森林生物量(蓄积量)估算全流程
森林生物量(蓄积量)估算全流程
- 一.哨兵2号获取/去云处理/提取参数
-
- 1.1SNAP软件下载
- 1.2 哨兵2号数据下载
- 1.3 哨兵2号预处理1C转2A
- 1.4利用Fmask算法生成云掩膜
- 1.5 SNAP软件中去云操作
- 1.6计算生物物理变量
- 1.7采用gdal计算各类植被指数
- 1.8纹理特征参数提取
- 二.哨兵1号获取/处理/提取数据
-
- 2.1 哨兵1号数据下载与预处理
- 2.2 S1纹理特征参数提取
- 三、DEM数据
-
- 3.1 数据下载
- 3.2 数据处理
- 四、样本生物量计算
- 五、样本变量选取
- 六、基于python随机森林模型反演森林生物量
-
- 6.1筛选变量相关性分析(可选)
- 6.2导入库与变量准备
- 6.3 选取参数
- 6.4 误差分布直方图
- 6.5 变量重要性可视化展示
- 6.6 对精度进行验证
- 6.7 预测生物量
- 七、生物量制图
-
- 7.1 提取森林掩膜区域
- 八. 需要注意的点
一.哨兵2号获取/去云处理/提取参数
1.1SNAP软件下载
-
SNAP安装
SNAP下载地址: http://step.esa.int/main/download/
SNAP安装:按照默认选项安装即可
1.2 哨兵2号数据下载
ntinel-2 是欧盟委员会和欧洲航天局共同完成的一种宽幅、高分辨率、多光谱成像对地观测任务。该观测任务由 Sentinel-2A 和 Sentinel-2B 双卫星组成,双星的重放周期为 5 天,分别于于 2015 年和 2017 年成功发射。该系列卫星搭载了具有 13 个光谱波段的多光谱成像仪(MSI),其中蓝、绿、红以及近红外波段的空间分辨率为 10 m(蓝:490 nm,绿:560 nm 红:665 nm, 近红外:842 nm),红边波段、窄近红外波段和短波红外波段的空间分辨率为 20 m(红边 1:705 nm, 红边 2:740 nm,红边 3:783 nm,窄近红外:865 nm,短波红外 1:1610 nm 和 短波红外 2:2190 nm),海岸带气溶胶、水蒸汽和短波红外-卷云波段的空间分辨率为 60 m(海岸带气溶胶:443 nm,水蒸汽:940 nm 和短波红外_卷云:1375 nm)。本文主要采用了空间分辨率为 10 m 和20 m 波段影像作为研究数据,该数据通过哥白尼科学数据中心(CSDB)https://scihub.copernicus.eu/ 免费获取。
下载链接
第一次使用需要先注册,点击右上方小人进行注册
-
切换地图模式,选择感兴趣区域
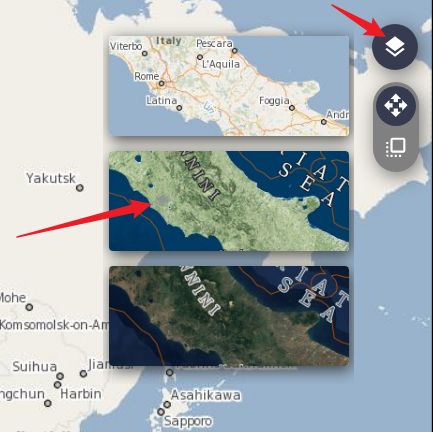
-
切换模式,点击鼠标左键勾选研究区

确定研究区也是点鼠标左键

-
点击搜索栏最左侧三条横的符号,弹出下面的对话框
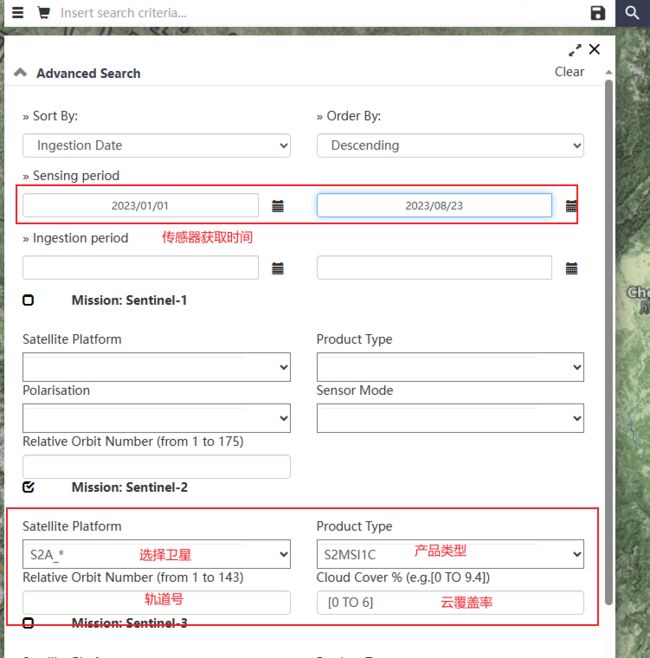
-
在sensing period中设置影像的时间范围
-
点击搜索按钮
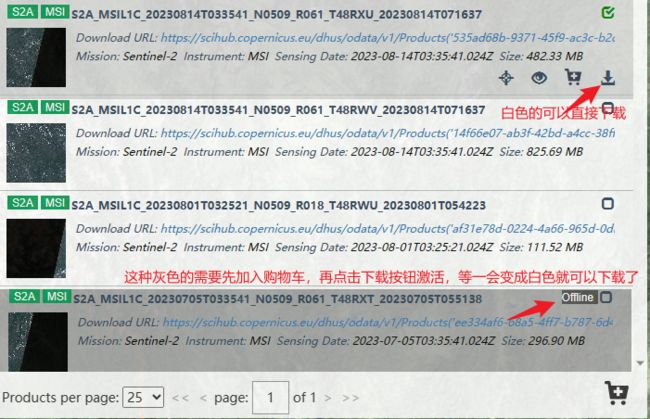
1.3 哨兵2号预处理1C转2A
参考链接:https://blog.csdn.net/qq_36327475/article/details/120476284
- Sen2cor插件下载
网址:http://step.esa.int/main/snap-supported-plugins/sen2cor/ - Sen2cor安装
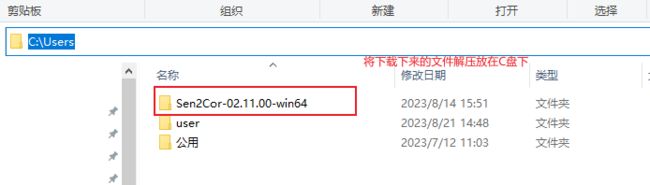
进入文件夹内
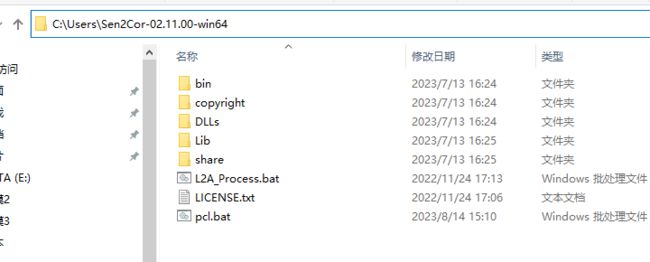
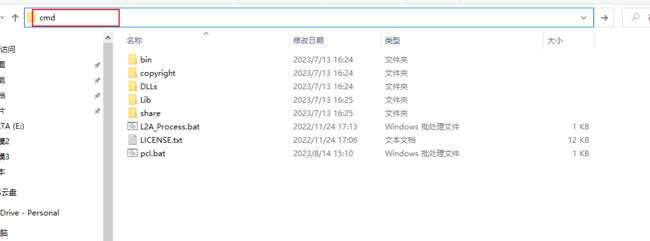
上方输入cmd,按下回车键,打开命令行如下
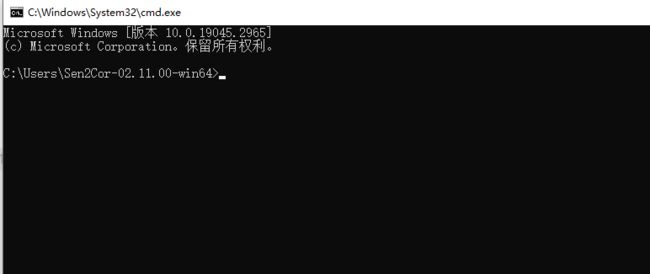
输入:L2A_Process --help,出现以下窗口则显示成功:
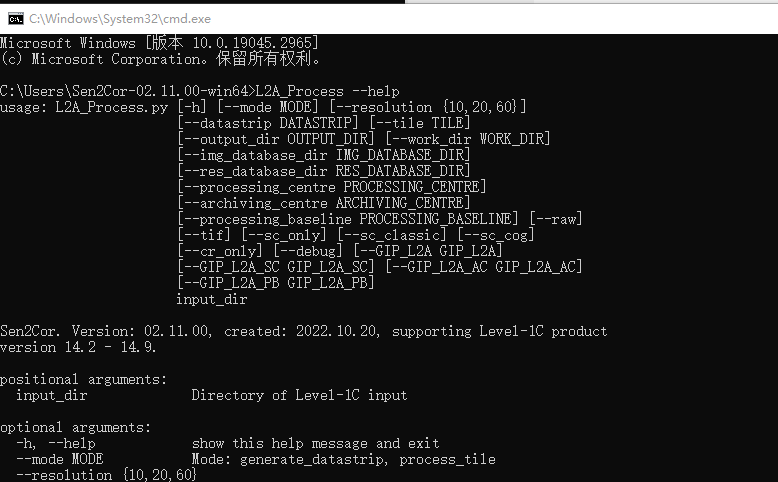
- 哨兵2号的批处理命令如下
for /D %s in (E:\S2\1C\2A\NEW\S2A_MSIL1C*) do L2A_Process %s --resolution=10
for /D %s in (E:\S2\1C\2B\new2\S2B_MSIL1C*) do L2A_Process %s --resolution=10
E:\S2\1C\2A\NEW这个路径需要更换成自己存放哨兵2号影像1C级影像的路径
S2A和S2B需要分开处理
输入命令行,我们先处理S2B星1C级产品

