一张表中几列字段以不同的条件规则去统计计数展示实现思路设计
今天在写一个业务的时候,遇到这样一个需求
一、需求描述
一张表中其中几列字段需要以不同的条件规则去统计计数,求实现方式
因为项目业务涉及隐私,我就想了一个类似的情景
二、情景描述
有一张月考成绩表,包含学生和他的各科成绩

现在需要生成一张统计表,统计各月份 各班级 各科成绩高于80的人数
如:
| 月考月份 | 班级 | 语文 | 数学 | 英语 | 物理 |
|---|---|---|---|---|---|
| 2023-07 | 301 | 18 | 24 | 27 | 15 |
| 2023-07 | 302 | 27 | 0 | 33 | 0 |
| 2023-07 | 303 | 16 | 13 | 19 | 21 |
注意:
1、月考不是强制要求,以班级为单位,会存在某月某一班级没参加月考的情况,如303班在6月没参与考试
2、会存在某一班级某一学科成绩没有超过80分的情况
分析发现,表中存有不同班级不同月份的成绩数据,科目不只一个,如果想使用sql语句来实现的话,一个sql语句只能查询出一个科目满足要求的人数,
如:
select count(math) math,yearmonth,classroom from stu_score where math>80
group by yearmonth,classroom
这个sql只能查询各班级各月份一个科目(数学)统计的人数
那么执行多条sql来查询出各科成绩人数再拼接起来(通过月份和班级关联)
如果数据很规范的话,这样处理没有问题,可是注意中2个条件让问题增加了难度
三、展开细节
查询各科人数数据,你会发现
select count(math) math,yearmonth,classroom from stu_score where math>80
group by yearmonth,classroom

select count(chinese) chinese,yearmonth,classroom from stu_score where chinese>80
group by yearmonth,classroom

select count(english) english,yearmonth,classroom from stu_score where english>80
group by yearmonth,classroom

select count(physics) physics,yearmonth,classroom from stu_score where physics>80
group by yearmonth,classroom

如何把查询出来的4个数据结果存放到一张表中,这是我们需要解决的问题
四、方案探讨
有人会说,这简单,根据yearmonth,classroom这2个字段来关联,4张表多表查询实现就好了
但观察会发现,4组查询出来的数据,yearmonth,classroom进行关联,会存在部分数据无法连接查询
如观察英语和语文查询出来的数据

对于上面的数据,我们希望查询的结果是
| yearmonth | classroom | English | chinese |
|---|---|---|---|
| 2023-07 | 302 | 2 | 1 |
| 2023-07 | 301 | 7 | 4 |
| 2023-07 | 303 | 1 | 0 |
| 2023-06 | 301 | 0 | 1 |
发现303班7月有英语人数,但没有语文人数
也就是说如果以英语表作为主表外左连接那么无法查询出这种效果(外连接需要关联yearmonth,classroom,以其中一个表作主表进行外连接,都会丢失第3或第4条数据)
有人会说,用笛卡尔积,这种方式更没有实际意义,会查出3*3=9条数据,但数据无意义且不正确
然后我想着Java结合sql语句的方式来实现这个过程:
下面是我2个思路:
思路一
把查询出来的各科人数存入多个集合中,再准备一个汇总集合,把分散的学科集合都添加到汇总集合中,这样汇总集合里数据就是需要的统计数据
这个思路想法很好,但在代码实现的过程中发现,实现难度较大,最后放弃了,但我还是说一下实现过程:
1、把查询出来的各科人数存入集合中,题目中有4个科目,那么就存入4个list集合a,b,c,d
list的泛型是自定义的dto
@Data
public class ScoreStatDto {
private String yearmonth;
private String classroom;
private String chinese;
private String math;
private String english;
private String physics;
}
每个集合中3个元素会赋值,yearmonth,classroom和对应学科
2、获取最长的那个集合长度
3、按这个长度进行循环遍历,在遍历过程中有值就赋值
for(int i=0;i<max;i++){
ScoreStatDto dto = new ScoreStatDto();
if(a.size() <=i){
//集合已经遍历完
}else{
dto.set科目1(a.get(i).get科目1());
if(b.size() <= i){
//嵌套4个if
...
}
}
}
这样写出来的代码不仅丑陋,而且也存在问题,科目a和科目b查出来的数据yearmonth,classroom不一定一一对应,如:
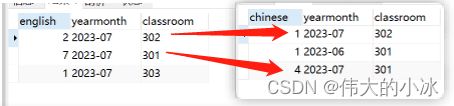
那又得加判断逻辑,很麻烦繁琐,所以pass
思路二:
拿到集合数据,依次存入一张新表中,存入规则为:以yearmonth,classroom为联合主键,如果没有就新增,如果有则更新,存入完成后即为需要的统计结果
1、还是存到4个集合中,再把4个集合存入一张新表中score_stat,新表表结构为:
yearmonth,classroom,和各科科目人数,yearmonth,classroom是联合主键

