YMatrix 5.0 故障自动转移功能新实现,运维更方便!
前言
分布式数据库一般都实现了数据多副本的存储以保证数据的高可用性。在多副本存储的基础上,通过切换活跃的存储副本来实现故障转移,是常见的做法。
YMatrix 5.0 实现了在数据库集群所有数据分片上的故障自动转移,完全实现了数据库集群的故障自动转移功能。这使得数据库运维操作自动化程度更高,数据库管理员的手工操作更少,为数据库运维提供了更多的便利。
作者:数据库内核研发工程师 杨旭东

Greenplum 故障自动转移功能的实现
1.1 数据分片和故障转移
YMatrix 5.0 的存储分布式设计来源于 Greenplum。这种设计通过将用户数据按照一定的分布规则(如哈希分布,随机分布等)分片并将其存储到相应的 PostgreSQL 数据库实例中实现了其分布式的功能,又通过为分片对应的 PostgreSQL 数据库实例设置使用流复制方式备份的 PostgreSQL 后备实例这一方法实现了数据的多副本存储。
-
数据分片

-
PostgreSQL 流复制到后备实例

当活跃的 PostgreSQL 数据库实例出现故障时,通过切换到其对应的 PostgreSQL 后备实例的方式实现了故障转移。
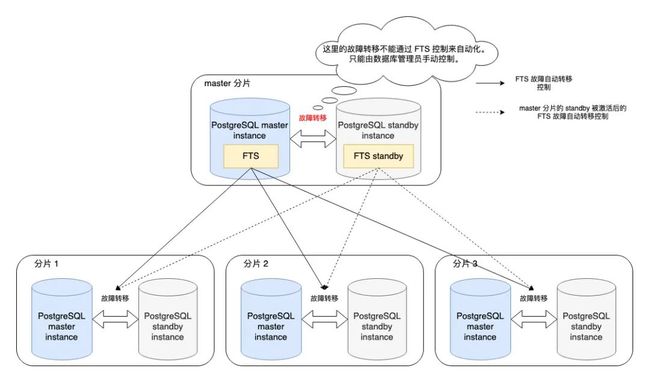
1.2 数据元信息分片 master 和 FTS
在 Greenplum 的实现中,在用户数据之外,设置了一个新的用于存储数据元信息的分片 master 用以管理整个数据库集群。在存储 master 数据的 PostgreSQL 数据库实例中添加了 FTS (Fault Tolerent Server) 服务来存储和管理整个数据库集群的所有 PostgreSQL 数据库实例的运行状态,实现了所有存储用户数据分片的 PostgreSQL 数据库实例的故障自动转移。

虽然 master 数据库实例同样可以设置一个 PostgreSQL 后备实例 ( standby ) 来实现该数据分片的数据多副本存储(其中同样包含一个后备的 FTS 服务),但是由于 FTS 服务是 master 数据库实例的一部分,它并不能提供本身数据分片的故障自动转移。当 master 的 PostgreSQL 数据库实例因为故障而不能工作时,需要数据库管理员手动通过 gpactivatestandby 命令激活其后备实例来实现该数据分片的故障转移。

YMatrix 5.0 故障自动转移功能的实现
YMatrix 5.0 彻底移除了 FTS 的实现,并引入了新的数据库集群组件 (etcd 和集群状态管理组件,包括 cluster 服务、shard 服务、replication 服务等) 来实现完全的故障自动转移功能。

