基于Item的协同过滤算法实践(最简单的在线电影推荐系统)
上一篇文章《基于用户的协同过滤算法实践》中,基于用户的相似度生成推荐列表,本文将基于Item的相似度阐述。
1 相似度
基于物品的协同过滤算法(简称ItemCF)给用户推荐那些和他们之前喜欢的物品相似的物品。不过ItemCF不是利用物品的内容计算物品之间相似度,而是利用用户的行为记录。
该算法认为,物品A和物品B具有很大的相似度是因为喜欢物品A的用户大都也喜欢物品B。这里蕴含一个假设,就是每个用户的兴趣都局限在某几个方面,因此如果两个物品属于同一个用户的兴趣列表,那么这两个物品可能就属于有限的几个领域。而如果两个物品同时出现在很多用户的兴趣列表,那么它们可能就属于同一领域,因而具有很大的相似度。
从上述概念出发,定义物品i和j的相似度为
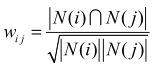
其中,|N(i)||N(i)|是喜欢物品i的用户数,|N(i)⋂N(j)||N(i)⋂N(j)|是同时喜欢物品i和物品j的用户数。分母是惩罚物品i和j的权重,因此惩罚了热门物品和很多物品相似的可能性。
在ItemCF中,两个物品产生相似度是因为它们共同出现在很多用户的兴趣列表中。假设有这么一个用户,他是开书店的,并且买了当当网上 80% 的书准备用来自己卖。那么,
他的购物车里包含当当网 80% 的书。所以这个用户对于他所购买书的两两相似度的贡献应该远远小于一个只买了十几本自己喜欢的书的文学青年。
提出一个称为 IUF ( Inverse User Frequence ),即用户活跃度对数的倒数的参数,来修正物品相似度的计算公式。认为活跃用户对物品相似度的贡献应该小于不活跃的用户。
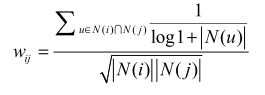
2 兴趣程度
在得到物品相似度之后,ItemCF通过以下公式计算用户u对未产生行为的物品j的感兴趣程度。
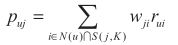
这里的N(u)N(u)是用户喜欢的物品集合,S(j,K)S(j,K)是和物品j最相似的K个物品的集合,wijwij是物品j和i的相似度,ruirui是用户u对物品j的兴趣评分(简单的,如果用户u对物品i有过行为,即可令ruirui=1)
对于已经得到的物品相似度矩阵w,按照以下公式对w进行按列归一化,不仅可以增加推荐的准确度,它还可以提高推荐的覆盖率和多样性。
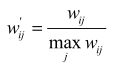
假设物品分为两类—— A 和 B , A 类物品之间的相似度为 0.5 , B 类物品之间的相似度为 0.6 ,而 A 类物品和 B 类物品之间的相似度是 0.2 。在这种情况下,如果一个用户喜欢了 5个 A 类物品和 5 个 B 类物品,用 ItemCF 给他进行推荐,推荐的就都是 B 类物品,因为 B 类物品之间的相似度大。但如果归一化之后, A 类物品之间的相似度变成了 1 , B 类物品之间的相似度也是 1 ,那么这种情况下,用户如果喜欢 5 个 A 类物品和 5 个 B类物品,那么他的推荐列表中 A 类物品和 B 类物品的数目也应该是大致相等的。从这个例子可以看出,相似度的归一化可以提高推荐的多样性。
一般来说,热门的类其类内物品相似度一般比较大。如果不进行归一化,就会推荐比较热门的类里面的物品,而这些物品也是比较热门的。因此,推荐的覆盖率就比较低。相反,如果进行相似度的归一化,则可以提高推荐系统的覆盖率。
3 电影推荐代码
1 生成用户数据集: 用户, 兴趣程度, 物品
{用户i: {物品1:兴趣程度, 物品2:兴趣程度, 物品3:兴趣程度}}
2 物品被多少个用户购买
{物品1: 2, 物品2: 5, 物品3: 1}
物品--物品共现矩阵
{物品1 :{物品2: 2, 物品3: 1},
物品2: {物品1: 2, 物品3: 2, 物品4: 1}
......
