Stable Diffusion---Ai绘画-下载-入门-进阶(笔记整理)
前言
注:本文偏向于整理,都是跟着大佬们学的。
推荐两个b站up主,学完他们俩的东西基本就玩转SD为底的ai绘画:
秋葉aaaki,Nenly同学
1.首先SD主流的就是秋叶佬的Webui了,直接压缩包下载即可,下载地址在这个视频的简介里:https://www.bilibili.com/video/BV1iM4y1y7oA
2.下载之后,就可以配合着Nenly佬的ai绘画课来看我的笔记了(正课一共10集,基本满足大部分人的需求了):
https://www.bilibili.com/video/BV1As4y127HW
3.有一点要注意以下,第10课中的ControlNet,Nenly佬提供的方法是不使用秋叶Webui的方法,我比较推荐用秋叶Webui,毕竟是来画的不是来被一堆安装问题弄疯的,在下载她的压缩包的时候就会把主流的ControlNet模型都给你了,然后启用ControlNet的方法可以看我的笔记也可以看秋叶佬的视频:https://www.bilibili.com/video/BV1fa4y1G71W
当然如果你想挑战原汁原味的下载和安装以及锻炼英语能力,你可以直接去github下载:https://github.com/AUTOMATIC1111/stable-diffusion-webui
Stable Diffusion笔记
目录 (点击即可跳转):
1. 提示词常用模板
2. 常用主模型/底模型(checkpoint)
3. 超分辨率
4. Embeddings/LoRa/Hypernetwork 针对性小模型
5. 图片tag反推
6. 定向局部重绘/修复
7. Stable Diffusion扩展插件
8. Lora的详细使用
9. ControlNet基础及进阶
1.提示词常用模板
ai绘画的重中之重,想让ai画出满意的画,tag自然要精良,以下是区分各种不同词条并分类,仅作为示例,比较简单且快速上手的方法就是直接抄大佬作业,去https://civitai.com/随便找个大佬作品,点进去图片基本上都会有生成那张图片的tag,抄就完事了,后续熟练再自己写。
不过负面提示词可以直接抄我的,这东西基本没啥变化,除非你想画古神?
以及可以通过加括号的方式来提高某些词语的权重, 一个括号()为1.1倍权重, 每次套一个括号就是再乘1.1,也可以通过(xxx:1.2)这种来直接指定tag的权重。
翻译软件或者在扩展插件中提到的词库翻译,都是你写tag的好帮手,个人非常推荐词库翻译,你可以写中文来补全英文,也能更好的理解有一些tag的意义。
正面提示词
- 描述人物:
1girl, solo, ultra detailed (green eyes), very long [brown|blondie|brown] curly hair, (fine face),upper body, - 描述场景:
sits in the flower meadow, - 描述环境(时间,光照):
sunrise,beautiful detailed sky,a lot of white flowers,sunlight, - 描述画幅视角:
cinematic angle, - 其他画面要素:
depth of field,
- 高品质标准化:
(masterpiece:1.5),(best quality:1.1),(ultra-detailed),(illustration), - 画风标准化:
anime, - 其他特殊要求:
- Lora添加:
负面提示词
(worst quality:1.5), (low quality:1.5), (normal quality:1.5), lowres, bad anatomy, bad hands, multiple eyebrow, (cropped), extra limb, missing limbs, deformed hands, long neck, long body, (bad hands), signature, username, artist name, conjoined fingers, deformed fingers, ugly eyes, imperfect eyes, skewed eyes, unnatural face, unnatural body, error, painting by bad-artist layman work, worst quality, ugly, (deformed|distorted|disfigured:1.21), poorly drawn, bad anatomy, wrong anatomy, mutation, mutated, (mutated hands AND fingers:1.21), bad hands, bad fingers, loss of a limb, extra limb, missing limb, floating limbs, amputation, Yaeba, photo, deformed, black and white, realism, disfigured, low contrast,EasyNegative,
示例:

2.常用主模型/底模型(checkpoint)
模型下载一般就去 https://civitai.com/ 或者 https://huggingface.co/,以下的这些皆为主流模型推荐。
二次元模型:
- Anything V5
- Counterfeit V2.5
- Dreamlike Diffusion
- AbyssOrangeMix2
- Cetus-Mix
- pastelMix
真实风格模型:
- koreanDollLikeness
- LOFI
- Realistic Vision
2.5D风格模型:
- Never Ending Dream
- Protogen
- GuoFeng3
3.超分辨率
3.1 Hi-Res Fix: 通过Text to image的固定词条和seed,
选择高清修复,调整放大算法(R-ESRGAN 4x+/anime6B),高清修复采样次数0-7,重绘幅度(0.3-0.7),放大倍率2等.

