@。如何利用pb文件来测试模型
1.首先得到了pb文件,关于如何得到pb文件,可以参照下面:https://blog.csdn.net/weixin_43147226/article/details/106038604
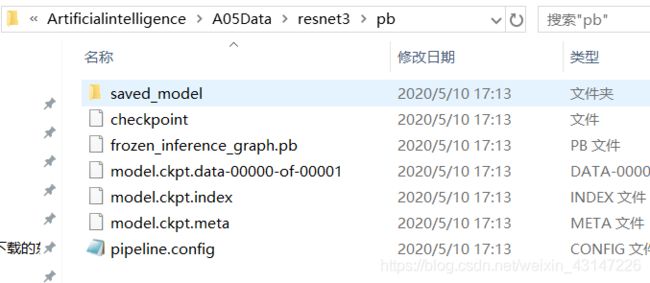
当然,你测试自己的模型,必须自己手写测试文件 (当然,也可以自己上网找(狗头))
现在以我的测试文件来说明需要配置的地方:
import numpy as np
import sys
import tensorflow as tf
import cv2
import glob
import time
from PIL import Image
from matplotlib import pyplot as plt
# This is needed since the notebook is store in the object_detection folder.
sys.path.append("..")
from object_detection.utils import ops as utils_ops
from object_detection.utils import label_map_util
from object_detection.utils import visualization_utils as vis_util
# What model to download.
# Path to frozen detection graph. This is the actual model that is used for the object detection.
PATH_TO_FROZEN_GRAPH = "D:\Artificialintelligence\A05Data\\resnet3\pb\\frozen_inference_graph.pb"
# List of the strings that is used to add correct label for each box.
PATH_TO_LABELS = "E:\\python\\Lib\\site-packages\\tensorflow\\tensorflow_models\\research\\object_detection\\data\\face_SafeHat_map.pbtxt"
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_FROZEN_GRAPH, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
im_path_list = glob.glob("D:\\Artificialintelligence\\A05Data\\ImageTest\\*")
IMAGE_SIZE = (256, 256)
category_index = label_map_util.create_category_index_from_labelmap(PATH_TO_LABELS, use_display_name=True)
print('category_index====', category_index)
def load_image_into_numpy_array(image):
(im_width, im_height) = image.size
return np.array(image.getdata()).reshape((im_height, im_width, 3)).astype(np.uint8)
#
# # Loading label map
# label_map = label_map_util.load_labelmap(PATH_TO_LABELS)
# categories = label_map_util.convert_label_map_to_categories(label_map, max_num_classes=NUM_CLASSES, use_display_name=True)
# category_index = label_map_util.create_category_index(categories)
def run_inference_for_single_image(image, graph):
with graph.as_default():
with tf.Session() as sess:
# Get handles to input and output tensors
ops = tf.get_default_graph().get_operations()
all_tensor_names = {output.name for op in ops for output in op.outputs}
tensor_dict = {}
for key in [
'num_detections', 'detection_boxes', 'detection_scores',
'detection_classes', 'detection_masks'
]:
tensor_name = key + ':0'
if tensor_name in all_tensor_names:
tensor_dict[key] = tf.get_default_graph().get_tensor_by_name(
tensor_name)
if 'detection_masks' in tensor_dict:
# The following processing is only for single image
detection_boxes = tf.squeeze(tensor_dict['detection_boxes'], [0])
detection_masks = tf.squeeze(tensor_dict['detection_masks'], [0])