处理完之后,会在文件夹下生成对应的2A级产品
1.4利用Fmask算法生成云掩膜
-
Fmask算法简介看这里
-
下载软件
-
软件下载,链接到github地址

我下载的是4.5版本,按照默认选项安装即可。
双击打开软件(需要等一会),长这样
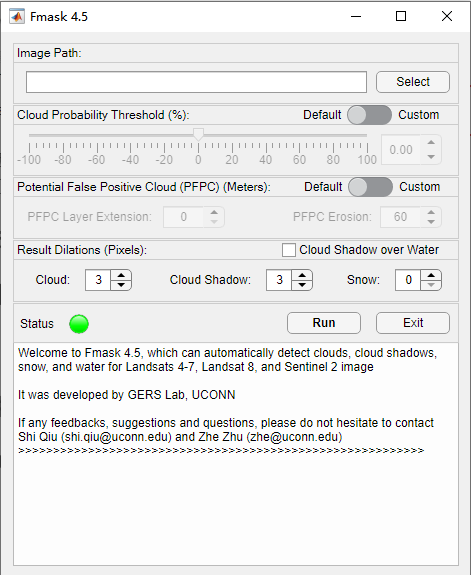
点击select按钮
路径选择E:\S2\S2A_MSIL1C_20220806T032531_N0400_R018_T49RBQ_20220806T054540\S2A_MSIL1C_20220806T032531_N0400_R018_T49RBQ_20220806T054540.SAFE\GRANULE\L1C_T49RBQ_A037195_20220806T033824
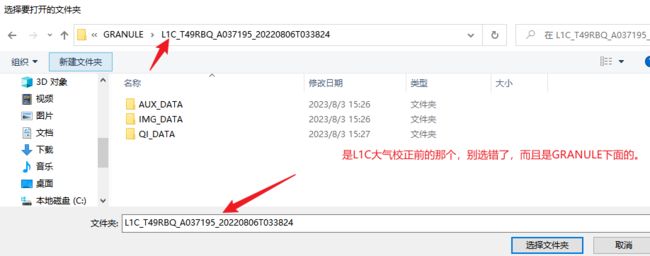
点击run
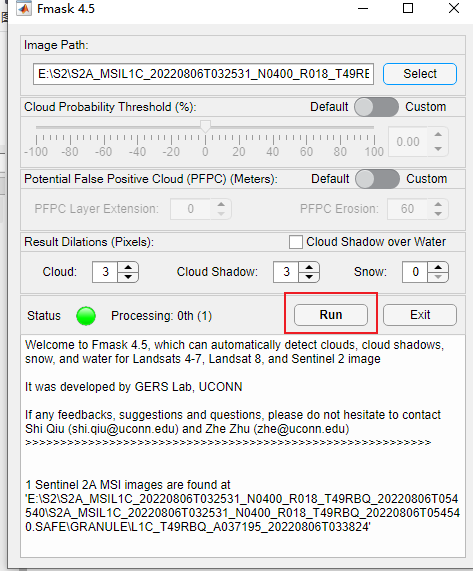
状态会发生变化

当然也可以采用python实现,详见这个链接
Python会运行快一些,但是生成的是.img格式,转成tif好像多了些奇怪的值。故还是用软件吧!哪个简单用哪个
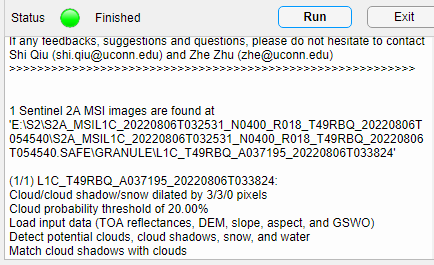
显示finished表示运行完毕
可以看到里面多了一个t文件夹,里面是Fmask.tif文件。
DN值所代表的含义如下:
0 => clear land pixel
1 => clear water pixel
2 => cloud shadow
3 => snow
4 => cloud
255 => no observation
运行完之后,我们会得到一个tif文件,因为我们只需要云掩膜也就是保留0和1的像元(纯净的陆地像素与纯净的水像素),其他和云相关的像元删掉,也就是将云所在的像素去掉。这里采用python实现,代码如下:
python环境,建议安装anaconda3
注意需要有gdal库,推荐本地安装,安去下载whl文件,然后转到放置whl文件的目录下,pip install 即可
这里不会可以看这篇文章。
我下载了python3.9版本
已上传到网盘
链接:https://pan.baidu.com/s/1QU0sqfXtdtaTEtwmyQ-Y0w?pwd=0xfs
提取码:0xfs
![]()
from osgeo import gdal, ogr, osr
import os
import datetime
path = r"L1C_T49RBP_A033220_20230717T033409_Fmask4.tif"#这个tif文件名是我们刚刚生成的那个掩膜tif文件
#文件路径可以自己更改,注意,路径名别太长,太长会报错
if __name__ == '__main__':
start_time = datetime.datetime.now()
inraster = gdal.Open(path)
inband = inraster.GetRasterBand(1)
prj = osr.SpatialReference()
prj.ImportFromWkt(inraster.GetProjection())
outshp ="E:\S2_2023\cloud_mask\shp\SBR0722.shp"#这个输出shp文件即是我们需要的云掩膜文件
#文件路径可以自己更改
drv = ogr.GetDriverByName("ESRI Shapefile")
if os.path.exists(outshp):
drv.DeleteDataSource(outshp)
polygon = drv.CreateDataSource(outshp)
poly_layer = polygon.CreateLayer(path[:-4], srs=prj, geom_type=ogr.wkbMultiPolygon)
newfield = ogr.FieldDefn('value', ogr.OFTReal)
poly_layer.CreateField(newfield)
gdal.Polygonize(inband, None, poly_layer, 0)
polygon.SyncToDisk()
polygon = None
# 打开生成的 Shapefile 文件
shp_datasource = ogr.Open(outshp, 1)
shp_layer = shp_datasource.GetLayer()
# 遍历要素并删除 value 不为 0 或 1 的要素
shp_layer_def = shp_layer.GetLayerDefn()
delete_indices = []
for i in range(shp_layer.GetFeatureCount()):
feature = shp_layer.GetFeature(i)
value = feature.GetField("value")
if value != 0 and value != 1:
delete_indices.append(i)
feature = None
# 从后往前删除要素,避免索引错位
for idx in reversed(delete_indices):
shp_layer.DeleteFeature(idx)
# 重新同步文件
shp_layer.ResetReading()
shp_datasource.SyncToDisk()
end_time = datetime.datetime.now()
print("Succeeded at", end_time)
print("Elapsed time:", end_time - start_time)
outshp =“E:\S2_2023\cloud_mask\shp\SBR0722.shp”
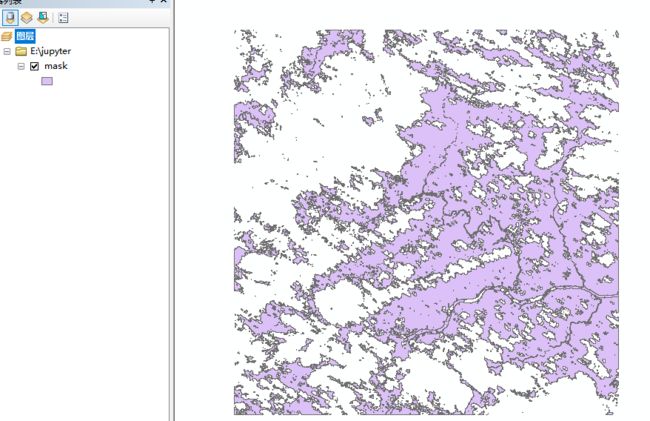
运行完这段代码后会在指定路径下得到一个掩膜文件,用ArcGIS打开长这样,1值代表有效像素
1.5 SNAP软件中去云操作
-
打开SNAP软件
-
打开2A级产品
先重采样到你想要的分辨率,这里我们选择B2波段10m.