3.2 SD放大(upscal): 通过image to image将图片分割为多个区块分别进行放大重绘,再通过图块重叠像素Tile Overlap来让区块进行过度,
选择SD脚本,重绘幅度0.3-0.7,重叠像素128,宽度和高度加上放大的像素尺寸.
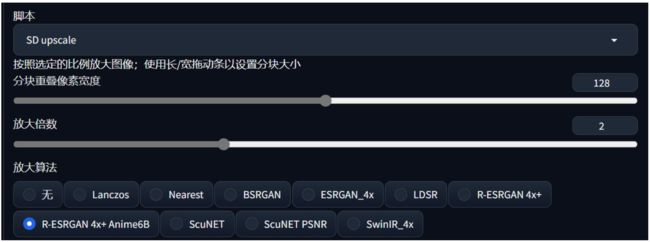
3.3 附加功能中的ai超分:相当于重绘幅度为0的高清修复
缩放比例2,选择两个放大算法,调整第二个放大算法的可见度0.3-0.7
4.Embeddings/LoRa/Hypernetwork 针对性小模型
4.1 Embeddings:
.pt文件,词嵌入模型,类似于书签,使用关键词触发,“嵌入式向量”,本身不包含信息。
- 角色三视图 CharTurner
- 解决手部问题 badhandv4,EasyNegative
- 真人问题 DeepNegative
4.2 LoRa:
.safe文件,低秩适应模型,类似于更为直接且清晰的彩页图片书签,更加完好的保证了某一角色/类型的特点,使用
4.3 Hypernetwork:
超网络模型,非写实类型更改画风,但可以被lora进行替代
5.图片tag反推
这个太简单了,没啥说的,切换到tagger中直接图片拖进去就自动给你分析了
- 图生图中的DeepBooru/CLIP反推
- WD1.4标签器(推荐)
6.定向局部重绘/修复
6.1 使用图生图中的局部重绘功能
使用画笔覆盖需要重绘的区域,设置较高的重绘幅度0.75+,蒙版预留边缘像素和重绘区域成正比,蒙版模糊也是同理,但推荐10以下。
蒙版:指被画笔涂黑的区域

6.2 Inpaint Stetch画笔绘制重绘 (涂鸦重绘)
使用画笔添加需要的内容,并可以根据调色板来指定颜色,可以对画面进行添加物体例如口罩。记得画完物品后加上对应的物品词条(black mask:1.2)。
蒙版透明度代表添加上去的颜色的不透明度,重绘幅度调低0.5-。