# Reframe is required to translate mask from box coordinates to image coordinates and fit the image size.
real_num_detection = tf.cast(tensor_dict['num_detections'][0], tf.int32)
detection_boxes = tf.slice(detection_boxes, [0, 0], [real_num_detection, -1])
detection_masks = tf.slice(detection_masks, [0, 0, 0], [real_num_detection, -1, -1])
detection_masks_reframed = utils_ops.reframe_box_masks_to_image_masks(
detection_masks, detection_boxes, image.shape[0], image.shape[1])
detection_masks_reframed = tf.cast(
tf.greater(detection_masks_reframed, 0.5), tf.uint8)
# Follow the convention by adding back the batch dimension
tensor_dict['detection_masks'] = tf.expand_dims(
detection_masks_reframed, 0)
image_tensor = tf.get_default_graph().get_tensor_by_name('image_tensor:0')
# Run inference
output_dict = sess.run(tensor_dict,
feed_dict={image_tensor: np.expand_dims(image, 0)})
# all outputs are float32 numpy arrays, so convert types as appropriate
output_dict['num_detections'] = int(output_dict['num_detections'][0])
output_dict['detection_classes'] = output_dict[
'detection_classes'][0].astype(np.uint8)
output_dict['detection_boxes'] = output_dict['detection_boxes'][0]
output_dict['detection_scores'] = output_dict['detection_scores'][0]
if 'detection_masks' in output_dict:
output_dict['detection_masks'] = output_dict['detection_masks'][0]
return output_dict
# for image_path in im_path_list:
# imdata = cv2.imread(image_path)
# sp = imdata.shape
# imdata = cv2.resize(imdata, IMAGE_SIZE)
# output_dict = run_inference_for_single_image(imdata, detection_graph)
# for i in range(len(output_dict['detection_scores'])):
# scores = output_dict['detection_scores'][i]
# print('scores======', scores)
# classes = output_dict['detection_classes'][i]
# print("classes====", classes)
# if output_dict['detection_scores'][i] > 0.4:
# # print("类别:%s"%(category_index[output_dict['detection_classes'][i]]))
# bbox = output_dict['detection_boxes'][i]
# y1 = int(IMAGE_SIZE[0] * bbox[0])
# x1 = int(IMAGE_SIZE[1] * bbox[1])
# y2 = int(IMAGE_SIZE[0] * bbox[2])
# x2 = int(IMAGE_SIZE[1] * bbox[3])
# name = 'test'
# cv2.rectangle(imdata, (x1, y1), (x2, y2), (0, 255, 0), 2)
# cv2.putText(imdata, name, (x1, y1-10), cv2.FONT_HERSHEY_COMPLEX, 1, (0, 255, 0), 2)
#
# cv2.imshow("im", imdata)
# cv2.waitKey(0)
print("test begin")
number = 1
for image_path in im_path_list:
time_start = time.time()
print("image_path:",image_path)
image = Image.open(image_path)
fig = plt.figure()
# ax = fig.add_subplot(121)
# ax.imshow(image)
# the array based representation of the image will be used later in order to prepare the
# result image with boxes and labels on it.
image_np = load_image_into_numpy_array(image)
# Expand dimensions since the model expects images to have shape: [1, None, None, 3]
image_np_expanded = np.expand_dims(image_np, axis=0)
# Actual detection.
output_dict = run_inference_for_single_image(image_np, detection_graph)
# Visualization of the results of a detection.
vis_util.visualize_boxes_and_labels_on_image_array(
image_np,
output_dict['detection_boxes'],
output_dict['detection_classes'],
output_dict['detection_scores'],
category_index,
instance_masks=output_dict.get('detection_masks'),
use_normalized_coordinates=True,
line_thickness=8)