2.1 高可用存储 etcd
YMatrix 5.0 引入了 etcd 组件用来存储和管理集群的定义和状态等关键信息,实现了这些信息的高可靠性和强一致性。关于 etcd 的详细信息,请参见其文档。
2.2 集群状态管理服务
YMatrix 5.0 用新的集群状态管理服务替换了 Greenplum 的 FTS 服务功能。这些服务不再属于 PostgreSQL 数据库实例,而是单独实现的服务组件。同时这些服务也实现了多副本的高可用机制,以防止单个服务实例异常停止引起数据库集群不可用。
2.3 用 etcd 来存储和管理 postgresql 数据库实例运行状态
在引入 etcd 后,原来由 FTS 管理并存储在 master 数据分片中的整个集群的 PostgreSQL 实例的运行状态信息被集群状态管理服务管理并存储在 etcd 数据库中。 master 数据分片中使用的这些状态信息改为从 etcd 中读取。
这样的改动使得包括 master 数据分片在内的所有 PostgreSQL 数据库实例状态信息都从 master 数据分片移除。集群状态管理服务可以实现 master 和 standby 所在数据分片的故障自动转移。
2.4 数据库客户端连接的故障自动转移
用户的数据库客户端(管理终端或者数据库应用等)要使用 YMatrix 5.0 的故障自动转移功能,需要配置客户端连接字符串同时包含 master 和 standby 的主机信息。详情请参见 YMatrix 5.0 的文档。

验证 YMatrix 5.0 新的故障自动转移功能的正确性
为了验证 YMatrix 5.0 完全实现了故障自动转移功能,研发团队基于混沌工程原则设计并实现了一整套自动化的测试来验证 YMatrix 5.0 数据库集群的故障自动转移和故障恢复行为。
这一套测试包括了如下内容:
3.1 设置稳态:
被测试的数据库集群被配置为完全高可用的集群,同时加上一定的工作负载。数据库集群在此状态下的稳定工作行为被认为是稳态。
3.2 模拟各种各样的故障:
-
数据库集群内的任意组件(etcd 实例、集群状态管理服务实例、 PostgreSQL 数据库实例等)被杀死或崩溃;
-
运行数据库集群的服务器机器集群的任意机器崩溃或断电;
-
数据库集群所在的网络出现网络分区等故障。
3.3 持续的自动运行:
-
数据库集群在被随机注入各种模拟故障之后,能够进行故障自动转移并能够保持对外服务的状态;
-
在监测到数据库的故障自动转移行为后,保持模拟故障发生状态一段时间后使模拟故障恢复。之后再使用 YMatrix 5.0 的恢复工具恢复数据库集群状态至完全高可用。
在正式发布 YMatrix 5.0 之前,研发团队对用预发布版本部署的数据库集群进行了持续两周,超过 1200 次故障注入的测试。该集群保持了持续服务可用的状态直到测试结束。这样的持续测试结果验证了 YMatrix 5.0 的故障自动转移功能能够保证数据库集群在一些组件遇到故障时能持续对外服务的高可用性。

