【Linux】线程池&读写锁
文章目录
- 线程池
-
- 应用场景
- 线程池原理
- 构造线程池
- 代码实现
- 读写锁
-
- 应用场景
- 读写锁的三种状态
- 读写锁的接口
-
- 初始化接口
- 销毁接口
- 以读模式加锁
- 以写模式加锁
- 解锁接口
- 常见问题
- 乐观锁/悲观锁
-
- 乐观锁
- 悲观锁
- 自旋锁
线程池
应用场景
线程池不仅要提高程序运行效率,还要提高程序处理业务的种类,提高程序运行效率自然要创建多个线程
说到提高业务的种类,应该不难想到switch case语句结合if语句来实现,示例如下:
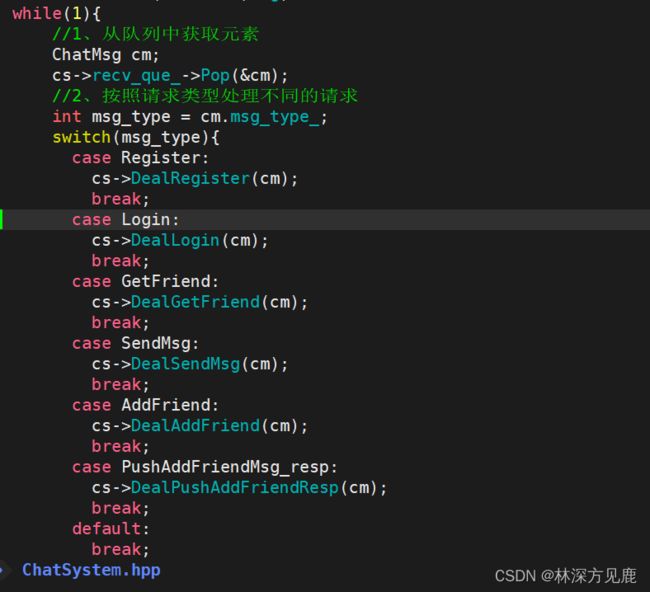
这种实现不同业务的方式比较简单,但是相对也很有局限性,如果业务种类比较多,这种分支语句就不适用了。
一个线程被创建之后,只能执行一个线程入口函数,后续是没有办法更改的,基于这种场景,线程可能执行的代码也就是固定了。换句话说即使线程入口函数当中有很多分支,但是相对来说线程执行的路线都是固定的,要么时A分支,要么时B分支,要么是C分支。这里的分支是指类似if,else语句。这里如果我们要是在后续再想新增加新的业务判断逻辑,那就只能在原有线程入口函数进行增加写代码,这样就会导致一个线程入口函数的代码愈来愈多。那么如果代码的耦合性过高,只要一个地方出现错误,我们查找bug时就会十分头疼。
所以为了能让线程执行不同的业务代码,就要考虑线程从队列中获取元素的身上下功夫。让线程可以通过线程元素来执行不同的代码。
线程池原理
线程池原理 = 一堆线程 + 线程安全的队列
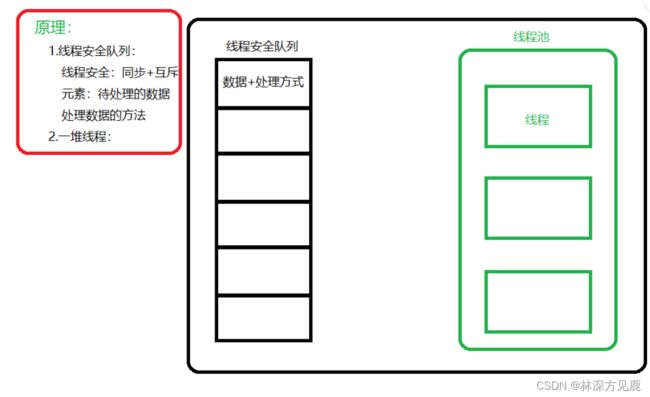
构造线程池
创建固定数量的线程池,循环从任务队列中获取任务对象
获取到任务对象之后执行任务对象的任务接口
代码实现
#include读写锁
应用场景
- 大量读取,少量写的场景
- 允许多个线程并行读,多个线程互斥写
读写锁的三种状态
- 以读模式加锁的状态
- 以写模式加锁的状态
- 不加锁的状态
读写锁的接口
初始化接口
int pthread_rwlock_init(pthread_rwlock_t *restrict rwlock,const pthread_rwlockattr_t *restrict attr)
参数:
- pthread_rwlock_t:读写锁的类型,rwlock:传递读写锁
- attr:NULL,默认属性
销毁接口
int pthread_rwlock_destroy(pthread_rwlock_t *rwlock);
以读模式加锁
int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock);
//阻塞接口
允许多个线程以并行已读模式获取读写锁
引用计数:用来记录当前读写锁有多少个线程以读模式获取了读写锁
1.每当有线程以读模式进行加锁,引用计数++;
2.每当读模式的线程释放锁,引用计数–;
引用计数的作用,当引用计数为0时,那么证明当前没有线程在进行读取操作,那么写的线程就可以获取到这把读写锁进行写。
int pthread_rwlock_tryrdlock(pthread_rwlock_t *rwlock);
//非阻塞接口
以写模式加锁
int pthread_rwlock_trywrlock(pthread_rwlock_t *rwlock);//非阻塞接口