2、存入数据的方式:如果有yearmonth,classroom都一样的,那么更新这条记录(也就完成了科目的拼接),如果没有,那么新增
这种存数据的方式sql是可以实现的:
INSERT INTO score_stat (yearmonth, classroom, chinese)
values(:yearmonth, :classroom, :chinese)
ON DUPLICATE KEY UPDATE
chinese = VALUES(chinese)
注意:
1、其中带有冒号的要替换为字段对应的value值
2、score_stat这张表要把yearmonth,classroom设置为主键
那么4个科目对应4个集合那就需要4个sql来完成
3、插入完成后,score_stat表即为目标数据
五、小结:
- 在实现业务逻辑的时候,不一定非要一个sql语句来解决业务要求,可以试着对需求进行拆分,也可以试着开发语言与sql语句结合的方式来共同完成需求的实现;
- 使用复杂的sql语句可能会降低性能;
- 可以考虑将查询的数据存入新表中;
ps: 思路二上的sql还是chatgpt教我的,真的是大大提高了生产力 ψ(`∇´)ψ

如果同学们想要复现上述情景,资料如下:
1、成绩表
DROP TABLE IF EXISTS `stu_score`;
CREATE TABLE `stu_score` (
`stuname` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '学生姓名',
`chinese` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '语文',
`math` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '数学',
`English` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '英语',
`physics` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '物理',
`classroom` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '班级',
`yearmonth` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '年月'
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci COMMENT = '学生成绩表' ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of stu_score
-- ----------------------------
INSERT INTO `stu_score` VALUES ('李四1', '98', '100', '89', '50', '302', '2023-07');
INSERT INTO `stu_score` VALUES ('王五1', '72', '76', '80', '59', '302', '2023-07');
INSERT INTO `stu_score` VALUES ('赵六1', '66', '78', '99', '100', '302', '2023-07');
INSERT INTO `stu_score` VALUES ('张三1', '80', '95', '76', '92', '302', '2023-07');
INSERT INTO `stu_score` VALUES ('张三2', '80', '95', '76', '92', '301', '2023-06');
INSERT INTO `stu_score` VALUES ('李四2', '98', '100', '79', '50', '301', '2023-06');
INSERT INTO `stu_score` VALUES ('王五2', '72', '76', '66', '59', '301', '2023-06');
INSERT INTO `stu_score` VALUES ('赵六2', '66', '78', '79', '100', '301', '2023-06');
INSERT INTO `stu_score` VALUES ('张三3', '80', '95', '76', '92', '301', '2023-06');
INSERT INTO `stu_score` VALUES ('李四3', '98', '100', '89', '50', '301', '2023-07');
INSERT INTO `stu_score` VALUES ('王五3', '72', '76', '80', '59', '301', '2023-07');
INSERT INTO `stu_score` VALUES ('赵六3', '66', '78', '99', '100', '301', '2023-07');
INSERT INTO `stu_score` VALUES ('张三4', '80', '95', '76', '92', '301', '2023-07');
INSERT INTO `stu_score` VALUES ('李四4', '98', '100', '89', '50', '301', '2023-07');
INSERT INTO `stu_score` VALUES ('王五4', '72', '76', '80', '59', '301', '2023-07');
INSERT INTO `stu_score` VALUES ('赵六4', '66', '78', '99', '100', '301', '2023-07');
INSERT INTO `stu_score` VALUES ('张三5', '80', '95', '76', '92', '301', '2023-07');
INSERT INTO `stu_score` VALUES ('李四5', '98', '100', '89', '50', '301', '2023-07');
INSERT INTO `stu_score` VALUES ('王五5', '72', '76', '80', '59', '301', '2023-07');
INSERT INTO `stu_score` VALUES ('赵六5', '66', '78', '99', '100', '301', '2023-07');
INSERT INTO `stu_score` VALUES ('张三', '80', '95', '76', '92', '301', '2023-07');
INSERT INTO `stu_score` VALUES ('李四', '98', '100', '89', '50', '301', '2023-07');
INSERT INTO `stu_score` VALUES ('王五', '72', '76', '80', '59', '303', '2023-07');
INSERT INTO `stu_score` VALUES ('赵六', '66', '78', '99', '100', '303', '2023-07');
2、统计表
CREATE TABLE `score_stat` (
`chinese` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '语文',
`math` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '数学',
`English` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '英语',
`physics` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '物理',
`classroom` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '班级',
`yearmonth` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '年月',
PRIMARY KEY (`classroom`,`yearmonth`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ROW_FORMAT=DYNAMIC COMMENT='优秀成绩人数统计表';
项目结构

