STDF-Viewer 解析工具说明
一、简介
1. 概述
STDF(Standard Test Data Format)(标准测试数据格式)是半导体测试行业的最主要的数据格式,包含了summary信息和所有测试项的测试结果;是半导体行业芯片测试数据的存储规范。
在半导体行业,每粒芯片在投放市场之前都要经过两道严格的测试,分别是 封装之前的CP测试 和封装之后的FT测试 ,之前(开发STDF之前)不同厂商提供的测试机会生成不同格式的测试结果,这会导致测试结果的转换、分析和存储变的非常困难,STDF规范就是为解决这一问题而诞生的。
它由Teradyne开发,统一了各项测试结果的数据格式,只要测试机供应商支持该规范,那么生成的测试数据就可以很容易的被解析成结构化数据,并保存到数据库,后续的数据分析因此而变得更加容易且全面。
2. 所解决的问题
其采用统一格式/规范保存着CP或FT芯片测试所能产生的所有类型的测试数据,解决了芯片测试行业不同品牌测试机所生成的测试数据格式不统一的问题。
3. STDF规范特点
提供一个通用的格式来保存和转换测试数据,所以可以来保存所有厂商提供的芯片测试机的测试结果
虽然STDF规范了很多 记录/字段 类型,但实际应用时可以根据需要灵活 存or取 其中的一部分
每个STDF文件都是一个独立的数据库,保存着所有类型的测试数据,所以用户只需相应的STDF文件即可对测试结果进行全面的分析
4. 优点
STDF规范采用了统一格式保存所有测试数据,所以通常情况下只需要解析一个STDF文件就可以对芯片测试结果作360°全方位的分析,无论是基于Lot的分析,基于Wafer的分析(CP),还是基于Die的分析,甚至是每个测试项的分析都可以轻松胜任,这便是它的最大优势。
5. 局限性
因为要把所有测试数据都保存在一个文件里,导致文件很大,动辄就几个G,因此在以下方面具有局限性:
规范复杂性、专业性强:
如: 数据效验bit位、半字节数据类型、不定长度的数组、大/小端字节序的区分、衬垫字段等概念还是挺让人难以理解的;此外,它的实际数据是以二进制形式保存到文件中的,即一个STDF实际上会是一个二进制的文件,并非ASCII字符的明文字符,所以无法直接打开查看结果,需要解析后才能看到具体数据。基于上述复杂性,解析它其实相当不容易,开发人员至少得具备测试机工作原理、芯片测试、程序开发这3项专业性相当强的专业技能才能胜任。
存储空间大:
因为文件很大,所以单个文件就需要很大的存储空间,而一般测试企业每天能完成几十个甚至几百个Lot的测试,就是说对于芯片测试企业每天光STDF就能消耗几百G到1T的磁盘空间,而且因为数据是不断生成的,对磁盘的I/O要求也很高,所以对企业的存储服务器要求很高,成本较大。
传输时间长&传输设备要求高:
绝大部分芯片测试企业的客户会要求将STDF文件传给他们,如上文所述,这么大量的数据要通过互联网分别传送给不同客户,往往需要较长的时间,测试企业为了满足客户要求,及时将测试数据传给客户,往往不得不架设多台服务器同时上传,对企业的IT基础设施建设(网络带宽&服务器)要求也很高。
解析速度慢&失败率高:
因为文件很大,所以解析STDF文件的时候速度较慢,且会大量消耗内存(解析后的数据往往也必须先保存在内存中,再转存到数据库或ASCII码文件),所以解析过程往往不太顺利,因为很容易中断。
以上局限性在一定程度上限制了STDF的应用范围,大部分半导体企业往往只能利用他人开发的转换工具解析STDF文件并保存为txt或Excel文件,较难做到系统化的解析测试结果并存储到数据库,也就很难用STDF实现系统化的数据分析。