int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock);//阻塞接口
解锁接口
int pthread_rwlock_unlock(pthread_rwlock_t *rwlock);//解锁接口
常见问题
现在如果有线程A和线程B在对一个资源进行读取,此时来了一个线程C要以写的方式获取这把读写锁,然后又来了一个线程D要进行读取,这里问线程C要不要等待线程D也读取完之后再对资源进行写?
这里读写锁的内部是有个机制的:如果读写锁已经在读模式打开了,有一个线程A想要以写模式打开获取读写锁,则需要等待,如果在等待期间,又来了读模式加锁的线程,那读模式的线程要等待写线程先执行完再说,因为如果这时读取的线程可以获取这把锁,读写锁本来就是大量读少量写的使用场景,那么就会导致写的线程一直拿不到这把锁,这是不合理的。线程就会饥饿。
乐观锁/悲观锁
乐观锁
针对某个线程访问临界区修改数据的时候,乐观锁认为只有该线程在修改,大概率不会存在并行的情况,所以修改数据不加锁,但是,在修改完毕,进行更新的时候,进行判断,例如:版本号控制、CAS无锁编程
悲观锁
针对某个线程访问临界区修改数据的时候,都会认为可能有其他线程并行修改的情况发生,所以在线程修改数据之前就进行加锁,让多个线程互斥访问。悲观锁有:互斥锁、读写锁、自旋锁等
自旋锁
自旋锁 (busy-waiting类型) 和互斥锁 (sleep-waiting类型)的区别:
1.自旋锁加锁时,加不到锁,线程不会切换 (时间片没有到的情况,时间片到了,也会线程切换),会持续的尝试拿锁, 直到拿到自旋锁
2.互斥锁加锁时, 加不到锁,线程会切换(时间片没有到,也会切换),进入睡眠状态,当其他线程释放互斥锁(解锁)之后, 被唤醒。在切换回来,进行抢锁
3.自旋锁的优点:因为自旋锁不会引起调用者睡眠,所以自旋锁的效率远高于互斥锁。
4.自旋锁的缺点:自旋锁一直占用着CPU,他在未获得锁的情况下,一直运行(自旋),所以占用着CPU,如果不能在很短的时间内获得锁,这无疑会使CPU效率降低
5.适用于临界区代码较短时(直白的说: 临界区代码执行时间短)的情况, 使用自旋锁效率比较高。因为线程不用来回切换
6.当临界区当中执行时间较长, 自旋锁就不适用了, 因为拿不到锁会占用CPU一直抢占锁。
自旋锁API:
pthread_spin_init:初始化自旋锁
int pthread_spin_init(pthread_spinlock_t *lock, int pshared);
pthread_spin_destroy:销毁自旋锁
int pthread_spin_destroy(pthread_spinlock_t *lock);
pthread_spin_lock:尝试获取自旋锁,如果自旋锁已经被锁定,线程将自旋等待。
int pthread_spin_lock(pthread_spinlock_t *lock);
pthread_spin_trylock:尝试获取自旋锁,如果自旋锁已经被锁定,它不会等待,而是立即返回
int pthread_spin_trylock(pthread_spinlock_t *lock);
pthread_spin_unlock:释放自旋锁,允许其他线程获取它
int pthread_spin_unlock(pthread_spinlock_t *lock);