ax = fig.add_subplot(111)
ax.imshow(image_np) # 以灰度图显示图片
# plt.axis("off")#不显示刻度
plt.savefig("test_out_images4/image"+str(number)+".jpg")
number+=1
# plt.show(image) # 显示刚才所画的所有操作
# 结果显示
print("结果显示")
print("----------.----------.----------.----------")
# print(len(output_dict['detection_scores'])) #100
for i in range(100):
if (output_dict['detection_scores'][i] == 0.0):
continue
print("框坐标[%.2f,%.2f,%.2f,%.2f], 类别:%s, 概率%.2f"%(output_dict['detection_boxes'][i][0], output_dict['detection_boxes'][i][1], output_dict['detection_boxes'][i][2], output_dict['detection_boxes'][i][3]
, category_index[output_dict['detection_classes'][i]]
, output_dict['detection_scores'][i]))
time_end = time.time()
print('totally cost', time_end - time_start)
print("test end")
需要注意的有:
- 该路径就是pb文件所在的路径
PATH_TO_FROZEN_GRAPH = "D:\Artificialintelligence\A05Data\\resnet3\pb\\frozen_inference_graph.pb"
- pbtxt内容如下:
PATH_TO_LABELS = "E:\\python\\Lib\\site-packages\\tensorflow\\tensorflow_models\\research\\object_detection\\data\\face_SafeHat_map.pbtxt"
item {
name: "person"
id: 1
display_name: "person"
}
item {
name: "hat"
id: 2
display_name: "hat"
}
im_path_list = glob.glob("D:\\Artificialintelligence\\A05Data\\ImageTest\\*")这是遍历文件夹下面的图片路径

plt.savefig("test_out_images4/image"+str(number)+".jpg")这是生成的文件夹及其测试后的输出的照片
运行后的结果
开始测试:
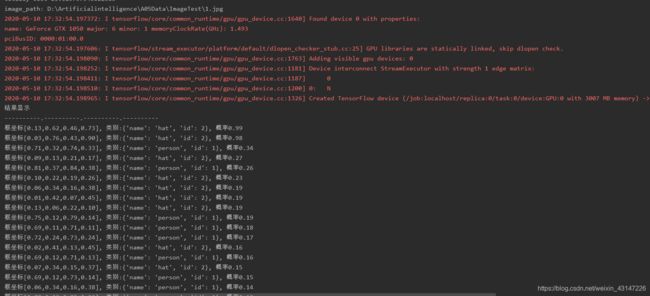
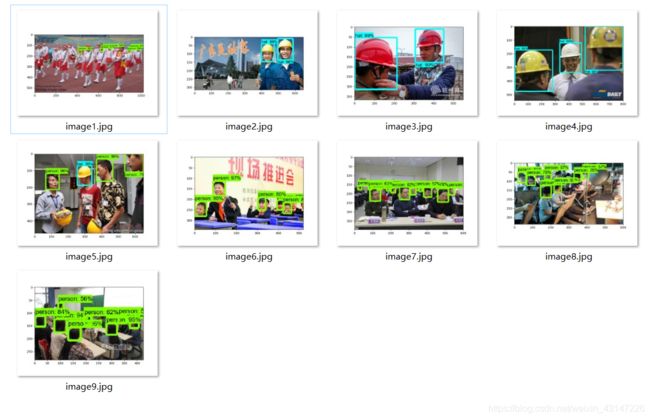
上面的测试文件是用照片list来测试,现在下面的测试文件是一张一张图片测试的。问为什么要这么区分?因为需求是通过视频来测试图片,所以实际上每一帧=每一张图片
import sys
import numpy as np
import tensorflow as tf
import cv2
sys.path.append("..")
from object_detection.utils import label_map_util
from object_detection.utils import ops as utils_ops
# 非最大值抑制算法
def py_nms(dets, thresh):
# x1、y1、x2、y2、以及score赋值
x1 = dets[:, 0]
y1 = dets[:, 1]
x2 = dets[:, 2]
y2 = dets[:, 3]
scores = dets[:, 4]
# 每一个候选框的面积
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
# order是按照score降序排序的
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
# 计算当前概率最大矩形框与其他矩形框的相交框的坐标
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
# 计算相交框的面积
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
# 计算重叠度IOU:重叠面积/(面积1+面积2-重叠面积)
ovr = inter / (areas[i] + areas[order[1:]] - inter)
# 找到重叠度不高于阈值的矩形框索引
inds = np.where(ovr <= thresh)[0]
# 将order序列更新,由于前面得到的矩形框索引要比矩形框在原order序列中的索引小1,所以要把这个1加回来
order = order[inds + 1]
return keep
# 模型文件路径
# PATH_TO_CKPT = 'D:\\迅雷下载\\helmet_detection\\helmet_detection\\object_detection\\my_inference_graph\\frozen_inference_graph.pb'
PATH_TO_CKPT = 'D:\Artificialintelligence\A05Data\\resnet2\pb2\\frozen_inference_graph.pb'
# 标签文件路径
PATH_TO_LABELS = 'E:\python\Lib\site-packages\\tensorflow\\tensorflow_models\\research\object_detection\data\\face_SafeHat_map.pbtxt'
# 标签种类数
NUM_CLASSES = 2
# 加载标签信息
label_map = label_map_util.load_labelmap(PATH_TO_LABELS)
categories = label_map_util.convert_label_map_to_categories(label_map, max_num_classes=NUM_CLASSES,
use_display_name=True)
category_index = label_map_util.create_category_index(categories)
cv2.namedWindow('capture', 0)
cv2.resizeWindow('capture', 720, 720)
cv2.moveWindow('capture', 0, 0)
image_path = "D:\Artificialintelligence\A05Data\ImageTest\\001.jpg"
image = cv2.imread(image_path)
# 获取图片信息
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 加载tensorflow目标检测模型
detection_graph = tf.Graph()
