查询优化器内核剖析之从一个实例看执行计划
学习查询优化器不是我们的目的,而是通过 它,我们掌握 SQL Server 是如何处理我们的 SQL 的,掌握执行计划,掌握为什么产生 I/O 问题, 为什么 CPU 使用老高,为什么你的索引加了不起作用...
如果,我告诉你,你去加个索引,换 SAN 存储,这样意义不大!数据库优化就是这样的: 没有所谓的“绝对手段,一下子把性能搞上去,一切都是看情况而定”,都是通过不断的分析, 抽丝剥解。不带头脑的优化,能好到那里去?
在前几篇文章中,我们已经谈了一些查询优化器的相关的基础介绍,也大致的了解了它到 底是干什么的。查询优化器的结果就是产生执行计划,执行计划就是一个树,这个树由很多的物 理操作组成,而这些物理操作就定义了如何去存储设备中去获取数据。
我们可以以很多的不同的方式,例如图形化,文本,XML 的形式来查看一个给定查询的实 际的执行计划和估计的执行计划。这些不同格式的执行计划的区别主要在于包含的信息的详细程 度不同。
当需要查看一个查询的实际的执行计划的时候,这个查询比较要执行。然而,如果查看估 计的执行计划,此时整个查询是不需要实际执行的。如果查询是个需要消耗很长时间,很多资源 的查询,我们在分析问题的时候,会先查看这个查询估计的执行计划,并且这样做也不会对使用 数据库的其他用户产生影响。
查看实际执行计划和估计的执行计划方式有很多,最简单的方式就是在 SQL Server 管理界 面点击如下按钮:
查看估计的执行计划:

查看实际的执行计划:
 下面,我们就来通过一个简单的示例讲述执行计划,这里采用示例数据库:
下面,我们就来通过一个简单的示例讲述执行计划,这里采用示例数据库:
我们在 SQL Server 中输入以下查询:

然后,点击“Include Actual Execution Plan”按钮,然后执行 SQL 语句,看到如下显示:

在图中,我们可以看到一些物理操作符号以图标显示,例如 Index Scan,Hash Aggregate。 第一个图标称为结果操作符,它返回了查询的结果。
每一个物理的操作符,其实就是存储引擎中实现的一些基本的操作或者方法。例如,一个 逻辑的 join(就是我们在 SQL 写的 inner join 之类的),可以再执行计划中以不同的物理 join 操作 实现(Nested Loops Join, Merge Join, Hash Join)。当然,这里没有所谓的“那种物理操作好,哪 种不好”,得看具体情况。
每个物理操作执行的时候,就会去获取一些数据,然后将数据传递给它下一个物理操作, 知道全部的操作完成,返回结果。在查看执行计划的时候,需要“从右向左,从下到上”进行。
在执行计划中,每个物理操作都有一些“箭头”相连,这些箭头就表明了执行的先后顺序, 并且箭头的粗细也放映了传递数据的多少,越粗就表明数据越多。 我们可以通过把鼠标放在这些 箭头上面,查看更多的信息。如下:
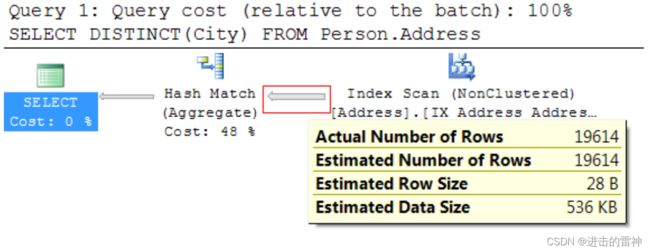
通过查看提示信息,我们可以知道:Index Scan 这个操作读取了 19614 条数据,这些数据 之后被传递给了Hash Aggregate操作。Hash Aggregate执行之后,就将这些数据通过City字段做 了一个 distinct 的处理,将 575 条数据给了下一个操作:

对于执行计划中出现的一些物理操作,一般基本会通过三个方法来实现它们的功能(这里 要把操作和方法的概念搞清楚,可能在很多的编程语言中,一个操作就是一个方法,或者说操作 就是方法,这里的操作和方法和那些不同,一个操作是有几个方法来实现和完成的,为了便于理解, 大家这里就把每一个操作理解为一个类吧):
Open()方法:这个方法初始化一个物理操作 GetRow()方法:这个方法每次都从它的上一个操作中获取一行数据 Close()方法:执行完毕,做一些相关的清理等工作
因为 GetRow()方法每次只能从上一个操作中获取一个数据,那么如果上一个操作传递了很 多的数据,那么这个物理操作就要多次调用上一个操作的 GetRow()方。在上面的例子中,Hash Aggregate 操作只调用一次 Index Scan 的 Open()方法,然后调用 19615 次 Index Scan 的 GetRow()方 法,最后调用一次 Index Scan 的 Close()方法。
其实我们还可以通过这个图形化的执行计划得到更多的信息!为了使得大家更好地消化今 天的知识,余下的内容,下次接着讲述。