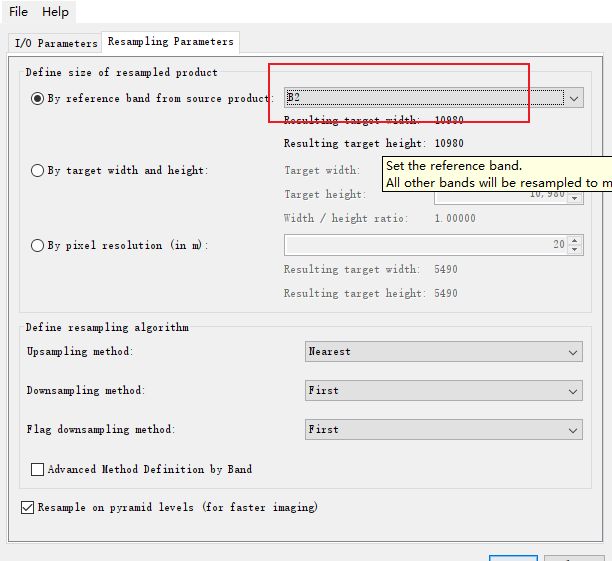
-
导入我们在第1.4节生成的云掩膜文件
这时候就要进行我们的掩膜操作了(有什么疑问的去看官方文档,点一下“帮助”认真读一下)
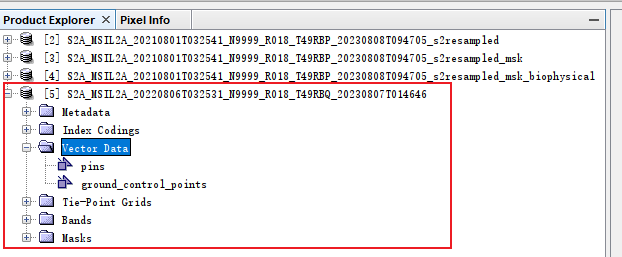
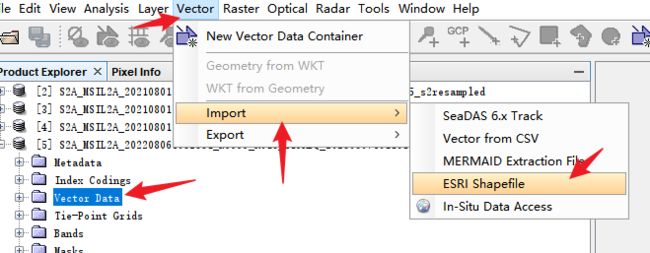
找到vector Data文件夹,选中之后点击上方菜单栏Vector- import - shp
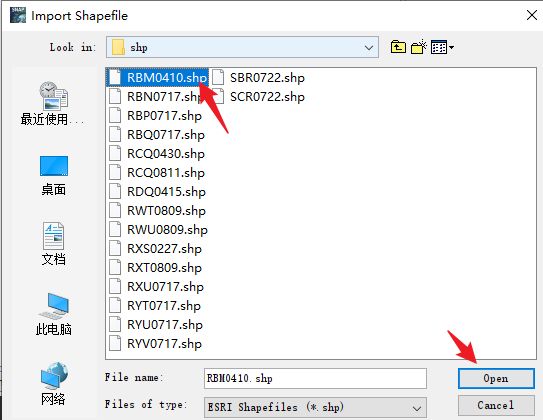
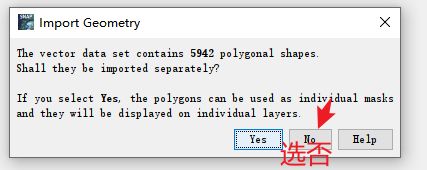
记得这里选否不然每个多边形都生成一个文件
选中后需要等它加载一会
可以看导在Vector Data下面和Masks下面多了一个mask

双击打开可以看到它的属性值,1代表有效像素,0代表无效像素,我们需要抠掉的像素
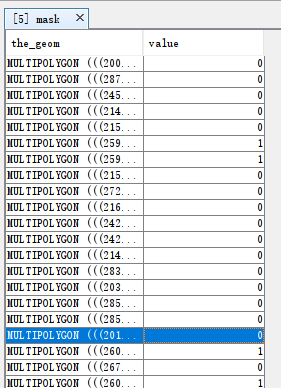
将图像以RGB真彩色显示

点击右侧layer manager工具
选中Masks下面刚刚导入的shp文件, 看看效果,mask是否完全覆盖了云
然后进行掩膜操作,就是把有云的地方抠掉,然后再进行后续的镶嵌操作补上来。
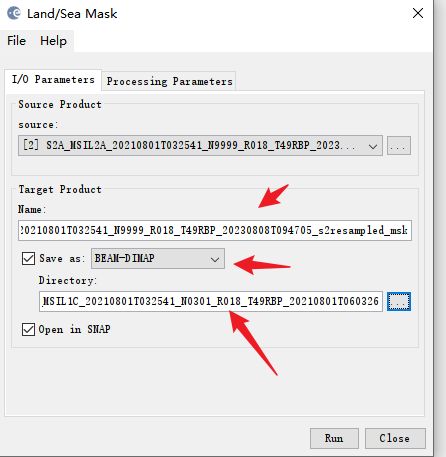
- 掩膜操作

输入输出参数,选好路径即可
处理参数选择使用矢量掩膜,拉到最后选择我们之前用Python生成的那个shp文件
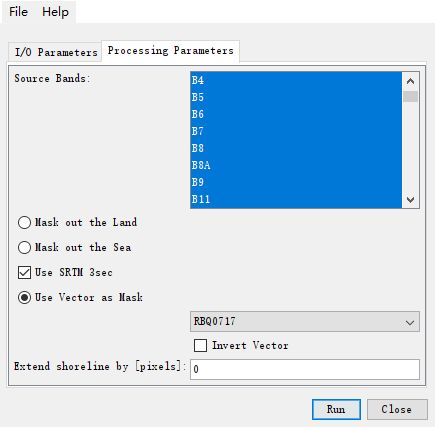
选择B1-B12,12个波段和下图这四个波段,共16个波段,这是后面提取生物物理变量必须的波段
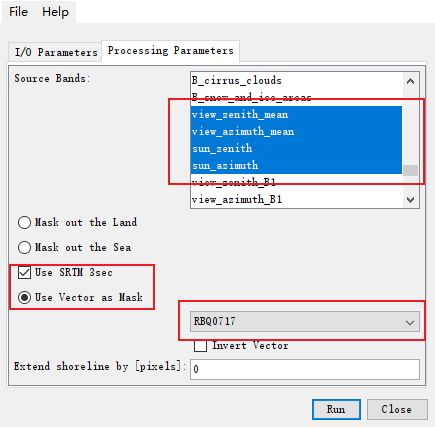
选择导入的掩膜文件,点击run运行即可。
可以看到掩膜之后相当于把云抠掉了
然后再选取同一传感器,同一地点,相近时间的影像在SNAP软件中做同样的处理 - 镶嵌操作
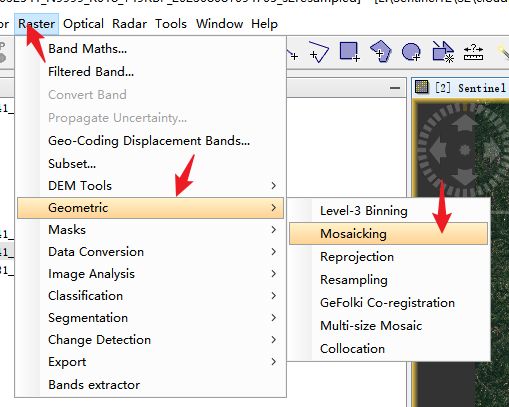
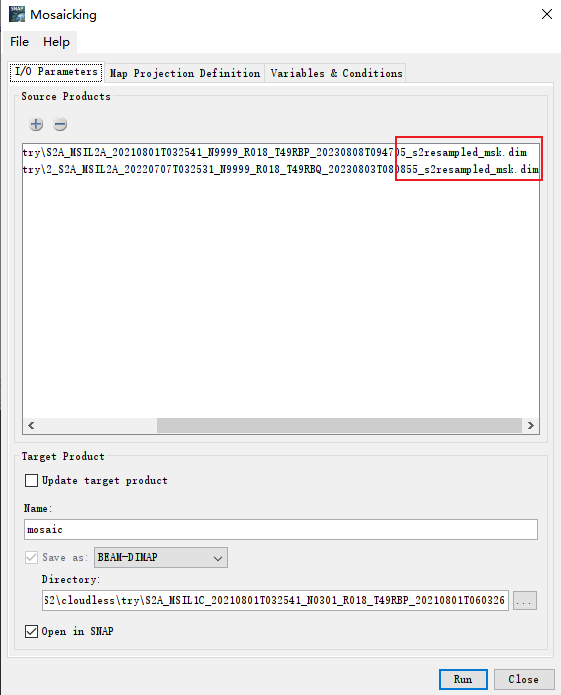
注意是选择dim文件,对话框里面有三个选项卡,I/O Parameters(输入输出参数),Map Projection Definition
(定义投影)和Variables&Coniditions(变量和条件)。首先我们在输入输出参数选项卡中指定输入的影像,点击下面箭头指向的"加号”即可选择所需影像文件。在本选项卡内还需要对Nme(文件名)、文件输出类型和目录进行设置。
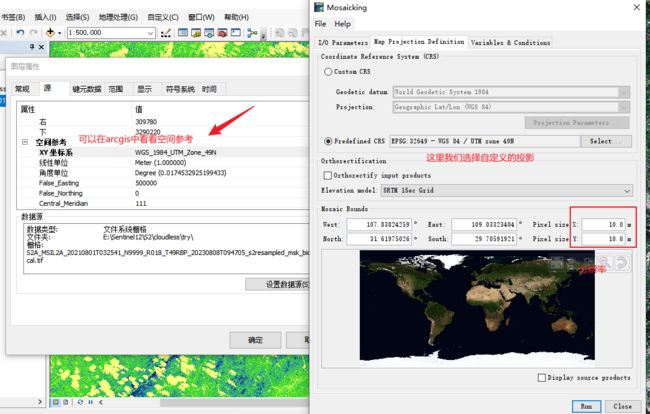