with detection_graph.as_default():
with tf.Session() as sess:
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_CKPT, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
#----------output_dict = run_inference_for_single_image(image, detection_graph)----------------------------
ops = tf.get_default_graph().get_operations()
all_tensor_names = {output.name for op in ops for output in op.outputs}
tensor_dict = {}
for key in [
'num_detections', 'detection_boxes', 'detection_scores',
'detection_classes', 'detection_masks'
]:
tensor_name = key + ':0'
if tensor_name in all_tensor_names:
tensor_dict[key] = tf.get_default_graph().get_tensor_by_name(
tensor_name)
if 'detection_masks' in tensor_dict:
# The following processing is only for single image
detection_boxes = tf.squeeze(tensor_dict['detection_boxes'], [0])
detection_masks = tf.squeeze(tensor_dict['detection_masks'], [0])
# Reframe is required to translate mask from box coordinates to image coordinates and fit the image size.
real_num_detection = tf.cast(tensor_dict['num_detections'][0], tf.int32)
detection_boxes = tf.slice(detection_boxes, [0, 0], [real_num_detection, -1])
detection_masks = tf.slice(detection_masks, [0, 0, 0], [real_num_detection, -1, -1])
detection_masks_reframed = utils_ops.reframe_box_masks_to_image_masks(
detection_masks, detection_boxes, image.shape[0], image.shape[1])
detection_masks_reframed = tf.cast(
tf.greater(detection_masks_reframed, 0.5), tf.uint8)
# Follow the convention by adding back the batch dimension
tensor_dict['detection_masks'] = tf.expand_dims(
detection_masks_reframed, 0)
image_tensor = tf.get_default_graph().get_tensor_by_name('image_tensor:0')
# Run inference
output_dict = sess.run(tensor_dict,
feed_dict={image_tensor: np.expand_dims(image, 0)})
# all outputs are float32 numpy arrays, so convert types as appropriate
output_dict['num_detections'] = int(output_dict['num_detections'][0])
output_dict['detection_classes'] = output_dict[
'detection_classes'][0].astype(np.uint8)
output_dict['detection_boxes'] = output_dict['detection_boxes'][0]
output_dict['detection_scores'] = output_dict['detection_scores'][0]
if 'detection_masks' in output_dict:
output_dict['detection_masks'] = output_dict['detection_masks'][0]
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
height = image.shape[0]
width = image.shape[1]
i = 0
scores = output_dict['detection_scores']
helmet_dets = np.empty((0, 5), dtype='int') # 存储安全帽的标识框坐标数据
person_dets = np.empty((0, 5), dtype='int') # 存储人的标识框坐标数据
while scores[i] > 0.3: # score_thresh=0.1
score = scores[i]
print("score====", score)
first_box = output_dict['detection_boxes'][i]
x1 = int(first_box[1] * width)
y1 = int(first_box[0] * height)
x2 = int(first_box[3] * width)
y2 = int(first_box[2] * height)
class_index = output_dict['detection_classes'][i]
helmet_det = np.empty((1, 5), dtype='int')
person_det = np.empty((1, 5), dtype='int')
if class_index == 2:
if score > 0.4:
helmet_det[0, 0] = x1
helmet_det[0, 1] = y1
helmet_det[0, 2] = x2
helmet_det[0, 3] = y2
helmet_det[0, 4] = score * 100
helmet_dets = np.vstack((helmet_dets, helmet_det))
elif class_index ==1:
if score >0.4:
person_det[0, 0] = x1
person_det[0, 1] = y1
person_det[0, 2] = x2
person_det[0, 3] = y2
person_det[0, 4] = score * 100
person_dets = np.vstack((person_dets, person_det))
i = i + 1
# 使用最大值抑制算法去掉重复的目标框
helmet_keep = py_nms(helmet_dets, 0.3) # helmet_nms_thresh=0.3
helmet_dets = helmet_dets[helmet_keep]
# 使用最大值抑制算法去掉重复的目标框
person_keep = py_nms(person_dets, 0.3) # person_nms_thresh=0.3
person_dets = person_dets[person_keep]
# person_helmet_index = judge_person(helmet_dets, person_dets)
helmet_num = len(helmet_dets)
print("helmet_num====", helmet_num)
person_num = len(person_dets)
print("person_num====", person_num)
# 判断某人是否戴了安全帽的算法
# theta:中心连线与垂直方向夹角的tan值
# thresh:安全帽中心落在人的矩阵框中的范围
# helmet_mid_dets = np.zeros((helmet_num, 2), dtype='int')
# keep_person = []
# for i in range(helmet_num):
# helmet_mid_dets[i, 0] = (helmet_dets[i][0] + helmet_dets[i][2]) / 2
# helmet_mid_dets[i, 1] = (helmet_dets[i][1] + helmet_dets[i][3]) / 2
# for i in range(person_num):
# mid_x = (person_dets[i][0] + person_dets[i][2]) / 2
# mid_y = (person_dets[i][1] + person_dets[i][3]) / 2
# height = person_dets[i][3] - person_dets[i][1]
# width = person_dets[i][2] - person_dets[i][0]
# for j in range(helmet_num):
# x_dis = helmet_mid_dets[j, 0] - mid_x
# y_dis = helmet_mid_dets[j, 1] - mid_y
# tan = x_dis / y_dis
# if y_dis < 0 and tan > -1.2 and tan < 1.2: # theta=1.2
# left_x = mid_x - 0.6 * width # x_thresh=0.6
# right_x = mid_x + 0.6 * width
# up_y = mid_y - 0.75 * height # y_thresh=0.75
# down_y = mid_y - (1 - 0.75) * height
# if helmet_mid_dets[j, 0] > left_x and helmet_mid_dets[j, 0] < right_x and helmet_mid_dets[
# j, 1] > up_y and helmet_mid_dets[j, 1] < down_y:
# keep_person.append(i)
# break
# person_helmet_index = judge_person(helmet_dets, person_dets)
# 可视化识别得到的信息
for i in range(len(helmet_dets)):
cv2.rectangle(image, (helmet_dets[i, 0], helmet_dets[i, 1]), (helmet_dets[i, 2], helmet_dets[i, 3]),
(0, 255, 0), 2)
cv2.putText(image, 'helmet' + str(helmet_dets[i, 4]) + '%', (helmet_dets[i, 0], helmet_dets[i, 1] + 15),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0), 2, cv2.LINE_AA)
for i in range(len(person_dets)):
# if i in keep_person:
# cv2.rectangle(image, (person_dets[i, 0], person_dets[i, 1]), (person_dets[i, 2], person_dets[i, 3]),
# (0, 255, 0), 2)
# else:
# cv2.rectangle(image, (person_dets[i, 0], person_dets[i, 1]), (person_dets[i, 2], person_dets[i, 3]),
# (0, 0, 255), 2)
# cv2.putText(image, str(person_dets[i, 4]) + '%', (person_dets[i, 0], person_dets[i, 1] + 15),
# cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0), 2, cv2.LINE_AA)
cv2.rectangle(image, (person_dets[i, 0], person_dets[i, 1]), (person_dets[i, 2], person_dets[i, 3]),
(0, 0, 255), 2)
cv2.putText(image, 'person' + str(person_dets[i, 4]) + '%', (person_dets[i, 0], person_dets[i, 1] + 15),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0), 2, cv2.LINE_AA)
# 统计总人数,戴帽人数与未戴帽人数
person_sum = len(person_dets) + len(helmet_dets)
# person_wear_helmet_sum = len(keep_person)
person_wear_helmet_sum = len(helmet_dets)
cv2.putText(image, 'person_sum:' + str(person_sum), (0, height - 90), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 0), 2,
cv2.LINE_AA)
cv2.putText(image, 'wear_helmet:' + str(person_wear_helmet_sum), (0, height - 50), cv2.FONT_HERSHEY_SIMPLEX, 1,
(0, 0, 0), 2, cv2.LINE_AA)
cv2.imshow('capture', image)
cv2.waitKey(0)
cv2.destroyAllWindows()