Master 数据分片故障自动转移的演示
下面展示在一个 YMatrix 5.0 数据库集群运行过程中,当 master 数据分片的 PostgreSQL 数据库实例出现故障异常终止时,该集群依然能正常服务的例子。
4.1 用于演示的集群信息
这个展示的数据库集群运行在 AWS 上,其各个主机状态如下
4.1.1 Master
-
所在主机: 10.0.138.11
-
监听端口: 5432
4.1.2 Standby
-
所在主机: 10.0.65.204
-
监听端口: 5432
4.1.3 4 个数据分片主机,每个主机上运行一个数据分片的 primary 实例和另一个数据分片的 mirror 实例。
-
10.0.165.185
-
10.0.163.92
-
10.0.74.8
-
10.0.111.252
其 gp_segment_configuration 表的内容如下:
postgres=# select * from gp_segment_configuration order by content, dbid;
dbid | content | role | preferred_role | mode | status | port | hostname | address | datadir
------+---------+------+----------------+------+--------+------+-------------------------------------------------+-------------------------------------------------+----------------------------------------
1 | -1 | p | p | s | u | 5432 | ip-10-0-138-111.cn-northwest-1.compute.internal | ip-10-0-138-111.cn-northwest-1.compute.internal | /mxdata_20230419053537/master/mxseg-1
10 | -1 | m | m | s | u | 5432 | ip-10-0-65-204.cn-northwest-1.compute.internal | ip-10-0-65-204.cn-northwest-1.compute.internal | /mxdata_20230419053537/standby/mxseg-1
4 | 0 | p | p | s | u | 6000 | ip-10-0-74-8.cn-northwest-1.compute.internal | ip-10-0-74-8.cn-northwest-1.compute.internal | /mxdata_20230419053537/primary/mxseg0
8 | 0 | m | m | s | u | 7000 | ip-10-0-163-92.cn-northwest-1.compute.internal | ip-10-0-163-92.cn-northwest-1.compute.internal | /mxdata_20230419053537/mirror/mxseg0
5 | 1 | p | p | s | u | 6000 | ip-10-0-111-252.cn-northwest-1.compute.internal | ip-10-0-111-252.cn-northwest-1.compute.internal | /mxdata_20230419053537/primary/mxseg1
9 | 1 | m | m | s | u | 7000 | ip-10-0-165-185.cn-northwest-1.compute.internal | ip-10-0-165-185.cn-northwest-1.compute.internal | /mxdata_20230419053537/mirror/mxseg1
3 | 2 | p | p | s | u | 6000 | ip-10-0-163-92.cn-northwest-1.compute.internal | ip-10-0-163-92.cn-northwest-1.compute.internal | /mxdata_20230419053537/primary/mxseg2
7 | 2 | m | m | s | u | 7000 | ip-10-0-74-8.cn-northwest-1.compute.internal | ip-10-0-74-8.cn-northwest-1.compute.internal | /mxdata_20230419053537/mirror/mxseg2
2 | 3 | p | p | s | u | 6000 | ip-10-0-165-185.cn-northwest-1.compute.internal | ip-10-0-165-185.cn-northwest-1.compute.internal | /mxdata_20230419053537/primary/mxseg3
6 | 3 | m | m | s | u | 7000 | ip-10-0-111-252.cn-northwest-1.compute.internal | ip-10-0-111-252.cn-northwest-1.compute.internal | /mxdata_20230419053537/mirror/mxseg3
(10 rows)4.2 演示过程
用 psql 使用连接多个主机的连接字符串连接到数据库集群,并持续(间隔 1 秒)向一个表中插入一行数据。
-
表的定义如下:
CREATE TABLE demo_auto_failover(
insert_id SERIAL PRIMARY KEY, -- 表的主键
ts TIMESTAMP WITH TIME ZONE, -- 插入该行的时间戳
connected_host INET -- 当前 psql 连接的数据库实例主机的 IP 地址
) DISTRIBUTED BY (insert_id);-
插入的 SQL 如下:
INSERT INTO demo_auto_failover(ts, connected_host) SELECT now() AS ts, inet_server_addr() AS connected_host;在使用 psql 持续插入数据的同时,将 master 的 PostgreSQL 实例杀死, YMatrix 5.0 数据库集群会发生 master 故障自动转移,psql 插入数据的连接会自动切换 standby 上。会观察到 demo_auto_failover 表中 connected_host 列的值在发生故障自动转移时从 master 所在主机的 IP 地址变成了 standby 主机的 IP 地址。这表明故障自动转移已经成功完成, standby 接替了 master 提供数据库集群对客户端的服务。
4.3 演示中用于持续插入数据的 expect 脚本
https://pastebin.com/u94NYCcL
4.4 演示视频

结论和展望
关于 YMatrix 5.0 的故障自动转移和恢复的功能介绍,请参见 YMatrix 5.0 的文档。在 5.0 的实现中,发生故障自动转移之后的数据库集群虽然依旧能对外提供服务,但仍需要数据库管理员在合适的时机使用 mxrecover 工具对数据库进行恢复,以使其重新进入高可用的状态。未来我们的研发团队将继续优化产品,提供更多自动化的故障恢复功能,进一步减轻数据库管理员手工运维的负担。
本文为 YMatrix 原创内容,未经允许不得转载。
欲了解更多超融合时序数据库相关信息,请访问 “YMatrix 超融合数据库” 官方网站