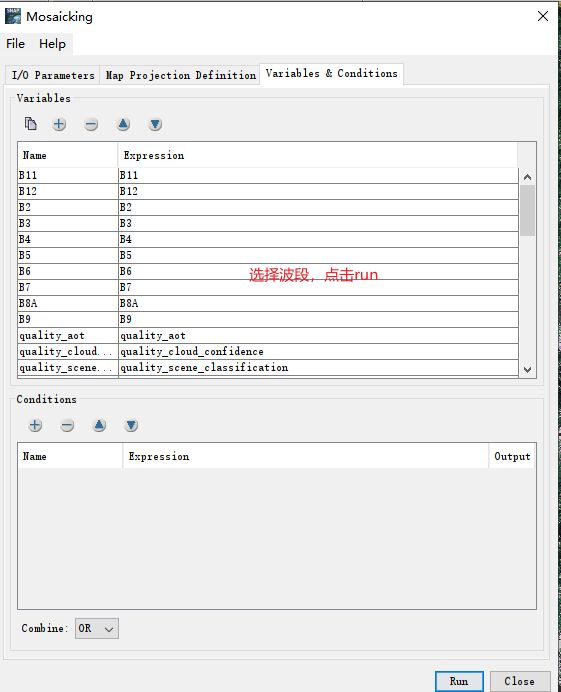
运行完毕!
镶嵌完之后再按照研究区的掩膜提取,就可以得到我们想要的研究区哨兵2号影像,这里我把它命名为S2.tif
可以在arcgis中查看一下坐标系、分辨率等信息是不是我们想要的。
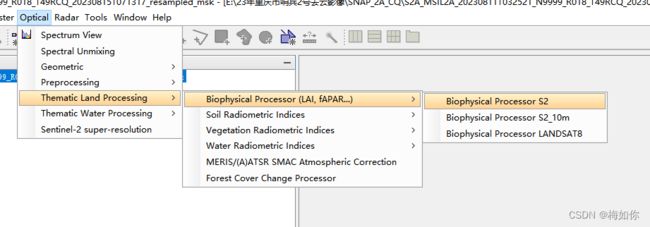
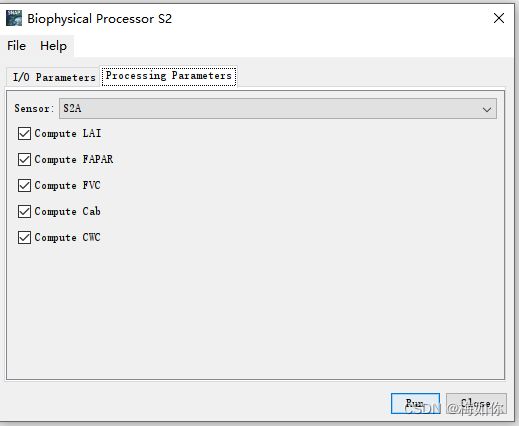
1.6计算生物物理变量
对于哨兵二号数据以及LANDSAT8数据,SNAP中有已经集成好的模块计算LAI。其算法主要基于辐射传输模型,可生成植被特征和TOC反射率的综合数据库,然后训练神经网络从TOC反射率估算冠层特征,并设置相应的角度定义观测配置。LAl输出将由算法在每个像素上的应用提供。除了产品值之外,还会生成描述输出有效性的质量标志(flags)。
此模块在Optical->Thematic Land Processing->Biopyhsical Processor目录下面。
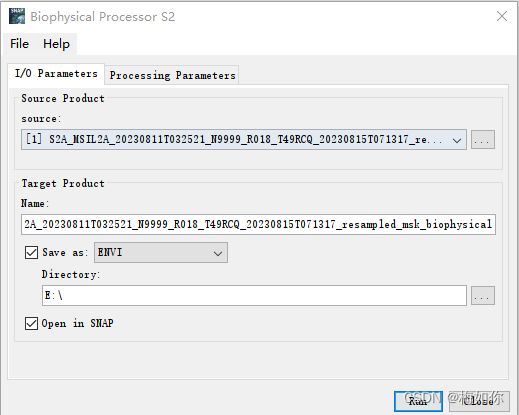
Biopyhsical Processor S2_10m可以计算出LAI、FAPAR和FVC,Biopyhsical Processor S2可以计算出LAI、FAPAR、FVC、Cab以及CWC。本研究需要计算LAI、FAPAR、FVC、Cab以及CWC。各个含义为:
LAI:叶面积指数;
FAPAR:吸收的光合有效辐射的分数;
FVC:植被覆盖率;
Cab:叶片叶绿素含量;
CWC:冠层含水量。
保存为envi格式
1.7采用gdal计算各类植被指数
Sentinel-2 影像文件名 s.tif,使用命令将指数计算转换为 GDAL python本地计算.
将gdal_calc.py下载地址和s.tif文件放在同一个文件夹下。
gdal_calc.py和run.bat文件已放在盘中
链接:https://pan.baidu.com/s/18KU7jNAZ82VpXzeuaBe2zg?pwd=xhv4 提取码:xhv4
1.点击开始界面,打开anaconda promopt
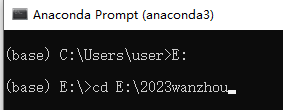
进入S2.tiff所在的文件夹路径
E:
cd E:\2023wanzhou
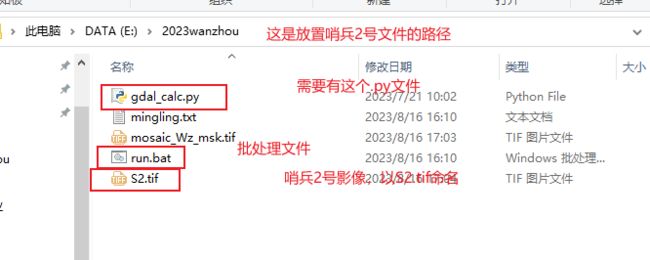
运行run.bat