}
3 物品相似度矩阵
物品1 : {物品2: (物品1 和 物品2 共现次数 ) / sqrt(物品1出现的次数 * 物品2出现的次数) }
代码说明:
代码中的文件u.data参考上一篇文章。
import math
from texttable import Texttable
import importlib
import sys
class ItemBasedCF:
def __init__(self, train_file):
self.train_file = train_file
self.readData()
"""
读取数据,处理成字典格式
生成用户数据集: 用户, 兴趣程度, 物品
{用户i: {物品1:兴趣程度, 物品2:兴趣程度, 物品3:兴趣程度}}
"""
def readData(self):
self.train = dict()
#print('train_file:', self.train_file)
for line in self.train_file:
#print('type(line):', type(line))
user, score, item = line.strip().split(",")
self.train.setdefault(user, {})
self.train[user][item] = int(float(score))
"""
N: {物品1: 2, 物品2: 5, 物品3: 1}
C: {
物品1 : {物品2: 2, 物品3: 1},
物品2 : {物品1: 2, 物品3: 2, 物品4: 1}
}
"""
def ItemSimilarity(self):
N = dict() #物品被多少个不同用户购买
C = dict() #物品和物品的共现矩阵
for user, items in self.train.items():
#print('user:', user)
#print('item:', items)
for ikey in items.keys(): #ikey: {'a': 1, 'b': 1, 'd': 1}
#print('ikey:', ikey)
N.setdefault(ikey, 0)
N[ikey] += 1
C.setdefault(ikey, {})
for jkey in items.keys(): #物品和物品的共现矩阵 jkey: {'a': 1, 'b': 1, 'd': 1}
if ikey==jkey:
continue
#print('jkey:', jkey)
C[ikey].setdefault(jkey, 0)
#C[ikey][jkey] += 1
C[ikey][jkey] += 1 / math.log( 1+len(items)*1.0 ) #用用户活跃度来修正相似度,len(items)来衡量用户活跃度
#print('N:', N)
#print('C:', C)
#根据N,C计算物品之间的相似度
#根据C得到物品和物品共现的次数,根据N得到物品分别出现的次数
self.W = dict()
self.W_max = dict() #记录每一列的最大值
for ikey, relateij in C.items():
#print('ikey:', ikey)
#print('relateij:', relateij)
self.W.setdefault(ikey, {})
for jkey, Wij in relateij.items():
self.W_max.setdefault(jkey, 0.0) #初始化当列最大值为0
self.W[ikey][jkey] = Wij / ( math.sqrt(N[ikey] * N[jkey]) ) #计算相似度
if self.W[ikey][jkey] > self.W_max[jkey]:
self.W_max[jkey] = self.W[ikey][jkey] #更新列中最大值
#print('jkey:', jkey, 'self.W_max:', self.W_max[jkey])
#归一化处理, Wij / Wij_max
for ikey, relateij in C.items():
for jkey, Wij in relateij.items():
self.W[ikey][jkey] = self.W[ikey][jkey] / self.W_max[jkey]
#for k, v in self.W.items():
#print(k + ':' + str(v))
"""
函数功能:生成推荐列表
函数参数:
@user:需要推荐的用户
@K :取物品相似度矩阵前k物品
@N : 最多推荐N个物品
"""
def Recommend(self, user, K=3, N=10):
rank = dict() #推荐字典
action_item = self.train[user] #获取用户user的物品和评分数据
for item, score in action_item.items(): #item为用户购买的物品,score为评分
for j, Wj in sorted(self.W[item].items(), key=lambda x:x[1], reverse = True)[0:K]: #self.W[item].items()为物品item的相似度矩阵
if j in action_item.keys(): #用户已经购买过的物品,不再推荐
continue
rank.setdefault(j, 0)
rank[j] += (Wj * score) #j为根据相似度推荐的物品,Wj为推荐的物品和用户的物品item的相似度,score为item的评分
return sorted(rank.items(), key=lambda x:[1], reverse = True)[0:N]
def readFile(filename):
contents = []
f = open(filename, "rb")
contents = f.readlines()
f.close()
return contents
def getRatingInfo(ratings):
rates = []
for line in ratings:
rate = line.split("\t".encode(encoding="utf-8"))
rate_str = str(int(rate[0])) +','+ str(int(rate[2])) +',' + str(int(rate[1]))
rates.append(rate_str)
return rates
#获取电影的列表
def getMovieList(filename):
contents = readFile(filename)
movies_info = {} #dict
for movie in contents:
single_info = movie.split("|".encode(encoding="utf-8")) #把当前行按|分隔,保存成list
movies_info[int(single_info[0])] = single_info[1:] #将第0个元素作为key,第二个到最后作为value保存成字典dict返回
return movies_info
#uid_score_bid = ['A,1,a','A,1,b','A,1,d','B,1,b','B,1,c','B,1,e','C,1,c','C,1,d','D,1,b','D,1,c','D,1,d','E,1,a','E,1,d']
#获取所有电影的列表
if __name__ == '__main__':
importlib.reload(sys)
movies = getMovieList("u.item") #movies为dict
#print('movies:', movies)
contents = []
contents = readFile("u.data")
rates = getRatingInfo(contents)
Item = ItemBasedCF(rates)
#print('train:', Item.train)
Item.ItemSimilarity()
recommend_dict = Item.Recommend('50', 5, 20) #k=5, N=20
print('推荐列表:')
recommend_list = []
for k, v in recommend_dict:
print(k + ':' + str(v))
recommend_list.append(int(k))
print(recommend_list)
table = Texttable()
table.set_deco(Texttable.HEADER)
table.set_cols_dtype(['t', 't', 't'])
table.set_cols_align(["l", "l", "l"])
rows=[]
rows.append([u"movie name",u"release", u"from userid"])
for movie_id in recommend_list[:20]:
rows.append([movies[movie_id][0],movies[movie_id][1]," "])
table.add_rows(rows)
print (table.draw()) 运行结果:
movie name release from userid ============================================================= Smilla's Sense of Snow (1997) 14-Mar-1997 Private Parts (1997) 07-Mar-1997 Trees Lounge (1996) 11-Oct-1996 Welcome to the Dollhouse (1995) 24-May-1996 Kansas City (1996) 16-Aug-1996 City Hall (1996) 16-Feb-1996 Chamber, The (1996) 11-Oct-1996 Arrival, The (1996) 31-May-1996 Kama Sutra: A Tale of Love (1996) 07-Mar-1997 Waiting for Guffman (1996) 31-Jan-1997 Daytrippers, The (1996) 21-Mar-1997 Kissed (1996) 18-Apr-1997 City of Lost Children, The (1995) 01-Jan-1995 Swingers (1996) 18-Oct-1996 Mis�rables, Les (1995) 01-Jan-1995 Georgia (1995) 01-Jan-1995 Cry, the Beloved Country (1995) 01-Jan-1995 Street Fighter (1994) 01-Jan-1994 Scarlet Letter, The (1995) 01-Jan-1995 Kolya (1996) 24-Jan-1997
参考文章列表:
《推荐系统实践》——基于物品的协同过滤算法(代码实现)