6.3 上传重绘蒙版
说人话就是用Ps等图片处理软件来进行蒙版的选取,套索工具等
7.Stable Diffusion扩展插件
一些基础扩展插件已经被秋叶佬的webui中收录,进阶的可以去扩展extension里下载。
7.1 基础扩展:
- SD汉化,搜索zh
- 图库浏览器,搜索image browser
- 提示词补全,搜索tag complete
- 词库翻译,b站up@一般路过的boki酱整合的7w词条翻译,放到extension文件中的tags文件夹中,并进行webui的设置(标签自动补全)更改选择使用的标签文件名以及翻译文件名
7.2 进阶扩展:
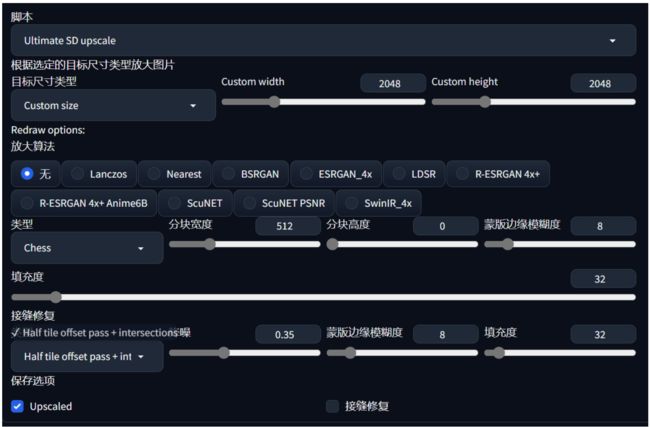
- Ultimate SD Upscale 无损高清放大,SD放大的上位替代,搜索ultimate。
目标尺寸类型选custom进行调整放大后的大小,放大算法R-ESRGAN 4+,Chess类型,宽度512,按缝修复half tile offset pass + intersection,重绘幅度0.5.
8.Lora
多在c站逛逛,总会有心仪的lora的
8.1 Lora的详细使用:
.ckpt/.safe文件,放入sd-webui-aki-v4.2\models\Lora文件夹中。
- 在提示词中假如对应的lora的
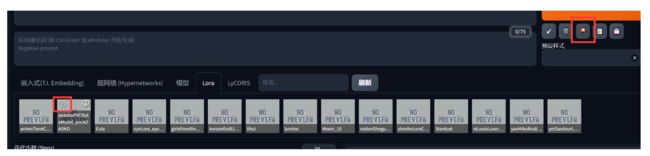
- 通过webui中的按钮来显示所有可用lora(记得刷新)。
同时可以通过点击Lora的替换图按钮来为Lora设置预设图,更清晰明了的展现Lora的风格,方便挑选:
8.2 Lora的分类:
人物lora的权重在0.6-0.8之间,其余lora如果用于’调味’那就设置在0.3左右。
9.ControlNet基础及进阶
Ai绘画的进阶技巧,通过 骨骼/景深/描边 模型来一定程度上的控制ai绘画的 动作/场景/人物特点 等。
工作原理是基于一些额外信息来给扩散模型的生成提供明确的指引 (启发式函数?)。
9.1 安装:
秋叶佬的教程:https://www.bilibili.com/video/BV1fa4y1G71W/
- 将预处理器的download文件夹复制到"sd-webui-aki-v4.2\extensions\sd-webui-controlnet\annotator"文件夹中。
- 将模型放入到"sd-webui-aki-v4.2\models\ControlNet"文件夹中。
9.2 ControlNet的参数:
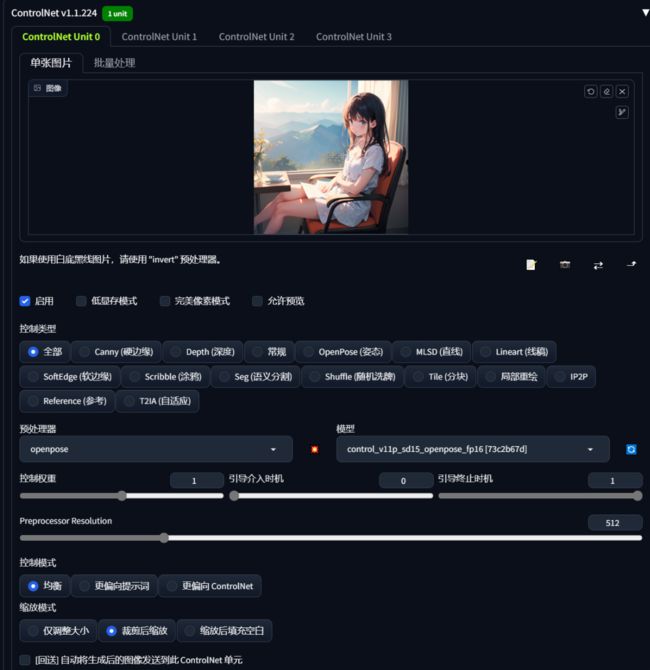
- 勾选启用。
- 完美像素模式,建议勾选,自动计算预处理器产出图像最适合的分辨率。
- 允许预览, 打开一个小窗口可以看到处理过的信息图。
- 控制模式,让图片更倾向于什么,一般balance就够用。
- 预处理器和模型选择要对应。
- 权重,controlnet的控制强度。
- 引导介入/引导终止时机, 也就是controlnet何时介入图像扩散生成的过程,晚一点介入可以给到ai更多的自由度。
控制模式的示例:

9.3 ControlNet的模型:
五种基础模型 (Canny已被Lineart替代)

其余可用模型:
- Lineart,上位替代Canny
- Instruct Pix2Pix,根据指令/tag局部整体操纵图像 (例如变为夜晚)
- Tile,增加局部细节
- Shuffle 打乱重建/风格迁移
9.4 五大模型的应用:
-
Openpose,捕捉人物骨骼,可以使用预处理器openpose-full来进行全捕捉(手部,面部,身体), 也可以使用hand/face/faceonly来只捕捉某一部分。
-
Depth,捕捉景深还原富有空间感的多层次场景,推荐使用Leres++预处理,效果最为精细,但处理时间也很长。
-
Canny,识别提取图像里的边缘特征,最重要的模型之一,因为可以最大程度的保留某些特征来做到还原,比如文字,使用Canny时,如果有些线条没被识别到,那么可以试试降低两个threshold(阈值)。
-
SoftEdge,类似于更加柔和的Canny,线条更为模糊,比Canny给ai的自由度更大。
-
Scribble, 比Softedge自由度更大,可以做到灵魂画手的感觉,比如用scribble提取一个房子的线条模型,给宇宙战舰的提示词,就能得到房子形状的宇宙战舰啦!
9.5 Multi-ControlNet应用:
秋叶佬webui默认启用,可在设置-ControlNet-ControlNet unit最大数量中进行更改。
用于处理一些单个模型无法解决的情况,例如有一张手挡在脸前面的图片,openpose识别出的骨骼图无法让ai知道手到底是在脑袋前还是后,而depth虽然能根据景深识别出手在前还是后,但无法精准的给出手的骨骼,那么就可以使用Multi-ControlNet了,来让几个模型同时发挥作用。
不过切记小心每个模型的权重,比如在刚刚的手在前的例子中,depth实际上只是让ai知道手在前,那么就可以适当降低depth模型的权重,让depth对其他东西的影响降到最低。
开启后通过unit进行切换。

结尾
如果有所帮助请给个免费的赞吧~有人看才是支撑我写下去的动力!
后续可能会继续更新,不过ai绘画最近也确实没什么大的突破了。