运行之后会在文件夹内生成植被指数。

mingling.txt里的内容即是run.bat里的内容。.bat文件是批处理文件
run.bat的内容如下:S2.tif代表我们要计算植被指数的影像,band=4代表S.tif的B4波段,rvi.tif表示输出影像的文件名,执行的波段运算是B/A也就是B8/B4也就是NIR/RED=RVI
我们计算的植被指数有:
1.比值植被指数RVI =B8/B4
2.红外植被指数IPVI=B8/(B8+B4)
3.垂直植被指数PVI=SIN(45)*B8-COS(45)*B4
4.反红边叶绿素指数IRECI=(B8-B4)/(B8+B4)
5.土壤调节植被指数SAVI=((B8-B4)/(B8+B4+L))(1+L) L取0.5
6.大气阻抗植被指数ARVI=B8-(2*B4-B2)/B8+(2B4-B2)
7.特定色素简单比植被指数PSSRa=B7/B4
8.Meris陆地叶绿素指数MTCI=(B6-B5)/(B5-B4)
9.修正型叶绿素吸收比值指数MCARI=[B5-B4]-0.2*(B5-B3)]*(B5-B4)
10.REIP红边感染点指数REIP=700+40*[(B4+B7)/2-B5]/(B6-B5)
11.NDVI78a =(NIR2 – RE3)/ (NIR2 + RE3)
12.NDVI67= (RE3- RE2)/ (RE3+ RE2)
13.NDVI58a =(NIR2- RE1)/ (NIR2 + RE1)
14.NDVI56 =(RE2- RE1)/ (RE2+ RE1)
15.NDVI57= (RE3- RE1)/ (RE3+ RE1)
16.NDVI68a =(NIR2 - RE2)/ (NIR2 + RE2)
17.NDVI= (NIR - R)/ (NIR + R)
#1.RVI:
python gdal_calc.py -A S2.tif --A_band=4 -B S2.tif --B_band=8 --outfile=rvi.tif --calc="(B/A)" --NoDataValue=0
#2.IPVI:
python gdal_calc.py -A S2.tif --A_band=4 -B S2.tif --B_band=8 --outfile=ipvi.tif --calc="(B/(A+B))" --NoDataValue=0
#3.PVI:
python gdal_calc.py -A S2.tif --A_band=4 -B S2.tif --B_band=8 --outfile=pvi.tif --calc="(sin(pi/4)*B)-(cos(pi/4)*A)" --NoDataValue=0
#4.IRECI:
python gdal_calc.py -A S2.tif --A_band=4 -B S2.tif --B_band=8 --outfile=ireci.tif --calc="((B-A)/(B+A))" --NoDataValue=0
#5.S2AVI:
python gdal_calc.py -A S2.tif --A_band=4 -B S2.tif --B_band=8 --outfile=savi.tif --calc="((B-A)/(B+A+0.5))*(1+0.5)" --NoDataValue=0
#6.ARVI:
python gdal_calc.py -A S2.tif -B S2.tif -C S2.tif --A_band=4 --B_band=8 --C_band=2 --outfile=arvi_wanzhou.tif --calc="((B-(2*A-C))/(B+(2*A-C)))" --NoDataValue=0
#7.PS2S2Ra:
python gdal_calc.py -A S2.tif --A_band=4 -B S2.tif --B_band=7 --outfile=pS2S2ra.tif --calc="(B/A)" --NoDataValue=0
#8.MTCI:
python gdal_calc.py -A S2.tif --A_band=4 -B S2.tif --B_band=5 -C S2.tif --C_band=6 --outfile=mtci.tif --calc="((B-C)/(C-A-0.01))" --NoDataValue=0
#9.MCARI:
python gdal_calc.py -A S2.tif --A_band=4 -B S2.tif --B_band=5 -C S2.tif --C_band=3 --outfile=mcari.tif --calc="((B-A)-(0.2*(B-C)))*(B-A)" --NoDataValue=0
#10.REIP:
python gdal_calc.py -A S2.tif --A_band=4 -B S2.tif --B_band=5 -C S2.tif --C_band=6 -D S2.tif --D_band=7 --outfile=reip.tif --calc="(700)+(40*((B+D)/2-A)/(C-A))" --NoDataValue=0
#11.NDVI78a (NIR2 – RE3)/ (NIR2 + RE3)
python gdal_calc.py -A S2.tif --A_band=8 -B S2.tif --B_band=7 --outfile=ndvi78a.tif --calc="(A-B)/(A+B)" --NoDataValue=0
#12.NDVI67 (RE3- RE2)/ (RE3+ RE2)
python gdal_calc.py -A S2.tif --A_band=7 -B S2.tif --B_band=6 --outfile=ndvi67.tif --calc="(A-B)/(A+B)" --NoDataValue=0
#13.NDVI58a (NIR2- RE1)/ (NIR2 + RE1)
python gdal_calc.py -A S2.tif --A_band=8 -B S2.tif --B_band=5 --outfile=ndvi58a.tif --calc="(A-B)/(A+B)" --NoDataValue=0
#14.NDVI56 (RE2- RE1)/ (RE2+ RE1)
python gdal_calc.py -A S2.tif --A_band=6 -B S2.tif --B_band=5 --outfile=ndvi56.tif --calc="(A-B)/(A+B)" --NoDataValue=0
#15.NDVI57 (RE3- RE1)/ (RE3+ RE1)
python gdal_calc.py -A S2.tif --A_band=7 -B S2.tif --B_band=5 --outfile=ndvi57.tif --calc="(A-B)/(A+B)" --NoDataValue=0
#16.NDVI68a (NIR2 - RE2)/ (NIR2 + RE2)
python gdal_calc.py -A S2.tif --A_band=8 -B S2.tif --B_band=6 --outfile=ndvi68a.tif --calc="(A-B)/(A+B)" --NoDataValue=0
#17.NDVI48 (NIR - R)/ (NIR + R)
python gdal_calc.py -A S2.tif --A_band=8 -B S2.tif --B_band=4 --outfile=ndvi48.tif --calc="(A-B)/(A+B)" --NoDataValue=0
1.8纹理特征参数提取
采用envi软件
有研究表明,遥感数据的纹理信息能够增强原始影像亮度的空间信息辨识度,提升地表参数的反演精度。本研究采用灰度共生矩阵( gray level co-occurrence matrix,GLCM) 提取纹理特征信息,究纹理窗口大小设置为 3×3,获取8类 纹 理 特 征 值。
灰度共生矩阵提取纹理特征信息可参考

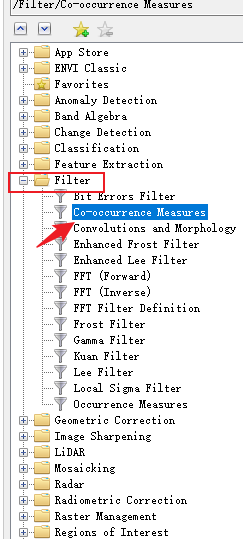
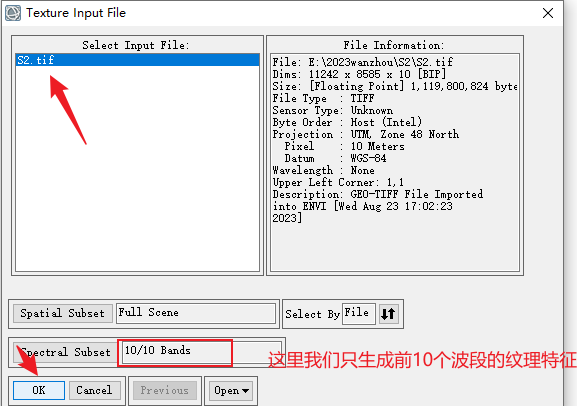
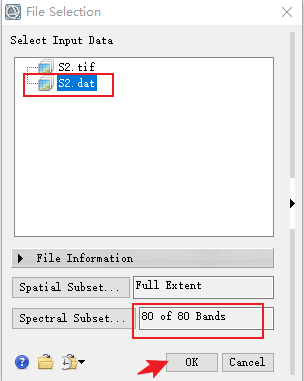
后缀名最好以.dat结尾,不然envi无法识别格式
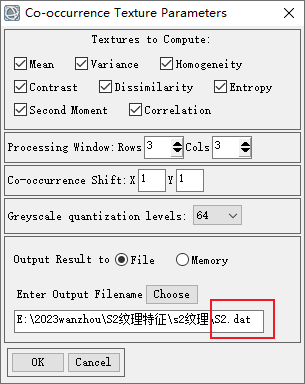
点击OK之后需要等很久很久很久,所以建议晚上运行,第二天一大早就可以看到运行完啦!
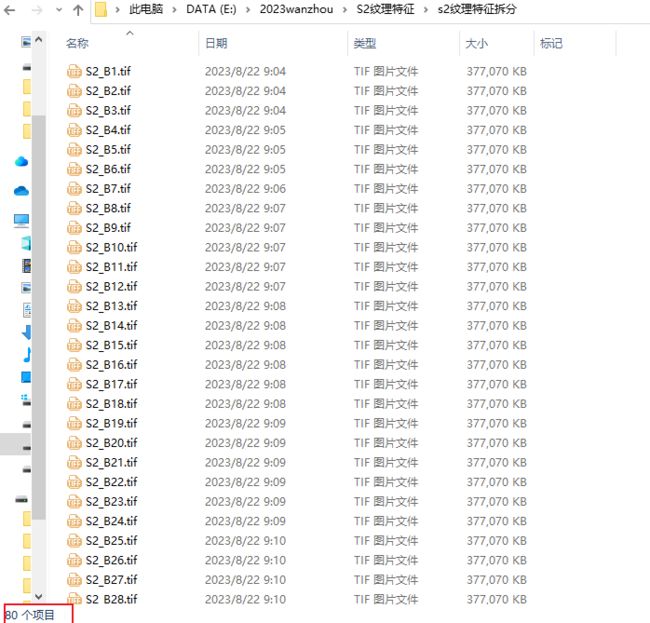
运行结束后可以看到生成了一个文件,里面有80个波段,S2有10个波段,1个波段对应8个特征
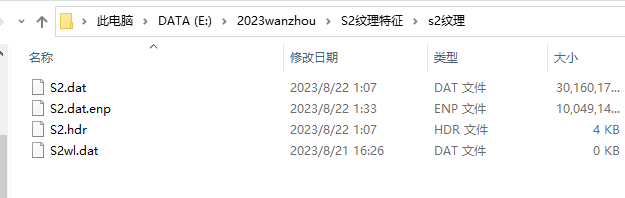
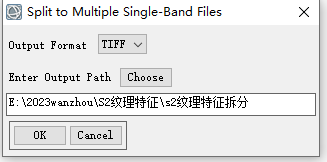
波段拆分工具:
6、处理完后可将纹理信息提取出来,可通过APP store 中的Split to Multiple Single-Band Files 工具进行直接拆分
APP Store中查找工具,第8页“将多波段图像拆分成多个单波段文件 V5.3”。

