HADOOP之HDFS集群配置
前期准备:
免密配置成功,jdk 1.8.0_271环境变量配置成功的前提下(免密和jdk没有配置好的看前面的博客)
将配置好的jdk 1.8.0_271文件夹和hadoop-2.7.6 下载解压后的文件夹上传到主节点
解压下载的Hadoop压缩包
tar -zxvf hadoop-2.7.6.tar.gz解压后得到两个文件
![]()
在当前(主节点)上建立一个hadoop文件夹,在hadoop文件夹下建立NameNode和DataNode两个空文件夹
mkdir namenodemkdir datanode目录结构如下

一.纵向配置:
如果使用root账户配置全部用户的环境变量,则修改配置文件:
/ect/profile如果使用用户hadoop22配置环境变量,则修改配置文件:
cd /home/hadoop22vim .bashrc增加如下内容:
#Hadoop
export HADOOP_HOME=/home/hadoop22/hadoop/hadoop-2.7.6
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
/* /home/hadoop22/hadoop/hadoop-2.7.6为具体安装路径*/
保存退出后输入source .bashrc使其生效
source .bashrc二、横向配置:
进入$/HADOOP_HOME/etc/hadoop目录:
cd hadoop-2.7.6/etc/hadoop完成该目录下的四个配置文件:
1、配置core-site.xml
fs.defaultFS
hdfs://westgisB087:8020
/*此处的westgisB087为NameNode的机器名,8020为RPC通讯端口*/
2、配置hdfs-site.xml
vim hdfs-site.xml
dfs.replication
3
dfs.namenode.name.dir
/home/hadoop22/software/hadoop/namnodee
dfs.datanode.data.dir
/home/hadoop22/software/hadoop/datanode
/*此处dfs.replation为数据的备份个数,一般情况为3
此处/home/hadoop22/software/hadoop/namenode为元数据在namenode本地存储路径,手动创建
此处/home/hadoop22/software/hadoop/dadanode为实际数据在datanode3、配置hadoop-env.sh
本地存储路径,手动创建*/
3、配置hadoop-env.sh
vim hadoop-env.sh在文件最后增加 export JAVA_HOME=/home/hadoop22/software/jdk/jdk1.8.0_271
/*在配置文件中增加jdk的路径*/
4、配置slaves
vim slaves删除文件重的localhost,然后将HDFS集群所有的DataNade机器名,每一个,形式如下:
westgisB083
westgisB084
westgisB085
westgisB086复制主节点的jdk 和 hadoop到所有从节点:
scp -r hadoop/ [email protected]:/home/hadoop22/software
scp -r jdk/ [email protected]:/home/hadoop22/software复制主节点环境配置到所有从节点:
scp .bashrc [email protected]:/home/hadoop22这里传完以后要到每个节点下面配置环境变量然后source .bashrc生效
三、集群的初始化与启动:
1、格式化HDFS
hadoop namenode -format2、启动HDFS
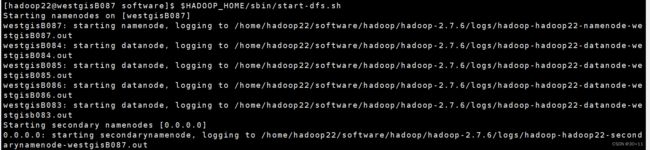
主节点执行 $HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-dfs.sh看到如下所示说明你的hdfs配置成功,奖励一下自己。
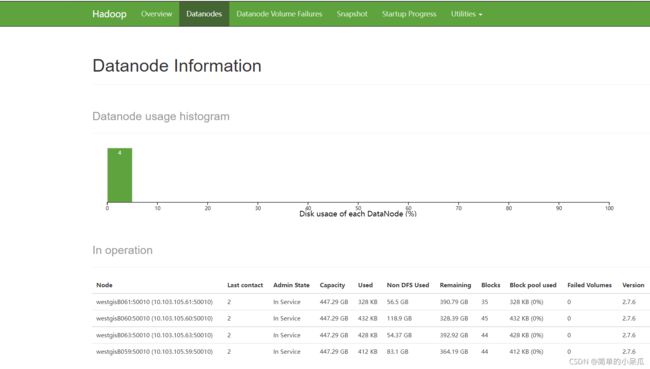
3、Web监控界面
URL http://10.103.105.87:50070
/*监控界面显示了集群的相关信息如NN节点个数、节点存储空间等信息*/
4、命令行状态查看集群状态
hadoop dfsadmin –report /*显示节点个数、节点存储空间等信息*/
5、停止HDFS
主节点执行 $HADOOP_HOME/sbin/stop-dfs.sh
$HADOOP_HOME/sbin/stop-dfs.sh常见的错误排查方法:
1、查看java进程(一)
jps /*显示当前账户java进程*/
2、查看java进程(二)
ps aux|grep java /*显示当前节点java进程,功能比(一)强大*/
3、查看端口是否开启
netstat –tunlp|grep 50070
4、占用某个端口的进程
lsof–i:50070
5、异常处理查看日志
$HADOOP_HOME/logs/*-DataNode-.log
$HADOOP_HOME/logs/*-DataNode-.out