用python爬取某个小说前导知识
今天写一篇用python爬取网站文本格式的内容,学习并且记录
首先导入好所需要用的python库:
1、打开cmd:输入:pip install requests 回车下载requests包
输入:pip install bs4 回车下载bs4包
这里我已经安装好了所需包

2、这里我们爬取以下网址:
url = "http://www.ibiqu.org/0_844/636719.html" # 笔趣阁的斗破苍穹网址,这里只爬取一章3、查找自己的headers
打开任意浏览器网页,鼠标右键,点击inspect,进入开发者模式,然后点击Network
这里我们看到什么都没有
接着我们刷新该页面
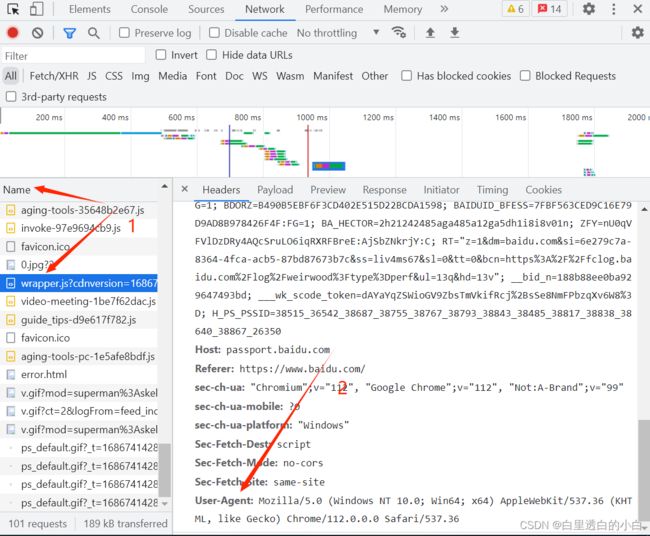
在Name属性中随便找一个,在右边的Headers中找到User-Agent,右键复制即可
以下是完整代码,都写有注释,只需要改变User-Agent即可直接运行
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36"
#这里换成自己复制到的User-Agent即可
}# 爬取一章小说
import requests#导入requests库,用于获取网页内容
from bs4 import BeautifulSoup # 从bs4库中导入BeautifulSoup
url = "http://www.ibiqu.org/0_844/636719.html" # 笔趣阁的斗破苍穹网址,这里只爬取一章
# response = requests.get(url)
# headers 里面的参数内容是从百度里面找的,不然会被反爬虫
headers = {
"user-agent": "这里写你复制到的User-Agent"
}
response1 = requests.get(url, headers=headers)
# print(response1.text)
# 将文本数据转换成BeautifulSoup对象
# bs=BeautifulSoup(response1.content,"html5lib")#html5lib是解析器,需要pip install html5lib
bs = BeautifulSoup(response1.content, "html.parser") # 同上
bs_find = bs.find('div', attrs={'id': 'content'})
# print(bs_find)
# print("\n")
book_list = bs_find.findAll('p') # 查找所有的p标签
# print(book_list)#列表
# 遍历数据
# 写入数据
with open('斗破苍穹.txt', 'a', encoding='utf-8') as f:#打开文件,写入爬取的内容
for txt in book_list:
f.write(txt.text)
f.write("\n")
print("写入完成")