点击 Install App安装插件。重启ENVI后,可以看到Toolbox / Extensions下有Split to Multiple Single-Band Files工具。
Sentinel-2中10个波段每个波段的纹理信息共80个
二.哨兵1号获取/处理/提取数据
2.1 哨兵1号数据下载与预处理
哨兵1号数据在欧空局中下载,然后采用SNAP软件对其进行一系列处理
可参考链接
下载哨兵1号预处理流程.xml
链接:https://pan.baidu.com/s/1fkn-_e3dB3gNDaR7ZEvEiQ?pwd=y45z 提取码:y45z
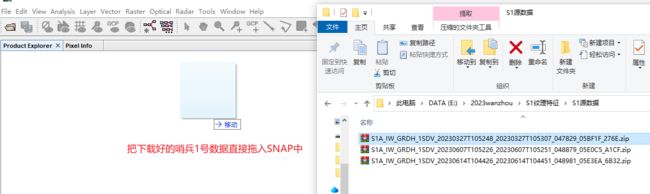
- 导入哨兵1号预处理流程.xml

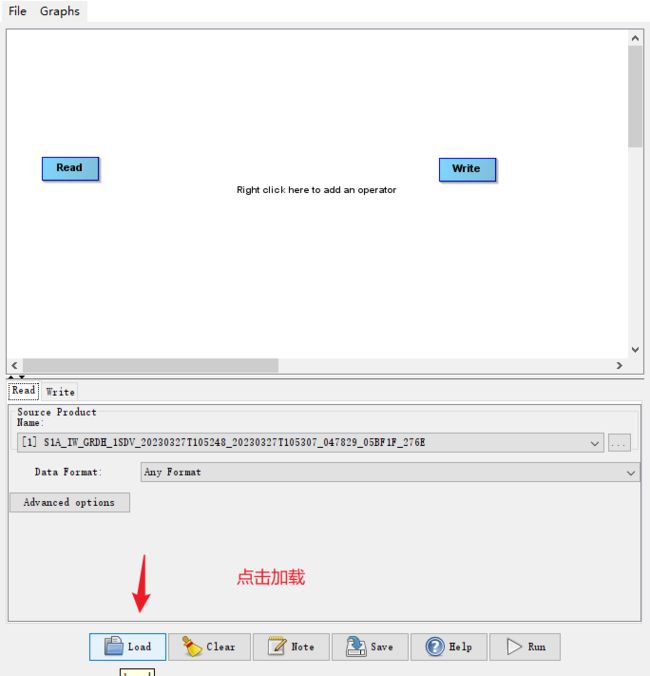
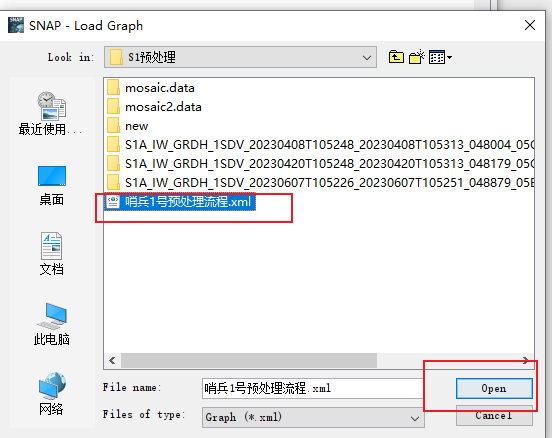
选中刚刚在百度网盘中下载的.xml文件
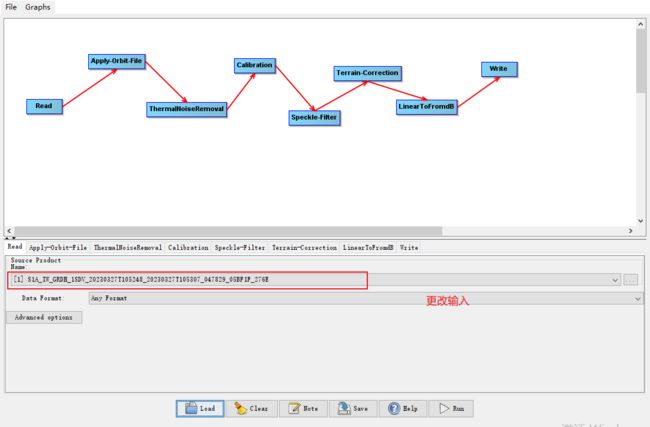
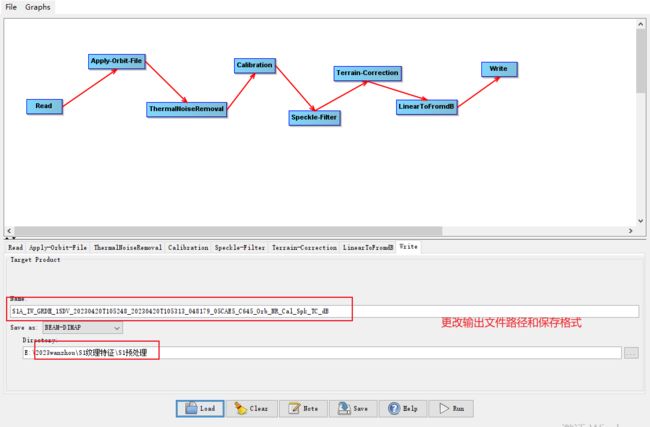
点击run按钮
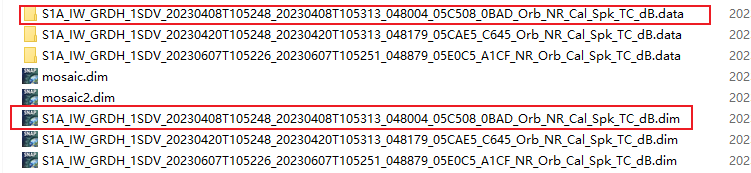
可以看到生成了一个文件件和一个dim文件
打开文件夹。
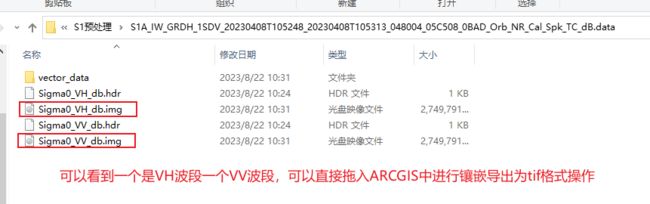
处理后记得把坐标系和投影转成和哨兵2号一样
2.2 S1纹理特征参数提取
同1.6节
基于 VH 和VV 极化影像提取纹理特征信息,获 取 8X2=16 个 纹 理 特 征
三、DEM数据
3.1 数据下载
可参考这篇文章进行数据下载
3.2 数据处理
一定要注意呀!
获取的数据是30m分辨率的,哨兵数据是10米分辨率,在arcGis中搜索resample 需要将DEM重采样到10米分辨率。
然后在ArcGis中搜索坡度和坡向这两个工具,分别计算这两变量。
四、样本生物量计算
代码如下,d代表胸径,h代表树高
查找优势树种对应的异速生长方程写上就行
import pandas as pd
# 读取 CSV 文件
df = pd.read_csv('E:\Sentinel12\yangben\yangben.csv', encoding='gbk')
# 定义优势树种类型及对应的
tree_types = {
'柏木': lambda d, h: 0.12703 * (d ** 2 * h )** 0.79775,
'刺槐': lambda d, h: ( 0.05527 * (d ** 2 * h )** 0.8576) + ( 0.02425* (d ** 2 * h )** 0.7908) +( 0.0545 * (d ** 2 * h )** 0.4574),
#http://www.xbhp.cn/news/11502.html
'栎类': lambda d, h:0.16625 * ( d ** 2 * h ) ** 0.7821,
'柳杉': lambda d, h:( 0.2716 * ( d ** 2 * h ) ** 0.7379 ) + ( 0.0326 * ( d ** 2 * h ) ** 0.8472 ) + ( 0.0250 * ( d ** 2 * h ) ** 1.1778 ) + ( 0.0379 * ( d ** 2 * h ) ** 0.7328 ),
'马尾松': lambda d, h: 0.0973 * (d ** 2 * h )** 0.8285,
'其他硬阔': lambda d, h:( 0.0125 * (d ** 2 * h )**1.05 ) + ( 0.000933* (d ** 2 * h )**1.23 ) +( 0.000394 * (d ** 2 * h )** 1.20),
'杉木': lambda d, h: ( 0.00849 * (d ** 2 * h) ** 1.107230) + ( 0.00175 * (d ** 2 * h )** 1.091916) + 0.00071 * d **3.88664 ,
'湿地松': lambda d, h: 0.01016* (d ** 2 * h )**1.098,
'香樟': lambda d, h:( 0.05560 * (d ** 2 * h )** 0.850193) + ( 0.00665 * (d ** 2 * h )** 1.051841) +( 0.05987 * (d ** 2 * h )** 0.574327)+( 0.01476 * (d ** 2 * h )** 0.808395) ,
'油桐': lambda d, h: ( 0.086217 *d ** 2.00297)+ ( 0.072497 *d ** 2.011502)+( 0.035183 *d ** 1.63929),
'杨树': lambda d, h: ( 0.03 * (d ** 2 * h )** 0.8734) + ( 0.0174 * (d ** 2 * h )** 0.8574) +( 0.4562 * (d ** 2 * h )** 0.3193)+( 0.0028 * (d ** 2 * h )**0.9675 ) ,
}
# 遍历样本并计算地上生物量```python
for i, row in df.iterrows():
tree_type = row['优势树']
if tree_type in tree_types:
d = row['平均胸径']
h = row['林分平均树高']
biomass = tree_types[tree_type](d, h)
df.at[i, '生物量'] = biomass
# 将计算后的地上生物量写入 CSV 文件
df.to_csv('E:\Sentinel12\yangben\yangben_processed.csv', index=False)
五、样本变量选取
将样本导入arcgis,设置好投影信息,在ArcGis中找到多值提取至点工具。
1.导入因子tif,和样地表

采用多值提取至点工具
可以选择多个tif影像,也就是我们前面步骤计算的生物物理变量、植被指数、S280个纹理特征、S116个纹理特征、VH、VV等变量。

提取后会将对应的字段添加在表后面
打开属性表可以看到

采用转换工具表转EXCEL可以导出为表格
六、基于python随机森林模型反演森林生物量
6.1筛选变量相关性分析(可选)
参考1
参考2
可以用SPSS进行相关性分析,可参考,选择相关性比较大的变量进行建模
也可以将全部变量扔进随机森林模型中,在变量重要性分析那里选择排名靠前的变量再进行建模
6.2导入库与变量准备
记得安装sklearn包
命令行如下:
pip install scikit-learn
本文中设计到的所有python代码均在jupyter notebook中运行的
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
from pyswarm import pso
import rasterio
# import pydot
import numpy as np
import pandas as pd
import scipy.stats as stats
from pprint import pprint
from sklearn import metrics
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import RandomizedSearchCV
from joblib import dump
# 读取Excel表格数据
data = pd.read_csv(r'E:\Sentinel12\yangben\建模\jianmo.csv' )
y = data.iloc[:, 0].values # 生物量
X = data.iloc[:, 1:].values # 指标变量
df = pd.DataFrame(data)
random_seed=44
random_forest_seed=np.random.randint(low=1,high=230)
# 分割数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
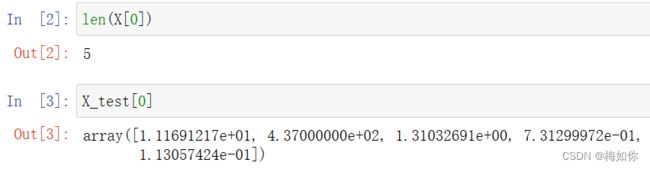
运行完这个代码块,可以打印一下,看看变量长什么样。这里可以看到,选取的变量一共有5个,值分别为1.11691217e+01, 4.37000000e+02, 1.31032691e+00, 7.31299972e-01, 1.13057424e-01 可以打开样本表看看,这五个变量对应的值是否正确。
6.3 选取参数
决策树个数n_estimators
决策树最大深度max_depth,
最小分离样本数(即拆分决策树节点所需的最小样本数) min_samples_split,
最小叶子节点样本数(即一个叶节点所需包含的最小样本数)min_samples_leaf,
最大分离特征数(即寻找最佳节点分割时要考虑的特征变量数量)max_features
# Search optimal hyperparameter
#对六种超参数划定了一个范围,然后将其分别存入了一个超参数范围字典random_forest_hp_range
n_estimators_range=[int(x) for x in np.linspace(start=50,stop=3000,num=60)]
max_features_range=['sqrt','log2',None]
max_depth_range=[int(x) for x in np.linspace(10,500,num=50)]
max_depth_range.append(None)
min_samples_split_range=[2,5,10]
min_samples_leaf_range=[1,2,4,8]
random_forest_hp_range={'n_estimators':n_estimators_range,
'max_features':max_features_range,
'max_depth':max_depth_range,
'min_samples_split':min_samples_split_range,
'min_samples_leaf':min_samples_leaf_range
}
random_forest_model_test_base=RandomForestRegressor()
random_forest_model_test_random=RandomizedSearchCV(estimator=random_forest_model_test_base,
param_distributions=random_forest_hp_range,
n_iter=200,
n_jobs=-1,
cv=3,
verbose=1,
random_state=random_forest_seed
)
random_forest_model_test_random.fit(X_train,y_train)
best_hp_now=random_forest_model_test_random.best_params_
# Build RF regression model with optimal hyperparameters
random_forest_model_final=random_forest_model_test_random.best_estimator_
print(best_hp_now)
可以看到打印结果

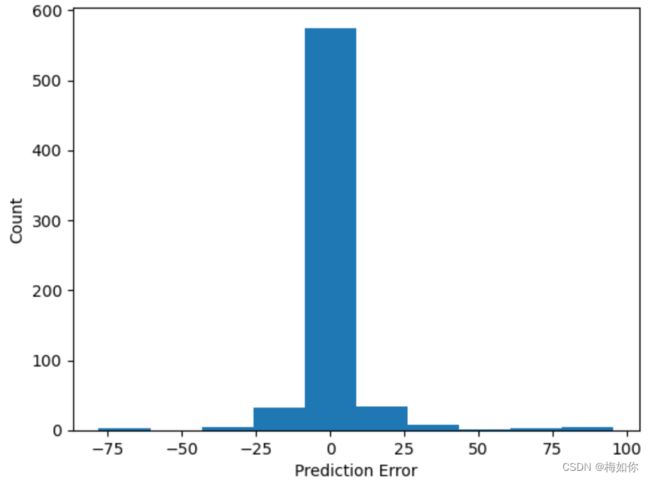
6.4 误差分布直方图
如果直方图呈现正态分布或者近似正态分布,说明模型的预测误差分布比较均匀,预测性能较好。如果直方图呈现偏斜或者非正态分布,说明模型在某些情况下的预测误差较大,预测性能可能需要进一步改进。
# Predict test set data
random_forest_predict=random_forest_model_test_random.predict(X_test)
random_forest_error=random_forest_predict-y_test
plt.figure(1)
plt.clf()
plt.hist(random_forest_error)
plt.xlabel('Prediction Error')
plt.ylabel('Count')
plt.grid(False)
plt.show()
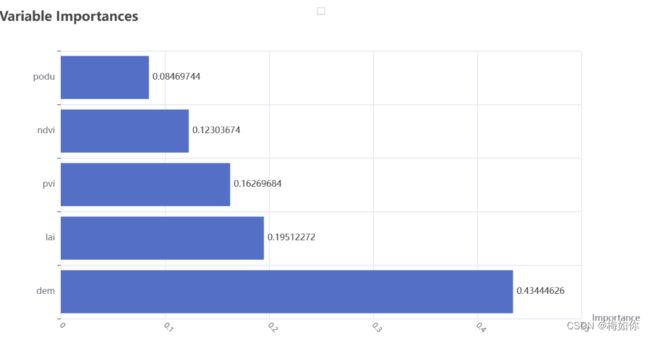
6.5 变量重要性可视化展示
#这里如果报错参考https://blog.csdn.net/sjjsaaaa/article/details/111824696
#需要安装 pip install pyecharts
from pyecharts.charts import Bar
from pyecharts import options as opts
# 计算特征重要性
random_forest_importance = list(random_forest_model_final.feature_importances_)
random_forest_feature_importance = [(feature, round(importance, 8))
for feature, importance in zip(df.columns[6:], random_forest_importance)]
#df.columns[4:]代表样本中从第6列起及以后的是我要建模的变量
random_forest_feature_importance = sorted(random_forest_feature_importance, key=lambda x:x[1], reverse=True)
# 将特征重要性转换为Pyecharts所需的格式
x_data = [item[0] for item in random_forest_feature_importance]
y_data = [item[1] for item in random_forest_feature_importance]
# 绘制柱状图
bar = (
Bar()
.add_xaxis(x_data)
.add_yaxis("", y_data)
.reversal_axis()
.set_series_opts(label_opts=opts.LabelOpts(position="right"))
.set_global_opts(
title_opts=opts.TitleOpts(title="Variable Importances"),
xaxis_opts=opts.AxisOpts(name="Importance",axislabel_opts=opts.LabelOpts(rotate=-45, font_size=10)),
yaxis_opts=opts.AxisOpts(name_gap=30, axisline_opts=opts.AxisLineOpts(is_show=False)),
tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="shadow")
)
)
bar.render_notebook()
6.6 对精度进行验证
这里可输出相关的精度值
# Verify the accuracy
random_forest_pearson_r=stats.pearsonr(y_test,random_forest_predict)
random_forest_R2=metrics.r2_score(y_test,random_forest_predict)
random_forest_RMSE=metrics.mean_squared_error(y_test,random_forest_predict)**0.5
print('Pearson correlation coefficient = {0}、R2 = {1} and RMSE = {2}.'.format(random_forest_pearson_r[0],random_forest_R2,random_forest_RMSE))
6.7 预测生物量
这里注意,输入变量需要与表格中一致
每个栅格变量数据一定要保持行数和列数一致,如果不一致可以先统一重采样到10m,再按照行列数小tif的对大的进行掩膜提取。
import numpy as np
import rasterio
from tqdm import tqdm
# 读取五个栅格指标变量数据并整合为一个矩阵
with rasterio.open(r'E:\Sentinel12\yangben\建模\result\nodata\podu.tif') as src:
data1 = src.read(1)
meta = src.meta
with rasterio.open(r'E:\Sentinel12\yangben\建模\result\nodata\dem.tif') as src:
data2 = src.read(1)
with rasterio.open(r'E:\Sentinel12\yangben\建模\result\nodata\lai.tif') as src:
data3 = src.read(1)
with rasterio.open(r'E:\Sentinel12\yangben\建模\result\nodata\ndvi.tif') as src:
data4 = src.read(1)
with rasterio.open(r'E:\Sentinel12\yangben\建模\result\nodata\pvi.tif') as src:
data5 = src.read(1)
X = np.stack((data1, data2, data3, data4, data5), axis=-1)
# 清洗输入数据
X_2d = X.reshape(-1, X.shape[-1])
# 检查数据中是否存在 NaN 值
print(np.isnan(X_2d).any()) # True
# 将 nodata 值替换为0
X_2d[np.isnan(X_2d)] = 0
# 使用已经训练好的随机森林模型对整合后的栅格指标变量数据进行生物量的预测
y_pred = []
for i in tqdm(range(0, X_2d.shape[0], 10000)):
y_pred_chunk = random_forest_model_test_random.predict(X_2d[i:i+10000])
y_pred.append(y_pred_chunk)
y_pred = np.concatenate(y_pred)
# 将预测结果保存为一个新的栅格数据
with rasterio.open(r'E:\Sentinel12\yangben\建模\result\biomass_v5.tif', 'w', **meta) as dst:
dst.write(y_pred.reshape(X.shape[:-1]), 1)
print("预测结束")
运行之后会在下面出现进度条,进度条走完了就代码预测完了

