MSST-NET:用于高光谱和多光谱图像融合的多尺度空间-光谱Transfomer网络
1.网络结构

主要贡献:
- 提出了一种多尺度空间光谱Transformer网络
- 光谱多头注意力旨在提取光谱特征
- 引入多尺度波段/补丁嵌入来提取多尺度特征
- 自监督训练
痛点:卷积核的感受野有限,基于卷积神经网络CNN的融合方法无法利用特征图中的全局关系。
方法:该文利用Transformer从整个特征图中提取全局信息进行融合的强大能力,提出一种新型多尺度空间光谱Transformer网络(MSST-Net)。
该网络是一个双分支网络,分别从HSI中提取光谱特征,从MSI中提取空间特征。
在特征提取之前,执行跨模态串联以实现两个分支之间的跨模态信息交互。然后,我们提出一种光谱变压器(SpeT)来提取光谱特征,并引入多尺度带/补丁嵌入,通过SpeT和空间变压器(SpaT)获得多尺度特征。为了进一步提高网络的性能和泛化,我们提出了一种自监督预训练策略,其中专门设计了掩码带自动编码器(MBAE)和掩蔽补丁自动编码器(MPAE),用于SpeTs和SpaT的自监督预训练。
两个浅层特征提取模块
- 一个卷积层,用于提取浅层特征
两种深层特征提取模块
- 光谱特征提取
- 空间特征提取
一个图像重建模块
- 两个卷积层
- GELU激活函数·
2. 具体模块


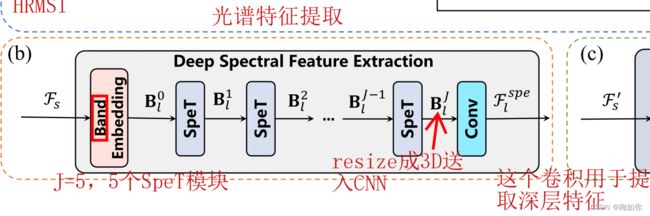
B l 0 B_l^0 Bl0代表第 l l l层第0个,维度是 D s p e D_{spe} Dspexc 这个 c = 16 ∗ 2 l − 1 c=16*2^{l-1} c=16∗2l−1, D s p e D_{spe} Dspe=32
文章设定层数为3层, l = 1 , 2 , 3 l=1,2,3 l=1,2,3


P l 0 P_l^0 Pl0维度为 N ∗ D s p a , p = 8 ∗ 2 l − 1 N*D_{spa},p=8*2^{l-1} N∗Dspa,p=8∗2l−1,p是每个patch的大小, N = H ∗ W P 2 N=\frac{H*W}{P^2} N=P2H∗W , D s p a D_{spa} Dspa=256
3.数据集


LRHSI:采用wald’s协议,对CAVE、Havard、WDCM数据集采用高斯滤波+下采样,比例因子4和8
HRMSI:CANE和Harvard数据,3波段,采用NikonD700光谱响应矩阵
WDCM数据集,10波段,采用哨兵-2 A的光谱响应矩阵生成
对于真实数据集YRE,我们将观测到的HSI和MSI降采样为3后生成训练样本。原来的HSI被当做真实值。训练后,我们将原始HSI和MSI融合,使用训练后的模型估计HR-HSI。
4.训练设置
4.1.自监督训练
从零开始训练网络需要大量的时间和数据。因此,我们希望该网络能够得到更好的初始化训练。换句话说,我们需要一个预训练网络,在下次执行类似任务时能快速获得更好的结果。一般来说,训练前学习可以分为有监督学习和无监督学习。自监督学习是有监督学习和无监督学习之间的一种中间形式。它在训练前阶段使用未标记的数据集,并在各种应用中产生了有希望的结果。因此,我们以一种自我监督学习的方式对我们的模型进行了预训练。
本来MAE是非对称的,本文改了一下改成对称的
本文采用对称编码器-解码器结构的MAE
Masked patches autoencoder :MPAE
the masking ratiois 50%
Masked bands autoencoder :MBAE
the masking ratios of the LR-HSIs to 75%
4.2.微调
微调的目的是将预训练好的模型应用于后续的图像融合任务中。我们首先使用预先训练过的编码器来更新我们的网络的参数,然后对整个网络进行端到端微调。使用比训练前更大的补丁进行微调通常是更有益的。为了进一步提高预训练的变压器编码器提取LR-HSI的光谱特征和HR-MSI的空间特征的能力,我们使用比预训练尺寸更大的补丁进行端到端微调。

我们首先将hr - msi输入到MPAE中,将lr - hsi输入到MBAE中进行自监督预训练,然后将两个预训练好的编码器的参数加载到所提出的网络中进行端到端微调
CAVE预训练之后,在CAVE和Harvard上微调, 在harvard数据集上的实验可以看做对网络泛化能力的一个测试
参数设置:
优化器选用AdamW

学习率:CAVE:1.0e-3和Harvard:1.0e-4
batch size:32
epoch:5000
在预训练中,将训练集的HR-MSIs裁剪成大小为128×128像素的patches,从而将训练集的LR-HSIs裁剪成大小为128/×128/像素的patches,其中为降采样比(4/8)。
在端到端微调中,HR-MSIs被裁剪成大小为192×192像素的patches,LR-HSIs被裁剪成大小为192/×192/像素的patches。
4.3与其他方法比较
为了有效地评价该方法的性能,我们引入了7种最先进的融合方法进行比较,包括两种传统方法,即FUSE [8]和CNMF [24],四种基于cnn的方法,即.,DBIN[66],MHF-Net[32],UAL[38]和SSR-NET [14],以及一种新提出的基于变压器的方法,融合器[54]。在不同的比较方法中的参数是根据作者的代码或参考文献中的建议来设置的。这两种传统方法在MATLAB(R2013a)服务器2012上进行测试,使用两个Intel Xeon E5-2650处理器和128GB内存,基于深度学习的方法由Pytorch 1.10.0在Python 3.7上使用NVIDIA A40的GPU。
5.结果


来自文章:Multiscale spatial–spectral transformer network for hyperspectral and multispectral image fusion