pojo
@TableName("stu_score")
@Data
public class StuScore {
private String stuname;
private String yearmonth;
private String classroom;
private String chinese;
private String math;
private String english;
private String physics;
}
dto层
@Data
public class ScoreStatDto {
private String yearmonth;
private String classroom;
private String chinese;
private String math;
private String english;
private String physics;
}
mapper层
@Mapper
public interface StuScoreMapper extends BaseMapper<StuScore> {
int insertChinese(@Param("datas") List<ScoreStatDto> datas);
int insertMath(@Param("datas") List<ScoreStatDto> datas);
List<ScoreStatDto> selectChinese();
List<ScoreStatDto> selectMath();
}
(应该有4个插入接口的,写了2个也能看出效果,剩下2个大家可以类比写出来)
mapper.xml
DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xbwang.demos.mappers.StuScoreMapper">
<insert id="insertChinese">
INSERT INTO score_stat (yearmonth, classroom, chinese)
values
<foreach collection="datas" item="item" separator="," >
(
#{item.yearmonth,jdbcType=VARCHAR},
#{item.classroom,jdbcType=VARCHAR},
#{item.chinese,jdbcType=VARCHAR}
)
foreach>
ON DUPLICATE KEY UPDATE
chinese = VALUES(chinese)
insert>
<insert id="insertMath">
INSERT INTO score_stat (yearmonth, classroom, math)
values
<foreach collection="datas" item="item" separator="," >
(
#{item.yearmonth,jdbcType=VARCHAR},
#{item.classroom,jdbcType=VARCHAR},
#{item.math,jdbcType=VARCHAR}
)
foreach>
ON DUPLICATE KEY UPDATE
math = VALUES(math)
insert>
<select id="selectChinese" resultType="com.xbwang.demos.pojo.dto.ScoreStatDto">
select count(chinese) chinese,yearmonth,classroom from stu_score
where chinese > 80 group by yearmonth, classroom
select>
<select id="selectMath" resultType="com.xbwang.demos.pojo.dto.ScoreStatDto">
select count(math) math,yearmonth,classroom from stu_score
where math > 80 group by yearmonth, classroom
select>
mapper>
controller层
@RestController
public class StuController {
@Resource
private StuScoreMapper stuScoreMapper;
@RequestMapping("/insertdemo")
public String insertdemo(){
LambdaQueryWrapper<StuScore> wrapper = new LambdaQueryWrapper<>();
wrapper.gt(StuScore::getChinese,80);
wrapper.groupBy(StuScore::getClassroom);
wrapper.groupBy(StuScore::getYearmonth);
List<ScoreStatDto> datas = stuScoreMapper.selectChinese();
int i = stuScoreMapper.insertChinese(datas);
List<ScoreStatDto> maths = stuScoreMapper.selectMath();
int i2 = stuScoreMapper.insertMath(maths);
//还有2个科目,相同的方式
return "success";
}
}
这里提供的代码只是为了演示功能效果的demo,像service层,统一的返回类型等这些我就没刻意去写了。