二、STDF数据介绍
1. 规范介绍
STDF 以二进制字节流的形式保存,包含最多 25 种类型的测试数据(测试程序可能会根据实际情况只写入必要数据,所以并非所有 STDF 文件都会包含 25种类型的测试数据),文件的前 6 个固定字节是 FAR (File Attributes Record.信息,其它24 种类型的测试数据在整个 STDF 文件中的位置和长度都不固定但都以 4个字节的头信息开始,头信息后则是具体的测试数据内容,头信息包括:

2. 测试数据记录分组和类型
如上表所述,STDF 文件中每种类型测试数据开始前的 4 个字节中的第 3 个字节会指定记录类型所属的第一类别信息,即 REC_TYP ;第 4个字节指定记录类型所属的第二类别信息,即 REC SUB,REC TYP 和 REC SUB 组合则形成了测试数据记录在整个 STDF 文件中的唯一类型标识。下面列出 REC_TYP 和REC SUB 的值范围和组合后代表的测试数据记录类型:

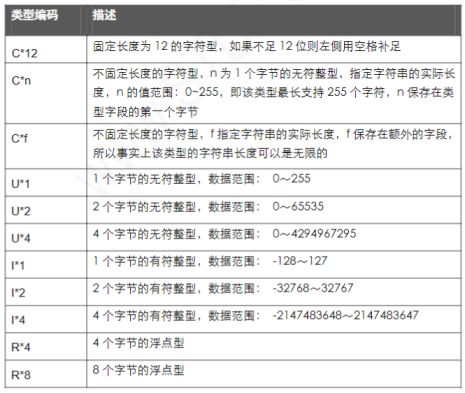
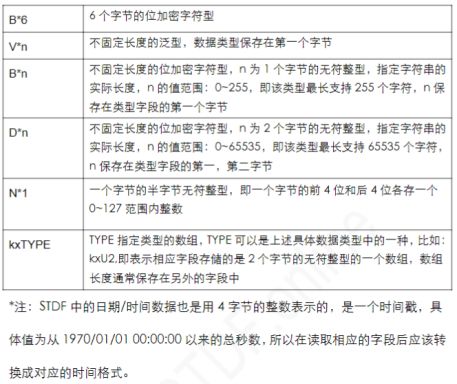
3. 字段值数据类型
STDF 文件中的字段值都有相应的数据类型,用以区分是数字型的数据还是字符型的数据,下面是 STDF 支持的常用数据类型:
4. 数据的存储字节序
因为所有数据在 STDF 中都是以二进制的形式存储的,所以需要关注大/小端字节序的问题,即这些数据在存储器中是按照从最低有效字节到最高有效字节的顺序存储对象,还是从最高有效字节到最低有效字节的顺序存储对象,前者称为小端字节序法,后者则为大端字节序法,我们读取或解析的 STDF 文件的时候必须明确知道其排序方法,否则会导致读取的数字型数据完全混乱。
STDF 文件的字节序和生成该文件的主机 CPU 有关,无法人工干涉,采用何种字节序的标识保存在 STDF 文件的第 5 个字节,是 File Attributes Record(FAR)的一个字段,一般值为 0,1或2 ,1 表示大端字节序,0/2 表示小端字节序。根据 STDF 的规范,该字段的命名为: CPU TYPE,所以我们解析 STDF文件时必须首先读取该字段值,确定好字节序后再解析后续二进制流。
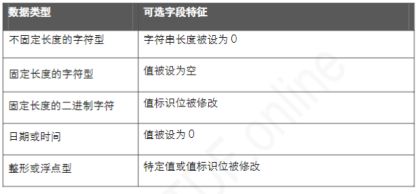
5. 可选字段和默认值
STDF 中不是每个字段都必须有一个值,有些字段在生成的时候是可以忽略的,即不用填入相应的值,这些字段本身可能会自动填入一个默认值,比如: 对一些字符型的数据,默认值是空,对一些数字型的数据,默认值则是 1或 0。另外有一些字段虽然有值,但可能是无效的,STDF 通常会某字节中设一个或多个标识位(bl]来区分字段值是否有效,通常情况下字段的值若是合法且有效的,那么对应标识位的值会是默认值 0(二进制的 0),即标识位的值是不会被改动,反过来说,如果标识为被改为 1 (二进制的 1) ,那么意味着对应字段的值就是无效的。
以上所述的两种类型的字段在 STDF 规范中被统称为可选字段,为了节约STDF文件的存储空间,如果这两种可选字段出现在记录的尾部,那么在生成STDF文件的时候就有可能会被 STDF 直接省略,当然仅限于这些字段连续排在记录的尾部,若在其它位置出现,则不会被省略。下表列出STDF中各种数据类型的字段值在何种情况下可被认为是可选字段: