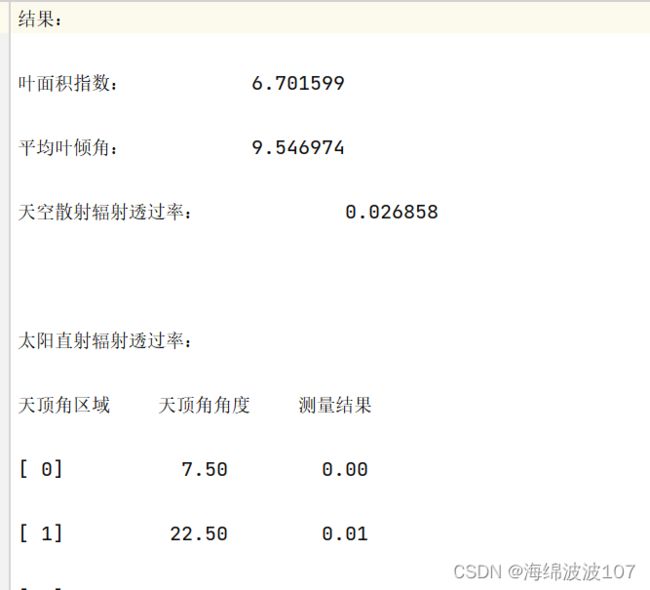
3、 tmp_list = row.split(’ ')。将字符串 row 按空格进行分割,并将分割后的结果存入列表 tmp_list 中。每个空格部分的内容都会成为列表中的一个元素。列表与其中分割的元素如下:
![]()
4、workbook = xw.Workbook(fileName) # 创建工作簿
worksheet1 = workbook.add_worksheet(“sheet1”) # 创建子表
worksheet1.activate() # 激活表。
首先,我们使用xw.Workbook()方法创建一个名为fileName的工作簿对象。然后,我们使用add_worksheet()方法在工作簿中创建一个名为"sheet1"的子表。最后,我们使用activate()方法激活该子表,使其成为活动表格,以激活后续操作。
5、worksheet1.write_row(row, insertData)。这是一个将数据写入Excel工作表中的代码片段。其中,worksheet1 是对应的工作表对象,row 是要写入的行数,insertData 是要插入的数据。
6、 for root, dirs, files in os.walk()。os.walk()是一个用于遍历目录树并获取目录中所有文件和子目录的函数。它返回一个生成器,可以用于迭代遍历目录结构。这里的root表示当前正在遍历的目录路径,dirs表示当前目录中的子目录列表,files表示当前目录中的文件列表。
7、ext = os.path.splitext(file)[-1].lower()。os.path.splitext(file):这个函数将文件名分割成文件名和扩展名的元组。例如,如果file是"example.txt",那么返回的元组将是(“example”, “.txt”)。
[-1]:这是Python中用于获取列表或元组中最后一个元素的索引。在这种情况下,它用于获取分割后元组中的扩展名(即.txt)。
.lower():这是一个字符串方法,用于将字符串转换为小写。这在这里使用是为了规范化扩展名,以便后续处理不受大小写的影响。
最终,ext变量将包含文件的小写扩展名。
8、newdata={“id”:n,“lai”:data[2][4],“angle”:data[4][4],“sky”:data[6][10]}
DATA.append(newdata)
每次创建一个字典
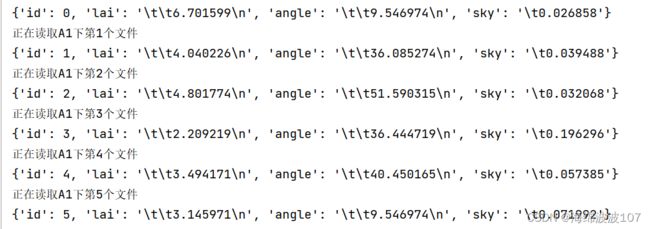
然后在列表中将每次创建的字典添加进去。
![]()
最后将字典写入excel中
运行结果