七、生物量制图
7.1 提取森林掩膜区域
[参考链接](https://www.bilibili.com/video/BV1qv4y1A75B?p=10&vd_source=ddb0eb9d8fde0d0629fc9f25dc6915e5)
-
这里需要全球土地覆盖10米的更精细分辨率观测和监测(FROM-GLC10)数据。
-
我们在GEE平台上下载研究区的GLC10图,参考链接
- 在 Google Earth Engine Code Editor 中搜索“ESA Global Land Cover 10m v2.0.0”并加载该数据集。
var glc = ee.Image('ESA/GLOBCOVER_L4_200901_200912_V2_3');
- 定义您感兴趣的区域。
这里的table需要先将shp文件上传到平台,再点那个小箭头导入
这里就会有table出现

var geometry = table;
- 使用 Image.clip() 函数将图像裁剪为您感兴趣的区域。
var clipped = glc.clip(geometry);
- 使用 Export.image.toDrive() 函数导出图像。以下代码将图像导出到您的 Google Drive 中。
Export.image.toDrive({
image: clipped,
description: 'GLC',
folder: 'my_folder',
scale: 10,
region: geometry
});
其中,description 是导出图像的名称,folder 是导出图像的文件夹,scale 是导出图像的分辨率,region 是导出图像的区域。
- 点击“Run”按钮运行代码。代码运行完成后,您可以在 Google Drive 中找到导出的图像文件。
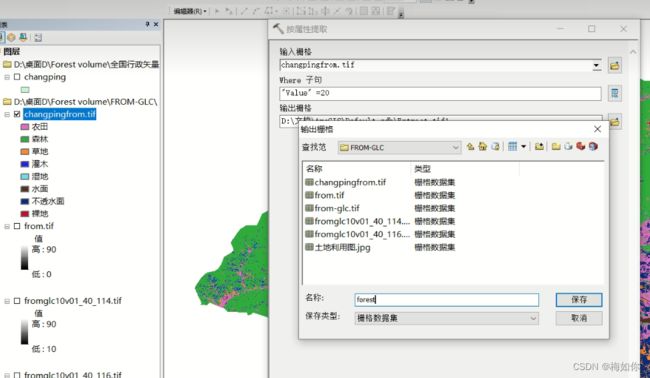
- 20序号代表森林,按属性提取,可以把森林提取出来,按属性提取工具。
重采样到10m,定义投影
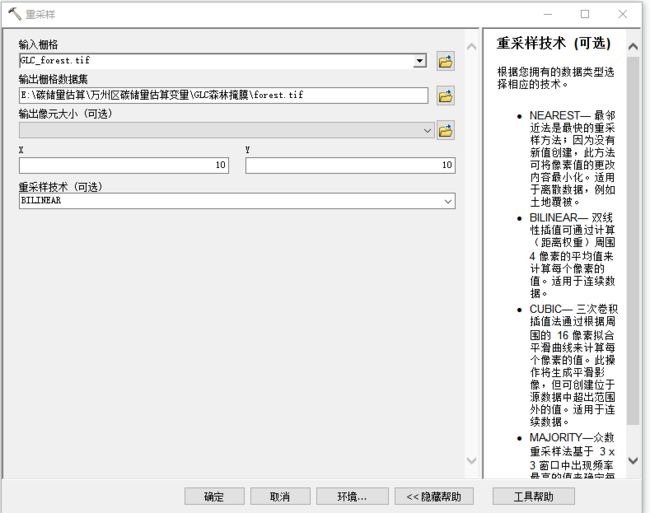
将6.7节得到的生物量.tif按照掩膜tif掩膜即可得到森林区域的生物量。
八. 需要注意的点
- 每个栅格变量数据一定要保持行数和列数一致,这不仅是为了”多值提取至点“等一一对应,更是为了最后估算生物量的时候生成二维矩阵输入模型,保证输入数据的维度一致。
- 投影!投影!投影!重要的事情说三遍,一定要在相同坐标系下面,分辨率一致一致!!!
- 发现问题解决问题,不要放弃!因为我就是这样过来的,不信看下面
浅记录一下实现一个功能尝试了9种方法成功了!
目的:估算生物物理变量
分析:SNAP软件中有这个功能,但是数据去云很麻烦,需要用去云后的数据来估算,SNAP提供的掩膜效果又不好。
方法1:在GEE上下载去云后tif格式影像,直接导入SNAP计算。(失败,缺失一些波段)
方法2:将对应safe格式导出为tif,共47个波段,除B1-B12,加入gee上下载的tif文件中。(失败,无法识别,缺失波段)
方法3:研究SNAP中Biophysical Processor模型官方文档,看能否在本地复现。(失败,看不懂,没公开代码,版权限制)
方法4:转而研究去云,不用GEE上的数据,发现sen2Three插件,似乎能完美解决我们的问题。查看官方文档,好不容易安?装好后,运行命令之后无输出结果。查看官方论坛之后发现,bug比较多,且需要和sen2cor版本配对。尝试低版本sen2cor依旧失败,无果。
方法5:查找去云算法Fmask,下载软件并安装,研究怎么去云,最终生成了云掩膜文件,成功迈出第一步!!打算在SNAP中导出TIF格式进行掩膜,再放入snap中进行镶嵌、计算生物物理变量。(失败,在arcGis中进行掩膜提取之后数据格式发生变化,snap无法计算,且SNAP导出tif时间太长,方法不可取。)
方法6:怎么SNAP没有按照掩膜提取这个功能呢???呜呜呜。发现SNAP可以导入shp文件,故尝试把生成的云掩膜文件栅格转面为shp格式(ENVI和ArcGis导出的shp都不行,奇了怪了这个SNAP软件)。(失败。云太复杂了,栅格转面后导入SNAP丢掉了一些像素,覆盖不全)
方法7:直接研究Fmask代码,更改输出文件类型为shp格式,本地运行,哎,快崩溃了!!啊gdal中偏偏没有直接调用.img转shp的功能。
方法8:算了算了,不研究Fmask的Python代码了,这么多估计我也看不懂。转而用Python代码直接把软件生成的tif转为shp会不会比ArcGIS导出来的要好一点?问了ChatGPT给我提供一堆报错的代码,算了算了自己在网上找。成功用代码转为了shp格式。导入SNAP全白(失败,怪我小白呜呜)
方法9:我就不信了我弄不出来!干脆直接把分类为云的像素删掉置为Nodata。找了ChatGPT帮忙,还好这次它比较靠谱。用ArcGis打开看了看我觉得这次能成功!导入SNAP确实OK了!
一共耗时约32个小时(四天)